Better intuition for information theory
Better intuition for information theory
2019-12-01 21:21:33
Source: https://www.blackhc.net/blog/2019/better-intuition-for-information-theory/
The following blog post is based on Yeung’s beautiful paper “A new outlook on Shannon’s information measures”: it shows how we can use concepts from set theory, like unions, intersections and differences, to capture information-theoretic expressions in an intuitive form that is also correct.
The paper shows one can indeed construct a signed measure that consistently maps the sets we intuitively construct to their information-theoretic counterparts.
This can help develop new intuitions and insights when solving problems using information theory and inform new research. In particular, our paper “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning” was informed by such insights.
For a gentle introduction to information theory, Christopher Olah’s Visual Information Theory is highly recommended. The original work “A Mathematical Theory of Communication” by Claude Shannon is also highly accessible, but more geared towards signal transmission.
Information theory with I-diagrams
If we treat our random variables as sets (without being precise as to what the sets contain), we can represent the different information-theoretic concepts using an Information diagram or short: I-diagram. It’s essentially a Venn diagram but concerned with information content.
An I-diagram for two random variables XX and YY looks as follows:
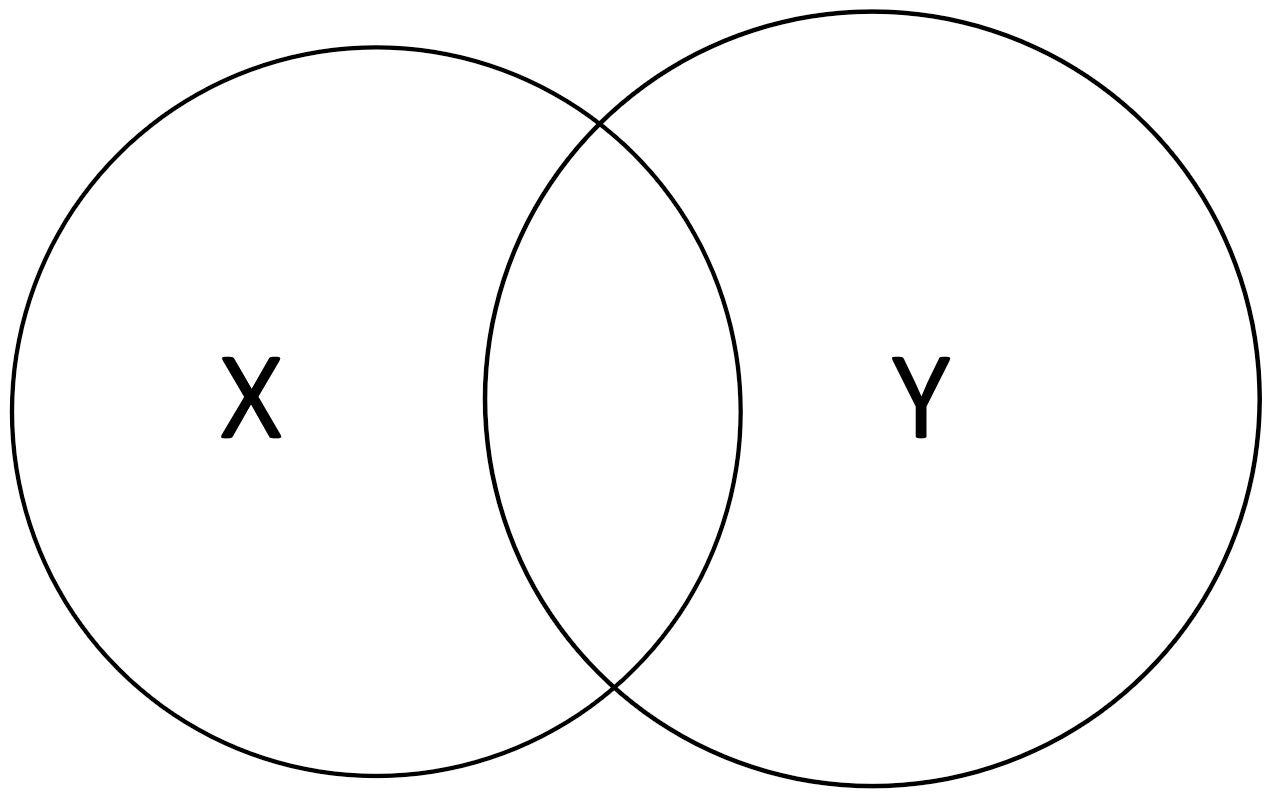
We can easily visualize concepts from information theory in I-diagrams.
|
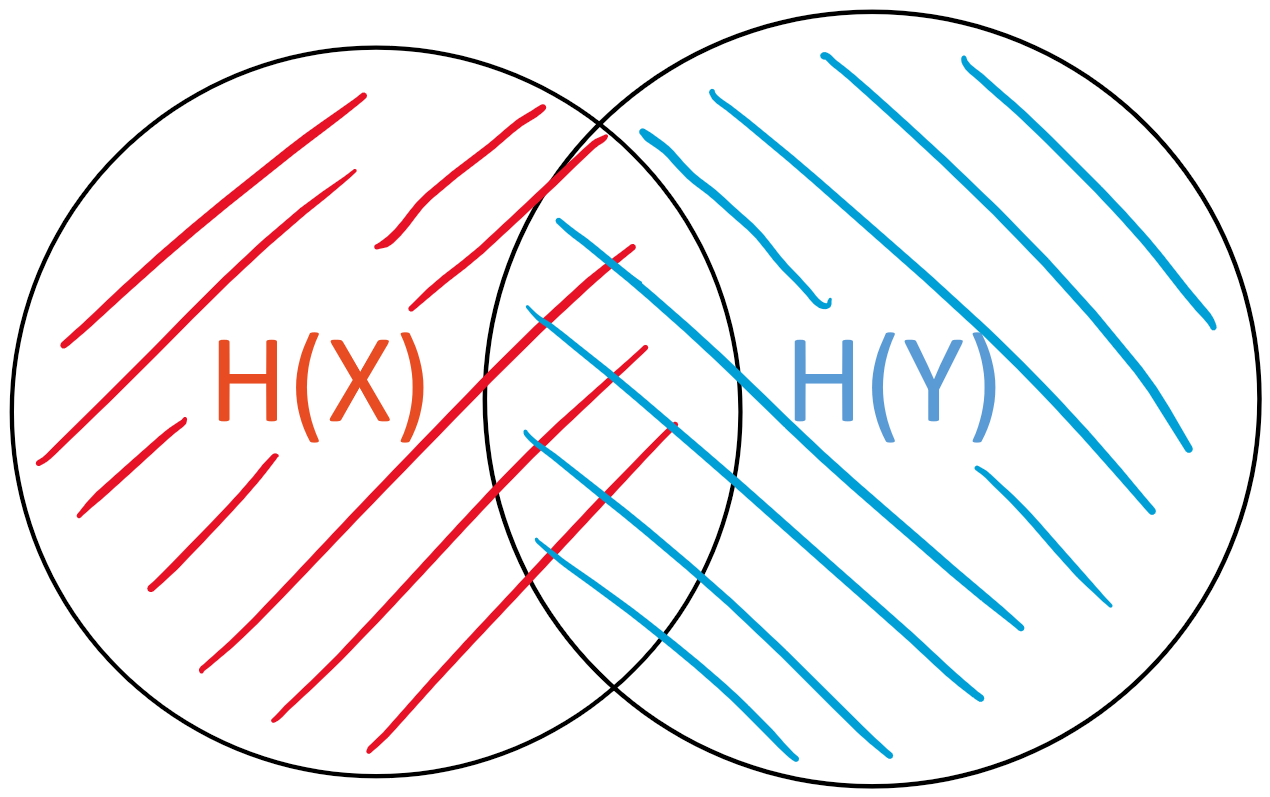
The entropy H(X)H(X) of XX, respectively H(Y)H(Y) of YY, is the “area” of either set
|
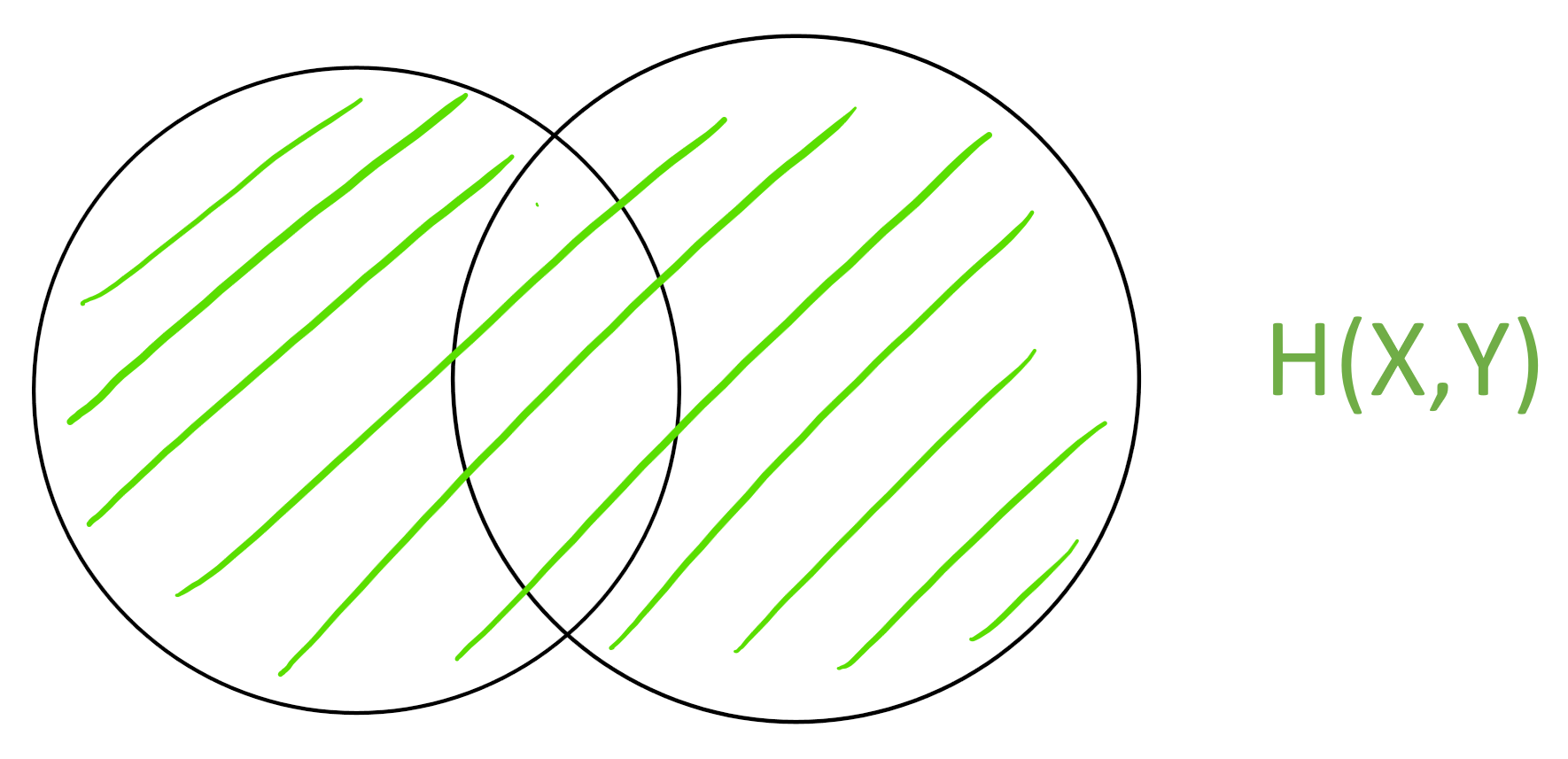
The joint entropy | H(X,Y)H(X,Y) is the “area” of the union X \cup YX∪Y
|
|
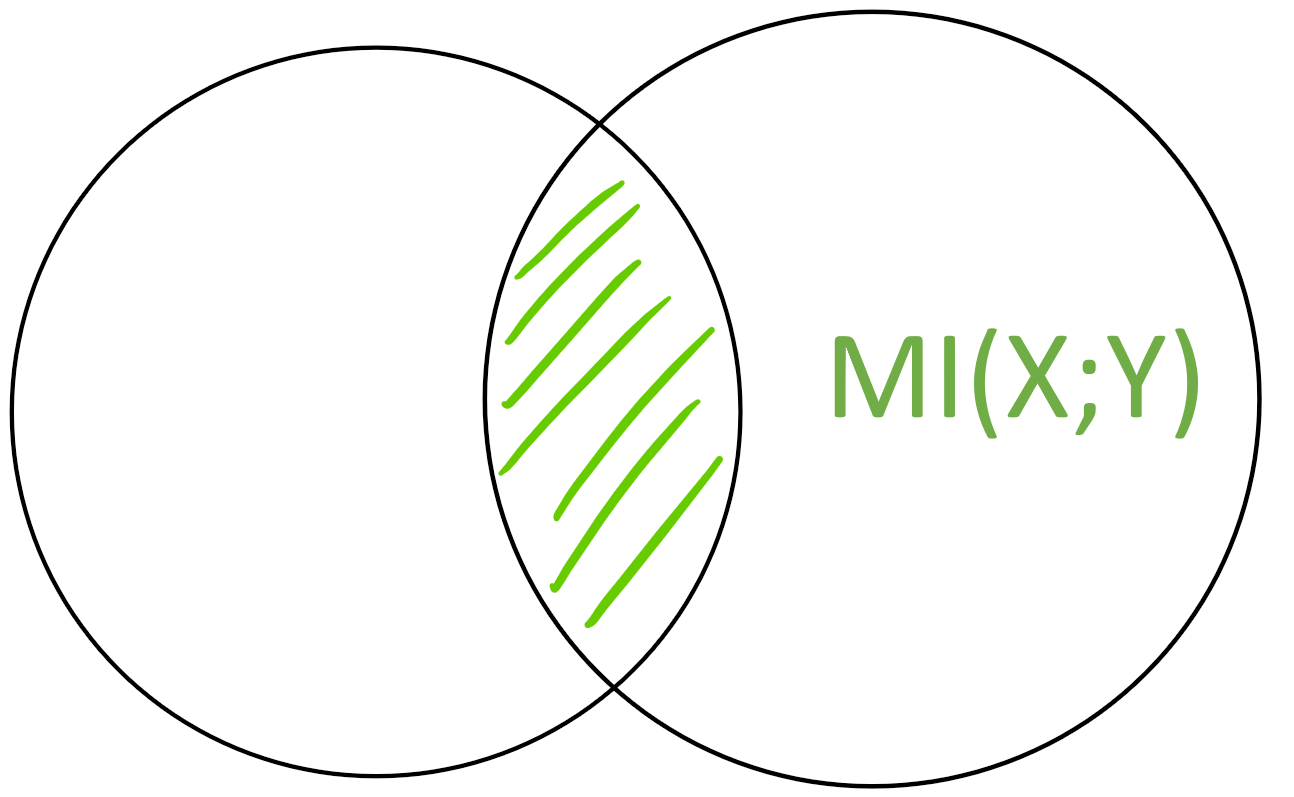
The mutual information MI(X;Y)MI(X;Y) is the “area” of the intersection X \cap YX∩Y
|
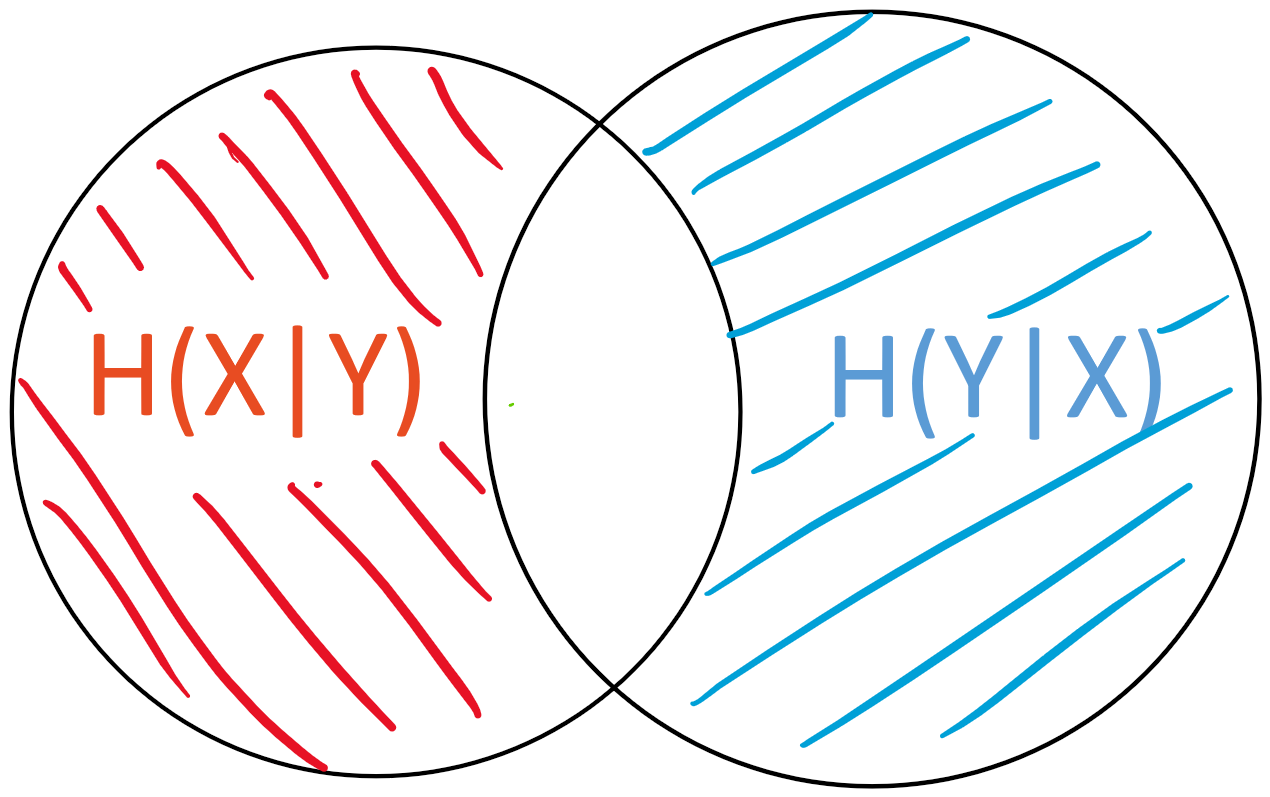
The conditional entropy H(X|Y)H(X∣Y) is the “area” of X - YX−Y
|
Benefits
This intuition allows us to create and visualize more complex expressions instead of having to rely on the more cumbersome notation used in information theory.
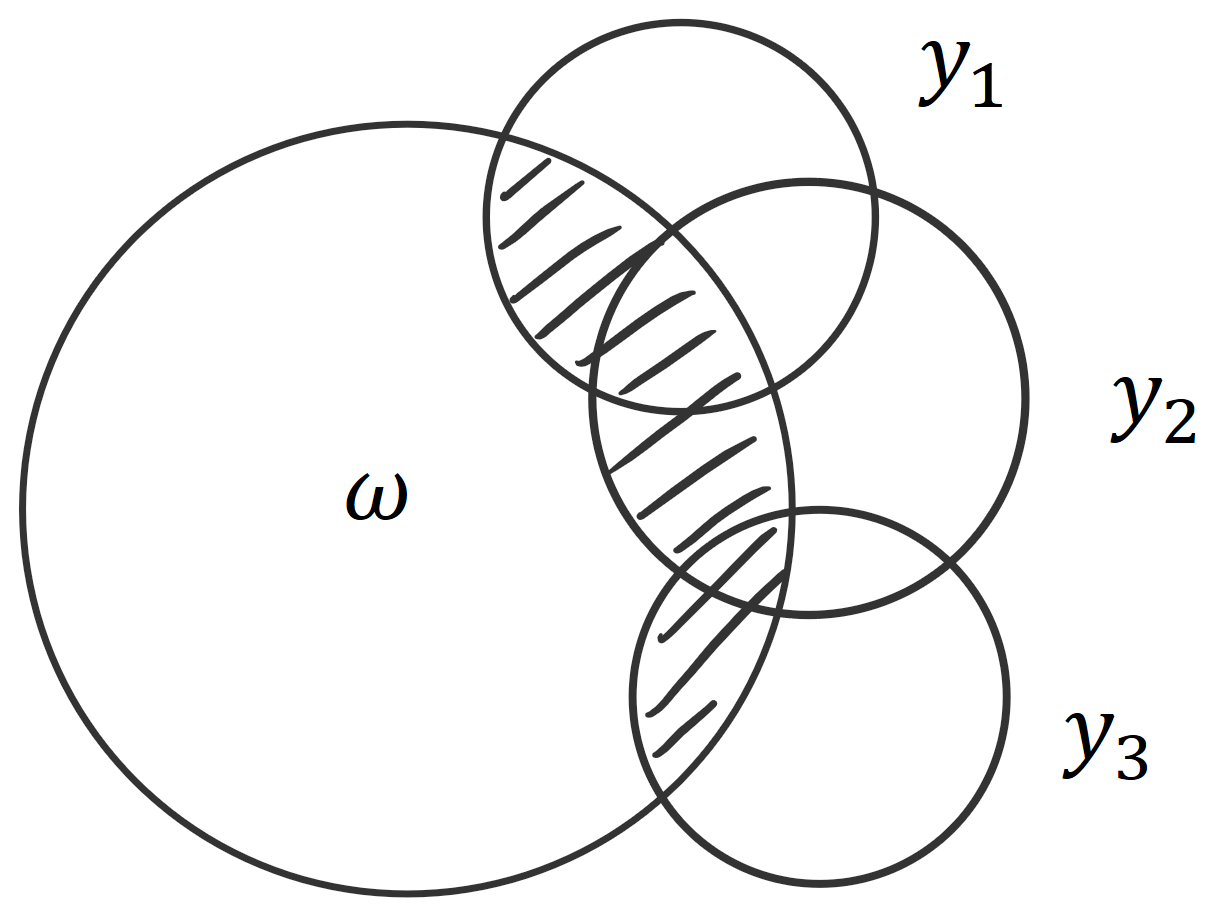 For example, BatchBALD relies on this intuition. We were looking for an information-theoretic measure that would allow us to capture the union of the predictions y_iyi intersected with the parameters \omegaω (to see why that is: read the blog post). Using an I-diagram, it’s easy to see that this is the same as the joint of all the predictions minus the joint of all the predictions conditioned on the parameters. This in turn is the same as the mutual information of the joint of predictions and the parameters:MI(y_1, y_2, y_3;\omega) = H(y_1, y_2, y_3) - H(y_1, y_2, y_3|\omega).MI(y1,y2,y3;ω)=H(y1,y2,y3)−H(y1,y2,y3∣ω).
For example, BatchBALD relies on this intuition. We were looking for an information-theoretic measure that would allow us to capture the union of the predictions y_iyi intersected with the parameters \omegaω (to see why that is: read the blog post). Using an I-diagram, it’s easy to see that this is the same as the joint of all the predictions minus the joint of all the predictions conditioned on the parameters. This in turn is the same as the mutual information of the joint of predictions and the parameters:MI(y_1, y_2, y_3;\omega) = H(y_1, y_2, y_3) - H(y_1, y_2, y_3|\omega).MI(y1,y2,y3;ω)=H(y1,y2,y3)−H(y1,y2,y3∣ω).
It is not immediately clear why this holds. However, using set operations, where \muμ signifies the area of a set, we can express the same as :\mu( (y_1 \cup y_2 \cup y_3) \cap \omega ) = \mu ( y_1 \cup y_2 \cup y_3 ) - \mu ( (y_1 \cup y_2 \cup y_3) - \omega )μ((y1∪y2∪y3)∩ω)=μ(y1∪y2∪y3)−μ((y1∪y2∪y3)−ω)From looking at the set operations, it’s clear that the left-hand side and the second term on the right-hand side together form the union:\mu( (y_1 \cup y_2 \cup y_3) \cap \omega ) + \mu ( (y_1 \cup y_2 \cup y_3) - \omega ) = \mu ( y_1 \cup y_2 \cup y_3 )μ((y1∪y2∪y3)∩ω)+μ((y1∪y2∪y3)−ω)=μ(y1∪y2∪y3)
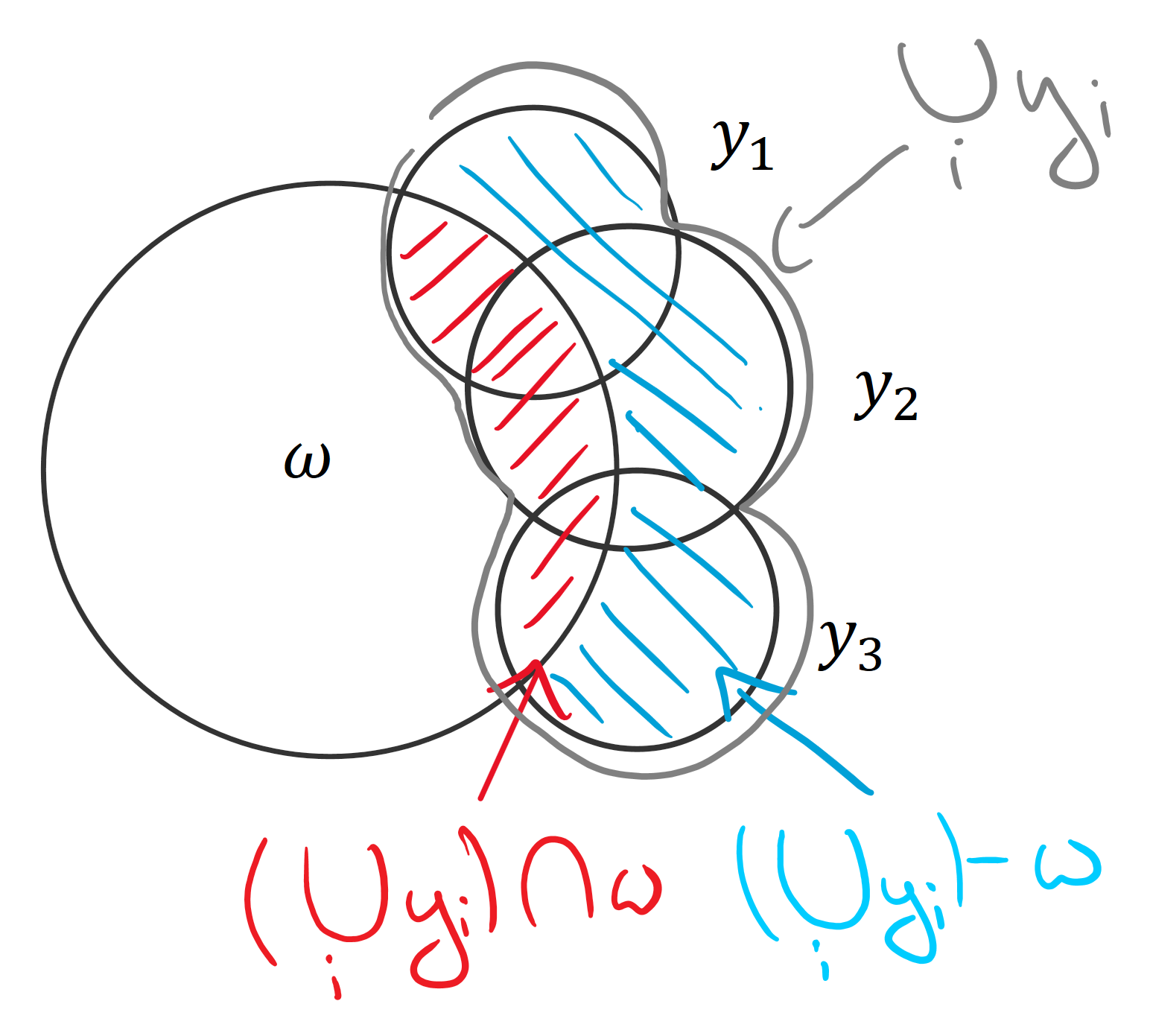 Visualizings how the terms on the left-hand side (blue and red) complement each other to form the right-hand side (gray).
Visualizings how the terms on the left-hand side (blue and red) complement each other to form the right-hand side (gray).
The equivalence can be either proven algebraically or by looking at the areas and set operations.
This is the advantage of I-diagrams.
Grounding: it’s not just an intuition—it’s true!
Yeung’s “A new outlook on Shannon’s information measures” shows that our intuition is more than just that: it is actually correct!
The paper defines a signed measure \muμ that maps any set back to the value of its information-theoretic counterpart and allows us to compute all possible set expressions for a finite number of random variables. The variables have to be discrete because differential entropy is not consistent. (This is not a weakness of the approach but a weakness of differential entropies in general.)
Using \muμ, we can write, for example:
- \mu(X \cap Y) = MI(X;Y)μ(X∩Y)=MI(X;Y),
- \mu(X \cup Y) = H(X,Y)μ(X∪Y)=H(X,Y), or
- \mu(X - Y) = H(X|Y)μ(X−Y)=H(X∣Y).
\muμ is a signed measure because the mutual information between more than two variables can be negative. This means that, while I-diagrams are correct for reading off equalities, we cannot use them to intuit about inequalities (which we could with regular Venn diagrams).
Proof sketch
The proof works by showing that we can uniquely express any set expression using a union of “atoms” that can be computed using joint entropies and then show that this is consistent with the laws of information theory. I will focus on the first part here.
Intuitively, each atom is exactly a non-overlapping area in an I-diagram.
For two variables, these atoms would be the three non-overlapping areas: H(X|Y)H(X∣Y), MI(X;Y)MI(X;Y) and H(Y|X)H(Y∣X).
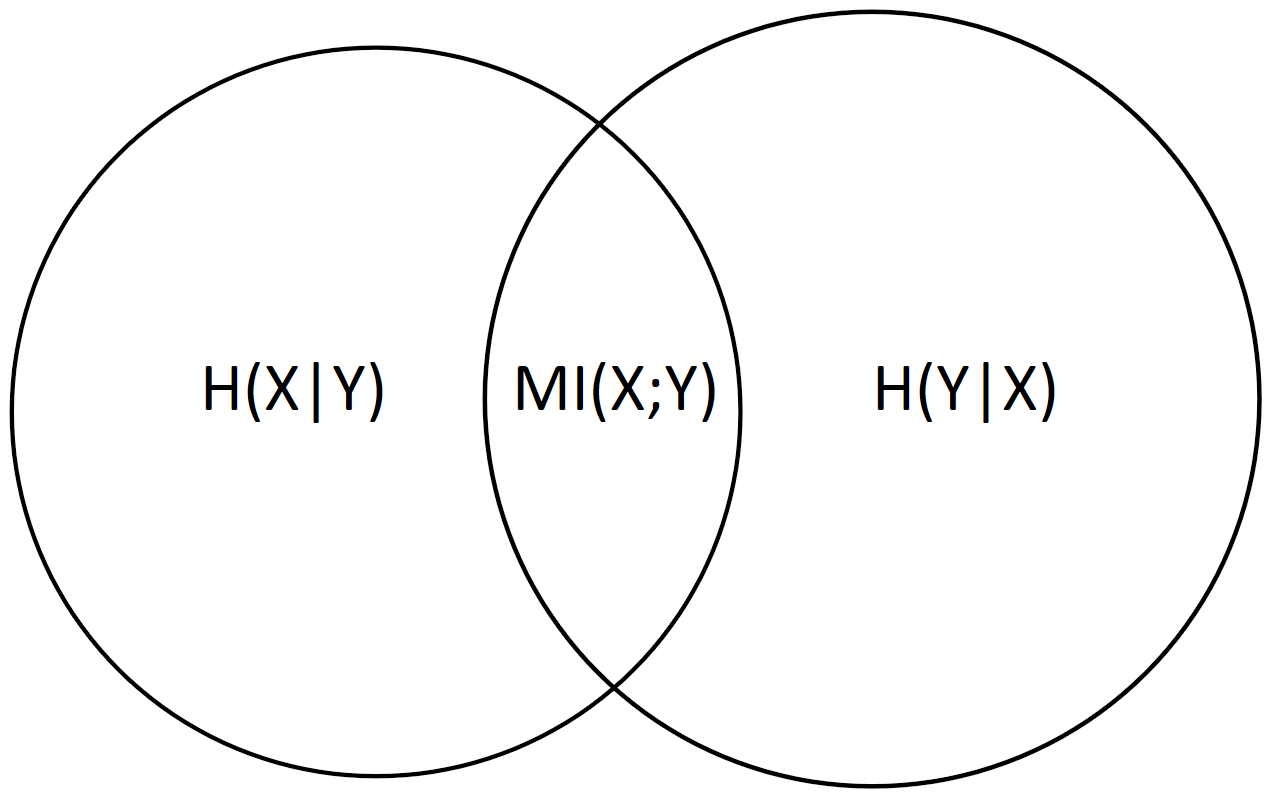
For more than two variables, it becomes more complicated, and these atoms cannot necessarily be described using simple information-theoretical expressions. However, the beauty of the proof is that it shows that the atoms can be expressed using information-theoretical values and that the values are consistent with the rules of signed measures and information theory and that there is a canonical extension of the concept of mutual information to more than two variables, which I will use below.
We can establish that given any finite set of random variables AA, BB, CC, …, we can write any set expression based on them using a union of atoms, where:
- As sets: each atom is an intersection of the variables or of some of their complements,
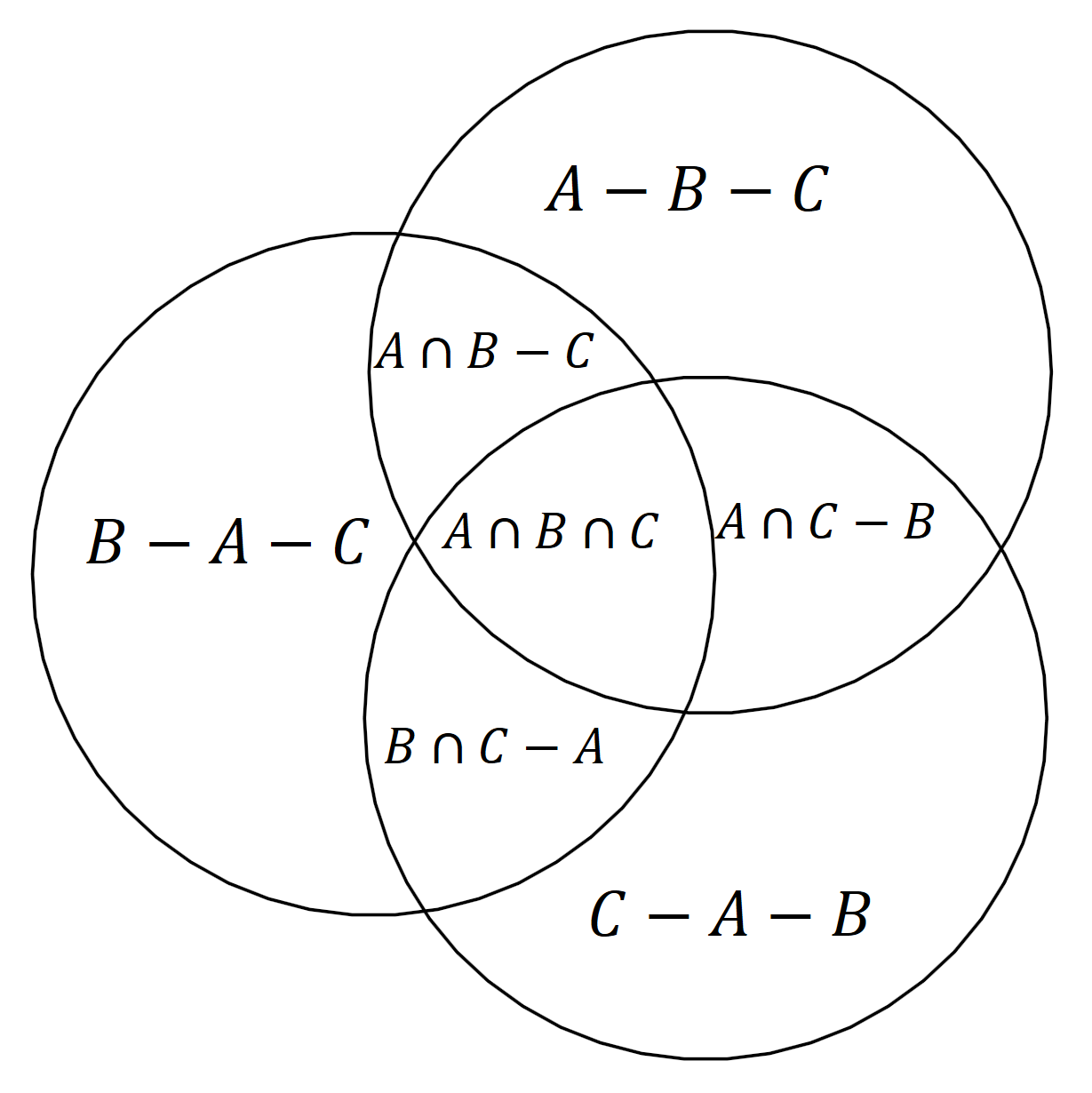 Expressing atoms using set differences and intersections.
Expressing atoms using set differences and intersections.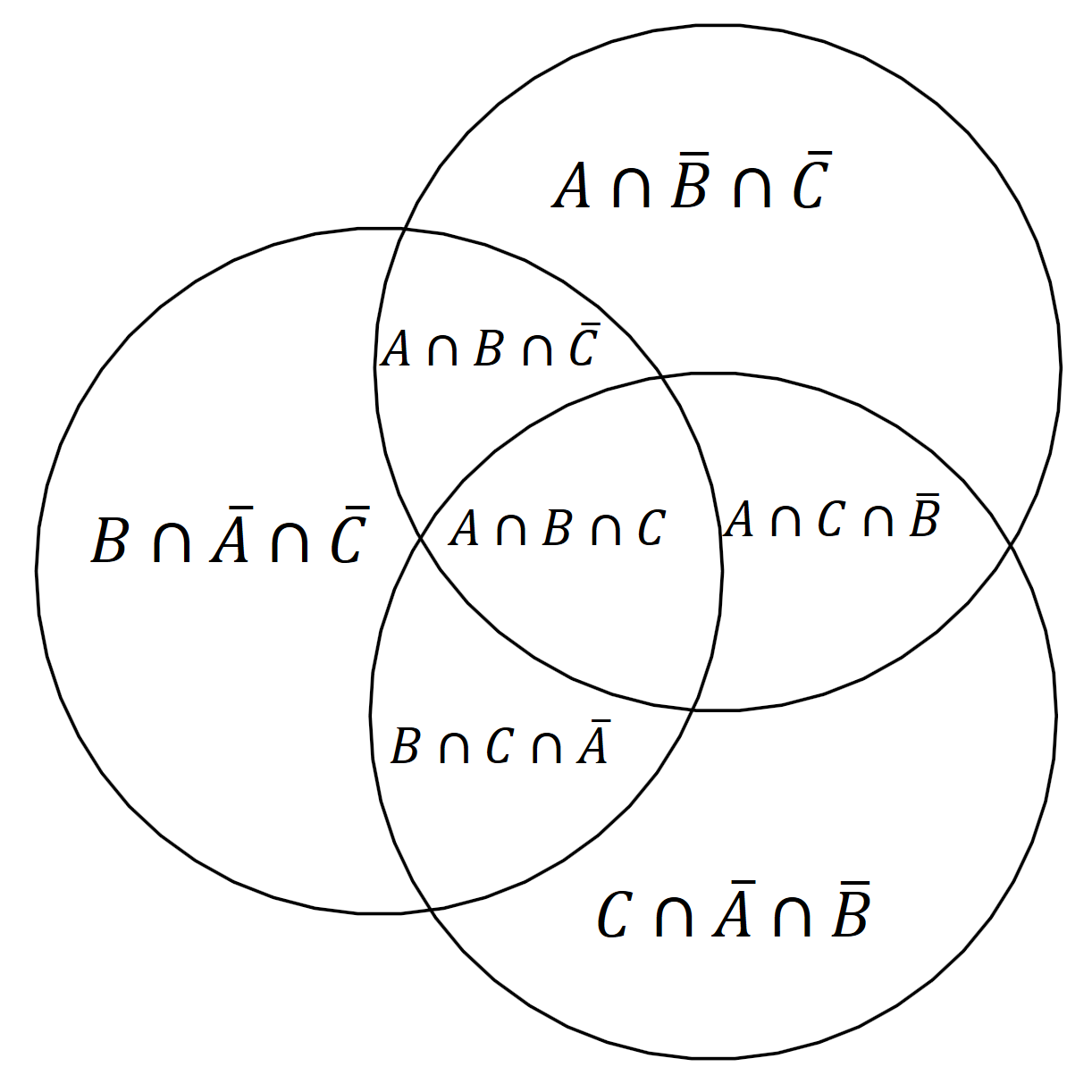 Expressing set differences using intersections and complements.
Expressing set differences using intersections and complements.
- As information-theoretic concept: each atom is a mutual information of some of the variables conditioned on the remaining variables.
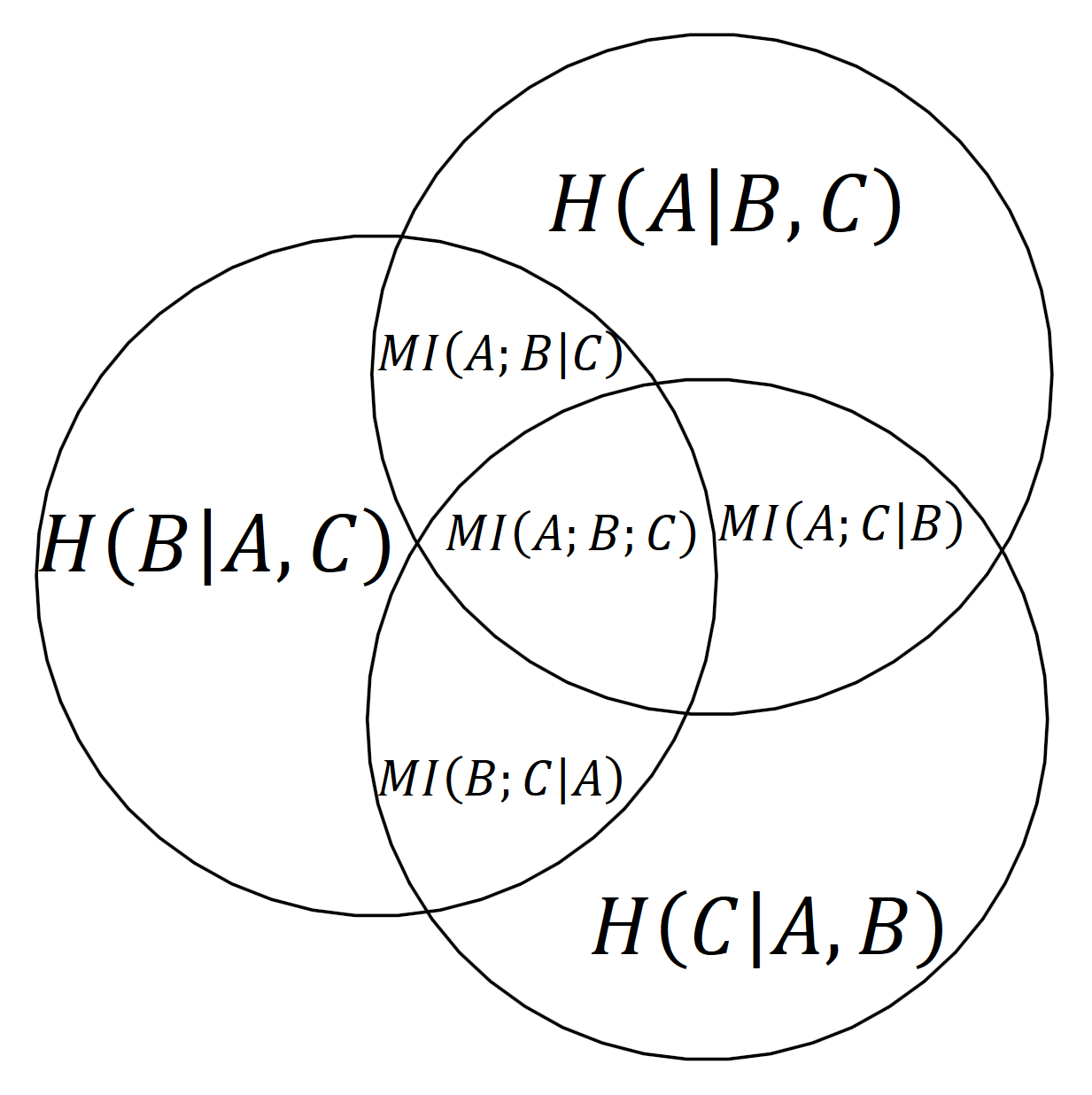 Using information-theoretic concepts
Using information-theoretic concepts
For example, we can immediately read from the diagram that the joint entropy of all three variables H(A, B, C)H(A,B,C), that is the union of all three, can be written as:
H(A, B, C) = H(A|B,C) + H(B|A,C) + H(C|A, B) + MI(A;B|C) + MI(A;C|B) + MI(B;C|A) + MI(A;B;C).H(A,B,C)=H(A∣B,C)+H(B∣A,C)+H(C∣A,B)+MI(A;B∣C)+MI(A;C∣B)+MI(B;C∣A)+MI(A;B;C).
MI(A;B;C)MI(A;B;C) is a multivariate mutual information, which is the canonical extension of the two-variable mutual information mentioned above. It can be negative, so it could happen that
MI(A;B) = MI(A;B|C) + MI(A;B;C) \le MI(A;B|C),MI(A;B)=MI(A;B∣C)+MI(A;B;C)≤MI(A;B∣C),
which can be surprising to people that are new to information theory.
How many atoms are there?
For nn variables, there are 2^n - 12n−1 such atoms as we choose for each variable if it goes into the atom as part of the mutual information or as variable to be conditioned on (so two options for each of the nn variables). The degenerate case that conditions on all variables can be excluded. Moreover, H(X) = MI(X;X)H(X)=MI(X;X).
Thus, there are 2^n - 12n−1 meaningful atoms, which yields 2^{2^n-1}22n−1 possible set expressions because each set expression can be written as union of some of the atoms, so there are two options for each atm.
How can we compute the atoms?
Every set expression is a union of some these atoms and their area is a sum where each atom contributes with a factor of 00 or 11. Such a binary combination is a special case of a linear combination.
The main idea of the proof is that whereas the atoms themselves have no easily defined information-theoretic analogue, we can look at all possible joint entropies and show that they uniquely determine these atoms.
There are 2^n - 12n−1 possible joint entropies as each variable is either part of a joint entropy or not, and we can again exclude the degenerate case without any variables.
We can express each joint entropy as a linear combination of the atoms we defined above. Using induction, one can see that these linear combinations are independent of each other. This means that the (2^n-1)\times(2^n-1)(2n−1)×(2n−1) matrix made up of these linear combinations is invertible, which allows us to solve for the atoms.
For example:
MI(A;B;C) = H(A,B,C)-H(A,B)-H(A,C)-H(B,C)+H(A)+H(B)+H(C)MI(A;B;C)=H(A,B,C)−H(A,B)−H(A,C)−H(B,C)+H(A)+H(B)+H(C)
All joint entropies are well-defined and thus we can compute the information measure of every atom, which we can use in turn to compute the information measure for any other set expression.
This proof idea is related to conjunctive and disjunctive normal forms in boolean logic. In boolean logic, every proposition can be expressed in either form. A disjunctive normal form is an OR of ANDs, which can be viewed as a UNION of INTERSECTIONS, which is exactly what we have used above to express set expressions using different atoms based.
Alternatively, this is like saying that we have two different bases for all possible set expressions: all possible joint entropies form one basis, and all possible atoms form another. The former is easier to compute and well-defined in information theory, and the latter is useful for constructing and computing new expressions, but both are equivalent.
For the actual proof and details, see the paper by Yeung.
Conclusion
I-diagrams are not just an intuition, but something we can build upon in a grounded fashion! This can provide as with another useful tool to come up with new ideas and translate them into new insights and research contributions. I hope that this was as useful to you as it was to me when I found out about it.
Please leave some feedback or share this article!
For more blog posts by OATML in Oxford, check out our group’s blog https://oatml.cs.ox.ac.uk/blog.html.
Thanks to Joost van Amersfoort, Lewis Smith and Yarin Gal for helpful comments!
Better intuition for information theory的更多相关文章
- Tree - Information Theory
This will be a series of post about Tree model and relevant ensemble method, including but not limit ...
- CCJ PRML Study Note - Chapter 1.6 : Information Theory
Chapter 1.6 : Information Theory Chapter 1.6 : Information Theory Christopher M. Bishop, PRML, C ...
- 信息熵 Information Theory
信息论(Information Theory)是概率论与数理统计的一个分枝.用于信息处理.信息熵.通信系统.数据传输.率失真理论.密码学.信噪比.数据压缩和相关课题.本文主要罗列一些基于熵的概念及其意 ...
- information entropy as a measure of the uncertainty in a message while essentially inventing the field of information theory
https://en.wikipedia.org/wiki/Claude_Shannon In 1948, the promised memorandum appeared as "A Ma ...
- 信息论 | information theory | 信息度量 | information measures | R代码(一)
这个时代已经是多学科相互渗透的时代,纯粹的传统学科在没落,新兴的交叉学科在不断兴起. life science neurosciences statistics computer science in ...
- 【PRML读书笔记-Chapter1-Introduction】1.6 Information Theory
熵 给定一个离散变量,我们观察它的每一个取值所包含的信息量的大小,因此,我们用来表示信息量的大小,概率分布为.当p(x)=1时,说明这个事件一定会发生,因此,它带给我的信息为0.(因为一定会发生,毫无 ...
- 决策论 | 信息论 | decision theory | information theory
参考: 模式识别与机器学习(一):概率论.决策论.信息论 Decision Theory - Principles and Approaches 英文图书 What are the best begi ...
- The basic concept of information theory.
Deep Learning中会接触到的关于Info Theory的一些基本概念.
- [Basic Information Theory] Writen Notes
随机推荐
- APS系统的现状以及与MES系统的关联
MES是智能工厂的核心,将前端产品设计.工艺定义阶段的产品数据管理与后端制造阶段的生产数据管理融合,实现产品设计.生产过程.维修服务闭环协同全生命周期管理. APS就是高级计划排程 应该说APS本来是 ...
- byte[],File和InputStream的相互转换
File.FileInputStream 转换为byte[] File file = new File("test.txt"); InputStream input = new F ...
- Jvm调优积累的文章
Linux查看CPU和内存使用情况 stat命令查看jvm的GC情况 (以Linux为例) jvm优化必知系列——监控工具 Java JVM 参数设置大全
- Mycat配置项详解
schema.xml文件配置中的balance属性和writeType属性: . balance=", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上. . ba ...
- Office--CVE-2017-11882【远程代码执行】
Office远程代码执行漏洞现POC样本 最近这段时间CVE-2017-11882挺火的.关于这个漏洞可以看看这里:https://www.77169.com/html/186186.html 今天在 ...
- 使用salt-stack指定IP添加系统用户为root的权限
指定多台要授权的用户,指定root权限 salt -L '192.168.3.212' cmd.run 'useradd fengniao -u 2000' salt -L '192.168.3.21 ...
- Unity 渲染教程(四):第一个光源
将法线从物体空间转换到世界空间. 使用方向光. 计算漫反射和镜面高光反射. 实现能量守恒. 使用金属的工作流程. 利用Unity的基于物理规则渲染的算法. 这是关于渲染基础的系列教程的第四部分.前面的 ...
- datetime,Timestamp和datetime64之间转换
引入工具包 import datetime import numpy as np import pandas as pd 总览 from IPython.display import Image fr ...
- adb命令篇
前言 Android的adb提供了很多命令,功能很强大,可以为开发和调试带来很大的便利.当然本文并不是介绍各种命令的文章,而是用于记录在平时工作中需要经常使用的命令,方便平时工作时使用,所以以后 ...
- JPA 报错:Page 2 of 1 containing UNKNOWN instances
JPA 中,page是从0开始,不是从1开始: 因此,将用户输入的从1开始的page页码减1: PageRequest pageRequest = PageRequest.of(page - 1, p ...