ELK Stack部署
部署ELK Stack
官网:https://www.elastic.co
环境准备:
| ip | hostname | 服务 | 用户、组 |
|---|---|---|---|
| 192.168.20.3 | node2003 | kibana6.5,filebeat | es |
| 192.168.20.4 | node2004 | elasticsearch 6.5,jdk8 | es |
| 192.168.20.5 | node2005 | elasticsearch 6.5,jdk8 | es |
| 192.168.20.6 | node2006 | elasticsearch 6.5,jdk8 | es |
| 192.168.20.7 | node2007 | logstash-6.5,jdk8 | es |
一、安装elasticsearch cluster
node2004:
~]# pwd
/usr/local/pkg/
~]# ll
-rw-r--r-- 1 root root 113320120 Dec 21 05:10 elasticsearch-6.5.2.tar.gz
-rw-r--r-- 1 root root 191753373 Dec 21 05:10 jdk-8u191-linux-x64.tar.gz
~]# tar xf jdk-8u191-linux-x64.tar.gz
~]# mv jdk1.8.0_191/ jdk8
~]# tar xf elasticsearch-6.5.2.tar.gz
~]# mv elasticsearch-6.5.2 elasticsearch
~]# cd elasticsearch
~]# mkdir data //用于存放数据,可挂载一个专门的数据存储
~]# useradd es
~]# chown -R es.es /usr/local/pkg/elasticsearch /usr/local/pkg/jdk8 //给这两个目录赋权限,程序只使用es用户维护
编辑配置文件
~]# vim config/elasticsearch.yml
cluster.name: myes
确保不要在不同的环境中重用相同的群集名称,否则最终会导致节点加入错误的集群。cluster.name的值来区分不同的集群。node.name: ${HOSTNAME}
给每个节点设置一个有意义的、清楚的、描述性的名字。node.master: true
用于指定该节点是否竟争主节点,默认为true。node.data: false
用于指定节点是否存储数据,默认为true。node.ingest: true
数据预处理功能。类似于logstash的功能。path.data: /usr/local/pkg/elasticsearch/data
数据存储目录,建议使用单独挂载的存储。path.logs: /usr/local/pkg/elasticsearch/logs
日志存储目录bootstrap.memory_lock: true
设置为true时,程序尝试将进程地址空间锁定到RAM中,从而防止任何elasticsearch内存被换出。 官方的说法是:交换对性能,节点稳定性非常不利,应该不惜一切代价避免,它可能导致垃圾收集持续数分钟而不是毫秒,并且可能导致节点响应慢甚至断开与集群的连接。
注:如果尝试分配的内存超过可用内存,可能会导致JVM和shell会话退出!
network.host: 192.168.20.4
对外网关IPhttp.port: 9200
对外数据端口discovery.zen.ping.unicast.hosts: ["192.168.20.4:9300", "192.168.20.5:9300","192.168.20.6:9300"]
集群内节点的信息,集群内通信使用tcp9300端口。discovery.zen.minimum_master_nodes: 2
discovery.zen.minimum_master_nodes设定对你的集群的稳定非常重要。当你的集群中有两个master时,这个配置有助于防止脑裂,一种两个主节点同时存在于一个集群的现象。
如果你的集群发生了脑裂,那么你的集群就会处在丢失数据的危险中,因为主节点被认为是这个集群的最高统冶者,它决定了什么时候新的索引可以创建,分片是如何移动的等等。如果你有两个master节点,你的数据的完整性将得不到保证,因为你有两个节点认为他们有集群的控制权。
这个配置就是告诉elasticsearch当没有足够的master候选节点的时候,就不要进行master节点选举,等master候选节点足够了才进行选举。
此值设置应该被配置为master候选节点的法定个数(大多数个)。法定个数就是 "(master候选节点/2)+1"。
如果你有10个节点(都能保存数据,1个master9个候选master),法定个数就是6
如果你有两个节点,法定个数为2,但是这意味着如果一个节点挂掉,你整个集群就不可用了。设置成1可以保证集群的功能,但是就无法保证集群脑裂。所以,至少保证是奇数个节点。
注: 这里的选举知识可参考经典的 paxos 协议。
gateway.recover_after_nodes: 2
集群中多少个节点启动后,才允许进行恢复处理。只有在重启时才会使用这里的配置。假如你有3个节点(都存数据),其中一个主节点。这时你需要将集群离线维护。维护好后将3台机器重启,有两台非master机器先启动好了,master机器无法启动。那这时先启动好的两机器等待一个时间周期后,重新选举。选举后新的master发现数据不再均匀分布。因为其中一个机器的数据丢失了,所以他们之间会立即启动分片复制。这里值的设定看个人喜好,如果有几个节点就设几的话,就失去选举功能了,并且一但master宕机,不修复就无法对外提供服务的可能。action.destructive_requires_name: true
用于删除索引时需要明确给出索引名称,默认为true
这里的配置只是其中一部分,详细配置请参考官方说明:https://www.elastic.co/guide/cn/elasticsearch/guide/current/important-configuration-changes.html
修改系统变量
1 文件描述符:
编辑/etc/security/limits.conf文件为特定用户设置持久限制。要将用户的最大打开文件数设置elasticsearch为65535,服务启动前添加如下配置:
~]# echo "es - nofile 65535" >> /etc/security/limits.conf
2 虚拟内存:
Elasticsearch mmapfs默认使用目录来存储其索引。mmap计数的默认操作系统限制可能太低,这可能导致内存不足异常。
添加如下配置,并重启后生效
~]# echo "vm.max_map_count = 262144" >> /usr/lib/sysctl.d/50-default.conf
3 线程数:
Elasticsearch为不同类型的操作使用了许多线程池。重要的是它能够在需要时创建新线程。确保Elasticsearch用户可以创建的线程数至少为4096。服务启动前添加如下配置:
~]# echo "es - nproc 4096" >> /etc/security/limits.conf
启动服务脚本
[Unit]
Description=Elasticsearch
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
PrivateTmp=true
Environment=ES_HOME=/usr/local/pkg/elasticsearch
Environment=ES_PATH_CONF=/usr/local/pkg/elasticsearch/config
Environment=PID_DIR=/var/run/elasticsearch
WorkingDirectory=/usr/local/pkg/elasticsearch
User=es
Group=es
ExecStart=/usr/local/pkg/elasticsearch/bin/elasticsearch
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
elasticsearch需要jdk8,防止系统内其它版本混乱,可在启动脚本中添加相应环境变量
~]# vim /usr/local/pkg/elasticsearch/bin/elasticsearch
#!/bin/bash
# CONTROLLING STARTUP:
#
# This script relies on a few environment variables to determine startup
# behavior, those variables are:
#
# ES_PATH_CONF -- Path to config directory
# ES_JAVA_OPTS -- External Java Opts on top of the defaults set
#
# Optionally, exact memory values can be set using the `ES_JAVA_OPTS`. Note that
# the Xms and Xmx lines in the JVM options file must be commented out. Example
# values are "512m", and "10g".
#
# ES_JAVA_OPTS="-Xms8g -Xmx8g" ./bin/elasticsearch
ES_PATH_CONFIG=/usr/local/pkg/elasticsearch/config
export JAVA_HOME=/usr/local/pkg/jdk8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
//在启动脚本前添加jdk环境变量,这样程序专门指定相应jdk
**启动服务:**
```
~]# systemctl daemon-reload
~]# systemctl start elasticsearch.service
~]# ps -ef | grep ela //查看进程
root 10806 10789 0 09:54 pts/1 00:00:00 vim bin/elasticsearch
es 11635 1 3 10:35 ? 00:00:26 /usr/local/pkg/jdk8/bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch.hTwfw2vY -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=logs/hs_err_pid%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:logs/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m -Des.path.home=/usr/local/pkg/elasticsearch -Des.path.conf=/usr/local/pkg/elasticsearch/config -Des.distribution.flavor=default -Des.distribution.type=tar -cp /usr/local/pkg/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch
es 11688 11635 0 10:35 ? 00:00:00 /usr/local/pkg/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller
root 12281 12141 0 10:46 pts/4 00:00:00 grep --color=auto ela
查看日志输出情况
~]# tail -f /usr/local/pkg/elasticsearch/logs/myes.log
[2018-12-22T10:19:54,669][INFO ][o.e.e.NodeEnvironment ] [node2004] using [1] data paths, mounts [[/ (rootfs)]], net usable_space [43.1gb], net total_space [45gb], types [rootfs]
[2018-12-22T10:19:54,672][INFO ][o.e.e.NodeEnvironment ] [node2004] heap size [1007.3mb], compressed ordinary object pointers [true]
[2018-12-22T10:19:54,673][INFO ][o.e.n.Node ] [node2004] node name [node2004], node ID [TN_N06ovT8ufWPkOYR0Esg]
[2018-12-22T10:19:54,674][INFO ][o.e.n.Node ] [node2004] version[6.5.2], pid[10935], build[default/tar/9434bed/2018-11-29T23:58:20.891072Z], OS[Linux/3.10.0-862.el7.x86_64/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_191/25.191-b12]
[2018-12-22T10:19:54,674][INFO ][o.e.n.Node ] [node2004] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=/tmp/elasticsearch.z1Ja46qO, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -XX:+PrintGCDetails, -XX:+PrintGCDateStamps, -XX:+PrintTenuringDistribution, -XX:+PrintGCApplicationStoppedTime, -Xloggc:logs/gc.log, -XX:+UseGCLogFileRotation, -XX:NumberOfGCLogFiles=32, -XX:GCLogFileSize=64m, -Des.path.home=/usr/local/pkg/elasticsearch, -Des.path.conf=/usr/local/pkg/elasticsearch/config, -Des.distribution.flavor=default, -Des.distribution.type=tar]
[2018-12-22T10:19:56,833][INFO ][o.e.p.PluginsService ] [node2004] loaded module [aggs-matrix-stats]
...
[2018-12-22T10:20:03,620][INFO ][o.e.n.Node ] [node2004] initialized
[2018-12-22T10:20:03,620][INFO ][o.e.n.Node ] [node2004] starting ...
[2018-12-22T10:20:03,762][INFO ][o.e.t.TransportService ] [node2004] publish_address {192.168.20.4:9300}, bound_addresses {192.168.20.4:9300}
[2018-12-22T10:20:03,783][INFO ][o.e.b.BootstrapChecks ] [node2004] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2018-12-22T10:20:06,829][WARN ][o.e.d.z.ZenDiscovery ] [node2004] not enough master nodes discovered during pinging (found [[Candidate{node={node2004}{TN_N06ovT8ufWPkOYR0Esg}{SCIJSvtyTQOp9XOfBQiTsw}{192.168.20.4}{192.168.20.4:9300}{ml.machine_memory=3974492160, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true}, clusterStateVersion=-1}]], but needed [2]), pinging again
[2018-12-22T10:20:09,830][WARN ][o.e.d.z.ZenDiscovery ] [node2004] not enough master nodes discovered during pinging (found [[Candidate{node={node2004}{TN_N06ovT8ufWPkOYR0Esg}{SCIJSvtyTQOp9XOfBQiTsw}{192.168.20.4}{192.168.20.4:9300}{ml.machine_memory=3974492160, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true}, clusterStateVersion=-1}]], but needed [2]), pinging again
//因为另外两个节点没有启动,所以服务无法发现,也就无法对外提供服务。
####配置node2005和node2006:
修改`network.host:`为本机IP,`node.master`和`node.data`都为true。其它配置不变,并启动。
<br />
查看nood2005机器的日志:
~]# tail -f /usr/local/pkg/elasticsearch/logs/myes.log
[2018-12-23T22:22:52,880][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-monitoring]
[2018-12-23T22:22:52,880][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-rollup]
[2018-12-23T22:22:52,880][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-security]
[2018-12-23T22:22:52,880][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-sql]
[2018-12-23T22:22:52,881][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-upgrade]
[2018-12-23T22:22:52,881][INFO ][o.e.p.PluginsService ] [node2005] loaded module [x-pack-watcher]
[2018-12-23T22:22:52,881][INFO ][o.e.p.PluginsService ] [node2005] no plugins loaded
[2018-12-23T22:22:57,405][INFO ][o.e.x.s.a.s.FileRolesStore] [node2005] parsed [0] roles from file [/usr/local/pkg/elasticsearch/config/roles.yml]
[2018-12-23T22:22:57,875][INFO ][o.e.x.m.j.p.l.CppLogMessageHandler] [node2005] [controller/3587] [Main.cc@109] controller (64 bit): Version 6.5.2 (Build 767566e25172d6) Copyright (c) 2018 Elasticsearch BV
[2018-12-23T22:22:58,612][DEBUG][o.e.a.ActionModule ] [node2005] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security
[2018-12-23T22:22:58,894][INFO ][o.e.d.DiscoveryModule ] [node2005] using discovery type [zen] and host providers [settings]
[2018-12-23T22:22:59,737][INFO ][o.e.n.Node ] [node2005] initialized
[2018-12-23T22:22:59,738][INFO ][o.e.n.Node ] [node2005] starting ...
[2018-12-23T22:22:59,879][INFO ][o.e.t.TransportService ] [node2005] publish_address {192.168.20.5:9300}, bound_addresses {192.168.20.5:9300}
[2018-12-23T22:22:59,900][INFO ][o.e.b.BootstrapChecks ] [node2005] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2018-12-23T22:23:03,259][INFO ][o.e.c.s.ClusterApplierService] [node2005] detected_master {node2006}{2iH5BLMbT3eTi6Tm8ysyNg}{zQkibzjOQk-jbe2cZNOiow}{192.168.20.6}{192.168.20.6:9300}{ml.machine_memory=3974492160, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}, added {{node2006}{2iH5BLMbT3eTi6Tm8ysyNg}{zQkibzjOQk-jbe2cZNOiow}{192.168.20.6}{192.168.20.6:9300}{ml.machine_memory=3974492160, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true},{node2004}{TN_N06ovT8ufWPkOYR0Esg}{4RjuzapkTs2Gy5q8bZGIkQ}{192.168.20.4}{192.168.20.4:9300}{ml.machine_memory=3974492160, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true},}, reason: apply cluster state (from master [master {node2006}{2iH5BLMbT3eTi6Tm8ysyNg}{zQkibzjOQk-jbe2cZNOiow}{192.168.20.6}{192.168.20.6:9300}{ml.machine_memory=3974492160, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true} committed version [23]])
//从上一条日志可以得到node2005通过连接查询得到node2006为master,并且与node2005机器进行了友好通信
[2018-12-23T22:23:03,533][WARN ][o.e.x.s.a.s.m.NativeRoleMappingStore] [node2005] Failed to clear cache for realms [[]]
[2018-12-23T22:23:03,537][INFO ][o.e.x.s.a.TokenService ] [node2005] refresh keys
[2018-12-23T22:23:03,893][INFO ][o.e.x.s.a.TokenService ] [node2005] refreshed keys
[2018-12-23T22:23:03,934][INFO ][o.e.l.LicenseService ] [node2005] license [4c39dc4c-1abb-4b60-bcd8-eed218f217b5] mode [basic] - valid
[2018-12-23T22:23:03,966][INFO ][o.e.x.s.t.n.SecurityNetty4HttpServerTransport] [node2005] publish_address {192.168.20.5:9200}, bound_addresses {192.168.20.5:9200}
[2018-12-23T22:23:03,967][INFO ][o.e.n.Node ] [node2005] started
这时候elasticsearch cluster已经建立OK,接下来就可以安装kibana和logstash以及filebeat。
##二、 安装kibana
**配置kibana.yml**
//解压
~]# cd /usr/local/pkg/
~]# tar xf kibana-6.5.2-linux-x86_64.tar.gz
~]# mv kibana-6.5.2-linux-x86_64 kibana
~]# cd kibana
~]# vim /etc/profile.d/kibana.sh //添加环境变量
export PATH=/usr/local/pkg/kibana/bin:$PATH
~]# source /etc/profile.d/kibana.sh
//编辑
~]# vim config/kibana.yml
...
配置文件中重要参数含义:
* `server.port: 5601`
默认端口号:5601
* `server.host: "localhost"`
默认值:"localhost",即指定后端服务器的主机地址
* `elasticsearch.url: "http://192.168.20.4:9200"`
用来处理所有查询的elasticsearch实例的URL。
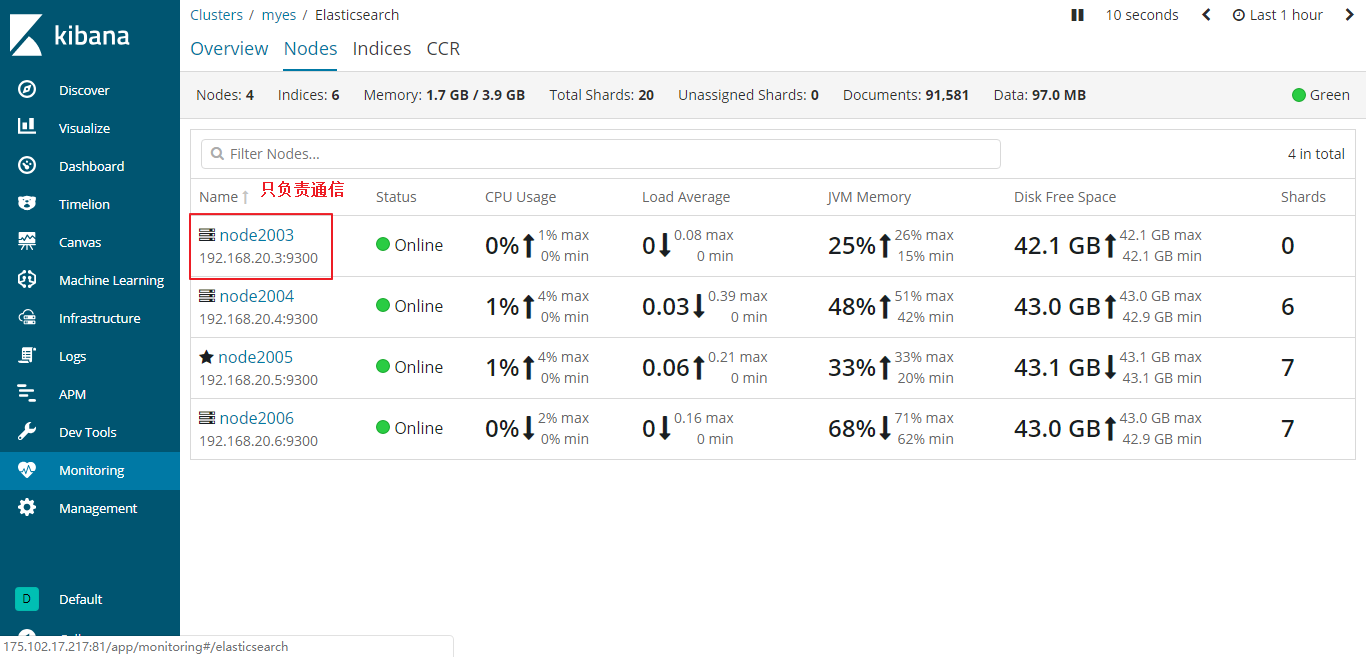
>这里的elasticsearch.url只能填写一个url,那这里该怎么连接es cluster呢?根据官方可出的解决方法,可以在kibana主机上部署一个elasticsearch只做通信,只需要把`node.data:false`,`node.master:false`,`node.ingest:false` 其它配置一样即可。
* `server.name: "node2003"
kibana实例对外展示的名称
* `kibana.index: ".kibana"`
kibana使用elasticsearch中的索引来存储保存的检索,可视化控件以及仪表板。如果没有索引,kibana会创建一个新的索引
* `tilemap.url:`
用来在地图可视化组件中展示地图服务的URL。可使用自己的地图地址。如高德地图URL:'http://webrd02.is.autonavi.com/appmaptile?lang=zh_cn&size=1&scale=1&style=7&x={x}&y={y}&z={z}'
* `elasticsearch.username:`和`elasticsearch.password:`
elasticsearch设置了基本的权限认证,该配置提供了用户名和密码,用于kibana启动时维护索引。
* `server.ssl.enabled: false`、`server.ssl.certificate: `、`server.ssl.key: `
对到浏览器端的请求启用SSL,设为true时,server.ssl.certificat和server.ssl.key也要设置。
* `elasticsearch.ssl.certificate: `、`elasticsearch.ssl.key: `
可配置选项,提供PEM格式SSL证书和密钥文件的路径。这些文件确保elasticsearch后端使用同校样的密钥文件。
* `elasticsearch.pingTimeout:`
elasticsearch ping状态的响应时间,判断elasticsearch状态
* `elasticsearch.requestTimeout:`
elasticsearch响应时间,单位毫秒。
* `elasticsearch.shardTimeout :`
等待来自分片的响应时间(以毫秒为单位)。0为禁用
* `elasticsearch.startupTimeout:`
kibana启动时等待elasticsearch的时间。
* `elasticsearch.logQueries: false`
记录发送到时elasticsearch的查询。
* `pid.file: /var/run/kibana.pid`
指定kibana的进程ID文件的路径
* `logging.dest: /usr/local/pkg/kibana/logs/kibana.log`
指定输出的方式。stdout标准输出,也可/path/to/xxx.log输出至文件中
* `logging.silent: false`
是否输出日志,true为不输出日志,false为输出日志
* `logging.quiet: true`
静默模式,禁止除错误外的所有日志输出。
* `logging.verbose: false`
记下的所有事件包括系统使用信息和所有请求的日志。
* `ops.interval`
设置采样系统和流程性能的时间间隔,最小值为100(单位毫秒)
* `i18n.locale: "zh_CN"
使用中文输出,可不是汉化,详细信息github上有。
**启动服务脚本**
~]# cat /usr/lib/systemd/system/kibana.service
[Unit]
Description=Kibana
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=simple
PIDFile=/var/run/kibana.pid
User=es
Group=es
Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
Prefixing the path with '-' makes it try to load, but if the file doesn't
exist, it continues onward.
EnvironmentFile=-/usr/local/pkg/kibana/config/kibana
ExecStart=/usr/local/pkg/kibana/bin/kibana serve
Restart=always
WorkingDirectory=/usr/local/pkg/kibana
[Install]
WantedBy=multi-user.target
**启动**
kibana]# systemctl daemon-reload
kibana]# mkdir logs
kibana]# useradd es
kibana]# chown -R es.es /usr/local/pkg/kibana
kibana]# systemctl start kibana.service
//查看日志,如果没有日志则说明正常启动,因为配置文件中禁止正常日志输出了,只允许错误日志输出。测试时建议打开。
kibana]# tail -f /usr/local/pkg/kibana/log/kibana.log
....
##三、安装filebeat
> 轻量采集器,将各种所需要的数据采集后发送给各种存储或直接发送给数据处理工具(logstash,es)。占用资源量小。
~]# cd /usr/local/pkg/
~]# tar xf filebeat-6.5.2-linux-x86_64.tar.gz && mv filebeat-6.5.2-linux-x86_64 filebeat
~]# vim filebeat/filebeat.yml //这里的配置文件就简单说下,具体如何配置以实现自己想要的功能,可参考官网较好。
- type: log
//类型logChange to true to enable this input configuration.
enabled: true
//打开input配置Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/access.log
- c:\programdata\elasticsearch\logs*
//读取日志的路径,可使用通配符匹配
....
----------------------------- Logstash output --------------------------------
output.logstash:
The Logstash hosts
hosts: ["node2007:5044"]
//输出至logstash上,进行深度处理
....
~]# mkdir filebeat/logs
~]# chown -R es.es /usr/local/pkg/filebeat
2. 添加启动脚本
~]# vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=filebeat
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=simple
PIDFile=/usr/local/pkg/filebeat/filebeat.pid
User=es
Group=es
ExecStart=/usr/local/pkg/filebeat/filebeat -c /usr/local/pkg/filebeat/filebeat.yml
Restart=always
WorkingDirectory=/usr/local/pkg/filebeat
[Install]
WantedBy=multi-user.target
~]# systemctl daemon-reload
~]# systemctl start filebeat
##四、安装logstash
>Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据。
logstash配置文件简单解释:
~]# cd /usr/local/pkg/
~]# tar xf jdk-8u191-linux-x64.tar.gz
~]# mv jdk1.8.0_191/ jdk8
~]# tar xf logstash-6.5.2.tar.gz
~]# mv logstash-6.5.2 logstash
~]# vim logstash/config/logstash.yml
node.name: test
//默认:机器主机名
path.data: /usr/loca/pkg/logstash/data
//存储相关数据
pipeline.id: main
//管道的ID
pipeline.workers: 2
//并行执行的管道数量,默认主机CPU核心数(处理能力,类似nginx worker)。
pipeline.batch.size: 125
//每次input数量
pipeline.batch.delay: 50
//分发batch到filters和workers之间最长等待的时间。
pipeline.unsafe_shutdown: false
//和kill pid 与kill -9 pid 一个意思。就是当关闭进程时,如果进程手头上还有事做,那就让其做完,在关闭。如果为true,就是说关闭不管手头有没有事情在做都强制关闭。建议默认false即可。
path.config: /usr/local/pkg/logstash/conf.d/*.conf
//配置文件或文件夹,可使用通配符,配置文件顺序按字母顺序读取
config.test_and_exit: false
//启动时检查配置文件是否有效并退出。grok patterns不会被检查。默认false
config.reload.automatic: false
//设置为true时,会周期性检查配置是否发生了更改并reload,也可手动发送SIGHUP信号来reload
config.reload.interval: 3s
//重读配置间隔,默认3秒
config.debug: false
//设置为true,会显示所有debug日志(同时开启log.level:debug才生效)。注意:为true会将传递给插件的密码显示出来。
config.support_escapes: false
//设置为true时,将支持\n,\r,\t,\,,",'转义
------------ Module Settings ---------------
modules:
- name: MODULE_NAME
var.PLUGINTYPE1.PLUGINNAME1.KEY1: VALUE
var.PLUGINTYPE1.PLUGINNAME1.KEY2: VALUE
var.PLUGINTYPE2.PLUGINNAME1.KEY1: VALUE
var.PLUGINTYPE3.PLUGINNAME3.KEY1: VALUE
Module variable names must be in the format of
var.PLUGIN_TYPE.PLUGIN_NAME.KEY
modules:
//配置模块如上格式
------------ Queuing Settings --------------
queue.type: memory
//用于事件缓冲的内部队列,memory保存在内存中,persisted持久是基于磁盘的队列。
path.queue:
//如果queue.type: persisted,则这里需要给定路径存储
queue.page_capacity: 64mb
//启用持久队列时使用的的页面数据文件大小。
queue.max_events: 0
//启用持久队列时队列中未读事件的最大数量为0(无限制)
queue.max_bytes: 1024mb
//队列的总容量
queue.checkpoint.acks: 1024
//启用持久队列时强制检查点最大ack,0为无限制
queue.checkpoint.writes: 1024
//启用持久队列时强制检查点之前写入的最大数量。0为无限制
queue.checkpoint.interval: 1000
//检查间隔
------------ Dead-Letter Queue Settings --------------
dead_letter_queue.enable: false
dead_letter_queue.max_bytes: 1024mb
path.dead_letter_queue:
//死信队列(Dead Letter Queue)本质上同普通的Queue没有区别,只是它的产生是为了隔离和分析其他Queue(源Queue)未成功处理的消息。
------------ Metrics Settings --------------
http.host: "127.0.0.1"
//标准REST端点的绑定地址
http.port: 9600-9700
//标准REST端点绑定端口
------------ Debugging Settings --------------
Options for log.level:
* fatal
* error
* warn
* info (default)
* debug
* trace
log.level: info
path.logs:
//日志级别,默认info
------------ Other Settings --------------
Where to find custom plugins
path.plugins: []
//自定义插件
startup.options配置文件简单解释:
~]# vim logstash/config/startup.options
JAVACMD=/usr/local/pkg/jdk8/bin/java
//本地jdk
LS_HOME=/usr/local/pkg/logstash
//logstash所在目录
LS_SETTINGS_DIR=/usr/local/pkg/logstash/config
//默认logstash.yml所在目录
LS_OPTS="--path.settings ${LS_SETTINGS_DIR}"
//logstash启动命令参数,指定配置文件目录
LS_JAVA_OPTS=""
//java参数
LS_PIDFILE=/var/run/logstash.pid
//logstash pid文件路径
LS_USER=es
LS_GROUP=es
//启动用户和用户组
LS_GC_LOG_FILE=/usr/local/pkg/logstash/logs/gc.log
//gc日志
LS_OPEN_FILES=16384
//文件句柄
Nice level
LS_NICE=19
//没找到相应解释,谁知道啥意思,分享下,感谢!
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
//程序名称及程序描述
官方配置文件解释:https://www.elastic.co/guide/en/logstash/6.5/logstash-settings-file.html
<br />
#### 标准nginx日志的pipeline
logstash有大量要学习的知识,这里先简单将整个集群展示出来。后面一点点写。
~]# mkdir logstash/{data,logs,conf.d,patterns} -p
~]# vim logstash/conf.d/local_file.conf
input {
beats {
port => 5044
#监听filebeat端口
}
}
输入
filter {
grok {
match => {
patterns_dir => ["/usr/local/pkg/logstash/patterns"]
#正则表达式单独写入单独目录下,这样方便修改
"message" => "%{OTHERNGINXLOG}"
#使用正则匹配nginx日志,并将每个值抽取出来。
}
}
}
过滤
output {
elasticsearch {
hosts => ["http://192.168.20.6:9200","http://192.168.20.5:9200","http://192.168.20.4:9200"]
#es cluster
index => "logstash-nginx"
#索引名称
}
}
输出给elasticsearch进行保存
~]# vim logstash/patterns/nginx
OTHERNGINXLOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
<br />
**添加启动脚本**
[Unit]
Description=logstash
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=simple
PIDFile=/var/run/logstash.pid
User=es
Group=es
ExecStart=/usr/local/pkg/logstash/bin/logstash -f /usr/local/pkg/logstash/conf.d/*.conf
Restart=always
WorkingDirectory=/usr/local/pkg/logstash
[Install]
WantedBy=multi-user.target
<br />
**启动服务**
//logstash也依赖jdk8,为了不使用系统jdk环境混乱,我们还是在启动脚本里添加相应jdk环境变量
~]# vim /usr/loca/pkg/logstash/bin/logstash
!/bin/bash
export JAVA_HOME=/usr/local/pkg/jdk8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
...
~]# chown -R es.es /usr/loca/pkg/jdk8 /usr/local/pkg/logstash
~]# systemctl daemon-reload
~]# systemctl start logstash.service
~]# tail -f logstash/logs/logstash-plain.log
[2018-12-24T17:18:08,809][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>6}
[2018-12-24T17:18:08,812][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the type event field won't be used to determine the document _type {:es_version=>6}
[2018-12-24T17:18:08,834][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://192.168.20.6:9200"]}
[2018-12-24T17:18:08,866][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2018-12-24T17:18:08,917][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"default"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2018-12-24T17:18:09,397][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2018-12-24T17:18:09,467][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x423f2fad run>"}
[2018-12-24T17:18:09,540][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2018-12-24T17:18:09,587][INFO ][org.logstash.beats.Server] Starting server on port: 5044
[2018-12-24T17:18:09,835][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
看到如下信息,说明启动成功了
<br/><br/>
###展示效果
所有服务都已经成功安装完成并启动,接下来访问kibana来查看最后效果。
ELK Stack部署的更多相关文章
- 集中式日志分析平台 - ELK Stack - 安全解决方案 X-Pack
大数据之心 关注 0.6 2017.02.22 15:36* 字数 2158 阅读 16457评论 7喜欢 9 简介 X-Pack 已经作为 Elastic 公司单独的产品线,前身是 Shield, ...
- Kubernetes实战之部署ELK Stack收集平台日志
主要内容 1 ELK概念 2 K8S需要收集哪些日志 3 ELK Stack日志方案 4 容器中的日志怎么收集 5 K8S平台中应用日志收集 准备环境 一套正常运行的k8s集群,kubeadm安装部署 ...
- 被一位读者赶超,手摸手 Docker 部署 ELK Stack
被一位读者赶超,容器化部署 ELK Stack 你好,我是悟空. 被奇幻"催更" 最近有个读者,他叫"老王",外号"茴香豆泡酒",找我崔更 ...
- 【ELK Stack】ELK+KafKa开发集群环境搭建
部署视图 运行环境 CentOS 6.7 x64 (2核4G,硬盘100G) 需要的安装包 Runtime jdk1.8 : jdk-8u91-linux-x64.gz (http://www.ora ...
- 快速搭建日志系统——ELK STACK
什么是ELK STACK ELK Stack是Elasticserach.Logstash.Kibana三种工具组合而成的一个日志解决方案.ELK可以将我们的系统日志.访问日志.运行日志.错误日志等进 ...
- 2019你该掌握的开源日志管理平台ELK STACK
转载于https://www.vtlab.io/?p=217 在企业级开源日志管理平台ELK VS GRAYLOG一文中,我简单阐述了日志管理平台对技术人员的重要性,并把ELK Stack和Gra ...
- ELK Stack 笔记
ELK Stack ELK Stack ELK Stack ELK 介绍 架构 Elasticsearch 安装 常见问题 关闭 Elasticsearch Elasticsearch-head Ki ...
- ELK Stack总结
目录 ELK Stack 介绍 Elasticsearch 概念1(基础) CRUD基本用法 概念2(文本解析器) 查询 分析/聚合 概念3(架构原理的补充) Logstash基础 Kibana的数据 ...
- ELK Stack 企业级日志收集平台
ELK Stack介绍 大型项目,多产品线的日志收集 ,分析平台 为什么用ELK? 1.开发人员排查问题,服务器上查看权限 2.项目多,服务器多,日志类型多 ELK 架构介绍 数据源--->lo ...
随机推荐
- RAC升级后,一个节点无法连接数据库,报ORA-12537: TNS:connection closed
RAC从11.2.0.3升级到11.2.0.4后,一个节点的Public IP.VIP无法连接数据库 SQL> CONN SYS/oracle@192.168.122.101:1521/pplu ...
- 阿里云composer 镜像
2019年12月2日13:54:32 https://developer.aliyun.com/composer 阿里云的镜像更新时间比较及时 本镜像与 Packagist 官方实时同步,推荐使用最新 ...
- Mac Pro 2015休眠掉电解决办法
硬件:Mac Pro 2015 系统:MacOs Mojave 10.14.3 问题:合盖的时候,休眠1小时掉电10%,由于之前是128G原装盘不会有这个问题,后面购买了M.2转接卡,更换1T Int ...
- window 10 U盘启动制作教程
微软win10工具下载链接https://www.microsoft.com/zh-cn/software-download/windows10?OCID=WIP_r_Win10_Body_AddPC ...
- ufw防火墙规则不生效
正式站系统是Ubuntu 16.04.6 一.今天一个项目有百度爬出,在nginx中封掉还在一直爬取,都403还不停爬取 二.在uwf封掉爬出ip,想封掉80端口没有用,然后封掉整个网段还是没有用,尴 ...
- java修改文件所有者及其权限
1.设置所有者 管理文件所有者 Files.getOwner()和Files.setOwner()方法 要使用UserPrincipal来管理文件的所有者 (1)更改文件的所有者 import jav ...
- 超详尽-QThread的正确使用姿势-以及信号槽的跨线程使用
贴上两篇博文 一.http://www.cnblogs.com/findumars/p/5031239.html 循序渐进介绍了,怎样正确的让槽函数工作在子线程中. 同时介绍了信号槽的绑定与线程的关系 ...
- Java生成艺术二维码也可以很简单
原文点击: Quick-Media Java生成艺术二维码也可以很简单 现在二维码可以说非常常见了,当然我们见得多的一般是白底黑块,有的再中间加一个 logo,或者将二维码嵌在一张特定的背景中(比如微 ...
- 用easyui实现查询条件的后端传递并自动刷新表格的两种方法
用easyui实现查询条件的后端传递并自动刷新表格的两种方法 搜索框如下: 通过datagrid的load方法直接传递参数并自动刷新表格 通过ajax的post函数传递参数并通过loadData方法将 ...
- vue中引入百度地图
xxx.vue <template> <div> <el-input v-model="inputaddr"> </el-input> ...