Python知识点总结篇(二)
列表
- 列表:一个值,包含多个字构成的序列,用
[ ]括起来,[]是一个空列表,不包含任何值,类似于空字符串,负数下标表示从后边开始,-1表示列表最后一个下标,它是一种可变的数据类型,值可以添加、删除或改变; +用于连接两个列表并得到一个新列表;*用于一个列表和一个整数,实现列表的复制;del将删除列表中下标处的值;in、not in用于确定一个值是否在列表中;- 多重赋值技巧:变量数目和列表长度必须严格相等,eg;
cat = ['fat', 'black', 'loud']size, color, disposition = cat
sort()方法对列表中排序时需注意的3件事:sort()方法当场对列表排序;- 不能对既有数字又有字符串值的列表排序;
- 对字符串排序时,使用"ASCII 字符顺序";
sort()和sorted()方法的比较:sort(key = None, reverse = False)就地改变列表,sorted(iterable, key = None, reverse = False)返回新的列表,对所有可迭代对象均有效;
supplies = ['pens', 'staplers', 'flame-throwers', 'binders']supplies.sort()print(supplies)supplies = ['pens', 'staplers', 'flame-throwers', 'binders']sortedSupplies = sorted(supplies)print(supplies)print(sortedSupplies)

\:续行字符;- 元组:使用
( ),和字符串一样是不可变的,值不能被修改、添加或删除; - 序列与元组的转换:
list()将元组转换为序列,tuple()将序列转换为元组;
#序列转元组pets = ['K', 'M', 'N']print(tuple(pets))#元组转序列pets = ('K', 'M', 'N')print(list(pets))

- 列表的引用:列表赋给一个变量时,不直接保存到变量,而是将列表的“引用”赋给了该变量,所以当改变变量的值时,原列表的值也要随着改变;
>>> spam = [0, 1, 2, 4, 5]>>> chees = spam>>> cheese[1] = 'Hello'>>> spam[0, 'Hello', 2, 4, 5]>>> cheese[0, 'Hello', 2, 4, 5]
copy()和deepcopy():处理列表或序列时,若不希望改动影响原来的列表或字典,则使用copy()函数,若是要复制的列表中包含了列表,则使用deepcopy()代替;
字典和结构化数据
- 字典:
{key:value}; - 字典与列表:列表是有序的,而字典是无序的,因此字典不可像列表一样切片;
keys()、values()、items():分别对应于字典的键、值和键-值对;get(要取得其值的键, 键不存在时返回的备用值):
>>> picnicItems = {'apples':5, 'cpus':2}>>> 'I am bringing ' + str(picnicItems.get('cups', 0) + ' cups.'I am bringing 2 cups.>>> 'I an bringing ' + str(picnicItems.get('eggs', 0) + ' cups.'I am bringing 0 eggs.
setdefault(要检查的键, 检查的键不存在时设置的值):第一次调用之后即存在,再次调用不会改变第一次赋给的键值;
>>> spam = {'name':'Pooka', 'age':5}>>> spam.setdefault('color', 'black')'black'>>> spam{'color':'black', 'age':5, 'name':'Pooka'}>>> spam.setdefault('color', 'white')'black'>>> spam{'color':'black', 'age':5, 'name':'Pooka'}
- 集合:无序、不重复的数据组合,主要作用为:
- 去重, 把一个列表变成集合,就自动去重了;
- 关系测试,测试两组数据之前的交集、差集、并集等关系;
- 格式输出:
pprint()和pformat();
import pprintinfo = {'name':'K', 'age': 23}pprint.pprint(info)#下列这句和上句结果相同#print(pprint.pformat(info))

- 嵌套的字典和列表
#嵌套的字典和列表allGuests = {'Alice':{'apple':4, 'pretzels':19},'Bob':{'apple':3, 'sandwiches':4},'Carol':{'cups':5, 'apple pies':4}}def totalBrought(guests, item):numberBrought = 0;for k, v in guests.items():numberBrought += v.get(item, 0)return numberBroughtprint('Apple = ' + str(totalBrought(allGuests, 'apple')))

字符串操作
- 字符串既可以用单引号,也可以用双引号开始和结束;
- 转义字符:
\; - 原始字符串:在字符串开始的引号前加上
r,原始字符串完全忽略所有的转义字符,打印出字符串中所有的倒斜杠;
>>> print(r'That is Carol\'s cat.')That is Carol\'s cat.
- 多行字符串:多行字符串的起止是3个单引号或3个双引号,三重引号之间的所有引号、制表符或换行,都被认为是字符串的一部分,此时缩进规则不适用;
>>> print('''Dear Alice,Eve's cat has been arrested for catnapping, cat burglary, and extortion.Sincerely,Bob''')Dear Alice,Eve's cat has been arrested for catnapping, cat burglary, and extortion.Sincerely,Bob
- 文本对齐:左对齐
ljust(),右对齐rjust(),居中center(); - 向计算机剪贴板发送或接受文本,需要用到
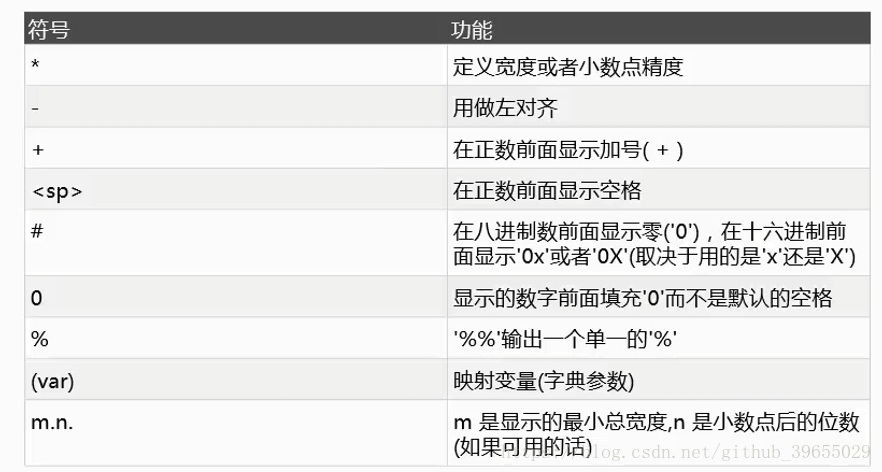
pyperclip模块中的copy()和paste()函数; - 字符串的格式化
欢迎关注微信公众号:村雨1943;创作不易,未经同意,转载请注明出处~
Python知识点总结篇(二)的更多相关文章
- [Python学习]错误篇二:切换当前工作目录时出错——FileNotFoundError: [WinError 3] 系统找不到指定的路径
REFERENCE:<Head First Python> ID:我的第二篇[Python学习] BIRTHDAY:2019.7.13 EXPERIENCE_SHARING:解决切换当前工 ...
- 零基础Python知识点回顾(二)
开始了,继续说!字符串替换,就是预留着空间,后边再定义要填上什么,这种叫字符串格式化,其有两种方法: % 和 format %s 就是一个占位符,这个占位符可以被其它的字符串代替 >&g ...
- Python知识点总结篇(五)
软件目录结构规范 目标: 提高可读性: 提高可维护性: 常见结构 Demo/ |-- bin/ #存放项目的一些可执行文件 | |-- demo #可执行程序,启动demo调main.py | |-- ...
- Python知识点总结篇(三)
文件操作 对文件操作流程 打开文件,得到文件句柄并赋值给一个变量: 通过句柄对文件进行操作: 关闭文件: with:自动关闭文件: with open('log', 'r') as f: ... 文件 ...
- Python知识点总结篇(一)
Python基础 变量 变量类型: 1.数字型 整形:int: 浮点型:float: 布尔型:bool,True和False: 复数型:complex: 2.非数字型 字符串: 列表: 元祖: 字典: ...
- python之scrapy篇(二)
一.创建工程 scarpy startproject xxx 二.编写iteam文件 # -*- coding: utf-8 -*- # Define here the models for your ...
- Python知识点总结篇(四)
递归 特性 必须有明确的结束条件: 每进入深一层递归,问题规模比上层应有所减少: 递归效率不高,层次更多会导致栈溢出: def calc(n): print(n) if n // 2 > 0: ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- Python 基础 面向对象之二 三大特性
Python 基础 面向对象之二 三大特性 上一篇主要介绍了Python中,面向对象的类和对象的定义及实例的简单应用,本篇继续接着上篇来谈,在这一篇中我们重点要谈及的内容有:Python 类的成员.成 ...
随机推荐
- promethues exporter+ grafana 监控pg+mysql
这篇文章本来是打算使用pmm 进行数据库监控的,但是居然参考官方文档使用docker 运行起来有点问题,所以直接改用 exporter 进行处理,但是比pmm 弱好多 pmm 的参考架构 说明,以上图 ...
- web前端开发初级
Web 页面制作基础 Web 的相关概念 WWWWebsiteURLWeb StandardWeb BrowserWeb Server HTML 基础 标记语言从 HTML 到 XHTMLHTML 的 ...
- mac切图
1.按住command键位, 两只手指点击需要切的图 2.再在右边栅格化图层 3.选中需要剪切的图层.command+c 和command+n和 command+v OK 切整张图.先 option ...
- 超级经典的HTTP协议讲解
- HTTP 协议 HTTP 是一个属于应用层的面向对象的协议,由于其简捷.快速的方式,适用于分布式超媒体信息系统.它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展. HTTP 协议的主 ...
- 实现mysql的读写分离(mysql-proxy)____1(mysql的主从复制,基于gtid的主从复制,半同步复制,组复制)
主从复制原理: 从库生成两个线程,一个I/O线程,一个SQL线程: i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中:主库会生成一个 log ...
- [Beta]Scrum Meeting#1
github 本次会议项目由PM召开,时间为5月6日晚上10点30分 时长15分钟 任务表格 人员 昨日工作 下一步工作 木鬼 beta初步计划 撰写博客整理文档 swoip 前端改进计划 模块松耦合 ...
- [Gamma]Scrum Meeting#3
github 本次会议项目由PM召开,时间为5月28日晚上10点30分 时长10分钟 任务表格 人员 昨日工作 下一步工作 木鬼 撰写博客,组织例会 撰写博客,组织例会 swoip 前端显示屏幕,翻译 ...
- [技术博客]采用Qthread实现多线程连接等待
采用Qthread实现多线程连接等待 本组的安卓自动化测试软件中,在测试开始前需要进行连接设备的操作,如下图左侧的按钮 后端MonkeyRunner相关操作的程序中提供了connect() ...
- js去除html标签样式
params = params.replace(/<\/?.+?>/g,"").replace(/ /g,"");
- how to transfer your linux to new work environment
tar cvpzf backup.tgz --exclude=/proc --exclude=/lost+found --exclude=/backup.tgz --exclude=/mnt --ex ...