Scrapy爬虫Demo 爬取资讯分类
爬取新浪网导航页所有下所有大类、小类、小类里的子链接,以及子链接页面的新闻内容。
效果演示图:
items.py
import scrapy
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinaItem(scrapy.Item):
# 大类的标题 和 url
parentTitle = scrapy.Field()
parentUrls = scrapy.Field() # 小类的标题 和 子url
subTitle = scrapy.Field()
subUrls = scrapy.Field() # 小类目录存储路径
subFilename = scrapy.Field() # 小类下的子链接
sonUrls = scrapy.Field() # 文章标题和内容
head = scrapy.Field()
content = scrapy.Field()
spiders/sina.py
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*- from Sina.items import SinaItem
import scrapy
import os import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinaSpider(scrapy.Spider):
name= "sina"
allowed_domains= ["sina.com.cn"]
start_urls= [
"http://news.sina.com.cn/guide/"
] def parse(self, response):
items= []
# 所有大类的url 和 标题
parentUrls = response.xpath('//div[@id=\"tab01\"]/div/h3/a/@href').extract()
parentTitle = response.xpath("//div[@id=\"tab01\"]/div/h3/a/text()").extract() # 所有小类的ur 和 标题
subUrls = response.xpath('//div[@id=\"tab01\"]/div/ul/li/a/@href').extract()
subTitle = response.xpath('//div[@id=\"tab01\"]/div/ul/li/a/text()').extract() #爬取所有大类
for i in range(0, len(parentTitle)):
# 指定大类目录的路径和目录名
parentFilename = "./Data/" + parentTitle[i] #如果目录不存在,则创建目录
if(not os.path.exists(parentFilename)):
os.makedirs(parentFilename) # 爬取所有小类
for j in range(0, len(subUrls)):
item = SinaItem() # 保存大类的title和urls
item['parentTitle'] = parentTitle[i]
item['parentUrls'] = parentUrls[i] # 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba)
if_belong = subUrls[j].startswith(item['parentUrls']) # 如果属于本大类,将存储目录放在本大类目录下
if(if_belong):
subFilename =parentFilename + '/'+ subTitle[j]
# 如果目录不存在,则创建目录
if(not os.path.exists(subFilename)):
os.makedirs(subFilename) # 存储 小类url、title和filename字段数据
item['subUrls'] = subUrls[j]
item['subTitle'] =subTitle[j]
item['subFilename'] = subFilename items.append(item) #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
for item in items:
yield scrapy.Request( url = item['subUrls'], meta={'meta_1': item}, callback=self.second_parse) #对于返回的小类的url,再进行递归请求
def second_parse(self, response):
# 提取每次Response的meta数据
meta_1= response.meta['meta_1'] # 取出小类里所有子链接
sonUrls = response.xpath('//a/@href').extract() items= []
for i in range(0, len(sonUrls)):
# 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True
if_belong = sonUrls[i].endswith('.shtml') and sonUrls[i].startswith(meta_1['parentUrls']) # 如果属于本大类,获取字段值放在同一个item下便于传输
if(if_belong):
item = SinaItem()
item['parentTitle'] =meta_1['parentTitle']
item['parentUrls'] =meta_1['parentUrls']
item['subUrls'] = meta_1['subUrls']
item['subTitle'] = meta_1['subTitle']
item['subFilename'] = meta_1['subFilename']
item['sonUrls'] = sonUrls[i]
items.append(item) #发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理
for item in items:
yield scrapy.Request(url=item['sonUrls'], meta={'meta_2':item}, callback = self.detail_parse) # 数据解析方法,获取文章标题和内容
def detail_parse(self, response):
item = response.meta['meta_2']
content = ""
head = response.xpath('//h1[@id=\"main_title\"]/text()')
content_list = response.xpath('//div[@id=\"artibody\"]/p/text()').extract() # 将p标签里的文本内容合并到一起
for content_one in content_list:
content += content_one item['head']= head
item['content']= content yield item
pipelines.py
from scrapy import signals
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinaPipeline(object):
def process_item(self, item, spider):
sonUrls = item['sonUrls'] # 文件名为子链接url中间部分,并将 / 替换为 _,保存为 .txt格式
filename = sonUrls[7:-6].replace('/','_')
filename += ".txt" fp = open(item['subFilename']+'/'+filename, 'w')
fp.write(item['content'])
fp.close() return item
settings.py
BOT_NAME = 'Sina' SPIDER_MODULES = ['Sina.spiders']
NEWSPIDER_MODULE = 'Sina.spiders' ITEM_PIPELINES = {
'Sina.pipelines.SinaPipeline': 300,
} LOG_LEVEL = 'DEBUG'
在项目根目录下新建main.py文件,用于调试,或者直接命令行输入:scrapy crawl sina
from scrapy import cmdline
cmdline.execute('scrapy crawl sina'.split())
执行程序
py2 main.py
效果:
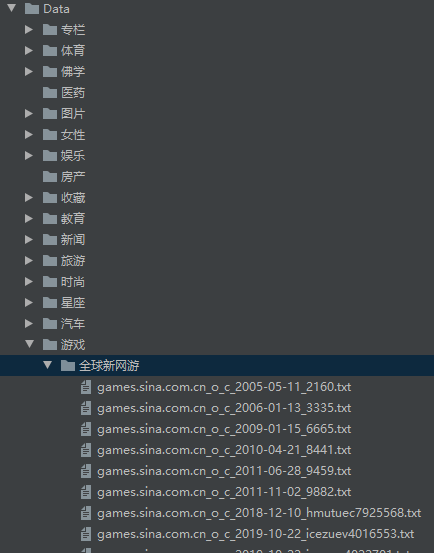
Scrapy爬虫Demo 爬取资讯分类的更多相关文章
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Scrapy爬虫笔记 - 爬取知乎
cookie是一种本地存储机制,cookie是存储在本地的 session其实就是将用户信息用户名.密码等)加密成一串字符串,返回给浏览器,以后浏览器每次请求都带着这个sessionId 状态码一般是 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- Scrapy爬虫实战-爬取体彩排列5历史数据
网站地址:http://www.17500.cn/p5/all.php 1.新建爬虫项目 scrapy startproject pfive 2.在spiders目录下新建爬虫 scrapy gens ...
- 手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了.菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开 ...
- scrapy爬虫案例--爬取阳关热线问政平台
阳光热线问政平台:http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1 爬取最新问政帖子的编号.投诉标题.投诉内容以 ...
- scrapy爬虫框架爬取招聘网站
目录结构 BossFace.py文件中代码: # -*- coding: utf-8 -*-import scrapyfrom ..items import BossfaceItemimport js ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
随机推荐
- 记vue nextTick用到的地方
nextTick是vue提供的全局函数,在下次 DOM 更新循环结束之后执行延迟回调.在修改数据之后立即使用这个方法,获取更新后的 DOM. // 修改数据 vm.msg = 'Hello' // D ...
- php命令模式(command pattern)
... <?php /* The command pattern decouples the object that executes certain operations from objec ...
- Jenkins的HTML报告增加显示Throughput展示
第一步,在summary中添加 在pagelist中添加 关于display-QPS部分,参考我的博文的另外一篇. 生成的报告如下:
- 追光的人对Echo,SkyReach的Beta产品测试报告
所属课程 软件工程1916 作业要求 Beta冲刺博客汇总 团队名称 追光的人 作业目标 团队互测 队员学号 队员博客 221600219 小墨 https://www.cnblogs.com/hen ...
- Python - 100天从新手到大师
简单的说,Python是一个“优雅”.“明确”.“简单”的编程语言. 学习曲线低,非专业人士也能上手 开源系统,拥有强大的生态圈 解释型语言,完美的平台可移植性 支持面向对象和函数式编程 能够通过调用 ...
- git在windows及linux(源码编译)环境下安装
git在windows下安装 下载地址:https://git-scm.com/ 默认安装即可 验证 git --version git在linux下安装 下载地址:https://mirrors.e ...
- UI系统的分类
1.DSL系统:UI领域特定语言 html markdown; 与平台无关,只与通用UI领域有关: 2.平台语言系统(通用语言系统) UI概念在平台和通用语言中的表示. 一.信息表达: 基本信息:文本 ...
- [Algorithm] 283. Move Zeroes
Given an array nums, write a function to move all 0's to the end of it while maintaining the relativ ...
- 文件夹上传插件webupload插件
在Web应用系统开发中,文件上传和下载功能是非常常用的功能,今天来讲一下JavaWeb中的文件上传和下载功能的实现. 先说下要求: PC端全平台支持,要求支持Windows,Mac,Linux 支持所 ...
- 迁移模型问题,提示admin已存在
在部署的时候迁移文件的时候提示 django.db.migrations.exceptions.InconsistentMigrationHistory: Migration admin.0001_i ...