深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6
目录
为什么要用激活函数
sigmod
tanh
ReLU
LeakyReLU
ReLU6
参考资料
|
为什么要用激活函数 |
在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型,只能把输入线性组合再输出(如下图),不能学习到复杂的映射关系,因此需要使用激活函数这个非线性函数做转换。

|
sigmod |
Sigmod激活函数和导函数分别为
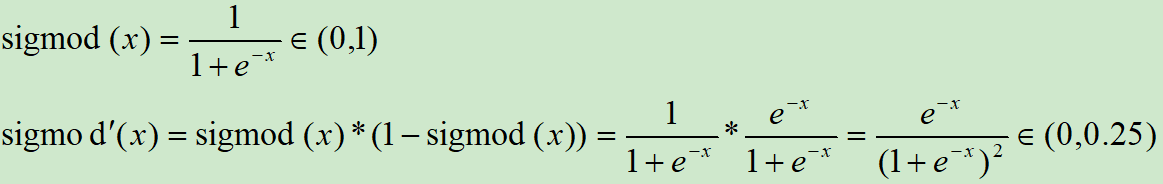
对应的图像分别为:
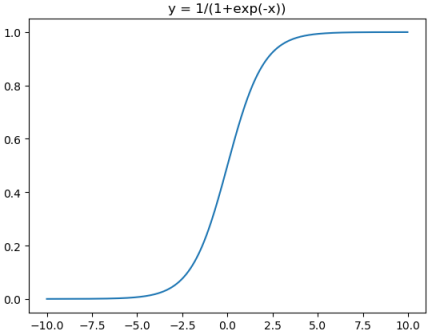
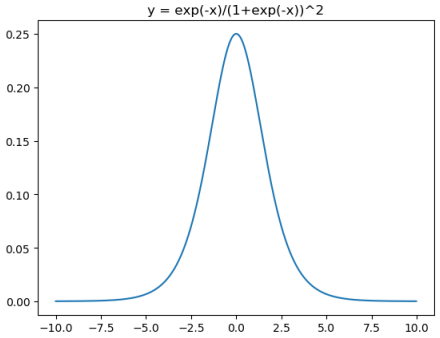
对应代码为:
Sigmod(x)的缺点:
①输出范围在0~1之间,均值为0.5,需要做数据偏移,不方便下一层的学习。
②当x很小或很大时,存在导数很小的情况。另外,神经网络主要的训练方法是BP算法,BP算法的基础是导数的链式法则,也就是多个导数的乘积。而sigmoid的导数最大为0.25,多个小于等于0.25的数值相乘,其运算结果很小。随着神经网络层数的加深,梯度后向传播到浅层网络时,基本无法引起参数的扰动,也就是没有将loss的信息传递到浅层网络,这样网络就无法训练学习了。这就是所谓的梯度消失。
|
tanh |
tanh是双曲函数中的一个,tanh()为双曲正切。在数学中,双曲正切“tanh”是由双曲正弦和双曲余弦这两种基本双曲函数推导而来。
tanh激活函数和导函数分别为
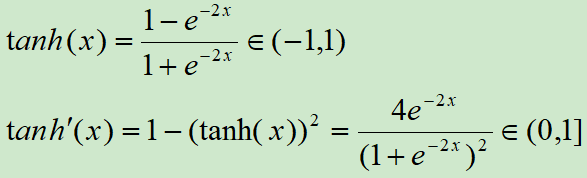
对应的图像分别为:
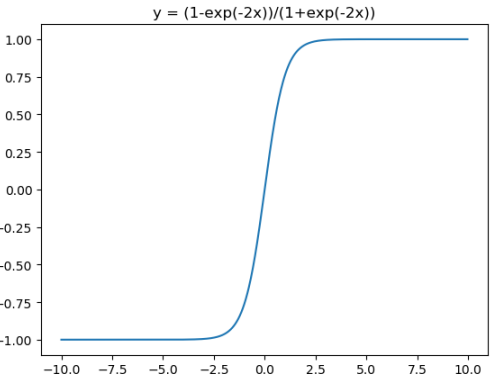
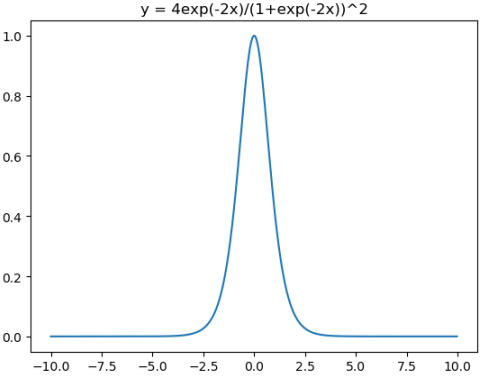
对应代码为:
在神经网络的应用中,tanh通常要优于sigmod的,因为tanh的输出在-1~1之间,均值为0,更方便下一层网络的学习。但有一个例外,如果做二分类,输出层可以使用sigmod,因为他可以算出属于某一类的概率
Sigmod(x)和tanh(x)都有一个缺点:在深层网络的学习中容易出现梯度消失,造成学习无法进行。
|
ReLU |
针对sigmod和tanh的缺点,提出了ReLU函数
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
ReLU激活函数和导函数分别为
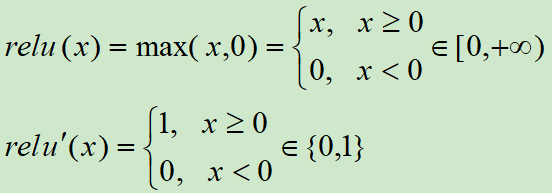
对应的图像分别为:
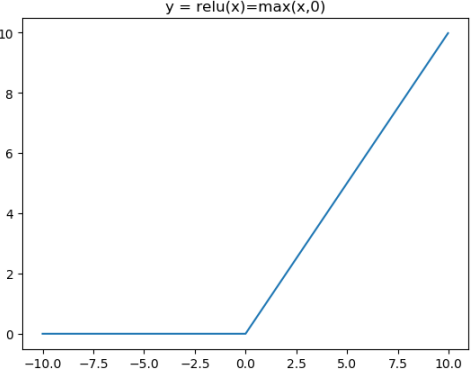
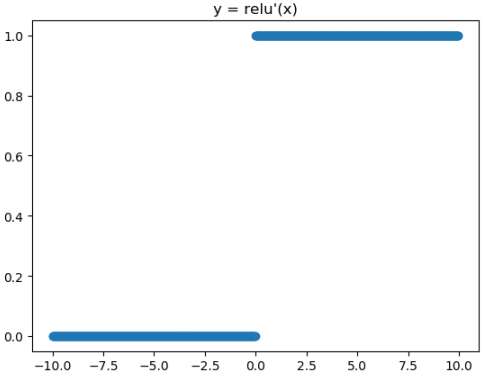
对应代码为:
Relu的一个缺点是当x为负时导数等于零,但是在实践中没有问题,也可以使用leaky Relu。
总的来说Relu是神经网络中非常常用的激活函数。
|
LeakyReLU |
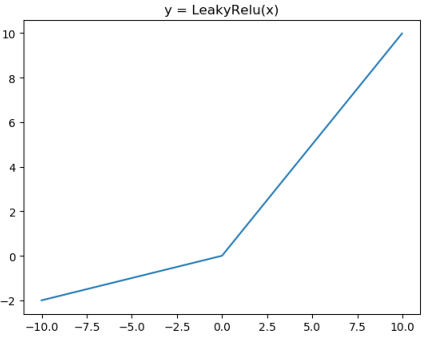
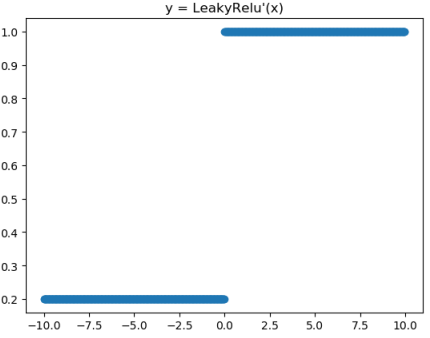
Leaky ReLU激活函数和导函数分别为
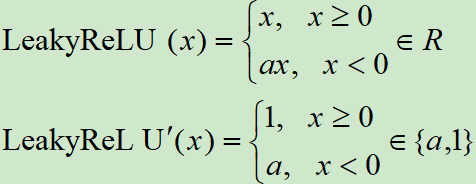
对应的图像分别为:
对应代码为:
|
ReLU6 |
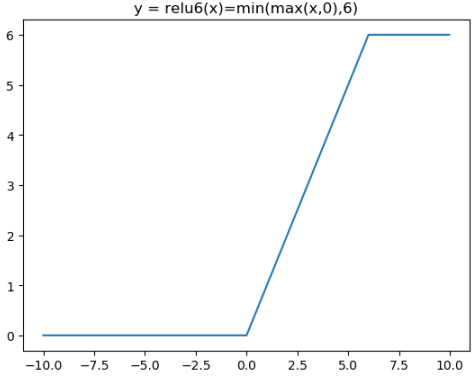
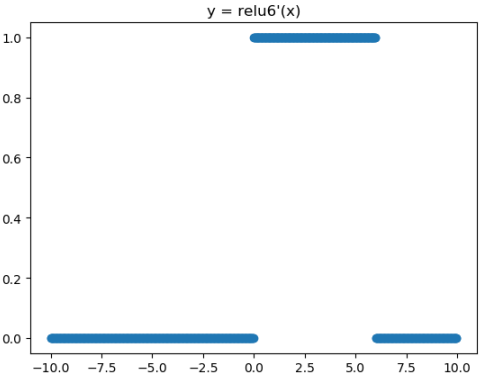
Relu在x>0的区域使用x进行线性激活,有可能造成激活后的值太大,影响模型的稳定性,为抵消ReLU激励函数的线性增长部分,可以使用Relu6函数
ReLU激活函数和导函数分别为
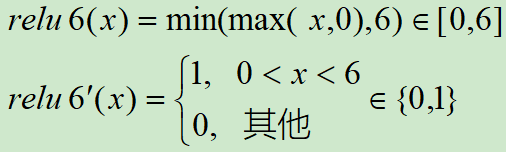
对应的图像分别为:
对应代码为:
|
参考资料 |
吴恩达深度学习
神经网络中的梯度消失
https://www.cnblogs.com/mengnan/p/9480804.html
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6的更多相关文章
- 深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录 sigmod交叉熵 Softmax转换 Softmax交叉熵 参考资料 sigmod交叉熵 Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只 ...
- 深度学习面试题13:AlexNet(1000类图像分类)
目录 网络结构 两大创新点 参考资料 第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是 ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- 深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录 产生背景 举例 参考资料 产生背景 之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势: ①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力. ②减 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 深度学习面试题14:Dropout(随机失活)
目录 卷积层的dropout 全连接层的dropout Dropout的反向传播 Dropout的反向传播举例 参考资料 在训练过程中,Dropout会让输出中的每个值以概率keep_prob变为原来 ...
- 深度学习面试题12:LeNet(手写数字识别)
目录 神经网络的卷积.池化.拉伸 LeNet网络结构 LeNet在MNIST数据集上应用 参考资料 LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务.自那时起 ...
- 深度学习面试题26:GoogLeNet(Inception V2)
目录 第一层卷积换为分离卷积 一些层的卷积核的个数发生了变化 多个小卷积核代替大卷积核 一些最大值池化换为了平均值池化 完整代码 参考资料 第一层卷积换为分离卷积 net = slim.separab ...
- 深度学习面试题25:分离卷积(separable卷积)
目录 举例 单个张量与多个卷积核的分离卷积 参考资料 举例 分离卷积就是先在深度上分别卷积,然后再进行卷积,对应代码为: import tensorflow as tf # [batch, in_he ...
随机推荐
- SIM900 HTTP POST
AT+SAPBR=3,1,"CONTYPE","GPRS" OK AT+SAPBR=3,1,"APN","CMNET" ...
- MySQL Network--域名与VIP
VIP与域名1.域名能在多个IDC切换,而VIP通常在特定网段内切换.2.VIP切换可以立即生效,而域名切换存在一定时间延迟. DNS解析顺序:1.查询本地域名映射配置(/etc/hosts)2.查查 ...
- Android笔记(五十六) Android四大组件之一——ContentProvider,实现自己的ContentProvider
有时候我们自己的程序也需要向外接提供数据,那么就需要我们自己实现ContentProvider. 自己实现ContentProvider的话需要新建一个类去继承ContentProvider,然后重写 ...
- 漫谈五种IO模型(主讲IO多路复用)
首先引用levin的回答让我们理清楚五种IO模型 1.阻塞I/O模型 老李去火车站买票,排队三天买到一张退票. 耗费:在车站吃喝拉撒睡 3天,其他事一件没干. 2.非阻塞I/O模型 老李去火车站买票, ...
- 登录-redis
session的问题 目前session直接是js变量,放在nodejs进程内存中 1.进程内存有限,访问量过大,内存暴增怎么办? 2.正式线上运行是多进程,进程之间内存无法共享 为何session适 ...
- 2018-2019 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2018)- D. Delivery Delays -二分+最短路+枚举
2018-2019 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2018)- D. Delivery Delays -二分+最短路+枚举 ...
- python温度转换代码
#TempConvert.py TempStr=input("请输入带有符号的温度值:")#赋值TempStr,括号里面的是提示 if TempStr[-1] in ['F','f ...
- 手写Java的字符串简单匹配方法IndexOf()
简单的字符串模式匹配算法,可使用KMP进行优化 /** * @param s1 母串 * @param s2 子串 * @return */ public static int myIndexOf(S ...
- MPU-6050
MPU-6000(6050)为全球首例整合性6轴运动处理组件,相较于多组件方案,免除了组合陀螺仪与加速器时间轴之差的问题,减少了大量的封装空间.当连接到三轴磁强计时,MPU-60X0提供完整的9轴运动 ...
- 前端学习笔记--js概述与基础语法、变量、数据类型、运算符与表达式
本篇记录js的概述与基础语法.变量.数据类型.运算符与表达式 1.概述与基础语法 2.变量 举例: 3.数据类型 4.运算符与表达式