Kafka Consumer Lag Monitoring
Sematext Monitoring 是最全面的Kafka监视解决方案之一,可捕获约200个Kafka指标,包括Kafka Broker,Producer和Consumer指标。尽管其中许多指标很有用,但每个人都有一个要监视的特定指标–消费者滞后。
什么是卡夫卡消费者滞后?
卡夫卡消费者滞后指标表明卡夫卡生产者和消费者之间存在多少滞后。人们谈论卡夫卡时,通常指的是卡夫卡经纪人。您可以将Kafka Broker视为Kafka服务器。代理实际上是存储和提供Kafka消息的对象。Kafka生产者是将消息写入Kafka(经纪人)的应用程序。Kafka使用者是从Kafka(Brokers)读取消息的应用程序。
内部经纪人数据存储在一个或多个主题中,每个主题由一个或多个分区组成。当写入数据时,代理实际上会将其写入特定的分区。在写入数据时,它会跟踪每个分区中的最后一个“写入位置”。这称为最新偏移,也称为对数结束偏移。每个分区都有自己独立的最新偏移量。
就像Broker跟踪每个分区中的写入位置一样,每个Consumer跟踪每个正在消耗其数据的分区中的“读取位置”。也就是说,它跟踪已读取的数据。这被称为消费者抵销。消费者偏移量会定期存在(到ZooKeeper或Kafka本身的特殊主题),因此它可以承受消费者崩溃或不正常关机的情况,并避免重复使用过多的旧数据。
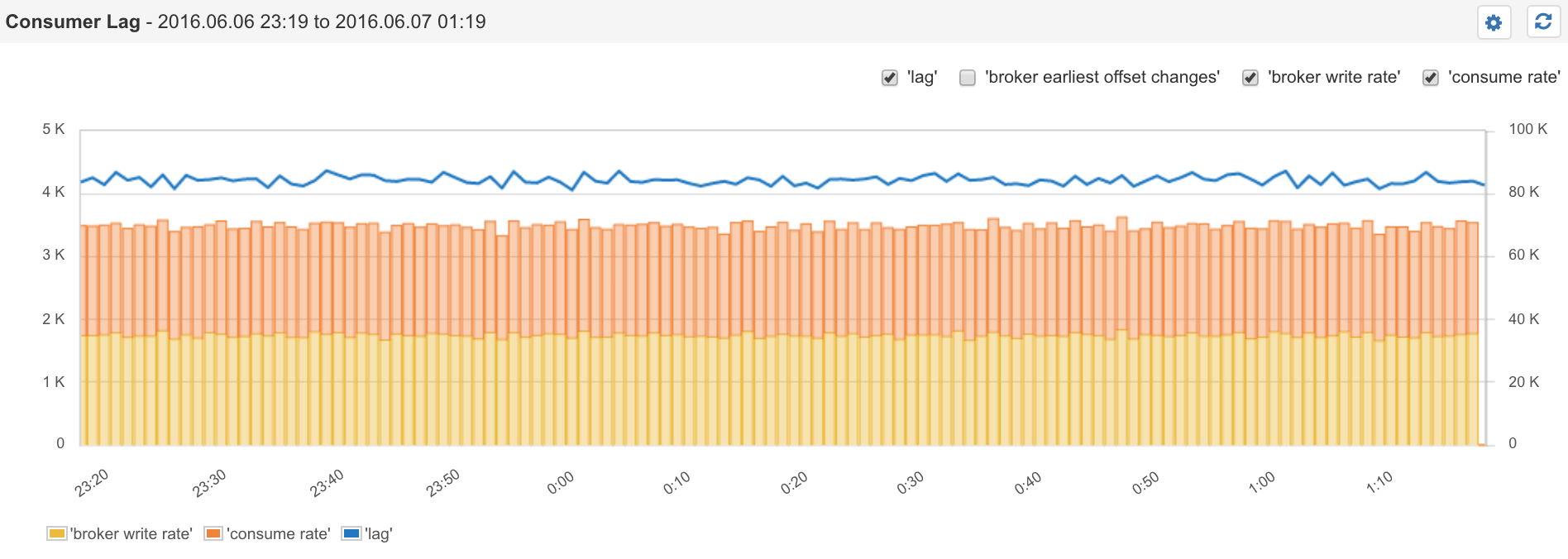 卡夫卡消费者滞后率和读/写率
卡夫卡消费者滞后率和读/写率
在上面的图表中,我们可以看到黄色的条形,代表着经纪人编写生产者创建的消息的速率。橙色条形表示消费者从经纪人那里消费消息的速率。费率看起来大致相等-必须保持一致,否则消费者将落后。但是,在写入消息和使用消息之间始终会有一些延迟。读取总是落后于写入,这就是我们所说的“消费者滞后”。消费者滞后时间只是最新偏移量和消费者偏移量之间的增量。
为什么消费者滞后很重要
如今,许多应用程序都是基于能够处理(接近)实时数据的。考虑一下性能监控系统(例如Sematext Monitoring)或日志管理服务(例如Sematext Logs)。他们连续不断地处理无限量的近实时数据。如果它们向您显示指标或日志的时间过长-如果“消费者滞后”过大-它们将几乎无用。消费者滞后告诉我们每个分区中每个消费者(组)落后多远。滞后时间越短,实时数据消耗就越大。
监视读写速率
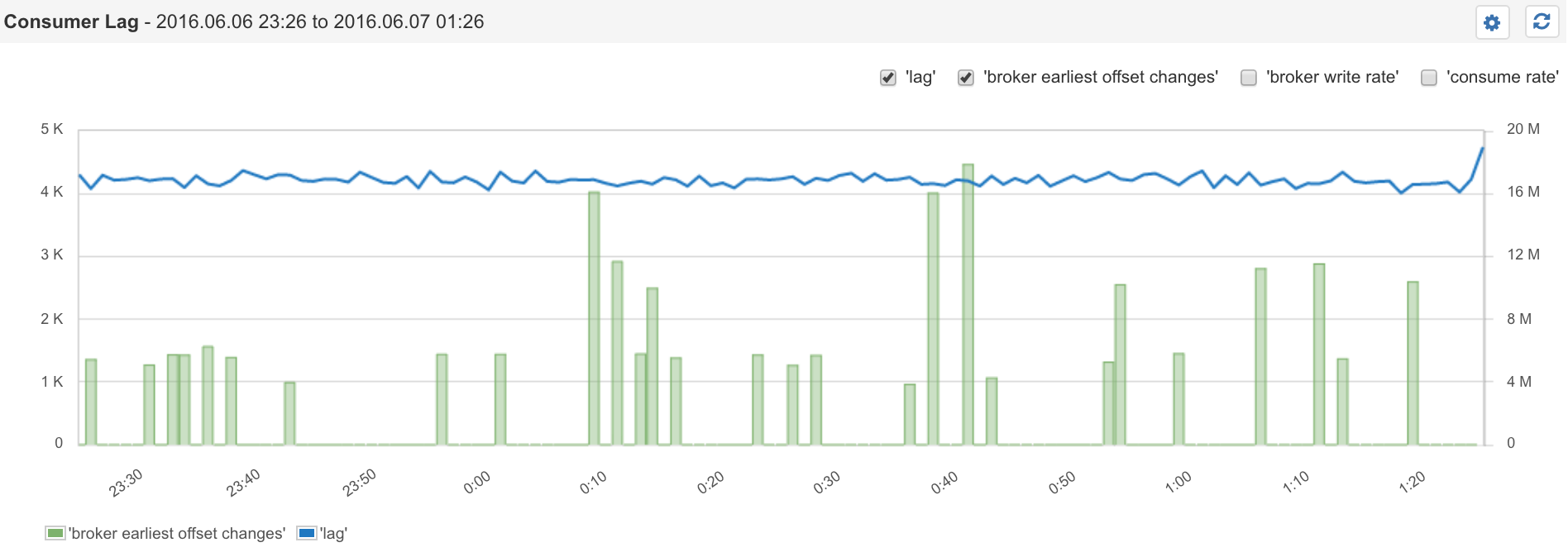 卡夫卡消费者滞后和经纪人抵销变化
卡夫卡消费者滞后和经纪人抵销变化
正如我们刚刚了解到的,“最新偏移量”与“消费者偏移量”之间的差异是导致我们“消费者滞后”的原因。在上面的Sematext图表中,您可能已经注意到其他一些指标:
- 经纪人写率
- 消耗率
- 经纪人最早的抵销变动
速率指标是派生的指标。如果您查看Kafka的指标,您将找不到它们。在后台,开源Sematext代理收集了一些Kafka指标具有各种偏移量,可从这些偏移量计算这些费率。此外,它还绘制了经纪人最早的偏移量变化图,这是每个经纪人分区中已知的最早的偏移量。换句话说,此偏移量是分区中最旧消息的偏移量。尽管仅靠偏移量可能并不是超级有用,但当情况出现问题时,了解其变化情况可能会很方便。Kafka中的数据具有一定的TTL(生存时间),可以轻松清除旧数据。该清除操作由Kafka本身执行。每次清除都会使最旧数据的偏移量发生变化。Sematext的经纪人最早的抵销更改会浮出水面,以便您进行监控。该指标使您了解清除的频率以及每次运行时清除的消息数量。
Kafka监控工具
那里有几种Kafka监控工具,例如 LinkedIn的Burrow,其Sematext中使用了Kafka Offset监控和Consumer Lag监控方法。我们在Kafka开源监控工具中编写了各种开源监控工具。如果您需要一个好的Kafka监控解决方案,请尝试使用Sematext。将您的Kafka和其他日志发送到Sematext Logs中,您便拥有了一个DevOps解决方案,该解决方案使故障排除变得容易而不是麻烦。
is one of the most comprehensive Kafka monitoring solutions, capturing some 200 Kafka metrics, including Kafka Broker, Producer, and Consumer metrics. While lots of those metrics are useful, there is one particular metric everyone wants to monitor – Consumer Lag.
What is Kafka Consumer Lag?
Kafka Consumer Lag is the indicator of how much lag there is between Kafka producers and consumers. When people talk about Kafka they are typically referring to Kafka Brokers. You can think of a Kafka Broker as a Kafka server. A Broker is what actually stores and serves Kafka messages. Kafka Producers are applications that write messages into Kafka (Brokers). Kafka Consumers are applications that read messages from Kafka (Brokers).
Inside Brokers data is stored in one or more Topics, and each Topic consists of one or more Partitions. When writing data a Broker actually writes it into a specific Partition. As it writes data it keeps track of the last “write position” in each Partition. This is called Latest Offset also known as Log End Offset. Each Partition has its own independent Latest Offset.
Just like Brokers keep track of their write position in each Partition, each Consumer keeps track of “read position” in each Partition whose data it is consuming. That is, it keeps track of which data it has read. This is known as Consumer Offset. This Consumer Offset is periodically persisted (to ZooKeeper or a special Topic in Kafka itself) so it can survive Consumer crashes or unclean shutdowns and avoid re-consuming too much old data.
Kafka Consumer Lag and Read/Write Rates
In our diagram above we can see yellow bars, which represents the rate at which Brokers are writing messages created by Producers. The orange bars represent the rate at which Consumers are consuming messages from Brokers. The rates look roughly equal – and they need to be, otherwise the Consumers will fall behind. However, there is always going to be some delay between the moment a message is written and the moment it is consumed. Reads are always going to be lagging behind writes, and that is what we call Consumer Lag. The Consumer Lag is simply the delta between the Latest Offset and Consumer Offset.
Why is Consumer Lag Important
Many applications today are based on being able to process (near) real-time data. Think about performance monitoring system like Sematext Monitoring or log management service like Sematext Logs. They continuously process infinite streams of near real-time data. If they were to show you metrics or logs with too much delay – if the Consumer Lag were too big – they’d be nearly useless. This Consumer Lag tells us how far behind each Consumer (Group) is in each Partition. The smaller the lag the more real-time the data consumption.
Monitoring Read and Write Rates
Kafka Consumer Lag and Broker Offset Changes
As we just learned the delta between the Latest Offset and the Consumer Offset is what gives us the Consumer Lag. In the above chart from Sematext you may have noticed a few other metrics:
- Broker Write Rate
- Consume Rate
- Broker Earliest Offset Changes
The rate metrics are derived metrics. If you look at Kafka’s metrics you won’t find them there. Under the hood the open source Sematext agent collects a few Kafka metrics with various offsets from which these rates are computed. In addition, it charts Broker Earliest Offset Changes, which is the earliest known offset in each Broker’s Partition. Put another way, this offset is the offset of the oldest message in a Partition. While this offset alone may not be super useful, knowing how it’s changing could be handy when things go awry. Data in Kafka has a certain TTL (Time To Live) to allow for easy purging of old data. This purging is performed by Kafka itself. Every time such purging kicks in the offset of the oldest data changes. Sematext’s Broker Earliest Offset Change surfaces this information for your monitoring pleasure. This metric gives you an idea how often purges are happening and how many messages they’ve removed each time they ran.
Kafka Monitoring Tools
There are several Kafka monitoring tools out there that, like LinkedIn’s Burrow, whose Kafka Offset monitoring and Consumer Lag monitoring approach is used in Sematext. We’ve written various open source monitoring tools in Kafka Open Source Monitoring Tools. If you need a good Kafka monitoring solution, give Sematext a go. Ship your Kafka and other logs into Sematext Logs and you’ve got yourself a DevOps solution that will make troubleshooting easy instead of dreadful.
Kafka Consumer Lag Monitoring的更多相关文章
- Understanding Kafka Consumer Groups and Consumer Lag
In this post, we will dive into the consumer side of this application ecosystem, which means looking ...
- 【原创】Kafka Consumer多线程实例续篇
在上一篇<Kafka Consumer多线程实例>中我们讨论了KafkaConsumer多线程的两种写法:多KafkaConsumer多线程以及单KafkaConsumer多线程.在第二种 ...
- Kafka consumer group位移0ffset重设
本文阐述如何使用Kafka自带的kafka-consumer-groups.sh脚本随意设置消费者组(consumer group)的位移.需要特别强调的是, 这是0.11.0.0版本提供的新功能且只 ...
- Kafka设计解析(十九)Kafka consumer group位移重设
转载自 huxihx,原文链接 Kafka consumer group位移重设 本文阐述如何使用Kafka自带的kafka-consumer-groups.sh脚本随意设置消费者组(consumer ...
- Kafka Consumer接口
对于kafka的consumer接口,提供两种版本, high-level 一种high-level版本,比较简单不用关心offset, 会自动的读zookeeper中该Consumer grou ...
- 【原创】美团二面:聊聊你对 Kafka Consumer 的架构设计
在上一篇中我们详细聊了关于 Kafka Producer 内部的底层原理设计思想和细节, 本篇我们主要来聊聊 Kafka Consumer 即消费者的内部底层原理设计思想. 1.Consumer之总体 ...
- 【原创】Kafka Consumer多线程实例
Kafka 0.9版本开始推出了Java版本的consumer,优化了coordinator的设计以及摆脱了对zookeeper的依赖.社区最近也在探讨正式用这套consumer API替换Scala ...
- Kafka设计解析(四)- Kafka Consumer设计解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/08/09/KafkaColumn4 摘要 本文主要介绍了Kafka High Level Con ...
- 【原创】kafka consumer源代码分析
顾名思义,就是kafka的consumer api包. 一.ConsumerConfig.scala Kafka consumer的配置类,除了一些默认值常量及验证参数的方法之外,就是consumer ...
随机推荐
- OO_BLOG4_UML系列学习
目录 Unit4 作业分析 作业 4-1 UML类图解析器UmlInteraction 作业 4-2 扩展解析器(UML顺序图.UML状态图解析,基本规则验证) 架构设计及OO方法理解的演进 测试理解 ...
- EntityFramework 基类重写
/* * ------------------------------------------------------------------------------ * * 创 建 者:F_Gang ...
- idea 忽略提交文件
https://blog.csdn.net/wangjun5159/article/details/74932433 https://blog.csdn.net/m0_38001814/article ...
- B端产品需求文档怎么写?
B端,或者2B,一般指的是英文中的 to busniss,中文即面向企业的含义.与B端相对应的,是C端,或者2C,同样指的是英文中的 to customer,即面向消费者的意思.因此,人们平常所说的B ...
- 景点API支持查询携程旅游门票景点详情
门票景点详情,景点api支持查询携程旅游门票景点详情. 接口名称:景点api 接口平台:开放api 接口地址:http://api2.juheapi.com/xiecheng/senicspot/ti ...
- MySQL5.7 安装和配置环境变量
安装 1.下载安装包 官网地址:https://dev.mysql.com/downloads/mysql/ 2.选择 Custom,自定义 3.根据自己系统选择 x64还是x86,然后点击第一个箭头 ...
- itextpdf中表格中单元格的文字水平垂直居中的设置
在使用itextpdf中,版本是5.5.6,使用Doucument方式生成pdf时,设置单元格中字体的对齐方式时,发现一些问题,并逐渐找到了解决方式. 给我的经验就是:看官网的例子才能保证代码的效果, ...
- 201871010102-《面向对象程序设计(java)》第6-7周学习总结
博文正文开头:(2分) 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/ ...
- 采坑复盘:logging日志能用封装后的函数来打日志,发现filename一直显示封装logging函数的方法所在的文件名
问题: logging日志能用封装后的函数来打日志,发现filename一直显示封装logging函数的方法所在的文件名 原因: logging记录的是第一个函数执行所在的文件,那用封装的函数,首先执 ...
- ManiFest.MF
Manifest-Version: 1.0 //指定manifest文件的版本信息 Bundle-ManifestVersion: 2 //指定该包遵从 OSGi 规范 V3 或者 OSGi 规范 V ...