数据分析——Pandas的用法(Series,DataFrame)
我们先要了解,pandas是基于Numpy构建的,pandas中很多的用法和numpy一致。pandas中又有series和DataFrame,Series是DataFrame的基础。
pandas的主要功能:
- 具备对其功能的数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据,处理NaN数据(******)
一、Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成
1.创建方法
第一种:
pd.Series([4,5,6,7])
#执行结果
0 4
1 5
2 6
3 7
dtype: int64
#将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取
第二种:
pd.Series([4,5,6,7,8],index=['a','b','c','d','e']) #index索引是用[]
#执行结果
a 4
b 5
c 6
d 7
e 8
dtype: int64
# 自定义索引,index是指定的索引名,是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
第三种:
pd.Series({"a":1,"b":2}) #传入字典格式数据
#执行结果:
a 1
b 2
dtype: int64
# 传入字典格式的数据,字典的key当成指定索引
第四种:
pd.Series(0,index=['a','b','c'])
#执行结果:
a 0
b 0
c 0
dtype: int64
# 创建一个值都是0的数组
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series,也支持通过索引取值。
2.缺失数据(******)在处理数据的时候经常会遇到这类情况
- dropna() # 过滤掉值为NaN的行
- fillna() # 填充缺失数据
- isnull() # 返回布尔数组,缺失值对应为True
- notnull() # 返回布尔数组,缺失值对应为False
# 第一步,创建一个字典,通过Series方式创建一个Series对象
st = {"sean":18,"yang":19,"bella":20,"cloud":21}
obj = pd.Series(st)
obj
运行结果:
sean 18
yang 19
bella 20
cloud 21
dtype: int64
------------------------------------------
# 第二步
a = {'sean','yang','cloud','rocky'} # 定义一个索引变量
------------------------------------------
#第三步
obj1 = pd.Series(st,index=a)
obj1 # 将第二步定义的a变量作为索引传入 # 运行结果:
rocky NaN
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
# 因为rocky没有出现在st的键中,所以返回的是缺失值
dropna() #过滤掉值有NaN的行
obj1.dropna()
#执行结果
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
fillna() #填充缺失数据,这个填写1
obj1.fillna(1)
#执行结果
cloud 21.0
sean 18.0
yang 19.0
rocky 1.0
dtype: float64
isnull() #缺失值返回True
obj1.isnull()
#执行结果
cloud False
sean False
yang False
rocky True
dtype: bool
notnull() #不是缺失值返回True
obj1.notnull()
#执行结果
cloud True
sean True
yang True
rocky False
dtype: bool
利用布尔值索引过滤缺失值
obj1[obj1.notnull()] #只有True的才显示
#执行结果
cloud 21.0
sean 18.0
yang 19.0
dtype: float64
3.Series特性
- 从ndarray创建Series:Series(arr)
- 与标量(数字):sr * 2
- 两个Series运算
- 通用函数:np.ads(sr)
- 布尔值过滤:sr[sr>0]
- 统计函数:mean()、sum()、cumsum()
因为pandas是基于numpy的,所以有numpy的很多特性,Series和numpy很多类似
支持字典的特性:
- 从字典创建Series:Series(dic),
- In运算:'a'in sr、for x in sr
- 键索引:sr['a'],sr[['a','b','d']]
- 键切片:sr['a':'c']
- 其他函数:get('a',default=0)等
4.整数索引
sr = pd.Series(np.arange(10))
sr1 = sr[3:]
sr1
运行结果:
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
# 到这里会发现很正常,一点问题都没有,可是当使用整数索引取值的时候就会出现问题了。因为在pandas当中使用整数索引取值是优先以标签解释的(就是index的值),而不是下标。
比如我想取索引值为1的数值,不再是我们之前的那种方法
sr1[1] #这种方式是取不出的,因为默认优先的是以标签解释的,这个没有1的标签(index)
解决方法:
- loc属性 # 以标签解释
- iloc属性 # 以下标(索引)解释
sr1.iloc[1] #以下标取值,(索引值为1的)
#执行结果
4 sr1.loc[4] #以标签取值(index值为1)
#执行结果
4
5.Series数据对齐
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr2 = pd.Series([11,20,10], index=['d','c','a',])
sr1 + sr2
运行结果:
a 33
c 32
d 45
dtype: int64
# 可以通过这种索引对齐直接将两个Series对象进行运算
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1 + sr3
运行结果:
a 33.0
b NaN
c 32.0
d 45.0
dtype: float64
# sr1 和 sr3的索引不一致,所以最终的运行会发现b索引对应的值无法运算,就返回了NaN,一个缺失值
将两个Series对象相加时将缺失值设为0
sr1 = pd.Series([12,23,34], index=['c','a','d'])
sr3 = pd.Series([11,20,10,14], index=['d','c','a','b'])
sr1.add(sr3,fill_value=0)
运行结果:
a 33.0
b 14.0
c 32.0
d 45.0
dtype: float64
# 将缺失值设为0,所以最后算出来b索引对应的结果为14
二.DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引(这里的索引指的就是列索引)。
1.创建方式
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种:
pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
# 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列
运行结果:
one two
0 1 4
1 2 3
2 3 2
3 4 1
#字典的key就是列索引,行索引和series一致
> 指定列
可以通过columns参数指定顺序排列
data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]})
pd.DataFrame(data,columns=['two','one']) #指定显示顺序
#执行结果
two one
0 4 1
1 3 2
2 2 3
3 1 4
#注意:columns一定要是key值中的,才能匹配的到,不然会报错
第二种:
pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])})
运行结果:
one two
a 1 2
b 2 1
c 3 3
#字典的key是列索引,index是行索引
2.查看数据
常用属性和方法:(和numpy类似)
- index 获取行索引
- columns 获取列索引
- T 转置
- values 获取值
- describe() 获取快速统计
one two
a 1 2
b 2 1
c 3 3
# 这样一个数组df
-----------------------------------------------------------------------------
df.index #行索引
运行结果:
Index(['a', 'b', 'c'], dtype='object')
----------------------------------------------------------------------------
df.columns #列索引
运行结果:
Index(['one', 'two'], dtype='object')
--------------------------------------------------------------------------
df.T #转置
运行结果:
a b c
one 1 2 3
two 2 1 3
-------------------------------------------------------------------------
df.values #获取值,ndarray类型
运行结果:
array([[1, 2],
[2, 1],
[3, 3]], dtype=int64)
------------------------------------------------------------------------
df.describe() #统计信息
运行结果:
one two
count 3.0 3.0
mean 2.0 2.0
std 1.0 1.0
min 1.0 1.0
25% 1.5 1.5
50% 2.0 2.0
75% 2.5 2.5
max 3.0 3.0
3.索引和切片
- DataFrame有行索引和列索引。
- DataFrame同样可以通过标签和位置两种方法进行索引和切片。
DataFrame使用索引切片:
- 方法1:两个中括号,先取列再取行。 比如:df['A'][0]
- 方法2(推荐):使用loc/iloc属性,一个中括号,逗号隔开,先取行再取列。
- loc属性:解释为标签
- iloc属性:解释为下标
- 向DataFrame对象中写入值时只使用方法2
- 行/列索引部分可以是常规索引、切片、布尔值索引、花式索引任意搭配。(注意:两部分都是花式索引时结果可能与预料的不同)
4.常见获取数据的方式
打开csv,excel等文档获取数据
df=pd.read_csv('./douban_movie.csv') #填写正确的文件路径
df.head() #head默认显示前五条
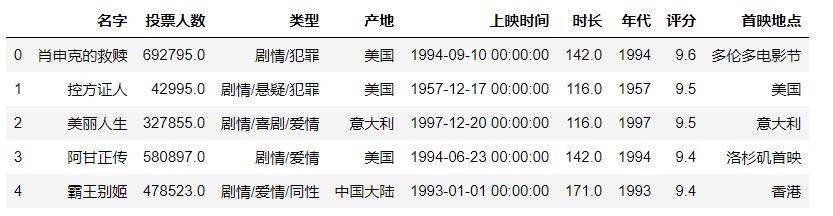
另存为
df.to_csv('./a.csv',index=False) #另存为,不要保存行索引(index索引),不然打开a.csv会出现两个行索引
read_html 获取页面上的表格
举例子:计算nba球队获取总冠军的次数
dd=pd.read_html('https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin') #地址为百度nba总冠军记录,返回的结果是列表,此页面的所有表格数据
因为是返回值是列表,所以一个表格代表一个元素,因为此页面中有两个表格,索引我们按照索引取值的方式取出第一个表格
champion=dd[0]
champion.head() #显示前5条
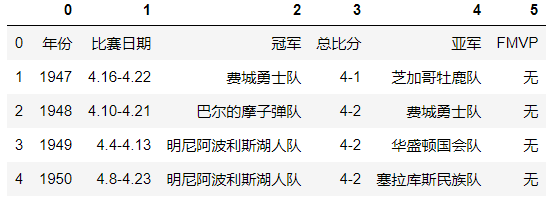
champion.columns=champion.iloc[0] #将第一行的数据赋值给列名(colimns代表列名)
champion.drop([0],inplace=True) #将数据的第一行删除掉
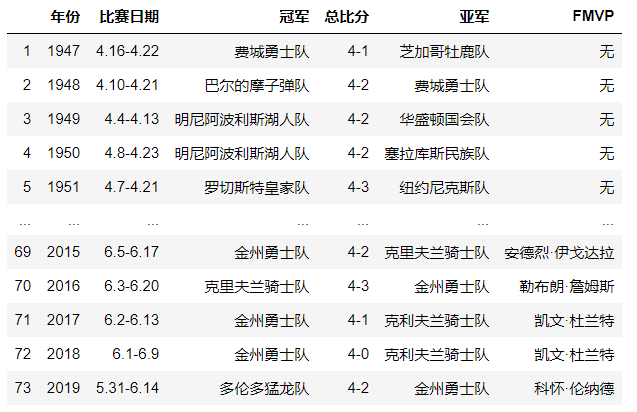
根据冠军球队来分组
champion.groupby('冠军').groups

统计次数,然后排序
champion.groupby('冠军').size().sort_values(ascending=False)

5.时间对象处理
时间序列类型
- 时间戳:特定时刻
- 固定时期:如2019年1月
- 时间间隔:起始时间-结束时间
python库:datatime
- date、time、datetime、timedelta
- dt.strftime()
- strptime()
灵活处理时间对象:dateutil包
- dateutil.parser.parse()
import dateutil
dateutil.parser.parse("2019 Jan 2nd") #注意时间格式一定要是英文格式 执行结果:
datetime.datetime(2019, 1, 2, 0, 0)
成组处理时间对象:pandas (******)
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019']) #处理时间 运行结果:
DatetimeIndex(['2018-03-01', '2019-02-03', '2019-08-12'], dtype='datetime64[ns]', freq=None) # 产生一个DatetimeIndex对象 # 转换时间索引,将时间做成索引
ind = pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019'])
sr = pd.Series([1,2,3],index=ind)
sr
运行结果:
2018-03-01 1
2019-02-03 2
2019-08-12 3
dtype: int64
通过以上方式就可以将索引转换为时间 补充:
pd.to_datetime(['2018-03-01','2019 Feb 3','08/12-/019']).to_pydatetime()
运行结果:
array([datetime.datetime(2018, 3, 1, 0, 0),
datetime.datetime(2019, 2, 3, 0, 0),
datetime.datetime(2019, 8, 12, 0, 0)], dtype=object)
# 通过to_pydatetime()方法将其转换为array数组
产生时间对象数组:data_range
- start 开始时间
- end 结束时间
- periods 时间长度
- freq 时间频率,默认为'D',可选H(our),W(eek),B(usiness),S(emi-)M(onth),(min)T(es), S(econd), A(year),…
pd.date_range("2019-1-1","2019-2-2")
运行结果:
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08',
'2019-01-09', '2019-01-10', '2019-01-11', '2019-01-12',
'2019-01-13', '2019-01-14', '2019-01-15', '2019-01-16',
'2019-01-17', '2019-01-18', '2019-01-19', '2019-01-20',
'2019-01-21', '2019-01-22', '2019-01-23', '2019-01-24',
'2019-01-25', '2019-01-26', '2019-01-27', '2019-01-28',
'2019-01-29', '2019-01-30', '2019-01-31', '2019-02-01',
'2019-02-02'],
dtype='datetime64[ns]', freq='D') #默认是D,按天算. M:按月算
时间序列
时间序列就是以时间对象为索引的Series或DataFrame。datetime对象作为索引时是存储在DatetimeIndex对象中的。
# 转换时间索引
dt = pd.date_range("2019-01-01","2019-02-02")
a = pd.DataFrame({"num":pd.Series(random.randint(-100,100) for _ in range(30)),"date":dt})
# 先生成一个带有时间数据的DataFrame数组
a.index = pd.to_datetime(a["date"])
# 再通过index修改索引
特殊功能:
- 传入“年”或“年月”作为切片方式
- 传入日期范围作为切片方式
- 丰富的函数支持:resample(), strftime(), ……
- 批量转换为datetime对象:to_pydatetime()
a.resample("3D").mean() # 计算每三天的均值
a.resample("3D").sum() # 计算每三天的和
...
6.数据分组和聚合
在数据分析当中,我们有时需要将数据拆分,然后在每一个特定的组里进行运算,这些操作通常也是数据分析工作中的重要环节。
- 分组(GroupBY机制) (分组是经常用到的)
- 聚合函数(组内应用某个函数)
- apply
- 透视表和交叉表
分组(GroupBY机制)
主要就是groupby结合索引和size的使用
聚合函数(组内应用某个函数)
| 函数名 | 描述 | |
|---|---|---|
| sum | 非NA值的和 | |
| median | 非NA值的算术中位数 | |
| std、var | 无偏(分母为n-1)标准差和方差 | |
| prod | 非NA值的积 | |
| first、last | 第一个和最后一个非NA值 |
apply(******)
GroupBy当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将它们组合到一起。
df.apply(
['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', '**kwds']
func:传入一个自定义函数
axis:函数传入参数当axis=0就会把一行数据作为Series的数据
数据分析——Pandas的用法(Series,DataFrame)的更多相关文章
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- 利用Python进行数据分析:【Pandas】(Series+DataFrame)
一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的.3.pandas的主要功能 --具备对其功能的数据结构DataFrame.S ...
- python做数据分析pandas库介绍之DataFrame基本操作
怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 这一部分主要学习pandas中基于前面两种数据结构的基本操作. 设有DataF ...
- 用python做数据分析pandas库介绍之DataFrame基本操作
怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 这一部分主要学习pandas中基于前面两种数据结构的基本操作. 设有DataF ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- Python数据分析中Groupby用法之通过字典或Series进行分组
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c',' ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- pandas 的数据结构Series与DataFrame
pandas中有两个主要的数据结构:Series和DataFrame. [Series] Series是一个一维的类似的数组对象,它包含一个数组数据(任何numpy数据类型)和一个与数组关联的索引. ...
随机推荐
- 洛谷 P3376 【模板】网络最大流 题解
今天学了网络最大流,EK 和 Dinic 主要就是运用搜索求增广路,Dinic 相当于 EK 的优化,先用bfs求每个点的层数,再用dfs寻找并更新那条路径上的值. EK 算法 #include< ...
- fake_useragent 本地运行各种报错解决办法
- Java基础教程(全代码解析)
字面量: 整数字面量为整型(int) 小数字面量为双精度浮点型(double) 数据类型: byte short int long float double 接下来代码展示理解 public clas ...
- C语言博客06-结构体
1.本章学习总结 1.1 学习内容总结 结构体如何定义.成员如何赋值 1.结构体的一般形式为: struct 结构体名 { 数据类型 成员名1: 数据类型 成员名2: : 数据类型 成员名n: }: ...
- shell脚本编程基础之case语句
基础简介 脚本编程分为: 面向过程 选择结构:if语句,单分支.双分支.多分支:case语句 控制结构:顺序结构(默认) 循环结构:for.while.until 面向对象 case语句结构 case ...
- Codeforces - 1264C - Beautiful Mirrors with queries - 概率期望dp
一道挺难的概率期望dp,花了很长时间才学会div2的E怎么做,但这道题是另一种设法. https://codeforces.com/contest/1264/problem/C 要设为 \(dp_i\ ...
- python3 Paramiko模块学习
简介 ssh是一个协议,OpenSSH是其中一个开源实现,paramiko是Python的一个库,实现了SSHv2协议(底层使用cryptography). 有了Paramiko以后,我们就可以在Py ...
- firewalld添加/删除服务service,端口port
启动CentOS/RHEL 7后,防火墙规则设置由firewalld服务进程默认管理. 一个叫做firewall-cmd的命令行客户端支持和这个守护进程通信以永久修改防火墙规则. # firewall ...
- 东软HIS系统_打印发票提示“打印机报错!对访问XXX的设置无效”解决办法
发票打印报错 添加打印机,端口跟物理打印机同一个. 添加 MZJSFP,ZYJSFP,YJJFP三个打印机 打印发票错位 设置自定义纸张 MZJSFP 宽30.40CM 高12.94CM ZYJSFP ...
- Kafka(四) —— KafkaProducer源码阅读
一.doSend()方法 Kafka中的每一条消息都对应一个ProducerRecord对象. public class ProducerRecord<K, V> { private fi ...