[E2E_L9]类化和级联化
一、多车辆识别可能和车辆车牌分割;

 0
0 1
1 7
7 8
8

}
#include <algorithm>
#include <fstream>
#include <iomanip>
#include <vector>
#include <string>
#include <chrono>
#include <memory>
#include <utility>
#include <format_reader_ptr.h>
#include <inference_engine.hpp>
#include <ext_list.hpp>
#include <samples/slog.hpp>
#include <samples/ocv_common.hpp>
#include "segmentation_demo.h"
using namespace InferenceEngine;
using namespace std;
using namespace cv;
//从图片中获得车和车牌(这里没有输出模型的定位结果,如果需要可以适当修改)
vector< pair<Mat, Mat> > GetCarAndPlate(Mat src)
{
vector<pair<Mat, Mat>> resultVector;
// 模型准备
InferencePlugin plugin(PluginDispatcher().getSuitablePlugin(TargetDevice::eCPU));
plugin.AddExtension(std::make_shared<Extensions::Cpu::CpuExtensions>());//Extension,useful
//读取模型(xml和bin
CNNNetReader networkReader;
networkReader.ReadNetwork("E:/OpenVINO_modelZoo/vehicle-license-plate-detection-barrier-0106.xml");
networkReader.ReadWeights("E:/OpenVINO_modelZoo/vehicle-license-plate-detection-barrier-0106.bin");
CNNNetwork network = networkReader.getNetwork();
network.setBatchSize(1);
// 输入输出准备
InputsDataMap inputInfo(network.getInputsInfo());//获得输入信息
if (inputInfo.size() != 1) throw std::logic_error("错误,该模型应该为单输入");
string inputName = inputInfo.begin()->first;
OutputsDataMap outputInfo(network.getOutputsInfo());//获得输出信息
DataPtr& _output = outputInfo.begin()->second;
const SizeVector outputDims = _output->getTensorDesc().getDims();
string firstOutputName = outputInfo.begin()->first;
int maxProposalCount = outputDims[2];
int objectSize = outputDims[3];
if (objectSize != 7) {
throw std::logic_error("Output should have 7 as a last dimension");
}
if (outputDims.size() != 4) {
throw std::logic_error("Incorrect output dimensions for SSD");
}
_output->setPrecision(Precision::FP32);
_output->setLayout(Layout::NCHW);
// 模型读取和推断
ExecutableNetwork executableNetwork = plugin.LoadNetwork(network, {});
InferRequest infer_request = executableNetwork.CreateInferRequest();
Blob::Ptr lrInputBlob = infer_request.GetBlob(inputName); //data这个名字是我看出来的,实际上这里可以更统一一些
matU8ToBlob<float_t>(src, lrInputBlob, 0);//重要的转换函数,第3个参数是batchSize,应该是自己+1的
infer_request.Infer();
// --------------------------- 8. 处理结果-------------------------------------------------------
const float *detections = infer_request.GetBlob(firstOutputName)->buffer().as<float *>();
int i_car = 0;
int i_plate = 0;
for (int i = 0; i < 200; i++)
{
float confidence = detections[i * objectSize + 2];
float x_min = static_cast<int>(detections[i * objectSize + 3] * src.cols);
float y_min = static_cast<int>(detections[i * objectSize + 4] * src.rows);
float x_max = static_cast<int>(detections[i * objectSize + 5] * src.cols);
float y_max = static_cast<int>(detections[i * objectSize + 6] * src.rows);
Rect rect = cv::Rect(cv::Point(x_min, y_min), cv::Point(x_max, y_max));
if (confidence > 0.5)
{
if (rect.width > 150)//车辆
{
Mat roi = src(rect);
pair<Mat, Mat> aPair;
aPair.first = roi.clone();
resultVector.push_back(aPair);
i_car++;
}
else//车牌
{
Mat roi = src(rect);
resultVector[i_plate].second = roi.clone();
i_plate++;
}
}
}
return resultVector;
}
//从车的图片中识别车型
pair<string,string> GetCarAttributes(Mat src)
{
pair<string, string> resultPair;
// --------------------------- 1.为IE准备插件-------------------------------------
InferencePlugin plugin(PluginDispatcher().getSuitablePlugin(TargetDevice::eCPU));
printPluginVersion(plugin, std::cout);//正确回显表示成功
plugin.AddExtension(std::make_shared<Extensions::Cpu::CpuExtensions>());//Extension,useful
// --------------------------- 2.读取IR模型(xml和bin)---------------------------------
CNNNetReader networkReader;
networkReader.ReadNetwork("E:/OpenVINO_modelZoo/vehicle-attributes-recognition-barrier-0039.xml");
networkReader.ReadWeights("E:/OpenVINO_modelZoo/vehicle-attributes-recognition-barrier-0039.bin");
CNNNetwork network = networkReader.getNetwork();
// --------------------------- 3. 准备输入输出的------------------------------------------
InputsDataMap inputInfo(network.getInputsInfo());//获得输入信息
BlobMap inputBlobs; //保持所有输入的blob数据
if (inputInfo.size() != 1) throw std::logic_error("错误,该模型应该为单输入");
auto lrInputInfoItem = *inputInfo.begin();//开始读入
int w = static_cast<int>(lrInputInfoItem.second->getTensorDesc().getDims()[3]); //这种写法也是可以的,它的first就是data
int h = static_cast<int>(lrInputInfoItem.second->getTensorDesc().getDims()[2]);
network.setBatchSize(1);//只有1副图片,故BatchSize = 1
// --------------------------- 4. 读取模型 ------------------------------------------(后面这些操作应该可以合并了)
ExecutableNetwork executableNetwork = plugin.LoadNetwork(network, {});
// --------------------------- 5. 创建推断 -------------------------------------------------
InferRequest infer_request = executableNetwork.CreateInferRequest();
// --------------------------- 6. 将数据塞入模型 -------------------------------------------------
Blob::Ptr lrInputBlob = infer_request.GetBlob("input"); //data这个名字是我看出来的,实际上这里可以更统一一些
matU8ToBlob<float_t>(src, lrInputBlob, 0);//重要的转换函数,第3个参数是batchSize,应该是自己+1的
// --------------------------- 7. 推断结果 -------------------------------------------------
infer_request.Infer();//多张图片多次推断
// --------------------------- 8. 处理结果-------------------------------------------------------
// 7 possible colors for each vehicle and we should select the one with the maximum probability
auto colorsValues = infer_request.GetBlob("color")->buffer().as<float*>();
// 4 possible types for each vehicle and we should select the one with the maximum probability
auto typesValues = infer_request.GetBlob("type")->buffer().as<float*>();
const auto color_id = std::max_element(colorsValues, colorsValues + 7) - colorsValues;
const auto type_id = std::max_element(typesValues, typesValues + 4) - typesValues;
static const std::string colors[] = {
"white", "gray", "yellow", "red", "green", "blue", "black"
};
static const std::string types[] = {
"car", "bus", "truck", "van"
};
resultPair.first = colors[color_id];
resultPair.second = types[type_id];
return resultPair;
}
//识别车牌
string GetPlateNumber(Mat src)
{
// --------------------------- 1.为IE准备插件-------------------------------------
InferencePlugin plugin(PluginDispatcher().getSuitablePlugin(TargetDevice::eCPU));
plugin.AddExtension(std::make_shared<Extensions::Cpu::CpuExtensions>());//Extension,useful
// --------------------------- 2.读取IR模型(xml和bin)---------------------------------
CNNNetReader networkReader;
networkReader.ReadNetwork("E:/OpenVINO_modelZoo/license-plate-recognition-barrier-0001.xml");
networkReader.ReadWeights("E:/OpenVINO_modelZoo/license-plate-recognition-barrier-0001.bin");
CNNNetwork network = networkReader.getNetwork();
network.setBatchSize(1);//只有1副图片,故BatchSize = 1
// --------------------------- 3. 准备输入输出的------------------------------------------
InputsDataMap inputInfo(network.getInputsInfo());//获得输入信息
BlobMap inputBlobs; //保持所有输入的blob数据
string inputSeqName;
if (inputInfo.size() == 2) {
auto sequenceInput = (++inputInfo.begin());
inputSeqName = sequenceInput->first;
}
else if (inputInfo.size() == 1) {
inputSeqName = "";
}
else {
throw std::logic_error("LPR should have 1 or 2 inputs");
}
InputInfo::Ptr& inputInfoFirst = inputInfo.begin()->second;
inputInfoFirst->setInputPrecision(Precision::U8);
string inputName = inputInfo.begin()->first;
//准备输出数据
OutputsDataMap outputInfo(network.getOutputsInfo());//获得输出信息
if (outputInfo.size() != 1) {
throw std::logic_error("LPR should have 1 output");
}
string firstOutputName = outputInfo.begin()->first;
DataPtr& _output = outputInfo.begin()->second;
const SizeVector outputDims = _output->getTensorDesc().getDims();
// --------------------------- 4. 读取模型 ------------------------------------------(后面这些操作应该可以合并了)
ExecutableNetwork executableNetwork = plugin.LoadNetwork(network, {});
// --------------------------- 5. 创建推断 -------------------------------------------------
InferRequest infer_request = executableNetwork.CreateInferRequest();
// --------------------------- 6. 将数据塞入模型 -------------------------------------------------
Blob::Ptr lrInputBlob = infer_request.GetBlob(inputName); //data这个名字是我看出来的,实际上这里可以更统一一些
matU8ToBlob<uint8_t>(src, lrInputBlob, 0);//重要的转换函数,第3个参数是batchSize,应该是自己+1的
// --------------------------- 7. 推断结果 -------------------------------------------------
infer_request.Infer();//多张图片多次推断
// --------------------------- 8. 处理结果-------------------------------------------------------
static std::vector<std::string> items = {
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"<Anhui>", "<Beijing>", "<Chongqing>", "<Fujian>",
"<Gansu>", "<Guangdong>", "<Guangxi>", "<Guizhou>",
"<Hainan>", "<Hebei>", "<Heilongjiang>", "<Henan>",
"<HongKong>", "<Hubei>", "<Hunan>", "<InnerMongolia>",
"<Jiangsu>", "<Jiangxi>", "<Jilin>", "<Liaoning>",
"<Macau>", "<Ningxia>", "<Qinghai>", "<Shaanxi>",
"<Shandong>", "<Shanghai>", "<Shanxi>", "<Sichuan>",
"<Tianjin>", "<Tibet>", "<Xinjiang>", "<Yunnan>",
"<Zhejiang>", "<police>",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J",
"K", "L", "M", "N", "O", "P", "Q", "R", "S", "T",
"U", "V", "W", "X", "Y", "Z"
};
const auto data = infer_request.GetBlob(firstOutputName)->buffer().as<float*>();
std::string result;
for (size_t i = 0; i < 88; i++) {
if (data[i] == -1)
break;
result += items[static_cast<size_t>(data[i])];
}
return result;
}
void main()
{
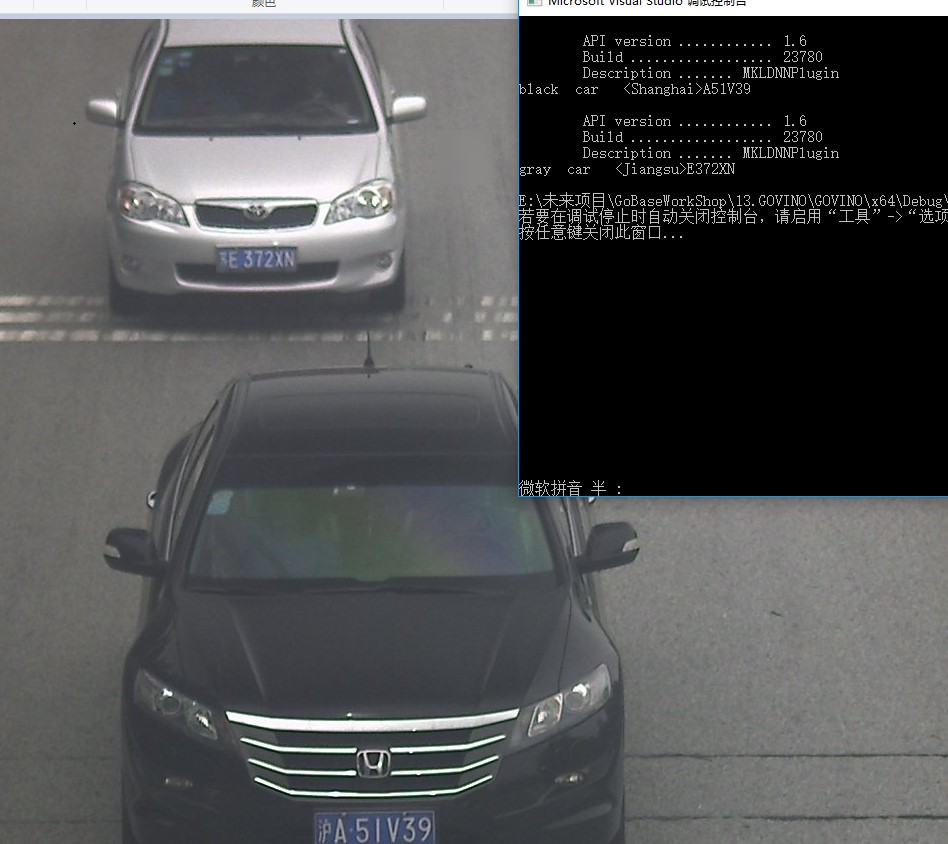
string imageNames = "E:/OpenVINO_modelZoo/沪A51V39.jpg";
Mat src = imread(imageNames);
if (src.empty())
return;
vector<pair<Mat, Mat>> CarAndPlateVector = GetCarAndPlate(src);
for (int i=0;i<CarAndPlateVector.size();i++)
{
pair<Mat, Mat> aPair = CarAndPlateVector[i];
pair<string, string> ColorAndType = GetCarAttributes(aPair.first);
string PlateNumber = GetPlateNumber(aPair.second);
cout << ColorAndType.first <<" "<<ColorAndType.second <<" "<< PlateNumber << endl;
}
cv::waitKey();
}
infer_request->StartAsync();
infer_request.Wait(IInferRequest::WaitMode::RESULT_READY);
sync_infer_request->Infer();



VideoCapture capture("E:/未来项目/炼数成金/(录制中)端到端/L9/道路监控数据集/2.avi");
Mat src;
while (true)
{
if (!capture.read(src))
break;
……



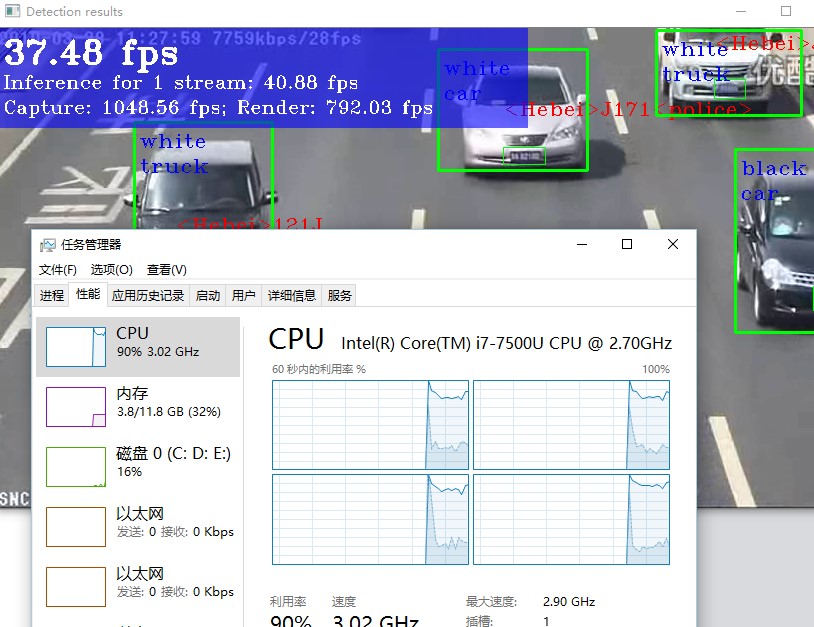
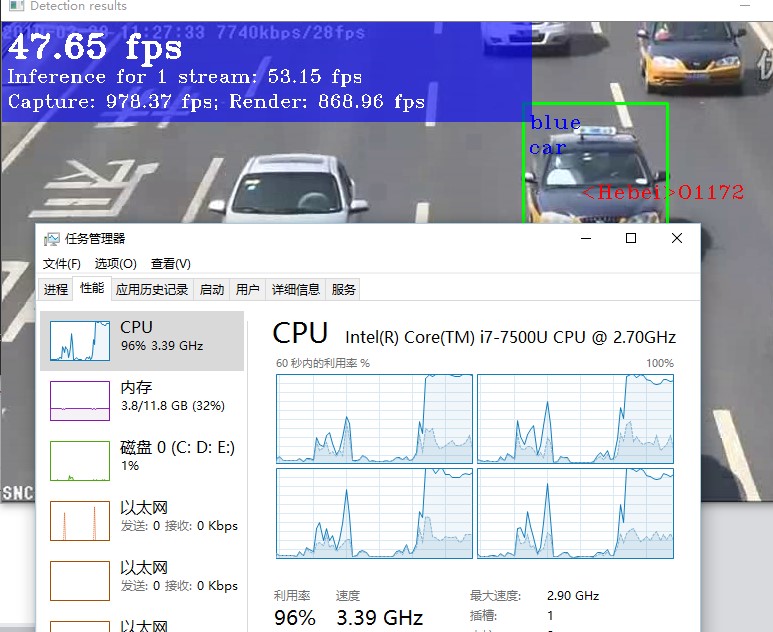
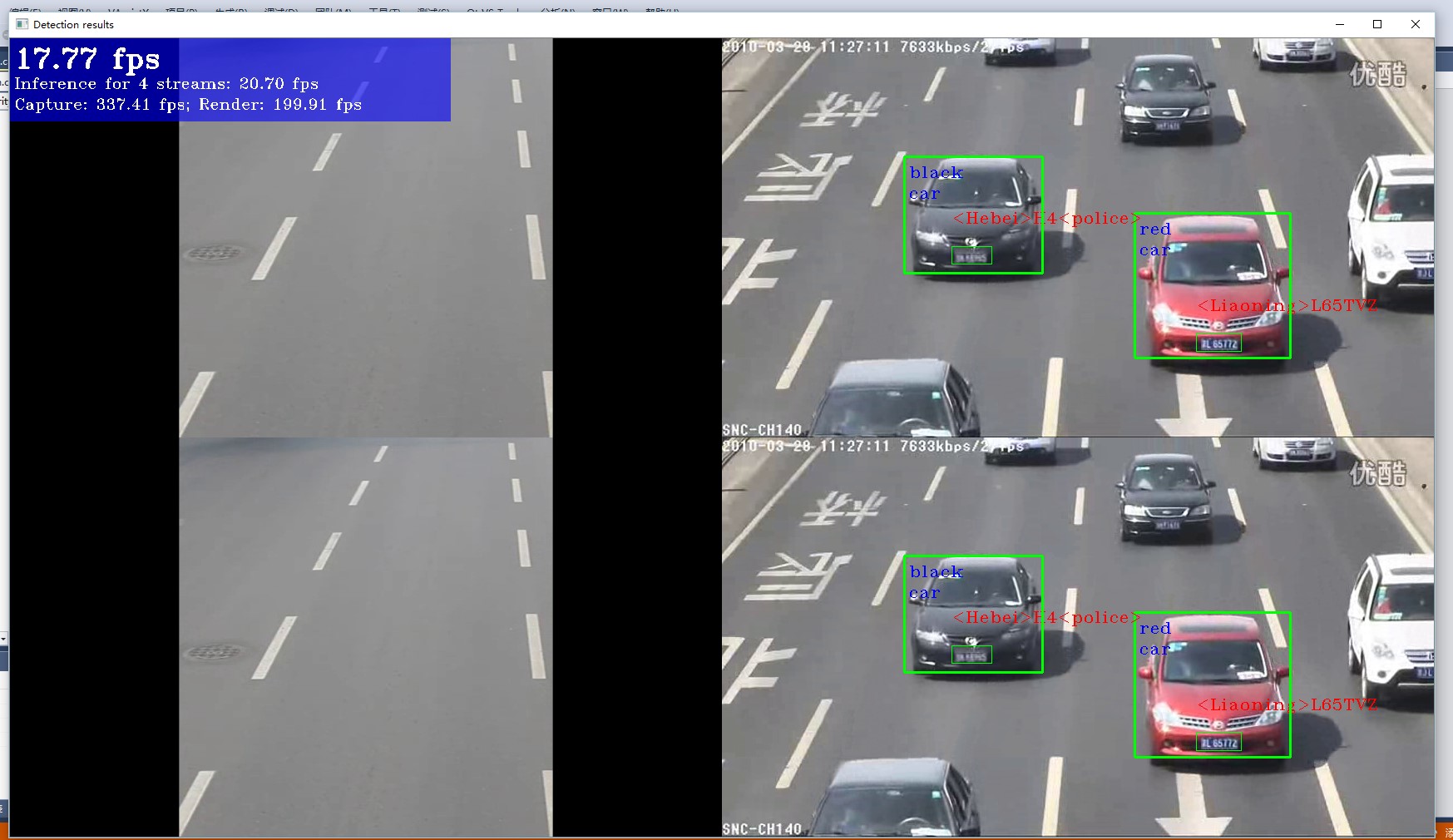
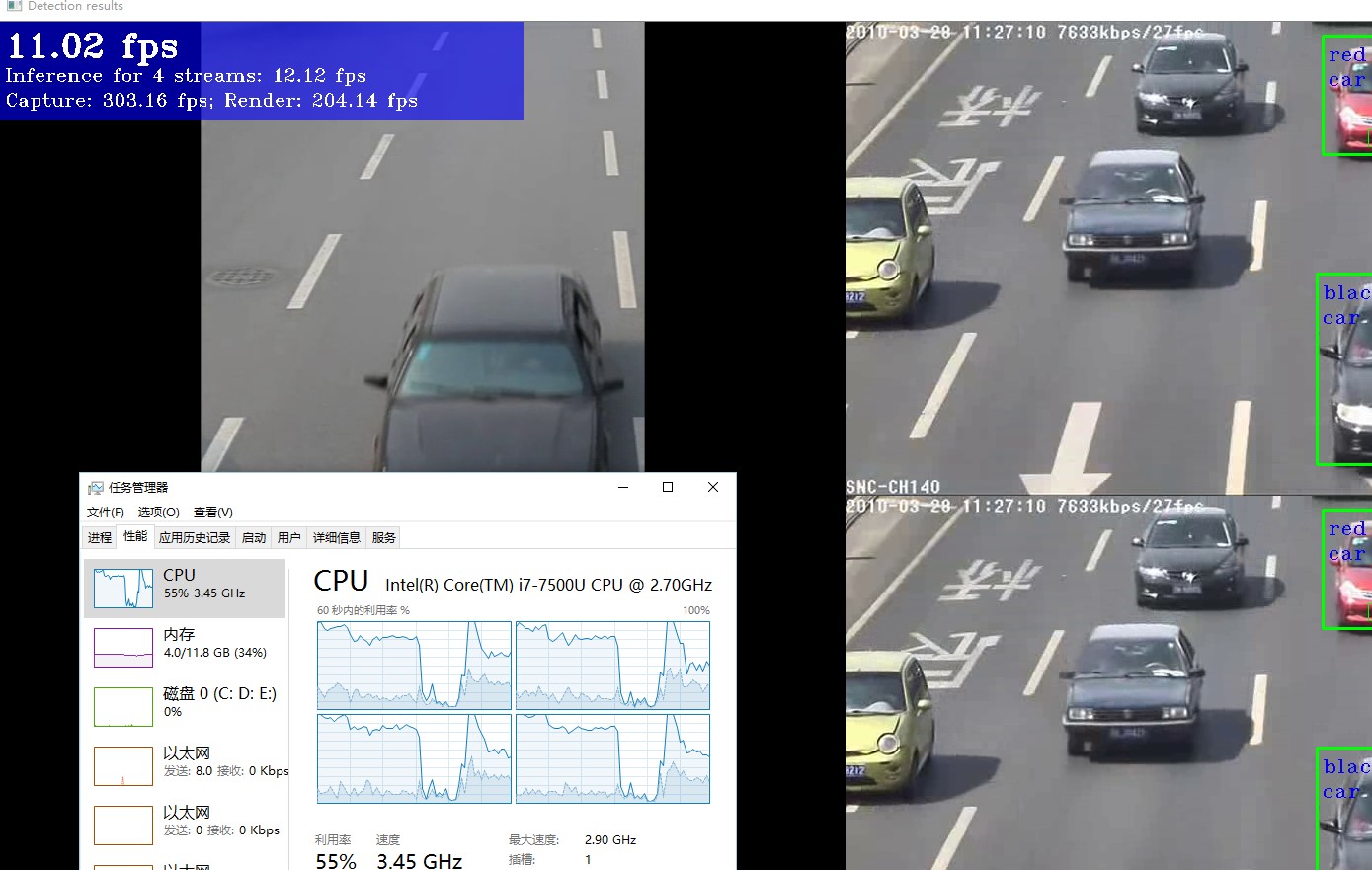
 是数据采集和输入的时间,我们称之为C;
是数据采集和输入的时间,我们称之为C; 是数据处理的时间(也是最消耗时间的地方),我们称之为P;
是数据处理的时间(也是最消耗时间的地方),我们称之为P; 是数据显示的时间(这个基本可以做到旁路),我们称之为S。
是数据显示的时间(这个基本可以做到旁路),我们称之为S。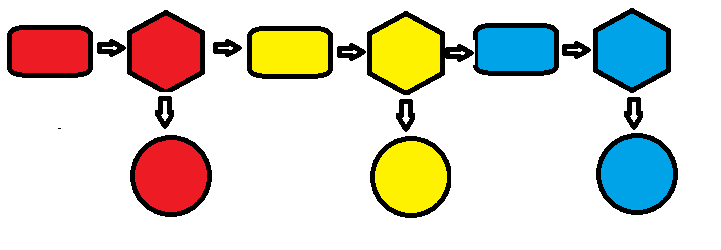
附件列表
[E2E_L9]类化和级联化的更多相关文章
- C++ 类的动态组件化技术
序言: N年前,我们曾在软件开发上出现了这样的困惑,用VC开发COM组件过于复杂,用VB开发COM组件发现效率低,而且不能实现面向对象的很多特性,例如,继承,多态等.更况且如何快速封装利用历史遗留的大 ...
- 窗口的子类化与超类化——子类化是窗口实例级别的,超类化是在窗口类(WNDCLASS)级别的
1. 子类化 理论:子类化是这样一种技术,它允许一个应用程序截获发往另一个窗口的消息.一个应用程序通过截获属于另一个窗口的消息,从而实现增加.监视或者修改那个窗口的缺省行为.子类化是用来改变或者扩展一 ...
- [Python]ctypes+struct实现类c的结构化数据串行处理
1. 用C/C++实现的结构化数据处理 在涉及到比较底层的通信协议开发过程中, 往往需要开发语言能够有效的表达和处理所定义的通信协议的数据结构. 在这方面是C/C++语言是具有天然优势的: 通过str ...
- 实列+JVM讲解类的实列化顺序
刨根问底---类的实列化顺序 开篇三问 1什么是类的加载,类的加载和类的实列有什么关系,什么时候类加载 2类加载会调用构造函数吗,什么时候调用构造函数 3什么是实列化对象,实列化的对象有什么东西. 我 ...
- I类HDACs是乳酸化修饰“eraser”
赖氨酸酰化修饰 (lysine acylation) 是一种广泛存在的.进化上高度保守的蛋白质翻译后修饰 (post-translational modifications, PTMs) 类型,通过表 ...
- Android组件化和插件化开发
http://www.cnblogs.com/android-blogs/p/5703355.html 什么是组件化和插件化? 组件化开发就是将一个app分成多个模块,每个模块都是一个组件(Modul ...
- C++ 中超类化和子类化常用API
在windows平台上,使用C++实现子类化和超类化常用的API并不多,由于这些API函数的详解和使用方法,网上一大把.本文仅作为笔记,简单的记录一下. 子类化:SetWindowLong,GetWi ...
- C++ 中超类化和子类化
超类化和子类化没有具体的代码,其实是一种编程技巧,在MFC和WTL中可以有不同的实现方法. 窗口子类化: 原理就是改变一个已创建窗口类的窗口过程函数.通过截获已创建窗口的消息,从而实现监视或修改已创建 ...
- 眼见为实(2):介绍Windows的窗口、消息、子类化和超类化
眼见为实(2):介绍Windows的窗口.消息.子类化和超类化 这篇文章本来只是想介绍一下子类化和超类化这两个比较“生僻”的名词.为了叙述的完整性而讨论了Windows的窗口和消息,也简要讨论了进程和 ...
随机推荐
- Gitlab创建一个项目(三)使用IntelliJ IDEA开发项目
Gitlab创建一个项目 Gitlab创建一个项目(二)创建新用户以及分配项目 1.登陆到gitlab 2.点击项目名,获取http的URL 3.idea打开,选择git 4.设置项目路径以及本地保存 ...
- JWT对SpringCloud进行系统认证和服务鉴权
JWT对SpringCloud进行系统认证和服务鉴权 一.为什么要使用jwt?在微服务架构下的服务基本都是无状态的,传统的使用session的方式不再适用,如果使用的话需要做同步session机制,所 ...
- Kubectl Rollout 回滚及Autoscale自动扩容
Kubectl Rollout 回滚及Autoscale自动扩容 Kubernetes 中采用ReplicaSet(简称RS)来管理Pod.如果当前集群中的Pod实例数少于目标值,RS 会拉起新的Po ...
- Springboot项目中Pom.xml报错
摘要:使用idea,两次在maven上浪费时间,第一次不知道怎么就解决了,第二次记录一下解决办法 参考博客地址: https://blog.csdn.net/u013129944/article/de ...
- AbsInt — 确保代码安全的性能/资源分析工具套件
德国AbsInt公司是一家安全苛求软件研发.确认.验证和认证工具链的供应商,能够为客户提供完整的确保代码安全的性能分析工具套件以及软件分析.验证.确认和编译器技术相关咨询服务.AbsI ...
- poj3522Slim Span(暴力+Kruskal)
思路: 最小生成树是瓶颈生成树,瓶颈生成树满足最大边最小. 数据量较小,所以只需要通过Kruskal,将边按权值从小到大排序,枚举最小边求最小生成树,时间复杂度为O( nm(logm) ) #incl ...
- JAVA的概念理解:JavaSE、JavaEE、JavaME、jdk、jre、ide
JavaSE是Java Standard Edtion的缩写,译成中文就是Java标准版,也是Java的核心.无论是 JavaEE(Java企业版)还是JavaME(Java微型版)都是以JavaSE ...
- 《exception》第九次团队作业:Beta冲刺与验收准备(第二天)
一.项目基本介绍 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 Exception 作业学习目标 1.掌握软件黑盒测试技术:2.学会编制软件项目 ...
- spring配置文件ApplicationContext.xml里面class等没有提示功能
实现效果: 解决方法: windows–>preference—>myeclipse—>files and editors–>xml—>xmlcatalog 点击add ...
- jvm 堆栈概念
关于JVM的工作原理以及调优是一个向往已久的模块,终于有幸接触到:http://pengjiaheng.iteye.com/blog/518623 那就顺着这个思路,来梳理一下自己看到后的结论和感想. ...