Google BERT摘要
1.BERT模型
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
1.1 模型结构
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
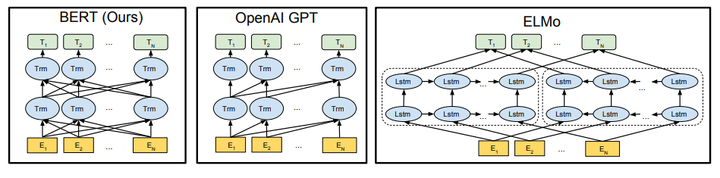
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
1.2 Embedding
这里的Embedding由三种Embedding求和而成:
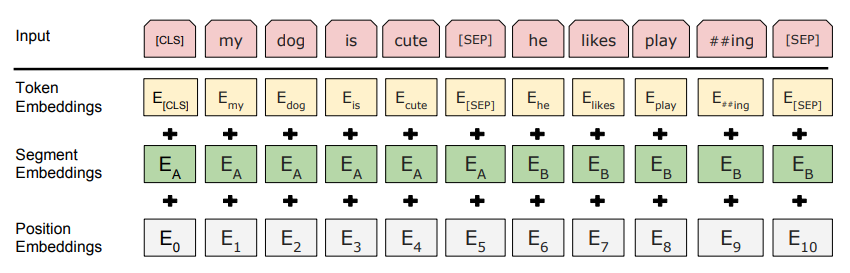
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
总结:
1. BERT的特征提取,是在捕捉词的(前后)位置关系。bidirectional决定了能获得前后的关系,position embedding决定了能学到更长的顺序关系。
2.训练,分为pre-train和fine-tune。pre-train中用到了MLM, Masked LM.
3. trick: MLM. 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
4. 缺点: (1)[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
(2)每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
https://zhuanlan.zhihu.com/p/46652512
https://arxiv.org/pdf/1810.04805.pdf
Google BERT摘要的更多相关文章
- Google BERT应用之《红楼梦》对话人物提取
Google BERT应用之<红楼梦>对话人物提取 https://www.jiqizhixin.com/articles/2019-01-24-19
- Google BERT
概述 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不 ...
- HTML5扩展之微数据与丰富网页摘要
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- HTML5扩展之微数据与丰富网页摘要itemscope, itemtype, itemprop
HTML5扩展之微数据与丰富网页摘要 by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpr ...
- HTML5扩展之微数据与丰富网页摘要——张鑫旭
一.微数据是? 一个页面的内容,例如人物.事件或评论不仅要给用户看,还要让机器可识别.而目前机器智能程度有限,要让其知会特定内容含义,我们需要使用规定的标签.属性名以及特定用法等.举个简单例子,我们使 ...
- Google论文BigTable拜读
这周少打点dota2,争取把这篇论文读懂并呈现出来,和大家一起分享. 先把论文搞懂,然后再看下和论文搭界的知识,比如hbase,Chubby和Paxos算法. Bigtable: A Distribu ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
- 我爱自然语言处理bert ner chinese
BERT相关论文.文章和代码资源汇总 4条回复 BERT最近太火,蹭个热点,整理一下相关的资源,包括Paper, 代码和文章解读. 1.Google官方: 1) BERT: Pre-training ...
随机推荐
- 13、Python文件处理、os模块、json/pickle序列化模块
一.字符编码 Python3中字符串默认为Unicode编码. str类型的数据可以编码成其他字符编码的格式,编码的结果为bytes类型. # coding:gbk x = '上' # 当程序执行时, ...
- Invalid bound statement (not found): com.taotao.mapper.TbItemMapper.selectByPrimaryKey
Invalid bound statement (not found): com.taotao.mapper.TbItemMapper.selectByPrimaryKey Invalid bound ...
- 74HC595 8位移位寄存器的使用小结
请查看我的博客园文章,比较详细. https://www.cnblogs.com/CodeWorkerLiMing/p/11964258.html
- iOS开源库分类
语言库 rx aop kvo 功能库 UI network data-model-map cache 跨平台库 wkjscorebridge jspatch 性能监控库:友盟 部署库:jspathc ...
- Optional类的基本使用(没怎么看)
参考:https://www.runoob.com/java/java8-optional-class.html java8中引入了一个新类:Optional,用于日常编码中对空指针异常进行限制和处理 ...
- 第1章 Spring的应用
一.Spring 的两种核心容器:BeanFactory 和 ApplicationContext(都通过xml加载Bean的) 二.通过ApplicationContext实例化: 1.通过Clas ...
- java 参数传递、对象、封装
参数传递分为值传递(传值)和引用传递(传地址). 面向对象的三大特征: 1. 封装 2. 继承 3. 多态 封装表现: 1.方法就是一个最基本封装体. 2.类其实也是一个封装体. 封装的好处: 1.提 ...
- C++后端工程师需要看的书籍
C++基础书籍<C++ primer><深度探索C++对象模型><Effective C++><more effective C++><STL源码 ...
- 洛谷P1084 运输计划
题目 题目要求使一条边边权为0时,m条路径的长度最大值的最小值. 考虑二分此长度最大值 首先需要用lca求出树上两点间的路径长度.然后取所有比mid大的路径的交集,判断有哪些边在这些路径上都有出现,然 ...
- libvirt原理
引用原文: https://blog.csdn.net/BtB5e6Nsu1g511Eg5XEg/article/details/80142155 libvirt是目前使用最为广泛的针对KVM虚拟机进 ...