2019.11.11 模拟赛 T2 乘积求和

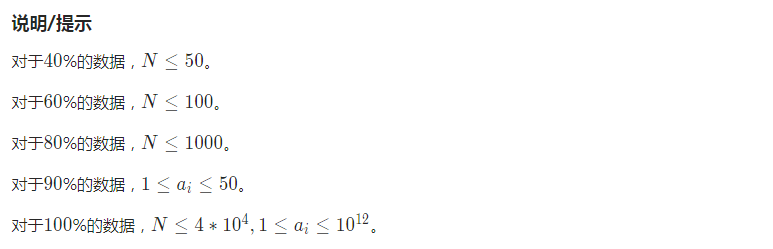
昨天 ych 的膜你赛,这道题我 O ( n4 ) 暴力拿了 60 pts。
这道题的做法还挺妙的,我搞了将近一天呢qwq
题解
60 pts
根据题目给出的式子,四层 for 循环暴力枚举统计答案即可;
#include<iostream>
#include<cstdio>
using namespace std;
int read()
{
char ch=getchar();
int a=,x=;
while(ch<''||ch>'')
{
if(ch=='-') x=-x;
ch=getchar();
}
while(ch>=''&&ch<='')
{
a=(a<<)+(a<<)+(ch-'');
ch=getchar();
}
return a*x;
}
const long long mod=1e12+;
int n;
long long ans,a[];
int main()
{
freopen("multiplication.in","r",stdin);
freopen("multiplication.out","w",stdout);
n=read();
for(int i=;i<=n;i++) a[i]=read();
for(int l=;l<=n;l++)
for(int r=l;r<=n;r++)
for(int i=l;i<=r;i++)
for(int j=i+;j<=r;j++)
if(a[i]>a[j])
ans=(ans+a[i]*a[j]%mod)%mod;
printf("%lld\n",ans);
return ;
}
80 pts
方法一:预处理 + O ( n2 )
我们可以翻译一下题目中给出的式子:
就是求所有区间中每个区间的逆序对乘积;
那么我们可以提前预处理出每个区间的答案,再统计答案;
时间复杂的 O ( n2 ),期望得分 80 pts;
for(int i=;i<=n;i++)
{
for(int j=i;j<=n;j++)
{
f[i][j]=f[i][j-];
if(a[j]<a[i]) f[i][j]=(f[i][j]+a[i]*a[j]%mod)%mod;
}
}
for(int i=;i<=n;i++)
{
for(int j=i+;j<=n;j++)
{
ans=(ans+i*f[i][j])%mod;
}
}
方法二:归并排序
考虑一对逆序对 ( ai , aj ) 会在所有的区间内出现几次 。
因为同时包含 ai 和 aj 的最小区间是 [ i , j ],所以左端点小于等于 i,右端点大于等于 j 的所有区间也包含,所有共有 i * ( n - j + 1 );
所以我们可以去找出所有的逆序对,然后去计算他们对答案的贡献;
求逆序对,我们可以用归并排序;
具体思路就是在两部分合并的过程中,如果左半部分的某个数 ai 大于右半部分某个数 aj ,这时候从 ai ~ amid 都会与 aj 产生一组逆序对,我们统计答案就好了;
#include<iostream>
#include<cstdio>
using namespace std;
long long read()
{
char ch=getchar();
long long a=,x=;
while(ch<''||ch>'')
{
if(ch=='-') x=-x;
ch=getchar();
}
while(ch>=''&&ch<='')
{
a=(a<<)+(a<<)+(ch-'');
ch=getchar();
}
return a*x;
}
const long long mod=1e12+;
const int N=5e4;
long long n,ans;
struct node
{
long long val,id;
}a[N],c[N];
void gb_sort(int l,int r)
{
if(l==r) return ;
int mid=(l+r)>>;
gb_sort(l,mid);
gb_sort(mid+,r);
int i=l,j=mid+;
int k=l-;
while(i<=mid&&j<=r)
{
if(a[i].val>a[j].val)
{
for(int l=i;l<=mid;l++)
ans=(ans+a[l].val*a[j].val%mod*a[l].id*(n-a[j].id+)%mod)%mod;
//printf("%lld\n",ans);
c[++k].val=a[j].val;c[k].id=a[j].id;
j++;
}
else
{
c[++k].val=a[i].val;c[k].id=a[i].id;
i++;
}
}
while(i<=mid)
{
c[++k].val=a[i].val;c[k].id=a[i].id;
i++;
}
while(j<=r)
{
c[++k].val=a[j].val;c[k].id=a[j].id;
j++;
}
for(int i=l;i<=r;i++)
{
a[i].id=c[i].id;
a[i].val=c[i].val;
}
}
int main()
{
freopen("multiplication.in","r",stdin);
freopen("multiplication.out","w",stdout);
n=read();
for(int i=;i<=n;i++)
{
a[i].val=read();
a[i].id=i;
}
gb_sort(,n);
printf("%lld\n",ans);
return ;
}
90 pts
发现正是归并排序统计答案的时候是 O ( n ) 的,使得复杂度升高了;
我们想能不能优化下:
还是按照上面的思路,如果在合并的时候有 ai > aj ,则 ai ~ amid 都会与 aj 产生逆序对,那么 aj 产生的贡献之和就是:
ai * aj * i * ( n - j + 1 ) + ai+1 * aj * ( i+1 ) * ( n - j + 1 ) + …… + amid * aj * mid * ( n - j + 1 )
我们将 aj * ( n - j + 1 ) 提出来就是:
aj * ( n - j + 1 ) * [ ai * i + ai+1 * ( i+1 ) + ai+2 * ( i+2 ) + amid * mid ]
也就是说,我们可以统计在 aj 之前的所有数中,每个比 aj 大的数 ai 再乘上 ai 的下标 i 的和是多少,记为 sum;
则 sum = ai * i + ai+1 * ( i+1 ) + ai+2 * ( i+2 ) + amid * mid,那么 aj 对答案的贡献就是:sum * aj * ( n - j + 1 )
然后我们发现这东西可以用权值树状数组来维护:
每个下标为 i 的数组维护 ai * i 的值是多少,当我们对原数列的数依次放到树状数组的时候,由于前面的数已经放进去了,我们可以去统计有所有比当前数大的数(可以与当前数构成逆序对的数)它们的 ai * i 的值的和是多少;由于是权值树状数组,所以比当前数要大的数在树状数组里的编号是比当前数的编号大的,所以我们可以求后缀和;但是由于我们不会求后缀和,所以我们可以把权值树状数组的编号反过来存,大的在前面,小的在后面,这样就转化成了我们熟悉的前缀和啦;
但是由于每个元素的权值范围较大,且逆序对的产生只与两个数的大小关系有关,与两个数具体是多少无关,所以我们可以先离散化;
时间复杂度 O ( nlog n ),期望得分 90 pts;
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
long long read()
{
char ch=getchar();
long long a=,x=;
while(ch<''||ch>'')
{
if(ch=='-') x=-x;
ch=getchar();
}
while(ch>=''&&ch<='')
{
a=(a<<)+(a<<)+(ch-'');
ch=getchar();
}
return a*x;
}
const long long mod=1e12+;
const long long N=1e5;
long long n;
long long ans,c[N];
struct node
{
long long id,val,rank;
}a[N];
bool cmp1(node x,node y)
{
if(x.val!=y.val)
return x.val<y.val;
return x.id<y.id;
}
bool cmp2(node x,node y)
{
return x.id<y.id;
}
void lsh() //离散化
{
sort(a+,a++n,cmp1); //先按照大小排序
for(long long i=;i<=n;i++) a[i].rank=i; //按大小关系给每个元素分个排名,就是离散化之后的大小
sort(a+,a++n,cmp2); //再按照在原序列里的编号排回去
}
long long lowbit(long long x)
{
return x&(-x);
}
long long ask(long long x) //树状数组求[1,x]的和
{
long long y=;
for(long long i=x;i;i-=lowbit(i)) y=(y+c[i]+mod)%mod;
return y;
}
void add(long long x,long long y) //将第x个数加y
{
for(long long i=x;i<=n;i+=lowbit(i)) c[i]=(c[i]+y+mod)%mod;
}
int main()
{
freopen("multiplication.in","r",stdin);
freopen("multiplication.out","w",stdout);
n=read();
for(long long i=;i<=n;i++)
{
a[i].val=read(); //每个元素的大小
a[i].id=i; //每个元素在原序列里的编号(是第几个)
}
lsh(); //离散化
for(long long i=;i<=n;i++) //依次将每个数丢进树状数组
{
long long sum=ask(n-a[i].rank+); //求一次前缀和,注意这里大小编号是反着的
ans=(ans+sum*a[i].val%mod*(n-a[i].id+)%mod)%mod; //算当前元素对答案的贡献
add(n-a[i].rank+,a[i].id*a[i].val%mod); //将当前元素丢进树状数组里,维护的是这个数的下标*权值
}
printf("%lld\n",ans%mod);
return ;
}
100 pts
不是,我时间复杂度 O ( nlog n ) 跑的飞快啊,怎么还没满分?
有一个小细节需要注意:
我们的模数是 1012 +7,两个数相乘很可能爆 long long 的。
这时候我们就要用到龟速乘了qwq:
龟速乘
龟速乘好像就是来弥补快速幂的 bug 的,虽然计算速度真的龟速。。。
它的原理是这样的:
假如我们现在要计算一个简单的式子:3 * 23
然后我们将 23 用二进制表示一下子:( 23 )10 = ( 10111 )2
那么我们可以将 23 写成这个形式:23 = 20 + 21 + 22 + 24
然后我们再将其代回原式:3 * 23 = 3 * ( 20 + 21 + 22 + 24 ) = 3 * 20 + 3 * 21 + 3 * 22 + 3 * 24
然后我们发现每次加的 3 的系数都是原来的两倍,这一点与快速幂类似;
代码实现:
long long slow_pow(long long a,long long b) //龟速乘计算a*b
{
long long tot=;
while(b)
{
if(b&) tot=(tot+a+mod)%mod;
a=(a+a+mod)%mod; //每次变为原来的2倍
b>>=;
}
return tot;
}
然后套上龟速乘,这个题最后的坑就被我们填完了,完整AC代码如下:
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
long long read()
{
char ch=getchar();
long long a=,x=;
while(ch<''||ch>'')
{
if(ch=='-') x=-x;
ch=getchar();
}
while(ch>=''&&ch<='')
{
a=(a<<)+(a<<)+(ch-'');
ch=getchar();
}
return a*x;
}
const long long mod=1e12+;
const long long N=1e5;
long long n;
long long ans,c[N];
struct node
{
long long id,val,rank;
}a[N];
long long slow_pow(long long a,long long b) //龟速乘计算a*b
{
long long tot=;
while(b)
{
if(b&) tot=(tot+a+mod)%mod;
a=(a+a+mod)%mod; //每次变为原来的2倍
b>>=;
}
return tot;
}
bool cmp1(node x,node y)
{
if(x.val!=y.val)
return x.val<y.val;
return x.id<y.id;
}
bool cmp2(node x,node y)
{
return x.id<y.id;
}
void lsh() //离散化
{
sort(a+,a++n,cmp1); //先按照大小排序
for(long long i=;i<=n;i++) a[i].rank=i; //按大小关系给每个元素分个排名,就是离散化之后的大小
sort(a+,a++n,cmp2); //再按照在原序列里的编号排回去
}
long long lowbit(long long x)
{
return x&(-x);
}
long long ask(long long x) //树状数组求[1,x]的和
{
long long y=;
for(long long i=x;i;i-=lowbit(i)) y=(y+c[i]+mod)%mod;
return y;
}
void add(long long x,long long y) //将第x个数加y
{
for(long long i=x;i<=n;i+=lowbit(i)) c[i]=(c[i]+y+mod)%mod;
}
int main()
{
freopen("multiplication.in","r",stdin);
freopen("multiplication.out","w",stdout);
n=read();
for(long long i=;i<=n;i++)
{
a[i].val=read(); //每个元素的大小
a[i].id=i; //每个元素在原序列里的编号(是第几个)
}
lsh(); //离散化
for(long long i=;i<=n;i++) //依次将每个数丢进树状数组
{
long long sum=ask(n-a[i].rank+); //求一次前缀和,注意这里大小编号是反着的
ans=(ans+slow_pow(slow_pow(sum,a[i].val)%mod,(n-a[i].id+))%mod)%mod; //算当前元素对答案的贡献
add(n-a[i].rank+,slow_pow(a[i].id,a[i].val)%mod); //将当前元素丢进树状数组里,维护的是这个数的下标*权值
}
printf("%lld\n",ans%mod);
return ;
}
这道题让我重新温习了我不熟悉的数据结构,让我距目标更近了一步呢,最后,CSP 加油!
2019.11.11 模拟赛 T2 乘积求和的更多相关文章
- 2019.08.06模拟赛T2
题目大意: 已知三个$n$位二进制数$A$,$B$,$C$. 满足: $A+B=C$ 它们二进制位中$1$的个数分别为$a$,$b$,$c$. 求满足条件的最小的$C$. Solution 唉,又是一 ...
- 9.11 myl模拟赛
9.11 myl 模拟赛 100 + 100 + 0 第一题耗费了太多的时间,导致最后一题没有时间想,直接去写了暴力,而且出题人没有给暴力分.... Problem 1. superman [题目描述 ...
- 模拟赛T2 交换 解题报告
模拟赛T2 交换 解题报告 题目大意: 给定一个序列和若干个区间,每次从区间中选择两个数修改使字典序最小. \(n,m\) 同阶 \(10^6\) 2.1 算法 1 按照题意模拟,枚举交换位置并比较. ...
- 20180414模拟赛T2——拼图
拼图 源程序名 puzzling.??? (PAS,BAS,C,CPP) 可执行文件名 puzzling.EXE 输入文件名 puzzling.IN 输出文件名 puzzling.OUT 时间限制 1 ...
- 【2019.8.11下午 慈溪模拟赛 T2】数数(gcd)(分块+枚举因数)
莫比乌斯反演 考虑先推式子: \[\sum_{i=l}^r[gcd(a_i,G)=1]\] \[\sum_{i=l}^r\sum_{p|a_i,p|G}\mu(p)\] \[\sum_{p|G}\mu ...
- 【2019.8.11上午 慈溪模拟赛 T2】十七公斤重的文明(seventeen)(奇偶性讨论+动态规划)
题意转化 考虑我们对于集合中每一个\(i\),若\(i-2,i+k\)存在,就向其连边. 那么,一个合法的集合就需要满足,不会存在环. 这样问题转化到了图上,就变得具体了许多,也就更容易考虑.求解了. ...
- 11.1NOIP模拟赛解题报告
心路历程 预计得分:\(100 + 100 + 50\) 实际得分:\(100 + 100 + 50\) 感觉老师找的题有点水呀. 上来看T1,woc?裸的等比数列求和?然而我不会公式呀..感觉要凉 ...
- 2017.6.11 NOIP模拟赛
题目链接: http://files.cnblogs.com/files/TheRoadToTheGold/2017-6.11NOIP%E6%A8%A1%E6%8B%9F%E8%B5%9B.zip 期 ...
- 11.17 模拟赛&&day-2
/* 后天就要复赛了啊啊啊啊啊. 可能是因为我是一个比较念旧的人吧. 讲真 还真是有点不舍. 转眼间一年的时间就过去了. 2015.12-2016.11. OI的一年. NOIP gryz RP++. ...
随机推荐
- Navicat 连接mysql 报错: Authentication plugin caching_ sha2_password cannot be loaded
出现这个错误的时候, 网上的资料都是修改mysql的登录信息的, ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password ...
- java第四次面试总结
该公司没有笔试,直接就进行了面试,然后我就拿着我的简历瑟瑟发抖...... 1.因为是看简历来面试,所以面试官从我的项目下手,而我的项目都是后端的东西,虽然学过一些前端,但是项目里并没有用到任何jav ...
- 网络编程-tcp三次握手和四次挥手
TCP三次握手和四次挥手过程 1.三次握手 (1)三次握手的详述 首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源.Client端接收到ACK报文后也向 ...
- ES6之promise原理
我在这里介绍了promise的原理: https://juejin.im/post/5cc54877f265da03b8585902 我在这里 仅仅张贴 我自己实现的简易promise——DiProm ...
- jQuery.each的function中有哪些参数
1.没有参数 $("img").each(function(){ $(this).toggleClass("example"); }); 2.有一个参数,这个参 ...
- ceph luminous版部署bluestore
简介 与filestore最大的不同是,bluestore可以直接读写磁盘,即对象数据是直接存放在裸设备上的,这样解决了一直被抱怨的数据双份写的问题 Bluestore直接使用一个原始分区来存放cep ...
- vue项目配置Mock.js
扯在前面 最近一直在忙跳槽的事情,博客也好久没有更新了,上次更新还是去年,不出意外的话,从今天起继续今年的博客之旅. 今天继续完善我之前的项目架构,从零开始搭建vue移动端项目到上线,有需要的同学可以 ...
- MySQL Lock--MySQL加锁学习2
准备测试数据: ## 开启InnoDB Monitor SET GLOBAL innodb_status_output=ON; SET GLOBAL innodb_status_output_lock ...
- sql语句,数据库中,同表添加,主键不同,数据相同。
insert into tablename(各个字段名) select #新主键值,其他字段名 from tablename where No = #表中主键值
- Burp Suite Extension tools
1.Setting up the envrionment for burp Extensions before we can write extensions we need to ensure ...