Docker Swarm部署集群
一、Swarm简介
Swarm是Docker的一个编排工具,参考官网:https://docs.docker.com/engine/swarm/
Swarm 模式简介
- 要在Swarm模式下运行docker,需要先安装docker,参考安装教程
- 当前版本的docker包含了swarm模式,用于管理docker集群。可以使用命令行来创建swarm集群,部署应用,管理swarm的行为。
如果你使用低于1.12.0版本的docker,可以使用独立模式的是swarm,但是建议使用最新版本
特性
- 与docker集成的集群管理工具
- 去中心化设计,只使用docker引擎即可创建各类节点
- 声明式服务模型。可以声明的方式来定义应用。
- 动态伸缩。管理节点自动调整服务数量。
- 高可用,对于服务期望状态做到动态调整,swarm的管理节点会持续监控集群状态,集群中有没有达到期望状态的服务,管理节点会自动调度来达到期望状态。
- 自定义网络。可以为你的服务指定一个网络,容器创建的时候分配一个IP
- 服务发现。管理节点给集群中每个服务一个特定的DNS名字,并给运行的容器提供负载均衡。
- 负载均衡。你可以暴露服务端口给外部的负载均衡。内部swarm提供可配置的容器分配到节点的策略。
- 默认的安全机制。swarm集群中各个节点强制TLS协议验证。连接加密,你可以自定义根证书。
滚动更新。增量跟新,可以自定义更新下个节点的时间间隔,如果有问题,可以会滚到上个版本。
二、安装Swarm
本教程进行如下指导:
- 在swarm模式下初始化一个基于docker引擎的swarm集群
- 在swarm集群中添加节点
- 部署应用服务到swarm集群中
- 管理swarm集群
本教程使用docker命令行的方式交互
安装
安装环境要求
- 3台可以网络通信的Linux主机,并且安装了docker
- 安装1.12.0以上的docker
- 管理节点的IP地址
- 主机之间开放端口
准备3台主机
3台主机可以是物理机,虚拟机,云主机,甚至是docker machine创建的主机。并安装docker。三台主机分别是manager1,work1和worker2.
安装1.12.0以上的docker
- 参考:在linux上安装docker
管理节点的IP地址
所有swarm集群中的节点都会连接到管理节点的IP地址
主机间开放端口
- 以下端口必须是开放的:
- TCP port 2377为集群管理通信
- TCP and UDP port 7946 为节点间通信
- UDP port 4789 为网络间流量
如果你想使用加密网络(--opt encrypted)也需要确保ip protocol 50 (ESP)是可用的
环境说明
| 操作系统 | 主机名 | ip地址 | docker版本 |
| ubuntu-16.04.4-server-amd64 | manager1 | 192.168.10.104 | Docker version 18.09.2 |
| ubuntu-16.04.4-server-amd64 | work1 | 192.168.10.108 | Docker version 18.09.2 |
| ubuntu-16.04.4-server-amd64 | work2 | 192.168.10.110 | Docker version 18.09.2 |
创建一个Swarm集群
完成上面的开始过程后,可以开始创建一个swarm集群。确保docker的后台应用已经在主机上运行了。
登陆到manager1上,如果使用docker-machine创建的主机,可以docker-machine ssh manager1
运行以下命令来创建一个新的swarm集群:
docker swarm init --advertise-addr <MANAGER1-IP>
MANAGER1-IP 表示管理节点
本教程中使用如下命令在manager1上创建swarm集群:
root@manager1:~# docker swarm init --advertise-addr 192.168.10.104
Swarm initialized: current node (zmvmswnwv6jcvjt1tmq65zzkg) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN--4q7uby9b9vjrjryrvl9r7kgq23hx0y6nwmdt3b9kmxpfcn7vmu-97op3d7nkn8rp31e0boz0308w 192.168.10.104: To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
- --advertise-addr 选项表示管理节点公布它的IP是多少。其它节点必须能通过这个IP找到管理节点。
- 命令输出了加入swarm集群的命令。通过--token选项来判断是加入为管理节点还是工作节点
1. 运行docker info来查看当前swarm集群的状态:
root@manager1:~# docker -v
Docker version 18.09., build
root@manager1:~# docker info
Containers:
Running:
Paused:
Stopped:
Images:
Server Version: 18.09.
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: active
NodeID: zmvmswnwv6jcvjt1tmq65zzkg
Is Manager: true
ClusterID: 04doas9mydex8aq4vadh0b0go
Managers:
Nodes:
Default Address Pool: 10.0.0.0/
SubnetSize:
Orchestration:
Task History Retention Limit:
Raft:
Snapshot Interval:
Number of Old Snapshots to Retain:
Heartbeat Tick:
Election Tick:
Dispatcher:
Heartbeat Period: seconds
CA Configuration:
Expiry Duration: months
Force Rotate:
Autolock Managers: false
Root Rotation In Progress: false
Node Address: 192.168.10.104
Manager Addresses:
192.168.10.104:
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 9754871865f7fe2f4e74d43e2fc7ccd237edcbce
runc version: 09c8266bf2fcf9519a651b04ae54c967b9ab86ec
init version: v0.18.0 (expected: fec3683b971d9c3ef73f284f176672c44b448662)
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 4.4.--generic
Operating System: Ubuntu 16.04. LTS
OSType: linux
Architecture: x86_64
CPUs:
Total Memory: .859GiB
Name: manager1
ID: 7N32:4Z4C:V5JN:L4I4:PR3K:KRN7:RR6M:MYR6:TBYG:EB5C:MDTA:CRTY
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/
Live Restore Enabled: false WARNING: No swap limit support
运行docker node ls来查看节点信息
root@manager1:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
zmvmswnwv6jcvjt1tmq65zzkg * manager1 Ready Active Leader 18.09.
- nodeId 旁边的*号表示你当前连接到的节点。
- docker引擎的swarm模式自动使用宿主机的主机名作为节点名。
将节点加入到swarm集群中
一旦前面的创建swarm集群完成,你就可以加入工作节点了。
ssh到要加入集群的节点上,我们要加入worker1.
运行创建swarm集群时候产生的命令来将woker1加入到集群中:
root@work1:~# docker swarm join --token SWMTKN-1-4q7uby9b9vjrjryrvl9r7kgq23hx0y6nwmdt3b9kmxpfcn7vmu-97op3d7nkn8rp31e0boz0308w 192.168.10.104:2377
This node joined a swarm as a worker.
如果你找不到加入命令了,可以在管理节点运行下列命令找回加入命令:
root@manager1:~# docker swarm join-token worker
To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN--4q7uby9b9vjrjryrvl9r7kgq23hx0y6nwmdt3b9kmxpfcn7vmu-97op3d7nkn8rp31e0boz0308w 192.168.10.104:
ssh到worker2
运行加入集群的命令来将worker2加入到集群:
root@worker2:~# docker swarm join --token SWMTKN-1-4q7uby9b9vjrjryrvl9r7kgq23hx0y6nwmdt3b9kmxpfcn7vmu-97op3d7nkn8rp31e0boz0308w 192.168.10.104:2377
This node joined a swarm as a worker.
ssh到manager1节点运行docker node ls命令来查看集群节点情况:
root@manager1:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
zmvmswnwv6jcvjt1tmq65zzkg * manager1 Ready Active Leader 18.09.
pi6ori8t1tuestb3hzhnn265v work1 Ready Active 18.09.
ohivom1sdi1vz1oaer1b9wpl0 work2 Ready Active 18.09.
MANAGER列表明了集群中的管理节点。worker节点的空意味着它们是工作节点
三、部署服务
在创建一个swarm集群后,就可以部署服务了。本教程中你也可以加入工作节点,但是不是必须的。
ssh到manager1节点
运行如下命令:
root@manager1:~# docker service create --replicas 1 --name helloworld alpine ping docker.com
qf8qydwuah1ym9xj5yxrxvhak
overall progress: out of tasks
/: running
verify: Service converged
- docker service create用来创建服务
- --name表明服务名字是helloworld
- --replicas 表示期望1个服务实例
- alpine ping docker.com 表示运行镜像是alpine,命令是ping
运行docker service ls来查看运行的服务:
root@manager1:~# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
qf8qydwuah1y helloworld replicated / alpine:latest
四、检查服务
在你部署服务到Swarm集群上后,可以使用命令行来检查运行的服务
ssh到管理节点
运行命令docker service inspect --pretty <ID> 来查看优化显示的服务详情
root@manager1:~# docker service inspect --pretty qf8qydwuah1y ID: qf8qydwuah1ym9xj5yxrxvhak
Name: helloworld
Service Mode: Replicated
Replicas:
Placement:
UpdateConfig:
Parallelism:
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Update order: stop-first
RollbackConfig:
Parallelism:
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:72c42ed48c3a2db31b7dafe17d275b634664a708d901ec9fd57b1529280f01fb
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vip
去掉--pretty选项将以json格式输出
运行docker service ps <ID> 将查看到哪些节点在运行该服务实例:
root@manager1:~# docker service ps qf8qydwuah1y
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
6u05btfqzo6j helloworld. alpine:latest manager1 Running Running minutes ago
- 服务可能运行在管理或工作节点上,默认的管理节点可以像工作节点一样运行任务。
- 该命令也显示服务期望的状态DESIRED STATE ,和实际的状态CURRENT STATE。
在运行任务的节点上运行docker ps也能看到这个任务运行的容器。备注:目前运行在manager1上面
root@manager1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
236ed4a13f7a alpine:latest "ping docker.com" minutes ago Up minutes helloworld..6u05btfqzo6j4mo4uxm5543mi
五、动态伸缩服务实例数
一旦你在swarm集群中部署一个服务后,你就可以使用命令行来改变服务的实例个数。在服务中运行的容器称为“任务”
语法:
docker service scale <ID>=数量
ssh到manager1节点
运行以下命令来改变服务的期望实例数:
root@manager1:~# docker service scale qf8qydwuah1y=3
qf8qydwuah1y scaled to
overall progress: out of tasks
/: running
/: running
/: running
verify: Service converged
运行以下命令来查看更新的任务列表:
root@manager1:~# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
qf8qydwuah1y helloworld replicated / alpine:latest
root@manager1:~# docker service ps qf8qydwuah1y
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
6u05btfqzo6j helloworld. alpine:latest manager1 Running Running minutes ago
m96ohuz60dw4 helloworld. alpine:latest work1 Running Running about a minute ago
9dldkulmsvwj helloworld. alpine:latest work2 Running Running about a minute ago
可以看到这3个任务被分布到了集群中的不同节点
ssh到运行服务的主机work1上运行docker ps查看运行的容器:
root@work1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fafaa17a2c6a alpine:latest "ping docker.com" minutes ago Up minutes helloworld..m96ohuz60dw4twr9np4kd8hz3
六、删除应用
接下来删除应用
ssh到管理节点
运行docker service rm <ID>来删除服务:
root@manager1:~# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
qf8qydwuah1y helloworld replicated / alpine:latest
root@manager1:~# docker service rm qf8qydwuah1y
qf8qydwuah1y
root@manager1:~# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
运行docker service inspect <ID>会发现服务不存在了
root@manager1:~# docker service inspect qf8qydwuah1y
[]
Status: Error: no such service: qf8qydwuah1y, Code:
尽管服务不存在了,任务容器还需要几秒钟来清理,你可以在节点上docker ps查看任务什么时候被移除。
七、滚动更新
在前面的章节中,修改了实例数。本节使用etcd:2.0.5 镜像来部署服务,然后滚动升级到etcd:2.0.10
ssh到管理节点
部署etcd:2.0.5 服务,配置10s的更新间隔:
root@manager1:~# docker service create --replicas 2 --name etcd --update-delay 10s elcolio/etcd:2.0.5 vh7w3mq5q0vc634w8x6m8r3m6
overall progress: out of tasks
/: running
/: running
verify: Service converged
- 注意:教程使用的是redis镜像,我使用的是etcd镜像拉
- 在服务部署阶段就指定滚动升级策略
- --update-delay配置了更新服务的时间间隔,你可以指定时间T为秒是Ts,分是Tm,或时是Th,所以10m30s就是10分30秒的延迟
- 默认的调度器scheduler一次更新一个任务.你可以传入参数--update-parallelism来配置调度器同时更新的最大任务数量
- 默认的当一个更新任务返回RUNNING状态后,调度器才调度另一个更新任务,直到所有任务都更新了。如果更新过程中任何任务返回了FAILED,调度器就会停止更新。你可以给命令docker service create or docker service update配置配置--update-failure-action,来配置这个行为。
查看etcd服务
root@manager1:~# docker service inspect --pretty etcd ID: vh7w3mq5q0vc634w8x6m8r3m6
Name: etcd
Service Mode: Replicated
Replicas:
Placement:
UpdateConfig:
Parallelism:
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Update order: stop-first
RollbackConfig:
Parallelism:
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Rollback order: stop-first
ContainerSpec:
Image: elcolio/etcd:2.0.@sha256:fa9c5bdfd7164b75d944da3693d891e1fd18c7c757bbb5c00caa99aef312a428
Init: false
Resources:
Endpoint Mode: vip
现在可以更新etcd的容器镜像了,语法:
docker service update --image <镜像名> <服务名>
运行以下命令,swarm的管理节点将会根据更新策略UpdateConfig来更新各个节点:
root@manager1:~# docker service update --image elcolio/etcd:2.0.10 etcd
etcd
overall progress: out of tasks
/: running
/: running
verify: Service converged
调度器依照以下步骤来滚动更新:
- 停止第一个任务
- 对停止的任务进行更新
- 对更新的任务进行启动
- 如果更新的任务返回RUNNING,等待特定间隔后启动下一个任务
- 如果在任何更新的时间,任务返回了FAILED,则停止更新。
运行命令docker service inspect --pretty etcd来查看新镜像的期望状态,可以看到显示了UpdateStatus完成。
root@manager1:~# docker service inspect --pretty etcd ID: vh7w3mq5q0vc634w8x6m8r3m6
Name: etcd
Service Mode: Replicated
Replicas:
UpdateStatus:
State: completed
Started: minutes ago
Completed: About a minute ago
Message: update completed
Placement:
UpdateConfig:
Parallelism:
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Update order: stop-first
RollbackConfig:
Parallelism:
On failure: pause
Monitoring Period: 5s
Max failure ratio:
Rollback order: stop-first
ContainerSpec:
Image: elcolio/etcd:2.0.@sha256:9a2e9a6ad26ddd87204b248c38d18b397881fc16283e4ac4ed5bfbf2ce03fa4c
Init: false
Resources:
Endpoint Mode: vip
如果中间有升级失败的,则会显示如下信息:
$ docker service inspect --pretty etcd ID: 0u6a4s31ybk7yw2wyvtikmu50
Name: redis
...snip...
Update status:
State: paused
Started: seconds ago
Message: update paused due to failure or early termination of task 9p7ith557h8ndf0ui9s0q951b
...snip...
- 重新开始一个升级过程:docker service update
- 为了避免重复失败升级,要重新配置服务服务,添加适当的参数在运行docker service update
运行docker service ps <服务名>来查看本次滚动更新的过程:
root@manager1:~# docker service ps etcd
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
nzwtsi4p8stw etcd. elcolio/etcd:2.0. work1 Running Running minutes ago
lom9z7y8rlps \_ etcd. elcolio/etcd:2.0. work1 Shutdown Shutdown minutes ago
8h8xjzyhlq1a etcd. elcolio/etcd:2.0. manager1 Running Running minutes ago
6hpxbv34jnfz \_ etcd. elcolio/etcd:2.0. manager1 Shutdown Shutdown minutes ago
注意升级后老的容器只是停止了,并没有删除
root@manager1:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e905f60e2ec3 elcolio/etcd:2.0. "/bin/run.sh" minutes ago Up minutes -/tcp, /tcp, /tcp etcd..8h8xjzyhlq1a7o5wu5tfqq17z
13886eb8ea94 elcolio/etcd:2.0. "/bin/run.sh" minutes ago Exited () minutes ago etcd..6hpxbv34jnfz0bjl1yx4xnwdd
b0963cce9bf3 elcolio/etcd:2.0. "/bin/run.sh /bin/ba…" minutes ago Exited () minutes ago hopeful_feistel
八、从集群中下线一个节点
- 前面的教程中管理节点会把任务分配给ACTIVE的节点,所有ACTIVE的节点都能接到任务
- 有时候,例如特定的维护时间,我们就需要从集群中下线一个节点。下线节点使节点不会接受新任务,管理节点会停止该节点上的任务,分配到别的ACTIVE的节点上。
- 注意:下线一个节点不移除节点中的独立容器,如docker run,docker-compose up或docker API启动的容器都不会删除。节点的状态仅影响集群服务的负载是否分到该节点。
ssh到manageer1
运行docker node ls,验证所有节点都是ACTIVE的:
root@manager1:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
zmvmswnwv6jcvjt1tmq65zzkg * manager1 Ready Active Leader 18.09.
pi6ori8t1tuestb3hzhnn265v work1 Ready Active 18.09.
ohivom1sdi1vz1oaer1b9wpl0 work2 Ready Active 18.09.
如果弄的etcd服务还没有从滚动更新中起来,需要启动起来:
运行docker service ps etcd查看管理节点如何分配任务到不同节点:
root@manager1:~# docker service ps etcd
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
nzwtsi4p8stw etcd. elcolio/etcd:2.0. work1 Running Running minutes ago
lom9z7y8rlps \_ etcd. elcolio/etcd:2.0. work1 Shutdown Shutdown minutes ago
8h8xjzyhlq1a etcd. elcolio/etcd:2.0. manager1 Running Running minutes ago
6hpxbv34jnfz \_ etcd. elcolio/etcd:2.0. manager1 Shutdown Shutdown minutes ago
运行docker node update --availability drain <NODE>来下线一个节点:
root@manager1:~# docker node update --availability drain manager1
manager1
运行以下来检查节点的可用性:
可以看到该节点的可用性是Drain
root@manager1:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
zmvmswnwv6jcvjt1tmq65zzkg * manager1 Ready Drain Leader 18.09.
pi6ori8t1tuestb3hzhnn265v work1 Ready Active 18.09.
ohivom1sdi1vz1oaer1b9wpl0 work2 Ready Active 18.09.
docker node inspect --pretty manager1
root@manager1:~# docker node inspect --pretty manager1
ID: zmvmswnwv6jcvjt1tmq65zzkg
Hostname: manager1
Joined at: -- ::37.150001136 + utc
Status:
State: Ready
Availability: Drain
Address: 192.168.10.104
Manager Status:
Address: 192.168.10.104:
Raft Status: Reachable
Leader: Yes
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs:
Memory: .859GiB
Plugins:
Log: awslogs, fluentd, gcplogs, gelf, journald, json-file, local, logentries, splunk, syslog
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 18.09.
TLS Info:
TrustRoot:
-----BEGIN CERTIFICATE-----
MIIBajCCARCgAwIBAgIUHwOd2JFLTCBePSGfOYdPvomygdEwCgYIKoZIzj0EAwIw
EzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNMTkwODI0MTIwNzAwWhcNMzkwODE5MTIw
NzAwWjATMREwDwYDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH
A0IABDQ1v1QxJoRfkoo6hWcKkYD6ixGtd/YCnTVuqOcpyh97dQ3qVPUIEJoafORt
5yQCu8mLOCH1mWrXjA2yVo/Z6DqjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB
Af8EBTADAQH/MB0GA1UdDgQWBBT3zbMseoYHkZ60+VhVDGn1qdv4njAKBggqhkjO
PQQDAgNIADBFAiA/nXEN/f6wpUtOWwUBDNAXlKmhp7j+MjfD84+ksu+JEgIhAL6O
ZYp25KHMOGQaVWDPJZIzObWofJvxFwE4hHRkbCaH
-----END CERTIFICATE----- Issuer Subject: MBMxETAPBgNVBAMTCHN3YXJtLWNh
Issuer Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAENDW/VDEmhF+SijqFZwqRgPqLEa139gKdNW6o5ynKH3t1DepU9QgQmhp85G3nJAK7yYs4IfWZateMDbJWj9noOg==
运行docker service ps etcd来查看管理节点是如何重新分配任务的:
可以看到管理节点将下线节点的任务停止了,为了保障副本数量,重新在active的节点上调度了任务。
root@manager1:~# docker service ps etcd
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
nzwtsi4p8stw etcd. elcolio/etcd:2.0. work1 Running Running minutes ago
lom9z7y8rlps \_ etcd. elcolio/etcd:2.0. work1 Shutdown Shutdown minutes ago
31x8luhz56zn etcd. elcolio/etcd:2.0. work2 Running Running about a minute ago
8h8xjzyhlq1a \_ etcd. elcolio/etcd:2.0. manager1 Shutdown Shutdown about a minute ago
6hpxbv34jnfz \_ etcd. elcolio/etcd:2.0. manager1 Shutdown Shutdown minutes ago
运行docker node update --availability active <NODE>来重新active该节点:
root@manager1:~# docker node update --availability active manager1
manager1
查看节点状态,可以看到节点状态重新为Active
root@manager1:~# docker node inspect --pretty manager1
ID: zmvmswnwv6jcvjt1tmq65zzkg
Hostname: manager1
Joined at: -- ::37.150001136 + utc
Status:
State: Ready
Availability: Active
Address: 192.168.10.104
Manager Status:
Address: 192.168.10.104:
Raft Status: Reachable
Leader: Yes
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs:
Memory: .859GiB
Plugins:
Log: awslogs, fluentd, gcplogs, gelf, journald, json-file, local, logentries, splunk, syslog
Network: bridge, host, macvlan, null, overlay
Volume: local
Engine Version: 18.09.
TLS Info:
TrustRoot:
-----BEGIN CERTIFICATE-----
MIIBajCCARCgAwIBAgIUHwOd2JFLTCBePSGfOYdPvomygdEwCgYIKoZIzj0EAwIw
EzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNMTkwODI0MTIwNzAwWhcNMzkwODE5MTIw
NzAwWjATMREwDwYDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH
A0IABDQ1v1QxJoRfkoo6hWcKkYD6ixGtd/YCnTVuqOcpyh97dQ3qVPUIEJoafORt
5yQCu8mLOCH1mWrXjA2yVo/Z6DqjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB
Af8EBTADAQH/MB0GA1UdDgQWBBT3zbMseoYHkZ60+VhVDGn1qdv4njAKBggqhkjO
PQQDAgNIADBFAiA/nXEN/f6wpUtOWwUBDNAXlKmhp7j+MjfD84+ksu+JEgIhAL6O
ZYp25KHMOGQaVWDPJZIzObWofJvxFwE4hHRkbCaH
-----END CERTIFICATE----- Issuer Subject: MBMxETAPBgNVBAMTCHN3YXJtLWNh
Issuer Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAENDW/VDEmhF+SijqFZwqRgPqLEa139gKdNW6o5ynKH3t1DepU9QgQmhp85G3nJAK7yYs4IfWZateMDbJWj9noOg==
当节点重新active的时候,在以下情况下它会重新接受任务:
- 当一个服务缩容扩容时
- 在滚动更新的时候
- 当另一个节点Drain下线的时候
当一个任务在另一个active节点上运行失败的时候
九、使用swarm模式的路由网络
- docker的swarm模式使服务暴露给外部端口更加方便。所有的节点都在一个路由网络里。这个路由网络使得集群内的所有节点都能在开放的端口上接受请求。即使节点上没有任务运行,这个服务的端口也暴露的。路由网络路由所有的请求到暴露端口的节点上。
- 前提是需要暴露以下端口来使节点间能通信
- Port 7946 TCP/UDP for container network discovery.用于容器间网络发现
- Port 4789 UDP for the container ingress network.用于容器进入网络
- 你也必须开放节点之间的公开端口,和任何外部资源端口,例如一个外部的负载均衡。
你也可以使特定服务绕过路由网络
为一个服务暴露端口
使用--publish来在创建一个服务的时候暴露端口。target指明容器内暴露的端口。published指明绑定到路由网络上的端口。如果不写published,就会为每个服务绑定一个随机的高数字端口。你需要检查任务才能确定端口
先删除etcd,再重新部署etcd,指定映射端口,查看进程
root@manager1:~# docker service rm etcd
etcd
root@manager1:~# docker service create --name etcd --publish published=2379,target=2379 --replicas 1 elcolio/etcd:2.0.10
0xej3ym93411svulph7f5l0m0
overall progress: out of tasks
/: running
verify: Service converged
root@manager1:~# docker service ps etcd
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
tqmgklo7fbmb etcd. elcolio/etcd:2.0. manager1 Running Running seconds ago
- 注意旧版的语法是冒号分开的published:target,例如 -p 8080:80。新语法更易读且灵活。
- 当你在任何节点访问8080端口时,路由网络将把请求分发到一个active的容器中。在各个节点,8080端口可能并没有绑定,但是路由网络知道如何路由流量,并防止任何端口冲突。
- 路由网络监听各个节点的IP上的 published port 。从外面看,这些端口是各个节点暴露的。对于别的IP地址,只在该主机内可以访问。
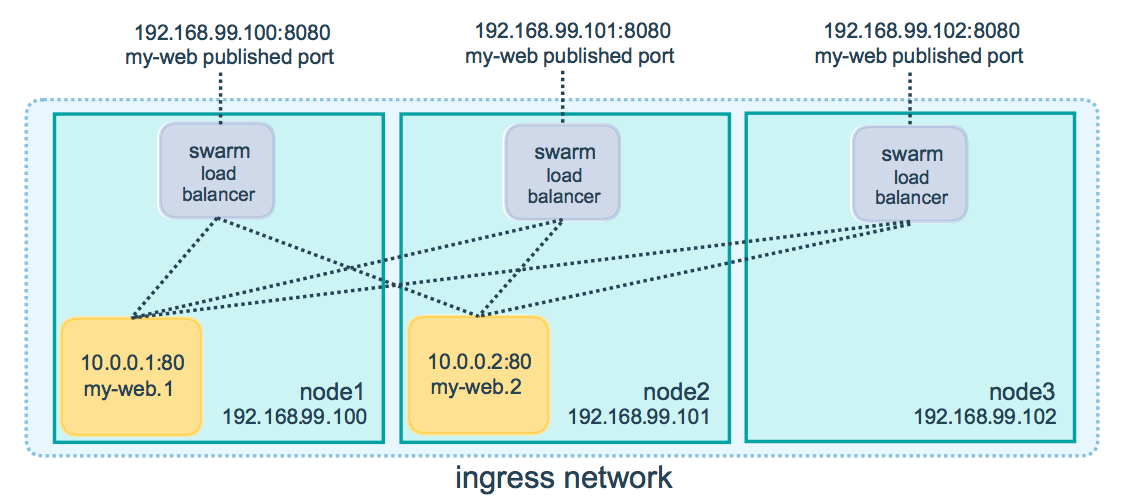
https://docs.docker.com/engine/swarm/images/ingress-routing-mesh.png
你可以用以下命令给一个已经存在的服务暴露端口
root@manager1:~# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
0xej3ym93411 etcd replicated / elcolio/etcd:2.0. *:->/tcp
root@manager1:~#
root@manager1:~# docker service update --publish-add published=20379,target=2379 etcd
etcd
overall progress: out of tasks
/: running
verify: Service converged
你可以使用docker service inspect来查看服务暴露的端口:
root@manager1:~# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" etcd
[{"Protocol":"tcp","TargetPort":,"PublishedPort":,"PublishMode":"ingress"},{"Protocol":"tcp","TargetPort":,"PublishedPort":,"PublishMode":"ingress"}]
- The output shows the (labeled TargetPort) from the containers and the (labeled PublishedPort) where nodes listen for requests for the service.
访问etcd api,查看版本
使用命令:docker service ps etcd 得知etcd运行在manager1,因此访问地址为:
root@manager1:~# curl http://192.168.10.104:20379/version
etcd 2.0.
仅暴露一个TCP或UDP端口
注意:这部分内容出现的命令,不需要执行
默认你暴露的端口都是TCP的。如果你使用长语法(Docker 1.13 and higher),设置protocol为tcp或udp即可暴露相应端口
仅TCP
长语法
$ docker service create --name dns-cache \
--publish published=,target= \
dns-cache
短语法
$ docker service create --name dns-cache \
-p : \
dns-cache
TCP和UDP
长语法
$ docker service create --name dns-cache \
--publish published=,target= \
--publish published=,target=,protocol=udp \
dns-cache
短语法
$ docker service create --name dns-cache \
-p : \
-p :/udp \
dns-cache
只暴露UDP
长语法
$ docker service create --name dns-cache \
--publish published=,target=,protocol=udp \
dns-cache
短语法
$ docker service create --name dns-cache \
-p :/udp \
dns-cache
绕过路由网络
- 你可以绕过路由网络,直接和一个节点上的端口通信,来访问服务。这叫做Host模式:
- 如果该节点上没有服务运行,服务也没有监听端口,则可能无法通信。
- 你不能在一个节点上运行多个服务实例他们绑定同一个静态target端口。或者你让docker分配随机高数字端口(通过空配置target),或者确保该节点上只运行一个服务实例(通过配置全局服务global service 而不是副本服务,或者使用配置限制)。
- 为了绕过路由网络,必须使用长格式--publish,设置模式mode为host模式。如果你忽略了mode设置或者设置为内网ingress,则路由网络将启动。下面的命令创建了全局应用使用host模式绕过路由网络:
$ docker service create --name dns-cache \
--publish published=,target=,protocol=udp,mode=host \
--mode global \
dns-cache
十、配置外部的负载均衡
你可以为swarm集群配置外部的负载均衡,或者结合路由网络使用或者完全不使用:
使用路由网络
- 你可以使用一个外部的HAProxy来负载均衡,服务是8080端口上的nginx服务:

- 在这个例子中负载均衡器和集群节点之间的8080端口必须是开放的。swarm集群节点在一个外部不可访问的内网中,节点可以与HAProxy通信。
你可以配置负载均衡器分流请求到不同的集群节点,即使节点上没有服务运行。例如你可以如下配置HAProxy:/etc/haproxy/haproxy.cfg:
安装haproxy
由于机器资源不够,这里在manager1节点,安装haproxy
apt-get install -y haproxy
配置haproxy
vim /etc/haproxy/haproxy.cfg
最后一行添加
# Configure HAProxy to listen on port
frontend http_front
bind *:
stats uri /haproxy?stats
default_backend http_back # Configure HAProxy to route requests to swarm nodes on port
backend http_back
balance roundrobin
server node1 192.168.10.104:2379 check
server node2 192.168.10.108:2379 check
server node3 192.168.10.110:2379 check
- 当你请求HAProxy的80端口的时候,它会转发请求到后端节点。swarm的路由网络会路由到相应的服务节点。这样无论任何原因swarm的调度器调度服务到不同节点,都不需要重新配置负载均衡。
你可以配置任何类型的负载均衡来分流请求。关于HAProxy参考 HAProxy documentation
不使用路由网络
如果不使用路由网络,配置--endpoint-mode的值为dnsrr,而不是vip。在本例子中没有一个固定的虚拟IP。Docker为服务做了DNS注册,这样一个服务的DNS查询会返回一系列IP地址。客户端就可以直接连接其中一个节点。你负责提供这一系列的IP地址,开放端口给你的负载均衡器。参考Configure service discovery.
重新加载配置
service haproxy reload
访问haproxy
http://192.168.10.104/haproxy?stats
效果如下:
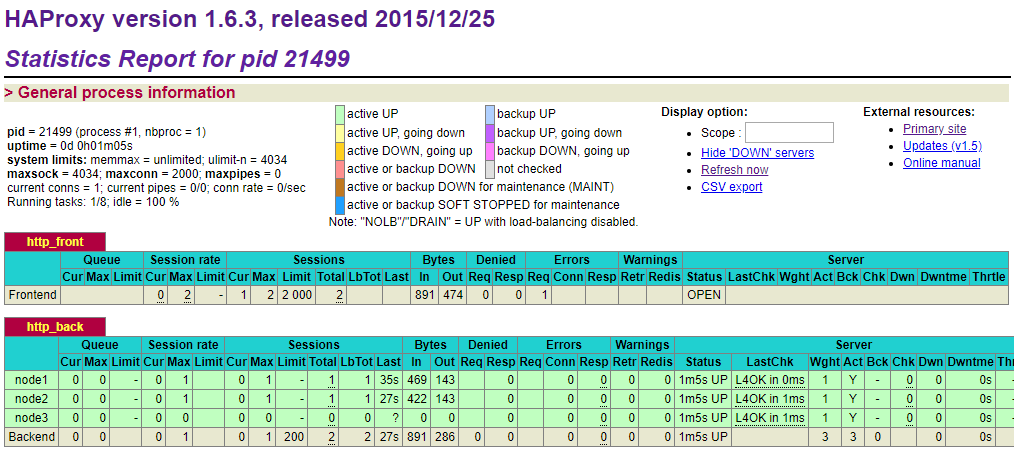
可以发现3台node的Act状态为Y,表示活跃。
访问etcd api的版本
http://192.168.10.104/version
效果如下:

本文参考链接:
https://www.cnblogs.com/drawnkid/p/8487337.html
Docker Swarm部署集群的更多相关文章
- 从零开始,使用Docker Swarm部署集群教程
本文首先从Dockerfile创建了一个简单web镜像 然后将web镜像推送到了远程仓库,以备后面集群中不同机器自动下载 之后使用docker-compose.yml配置了一个应用 而后新建了2台虚拟 ...
- Docker Swarm redis 集群搭建
Docker Swarm redis 集群搭建 环境1: 系统:Linux Centos 7.4 x64 内核:Linux docker 3.10.0-693.2.2.el7.x86_64 Docke ...
- docker Swarm mode集群
基本概念 Swarm 是使用 SwarmKit 构建的 Docker 引擎内置(原生)的集群管理和编排工具. 使用 Swarm 集群之前需要了解以下几个概念. 节点 运行 Docker 的主机可以主动 ...
- Swarm部署集群
swarm-manager 是 manager node,swarm-worker是 worker node.所有节点的 Docker 版本均不低于 v1.12.在master上 docker swa ...
- Docker Swarm nginx 集群搭建
环境1: 系统:Linux Centos 7.4 x64 内核:Linux docker 3.10.0-693.2.2.el7.x86_64 Docker 版本:18.09.1 redis 版本:ng ...
- centos7 docker swarm加入集群失败
提示的错误为 [root@localhost downloads]# docker swarm join --token SWMTKN-1-2ezr0k5ybds1la4vgi2z7j8ykxkmm0 ...
- docker swarm部署spring cloud服务
一.准备docker swarm的集群环境 ip 是否主节点 192.168.91.13 是 192.168.91.43 否 二.准备微服务 ①eureka服务 application.y ...
- docker~swarm搭建docker高可用集群
回到目录 Swarm概念 Swarm是Docker公司推出的用来管理docker集群,它将一群Docker宿主机变成一个单一的,虚拟的主机.Swarm使用标准的Docker API接口作为其前端访问入 ...
- docker学习之使用 DockerFile 构建镜像并搭建 swarm+compose 集群
题目要求 (1)将springboot应用程序打成jar包:Hot.jar (2)利用dockerfile将Hot.jar构建成镜像 (3)构建 Swarm 集群 (4)在 Swarm 集群中使用 c ...
随机推荐
- 【luoguP1858】多人背包
链接 对于每个状态\(f[j]\)多记录一个维度,转移的时候利用类似于归并排序的方法合并,以保证时间复杂度可以承受 注意事项:前\(K\)大可以有重复的价值 #include<iostream& ...
- Internet地址结构
IP地址结构及分类寻址 IP地址 = <网络号> + <主机号> ------------IPv4(32bit)点分四组表示法: 192.168.31.1 ...
- 保存tensor至本地文件
path_temp = '../m39_data/temp3' #文件目录 file_name = os.path.join(path_temp, "setQ.txt") Q = ...
- 数位dp技巧
一个奇怪的东西 正反都能dp!: 正常我们数位dp都是从高到低,以这样的方式保证其小于给定数-> ll n; int num[N],l; ll dp[]; ll dfs(int p,int li ...
- 终于明白为什么要加 final 关键字了!
阅读本文大概需要 2.8 分钟. 来源: www.jianshu.com/p/acc8d9a67d0c 在开发过程中,由于习惯的原因,我们可能对某种编程语言的一些特性习以为常,特别是只用一种语言作为日 ...
- docker安装 与 基本配置
1.安装docker #yum remove docker \ docker-common \ container-selinux \ docker-selinux \ docker-engine \ ...
- [Gamma阶段]第九次Scrum Meeting
Scrum Meeting博客目录 [Gamma阶段]第九次Scrum Meeting 基本信息 名称 时间 地点 时长 第九次Scrum Meeting 19/06/05 大运村寝室6楼 20min ...
- linux 线程查看 和 Jvm栈线程ID对应
一.proc查看进程和线程 该方法是个人最为推荐,也最喜欢的一种方法.进程文件下,有几种方式可以获取目前进程开启的进程数. 查看status文件: # cat /proc//status Name: ...
- mysql注入写文件
select * from admin where id =-1 union select 1,'<?php phpinfo();?>',3,4 into outfile 'c:\\1.p ...
- Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects 2019-10-04 14:4 ...