Storm-0.9.0.1安装部署 指导
可以带着下面问题来阅读本文章:
1.Storm只支持什么传输
2.通过什么配置,可以更改Zookeeper默认端口
3.Storm UI必须和Storm Nimbus部署在同一台机器上,UI无法正常工作为什么
2.Storm-0.9.0.1大概经过几个步骤
Twitter Storm更新0.9.0.1之后,安装部署变得容易得多了,比起Storm0.8.x的版本,Storm少了zeromq和jzmq的安装,也省去了很多编译这些插件时出现的bug。
1、Storm-0.9.0.1 版本的亮点:
1.1、Netty Transport
Storm 0.9.0.1版本的第一亮点是引入了netty
transport。Storm网络传输机制实现可插拔形式,当前包含两种方式:原来的0mq传输,以及新的netty实现;在早期版本中(0.9.x之
前的版本),Storm只支持0mq传输,由于0MQ是一个本地库(native
library),对平台的依赖性较高,要完全正确安装还是有一定挑战性。而且版本之间的差异也比较大;Netty
Transport提供了纯JAVA的替代方案,消除了Storm的本地库依赖,且比0MQ的网络传输性能快一倍以上;
补充:之前写这篇文档的时候忘记把配置Netty Transport的方式写进来,所以可能很多朋友配置了之后会发觉后台会报一个错误;这里还是用的原来的方式,所以下面补充下storm使用netty配置的方式;
要配置Storm使用Netty传输需要添加以下配置和调整值到你的storm.yaml文件上,响应的配置值可根据你的需求自行调整
- storm.messaging.transport: "backtype.storm.messaging.netty.Context" --指定传输协议
- storm.messaging.netty.server_worker_threads: 1 --指定netty服务器工作线程数量
- storm.messaging.netty.client_worker_threads: 1 --指定netty客户端工作线程数量
- storm.messaging.netty.buffer_size: 5242880 --指定netty缓存大小
- storm.messaging.netty.max_retries: 100 --指定最大重试次数
- storm.messaging.netty.max_wait_ms: 1000 --指定最大等待时间(毫秒)
- storm.messaging.netty.min_wait_ms: 100 --指定最小等待时间(毫秒)
复制代码
1.2、日志修改
Storm 0.9.0.1版本提供了有助于调试和检测拓扑结构的新特性:logviewer(守护进程名)
你现在可以在Storm UI通过点击相应的Woker来查看对应的工作日志。有点类似于hadoop的那种日志查看机制。
1.3、安全
安全性、认证以及授权已经并将继续成为将来的重要特点重点领域。Storm 0.9.0.1版本引入了一个可插拔的序列化元组API以及实现一个基于blowfish加密方法对敏感数据进行加密的用例。
主要的改进就是以上三点。其他的就不提了!
2、Storm-0.9.0.1 安装部署
这一章节将详细描述如何搭建一个Storm集群。下面是接下来需要依次完成的安装步骤
1. 搭建Zookeeper集群;
2. 依赖库安装
3. 下载并解压Storm发布版本;
4. 修改storm.yaml配置文件;
5. 启动Storm各个后台进程。
2.1 搭建Zookeeper集群
Storm使用Zookeeper协调集群,由于Zookeeper并不用于消息传递,所以Storm给Zookeeper带来的压力相当低。大多数情况
下,单个节点的Zookeeper集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模节点的Zookeeper集群(对
于Zookeeper集群的话,官方推荐的最小节点数为3个)。在Zookeeper集群的每台机器上完成以下安装部署步骤:
1. 下载安装Java JDK,官方下载链接为http://java.sun.com/javase/downloads/index.jsp,JDK版本为JDK 6或以上。
2. 根据Zookeeper集群的负载情况,合理设置Java堆大小,尽可能避免发生swap,导致Zookeeper性能下降。保守起见,4GB内存的机器可以为Zookeeper分配3GB最大堆空间。
3. 下载后解压安装Zookeeper包,官方下载链接为http://hadoop.apache.org/zookeeper/releases.html。
4. 根据Zookeeper集群节点情况,在conf目录下创建Zookeeper配置文件zoo.cfg:
- tickTime=2000
- dataDir=/var/zookeeper/
- clientPort=2181
- initLimit=5
- syncLimit=2
- server.1=zookeeper1:2888:3888
- server.2=zookeeper2:2888:3888
- server.3=zookeeper3:2888:3888
复制代码
5.
在dataDir目录下创建myid文件,文件中只包含一行,且内容为该节点对应的server.id中的id编号。其中,dataDir指定
Zookeeper的数据文件目录;其中server.id=host:port:port,id是为每个Zookeeper节点的编号,保存在
dataDir目录下的myid文件中,zookeeper1~zookeeper3表示各个Zookeeper节点的hostname,第一个port
是用于连接leader的端口,第二个port是用于leader选举的端口。
6. 启动Zookeeper服务:
- bin/zkServer.sh start
复制代码
7. 通过Zookeeper客户端测试服务是否可用:
- bin/zkCli.sh -server 127.0.0.1:2181
复制代码
2.2 依赖库安装
这里的Storm依赖库有python、以及JDK两个,这两个的安装相对比较简单, 所以在这里就不提了!
2.3 下载并解压Storm发布版本
Storm0.9.0.1版本提供了两种形式的压缩包:zip和tar.gz
我们下载tar.gz格式的,这样可以免去uzip的安装
下载路径:https://dl.dropboxusercontent.co ... torm-0.9.0.1.tar.gz
解压命令
- tar -zxvf storm-0.9.0.1.tar.gz
复制代码
2.4 下载并解压Storm发布版本
Storm发行版本解压目录下有一个conf/storm.yaml文件,用于配置Storm。默认配置在这里可以查看。conf/storm.yaml
中的配置选项将覆盖defaults.yaml中的默认配置。以下配置选项是必须在conf/storm.yaml中进行配置的:
1) storm.zookeeper.servers:Storm集群使用的Zookeeper集群地址,其格式如下:
- storm.zookeeper.servers:
- - “111.222.333.444″
- - “555.666.777.888″
复制代码
如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项。
2) storm.local.dir:Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置该目录,如:
- storm.local.dir: "/home/admin/storm/workdir"
复制代码
3) nimbus.host:Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件,如:
- 01.nimbus.host: "111.222.333.444"
复制代码
4)
supervisor.slots.ports:
对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即
用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口,如:
- supervisor.slots.ports:
- -6700
- -6701
- -6702
- -6703
复制代码
2.5 启动Storm各个后台进程
最后一步,启动Storm的所有后台进程。和Zookeeper一样,Storm也是快速失败(fail-fast)的系统,这样Storm才能在任意时
刻被停止,并且当进程重启后被正确地恢复执行。这也是为什么Storm不在进程内保存状态的原因,即使Nimbus或Supervisors被重启,运行
中的Topologies不会受到影响。
以下是启动Storm各个后台进程的方式:
Nimbus: 在Storm主控节点上运行”bin/storm nimbus >/dev/null 2>&1 &”启动Nimbus后台程序,并放到后台执行;
Supervisor: 在Storm各个工作节点上运行”bin/storm supervisor>/dev/null 2>&1 &”启动Supervisor后台程序,并放到后台执行;
UI: 在Storm主控节点上运行”bin/storm ui >/dev/null 2>&1
&”启动UI后台程序,并放到后台执行,启动后可以通过http://{nimbushost}:8080观察集群的worker资源使用情况、
Topologies的运行状态等信息。
logview:在Storm主节点上运行"bin/storm logviewer > /dev/null 2>&1"启动logviewer后台程序,并放到后台执行。
注意事项:
启动Storm后台进程时,需要对conf/storm.yaml配置文件中设置的storm.local.dir目录具有写权限。
Storm后台进程被启动后,将在Storm安装部署目录下的logs/子目录下生成各个进程的日志文件。
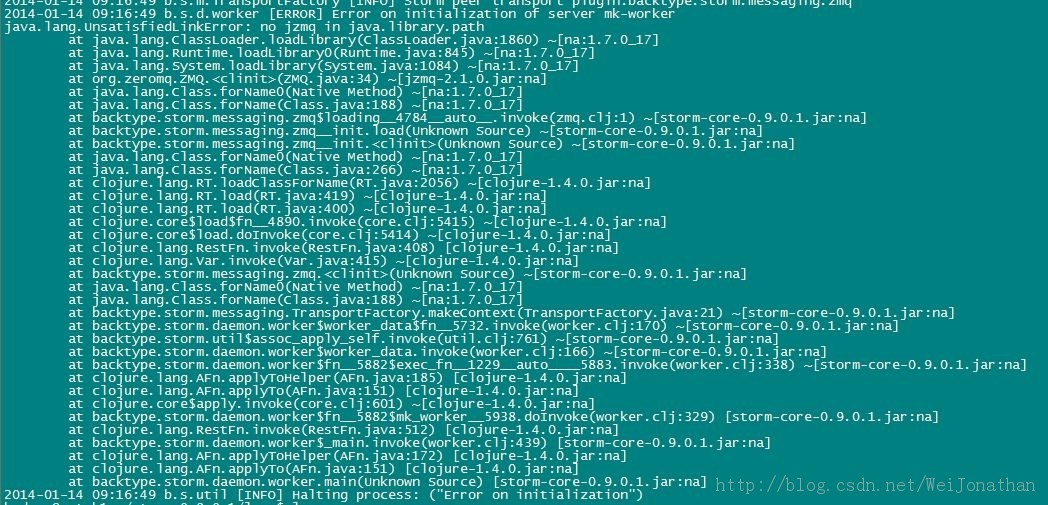
经测试,Storm UI必须和Storm Nimbus部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
为了方便使用,可以将bin/storm加入到系统环境变量中。
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。
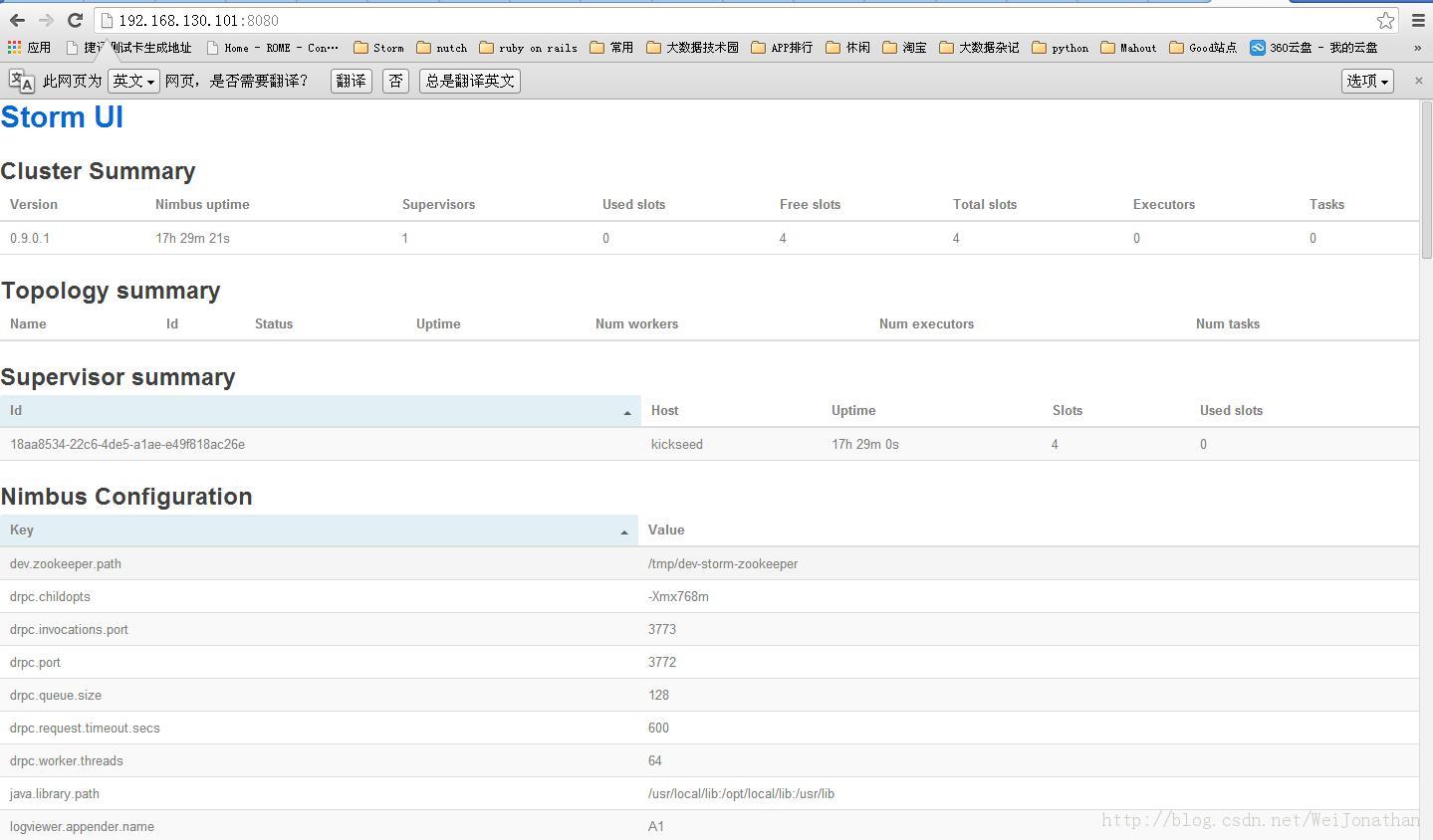
接下来我们检查下环境的运行情况:--使用jps检查守护进程运行状况
- zqgame@kickseed:/data/storm/zookeeper-3.4.5/bin$ jps
- 20420 nimbus
- 20623 logviewer
- 20486 supervisor
- 20319 core
- 21755 Jps
复制代码
查看运行页面如下
Storm-0.9.0.1安装部署 指导的更多相关文章
- Linux平台Oracle 12.1.0.2 单实例安装部署
主题:Linux平台Oracle 12.1.0.2 单实例安装部署 环境:RHEL 6.5 + Oracle 12.1.0.2 需求:安装部署OEM 13.2需要Oracle 12.1.0.2版本作为 ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- redis4.0.1集群安装部署
安装环境 序号 项目 值 1 OS版本 Red Hat Enterprise Linux Server release 7.1 (Maipo) 2 内核版本 3.10.0-229.el7.x86_64 ...
- 0、ubuntu16.04安装部署kvm
ubuntu16.04安装部署kvm1.查看CPU是否支持KVM egrep "(svm|vmx)" /proc/cpuinfo 2.安装相关kvm包 sudo apt-get i ...
- window10下的solr6.1.0入门笔记之---安装部署
1.安装部署java1.6+ ,确保jre安装[安装步骤略] 安装后的环境为jdk1.8+ jre1.8+ 2.安装ant 下载:官网=>http://ant.apache.org/=> ...
- centos7 ambari2.6.1.5+hdp2.6.4.0 大数据集群安装部署
前言 本文是讲如何在centos7(64位) 安装ambari+hdp,如果在装有原生hadoop等集群的机器上安装,需要先将集群服务停掉,然后将不需要的环境变量注释掉即可,如果不注释掉,后面虽然可以 ...
- OEMCC 13.2 安装部署
需求:安装部署OEM 13.2 环境:两台主机,系统RHEL 6.5,分别部署OMS和OMR: OMS,也就是OEMCC的服务端 IP:192.168.1.88 内存:12G+ 硬盘:100G+ OM ...
- Apache atlas liunx环境安装部署手册
一. 背景 本文使用一台ubuntu虚拟机安装Apache-atlas,使用集成包unzip apache-atlas-2.1.0.zip进行快速安装部署,该集成包高度集成了hadoop ...
- 手把手0基础Centos下安装与部署paddleOcr 教程
!!!以下内容为作者原创,首发于个人博客园&掘金平台.未经原作者同意与许可,任何人.任何组织不得以任何形式转载.原创不易,如果对您的问题提供了些许帮助,希望得到您的点赞支持. 0.paddle ...
随机推荐
- bzoj1588: [HNOI2002]营业额统计 splay瞎写
最近各种瞎写数论题,感觉需要回顾一下数据结构 写一发splay冷静一下(手速过慢,以后要多练练) 用splay是最直接的方法,但我感觉离散一波应该可以做出来(没仔细想过) 现在没有很追求代码优美,感觉 ...
- Linux环境快速部署Zookeeper集群
一.部署前准备: 1.下载ZooKeeper的安装包: http://zookeeper.apache.org/releases.html 我下载的版本是zookeeper-3.4.9. 2.将下载的 ...
- js getByClass函数封装
function getByClass(oParent, sClass) { var aEle=oParent.getElementsByTagName('*'); var aResult=[]; v ...
- Android学习笔记(二)Git和Github
一.添加SSH Key ssh-keygen -t rsa -C "email@example.com" 遇到提示只需要一直确认.用户目录(如/root)下会生成一个.ssh文件夹 ...
- jquery通过attr取html里自定义属性原来这么方便啊
<script type="text/javascript"> function fangGouWuChe(obj) { //放入购物车 var sMat = $(o ...
- YARN的capacity调度器主要配置分析
yarn中一个基本的调度单元是队列. yarn的内置调度器: 1.FIFO先进先出,一个的简单调度器,适合低负载集群.2.Capacity调度器,给不同队列(即用户或用户组)分配一个预期最小容量,在每 ...
- eclipse中svn提交过滤不需要的文件
eclipse>Preference>Team>Ignored Resource 添加 .settings .classpath .project
- shell 文件中列的整合成一个文件
原文件 第一种方法 [root@wxb- jt]# paste -d "," b c d ,q, , ,e, ,r, ,t, [root@wxb- jt]# paste b c d ...
- HDU 1728 逃离迷宫(DFS||BFS)
逃离迷宫 Problem Description 给定一个m × n (m行, n列)的迷宫,迷宫中有两个位置,gloria想从迷宫的一个位置走到另外一个位置,当然迷宫中有些地方是空地,gloria可 ...
- C# 语言规范_版本5.0 (第20章 附录B_语法)
A. 语法 此附录是主文档中描述的词法和语法以及不安全代码的语法扩展的摘要.这里,各语法产生式是按它们在主文档中出现的顺序列出的. A.1 词法文法 input: input-sectionopt i ...