dplyr 数据操作 统计描述(summarise)
在R中,summary()是一个基础包中的重要统计描述函数,同样的在dplyr中summarise()函数也可以对数据进行统计描述。
不同的是summarise()更加的灵活多变,下面来看下summarise这个函数
summarise(.data, ...)
其灵活性和其他dplyr函数一样,主要在于条件的使用上
下面看些具体的例子
library(dplyr)
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x

summarise(x,sum(shuxue))

可以很好的配合聚合函数一起使用
summarise(group_by(x,name),sum(shuxue))

这里由于每个name对应的shuxue只有一个参数,所以sum的结果没变化。
summarise(group_by(x,name),sum(shuxue,yuwen))

可以看出shuxue和yuwen求和后的数据。
arrange(summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)),desc(qiuhe))

配合上前面的函数,就可以对求和后的数据进行排序,当然上面数据的可读性较低。
把他分为两个步骤,理解起来可能会相对比较容易。
y<-summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)) 求和过程
arrange(y,desc(qiuhe)) 排序过程
summarise(x,mean(shuxue),sd(shuxue))

求均值和方差
summarise(group_by(x,name),a=n(),b=a+2)

配合你n()可以对每个因子的出现次数进行统计。
summarise_all(group_by(x,name),mean)

对所有列按照name分组后求平均值
summarise_if(x,is.numeric,mean)

对所有是数值的列求平均值
summarise_at(x,c(3,4),mean)

对特定的列求平均值
类似结果的表达方式有:
summarise_at(x,vars(shuxue,yuwen),mean)
summarise_at(x,c("shuxue","yuwen"),mean)
summarise_all(select(x,c(1,3,4)),funs(min,max,mean,sum,sd))
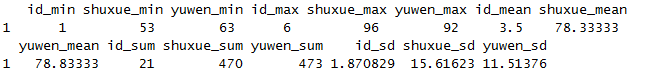
使用funs,对数据进行多重聚合统计。
summarise_each(x[c(1,3,4)],funs(mean,sum))
summarise_each也可以达到类似的效果。
dplyr 数据操作 统计描述(summarise)的更多相关文章
- SQL大数据操作统计
SQL大数据操作统计 1:select count(*) from table的区别SELECT object_name(id) as TableName,indid,rows,rowcnt FROM ...
- dplyr 数据操作 常用函数(5)
继续来了解dplyr中的其他有用函数 1.sample() 目的是可以从一个数据框中,随机抽取一些行,然后组成新的数据框. sample_n(tbl, size, replace = FALSE, w ...
- dplyr 数据操作 常用函数(3)
接下了我们继续了解dplyr中有用的函数 1.if_else() if_else主要用于在数据做判断用 x<-data.frame(id=1:6, name=c("wang" ...
- dplyr 数据操作 常用函数(1)
上面介绍完dplyr中,几个主要的操作函数后,我们再进一步了解dplyr中那些函数可能我们会经常要用到. 这里主要根据dplyr包作者的书籍目录来把它列出来. 1.add_rownames 添加行名称 ...
- dplyr 数据操作 列操作(select / mutate)
在R中,我们通常需要对数据列进行各种各样的操作,比如选取某一列.重命名某一列等. dplyr中的select函数子在数据列的操作上也同样表现了它的简洁性,而且各种操作眼花缭乱. select(.dat ...
- dplyr 数据操作 数据过滤 (filter)
在R的使用过程中我们几乎都绕不开Hadley Wickham 开发的几个包,前面说过的ggplot2.reshape2以及即将要讲的dplyr 因为这几个包可以非常轻易的使我们从复杂的数据操作中逃离, ...
- dplyr 数据操作 常用函数(4)
接下来我们继续了解一些dplyr中的常用函数. 1.ranking 以下各个函数可以实现对数据进行不同的排序 row_number(x) ntile(x, n) min_rank(x) dense_r ...
- dplyr 数据操作 常用函数(2)
继上一节常用函数,继续了解其他函数 1.desc() 这个函数和SQL中的排序用法是一样的,表示对数据进行倒序排序. 接下来我们看些例子. a=sample(20,50,rep=T)a desc(a) ...
- dplyr 数据操作 数据排序 (arrange)
在R中,我们在整理数据时,经常需要对数据排序,以便数据增强数据的可读性. 下面我们来看下dplyr中的,arrange函数 arrange(.data, ...) 跟filter()类似,arrang ...
随机推荐
- Tomcat启动时报错:java.net.UnknownHostException
异常信息如下: INFO: Failed to get local InetAddress for VMID. This is unlikely to matter. At all. We'll ad ...
- oracle_sequence用法
1. About Sequences(关于序列) 序列是数据库对象一种.多个用户可以通过序列生成连续的数字以此来实现主键字段的自动.唯一增长,并且一个序列可为多列.多表同时使用.序列消除了串行化 ...
- 职责链模式(Chain of Responsibility)(对象行为型)
1.概述 你去政府部门求人办事过吗?有时候你会遇到过官员踢球推责,你的问题在我这里能解决就解决,不能解决就推卸给另外个一个部门(对象).至于到底谁来解决这个问题呢?政府部门就是为了可以避免屁民的请求与 ...
- 持续集成Jenkins+sonarqube部署教程
1 引言 1.1 文档概要 本文主要介绍jenkins,sonar的安装与集成,基于ant,maven构建.用一个例子介绍jenkins的编译打包部署,代码检查.最后集成jenkins.(现阶段只是简 ...
- Junit4单元测试之高级用法
Junit单元测试框架是Java程序开发必备的测试利器,现在最常用的就是Junit4了,在Junit4中所有的测试用例都使用了注解的形式,这比Junit3更加灵活与方便.之前在公司的关于单元测试的培训 ...
- VS发布网站步骤(先在vs上发布网站到新的文件夹,然后挂到iis上面)
VS发布网站步骤(先在vs上发布网站到新的文件夹,然后挂到iis上面) 首先用vs2010打开一个Asp.Net项目, 也可以通过vs菜单->生成->发布网站 选择发布网站的路径 ...
- HDU 5860 Death Sequence(递推)
HDU 5860 Death Sequence(递推) 题目链接http://acm.split.hdu.edu.cn/showproblem.php?pid=5860 Description You ...
- Arpa's weak amphitheater and Mehrdad's valuable Hoses
Arpa's weak amphitheater and Mehrdad's valuable Hoses time limit per test 1 second memory limit per ...
- setAction方法 Snackbar 右侧按钮可以被点击并处理一些事件
从数据库同一记录取得的字段所组装成的对象应该是同一个对象,然后由不同的Session从数据库同一条记录上分别取得对象,它们的内存地址是不一样的. 一般来说,常见的数字加密方式都可以分为两类,即对称加密 ...
- libimobiledevice命令
Mac 安装 1. 安装HomeBrew ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/m ...