【翻译】Jay Kreps - 为何流处理中局部状态是必要的
译者注:
原文作者是 Jay Kreps,也是那篇著名的《The Log: What every software engineer should know about real-time data's unifying abstraction》的作者。
本文是意译为主,非逐字翻译,因此同原文的差异略大。欢迎原著爱好者们阅读原文。此文后面有一些对 Samza 的软广告,此处就忽略了。
大多数开发者已经习惯了无状态服务的理念,倾向于将所有数据存放在远端数据库中,难以理解流式计算中为何需要「局部状态」的存在。此文将阐述流计算中「局部状态」的含义、动机、适用场景和优劣势。
什么是状态?
想象你在使用 SQL 执行一些操作。
如果所有请求都只需要操作单行数据(如使用主键ID执行基本的 select 检索操作),那么此服务对数据的依赖可以称之为是「无状态」的。
然而现实场景中往往存在各类聚合(aggregation)、联合(join)操作。
- 聚合操作如:在某段时间窗口内,对若干页面的广告点击率(CTR,click-through rate)进行统计。
- 流连接(streaming join)操作如:广告展示(ad impression)数据流同广告点击率数据流两者存在时间先后顺序,但又是强关联的,需进行流连接操作。
- 字段填充(enrichment)操作如:给仅包含用户ID的广告点击率数据流,补充更详细的用户属性值,以便下游分析系统处理。
远程状态
一种常见的处理模式是,从输入流中依次获取记录,对每条记录执行若干次针对远程分布式数据库的请求。

如上图可见,数据流被分派至多个机器上的多个处理单元(processor)上进行处理,每个处理单元都会发起对远端的分布式数据库的请求;由于分布式数据库的特性,这些请求最终落在位于不同机器的各个数据库分区(database partition)上。另一种可能的做法是,将处理单元和数据库分区「绑起来」(co-located),让请求不用兜一个大圈子、而是直接在本机上进行处理,以提速数据流的处理。这种做法中,同处理单元绑定的数据存储分区,我们称之为「局部状态」(local state)。
局部状态
满足如下条件的,都可以称之为局部状态。
- 同处理单元位于同一台机器上。
- 处理单元可根据输入数据流,查询/修改其中的状态数据。
- 存储于内存或者磁盘中。
在阐述局部状态的好处前,我们先尝试回答一个显而易见的问题:局部状态如何做到高可用,如果机器挂了怎么办?
容错机制
Samza 对于局部状态提供的容错机制是,将局部状态的变更(local state changes)建模成一种提交日志/变更日志(commit/change log),从而利用提交日志的可重放(replay)特性来保障容错。
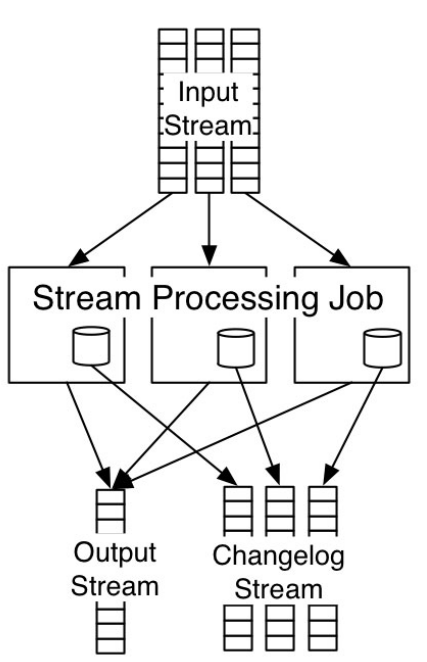
处理单元执行变更状态时,将变更日志写入 Kafka topic 中。如果机器挂掉,那么新启动的处理单元从上述 Kafka topic 中回放变更日志,从而重建机器挂掉前的局部状态。利用 Kafka 周期性的日志压缩(log compaction)操作,能够将日志量控制在合理的大小、而不会随着时间日益膨胀。
数据库也可以认为是日志数据流
从数据流的视角来看,数据库本身就是持久化的数据流,即行变更的流(the stream of row updates)。
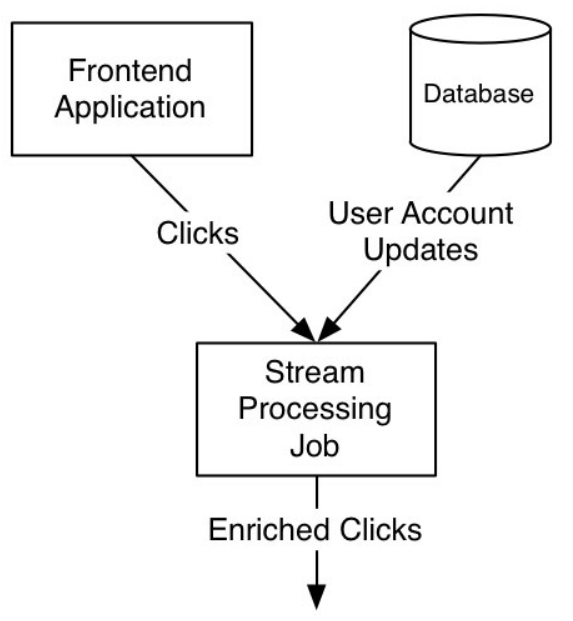
如下图所示,流处理单元同时订阅前端应用的点击率数据流(click-through rate stream)和来自数据库行变更数据流的用户属性变更流(user account change stream),对于后者(用户属性变更流),流处理单元根据用户属性的变更记录更新本地存储的局部状态,当前者(点击率数据流)到达时,流处理单元根据点击率数据中的用户ID,从本机存储的局部状态中获取最新的用户属性,对前者的流数据进行增强以供下游服务使用。
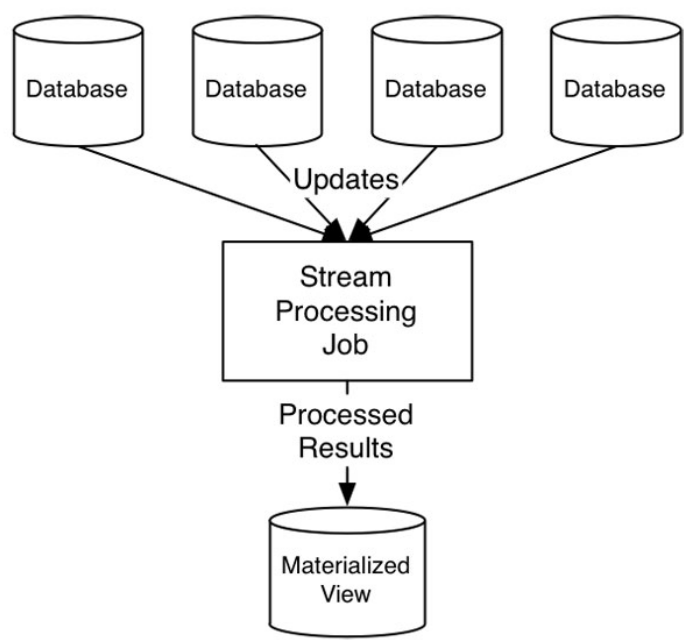
实际上,很多时候流处理单元的工作,就是从多个数据库中订阅行变更记录,并将其聚合起来以创建物化视图(做为局部状态进行存储)以供外部查询请求。
局部状态的好处是什么?
介绍了如何根据提交日志来保障局部状态的容错性之后,我们来谈一谈局部状态的好处。
相比较于传统的远端数据库访问方式而言,其好处有三:
- 局部状态可以按需索引,以满足各类业务场景需求。
- 读写速度更快。
- 更高的隔离度,异常场景下对线上业务影响小。
下面我们依次来说明。
按需索引
局部状态可以支持各种丰富的索引存取方式,倒排索引、压缩位图索引、键值存取、全表扫、复杂的聚合操作,等等。尽管集中式的关系数据库也能做到这一点,但现如今的业务对水平扩展要求越来越高,大多数使用关系数据库的公司都使用了按数据分区的水平扩展方案,这让按需索引变得更难。(译者注:推荐阅读 Pinterest 的数据分区方案。)
「按需索引」优势背后的理论基础是:几乎所有的数据结构都可以使用提交日志数据流来支撑,即,提交日志流最终不仅能重建几乎任意的数据结构、还能提供容错性保障。这意味着,在底层提交日志的基础上,你可以使用任意的嵌入式数据结构存储模块来存储局部状态。
此架构的额外好处在于,局部状态只会被本机的处理单元操作,这样,多进程共同访问集中式存储的竞争操作局面将不复存在。
读写速度更快
随机存取在实际场景中几乎是不可或缺的,很少有场景能完全避免 aggregation/join 这类需要大量随机存取的操作。
在各类存储介质上(尤其是机械磁盘上),随机存取的速度都是远小于顺序存取的。因此,要提升流处理的性能,我们应尽可能的让流处理的关键路径上不存在慢介质的随机存取操作,否则,整体的处理速度就会大打折扣(想想水桶效应里那根最短的木板)。
如何提速?考虑一下 RocksDB 这种非常适合在 SSD 上使用的嵌入式数据库的做法:通过将大部分数据放在内存态而将其他的放在 SSD 上,单线程随机读的性能可以得到大幅提升(提升幅度取决于读操作的缓存命中率)。
在 Dhruba Borthakur 的一次演讲中,也特地提到了 Facebook 在嵌入式键值存储 RocksDB 上投入的出发点,就是传统磁盘、网络操作、SSD 之间的性能差异,让性能敏感的数据架构更倾向于将「数据」同「处理单元」绑定在一起(co-located)。
隔离性更好
我们不妨考虑一个场景:流处理单元同线上服务都共用一个远端的分布式数据库;流处理单元某天因机器故障/程序错误等原因,挂掉了半小时;等流处理单元恢复后,它不予限速的处理半小时内堆积的流事件、并不断从远端数据库存取数据;这样的峰值操作很可能导致线上用户的请求延时提高。
如果上述场景能尽可能的使用隔离性更好的局部状态,那么整体的影响将小得多:无非就是本机 SSD 的存取压力提升、而不会影响线上服务。
硬币的另一面
凡事有好有坏。上述架构的一些缺点是:
- 数据冗余性。局部状态里的数据,可认为是远端数据的一份非全量的本地拷贝,这会提升一些数据冗余性。但考虑到存储介质的价格越来越低廉、许多业务场景对隔离性要求越来越高,牺牲一些冗余性所带来的好处可能更多。
- 如果局部状态过于庞大,那么 failover 可能会耗时过长。对于局部状态过大的数据集合,如果对 failover 耗时的要求比较苛刻,这种架构可能不太合适。
- 如果某个远端数据库的上层读取服务层,会在数据读取操作时执行大量的业务逻辑,那么局部状态架构中对数据的简单复制可能就无法满足业务需求。其解决办法是,流处理单元对订阅数据也执行相同的业务逻辑操作;具体办法就依场景而定了。
【翻译】Jay Kreps - 为何流处理中局部状态是必要的的更多相关文章
- OTL翻译(10) -- OTL的流缓冲池
OTL的流缓冲池 一般来讲,流一般作为一个局部的变量被使用,当使用完毕后就立刻关闭,如果需要再次使用就需要再次的声明变量,如此循环.OTL流的缓冲池(内存池)是一个解决以往的流性能低下的一个机制.当流 ...
- [翻译] 如何在 ASP.Net Core 中使用 Consul 来存储配置
[翻译] 如何在 ASP.Net Core 中使用 Consul 来存储配置 原文: USING CONSUL FOR STORING THE CONFIGURATION IN ASP.NET COR ...
- 18.翻译系列:EF 6 Code-First 中的Seed Data(种子数据或原始测试数据)【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/seed-database-in-code-first.aspx EF 6 Code-F ...
- 11.翻译系列:在EF 6中配置一对零或者一对一的关系【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/configure-one-to-one-relationship-in-code-fi ...
- 6.翻译系列:EF 6 Code-First中数据库初始化策略(EF 6 Code-First系列)
原文链接:http://www.entityframeworktutorial.net/code-first/database-initialization-strategy-in-code-firs ...
- CAD从二制流数据中加载图形(com接口Delphi语言)
主要用到函数说明: _DMxDrawX::ReadBinStream 从二制流数据中加载图形,详细说明如下: 参数 说明 VARIANT varBinArray 二制流数据,是个byte数组 BSTR ...
- CAD从二制流数据中加载图形(com接口VB语言)
主要用到函数说明: _DMxDrawX::ReadBinStream 从二制流数据中加载图形,详细说明如下: 参数 说明 VARIANT varBinArray 二制流数据,是个byte数组 BSTR ...
- CAD从二制流数据中加载图形(com接口)
主要用到函数说明: _DMxDrawX::ReadBinStream 从二制流数据中加载图形,详细说明如下: 参数 说明 VARIANT varBinArray 二制流数据,是个byte数组 BSTR ...
- vue中局部封装axios
Vue中局部配置axios 'use strict' import axios from 'axios'; import { Loading } from 'element-ui'; export c ...
随机推荐
- 友坚恒天.开发板(Cotex-A9 Exynos4412 开发板)
友坚恒天.开发板 Cotex-A9 Exynos4412 开发板
- java实现——030最小的k个数
1.O(nlogk)海量数据 import java.util.TreeSet; public class T030 { public static void main(String[] args){ ...
- 测试MarsEdit
测试MarsEdit 今天在MAC上使用MarsEdit编写第一篇博客,测试使用. 今天在MAC上使用MarsEdit编写第一篇博客,测试使用. -(void)myBtnAction:(UIButto ...
- [Angular Tutorial] 9 -Routing & Multiple Views
在这一步中,您将学到如何创建一个布局模板,并且学习怎样使用一个叫做ngRoute的Angular模块来构建一个具有多重视图的应用. ·当您现在访问/index.html,您将被重定向到/index.h ...
- maven 第一次运行报错
在大中国的网络环境下,使用一些国外的资源,是一件很痛苦的事情... 大概在好几个月以前,一个同事跟我说,没事的时候学习maven,现在公司项目都用这个做管理 还给了我电子书<Maven实战> ...
- Mybatis学习(8)逆向工程
什么是逆向工程: mybaits需要程序员自己编写sql语句,mybatis官方提供逆向工程 可以针对单表自动生成mybatis执行所需要的代码(mapper.java,mapper.xml.po.. ...
- swift 定位 根据定位到的经纬度转换城市名
好久没写随笔了 最近这段时间项目有点紧 天天在加班 国庆 一天假都没放 我滴娃娃 好啦 牢骚就不发了 毕竟没有什么毛用 待我那天闲了专门写一篇吐槽的随笔
- Failed to register Grid Infrastructure type ora.mdns.type
安装11g的集群软件的时候,在最后运行root.sh脚本时候,没有执行成功,最后提示如下错误: [root@r2 ~]# /u01/app/11.2.0/grid_1/root.sh Performi ...
- IIS 挂载android的apk文件进行下载
需要进行MIME的映射处理: 添加MIME映射:文件扩展名:.apk,MIME文件类型:application/vnd.android
- 配置FMS发布/HDS/HLS流
一.前言 安装完FMS4.5以后就有了apache2.2,由于在FMS安装目录里面,他是对外面已经安装的是没有影响的,默认情况向, FMS监听80端口接收traffic然后传递给Apache的8134 ...