Bulk Insert Data
Bulk Insert Data
命名空间:Oracle.DataAccess.Client
组件:Oracle.DataAccess.dll(2.112.1.0)
ODP.NET 版本:ODP.NET for .NET Framework 2.0 或 ODP.NET for .NET Framework 4
工具:Microsoft Visual Studio Ultimate 2013 + Oracle SQL Developer 1.5.5 + Oracle Database 11g Enterprise Edition 11.2.0.1.0(32位) + TNS for 32-bit Windows 11.2.0.1.0
方式一:ArrayBind
当插入一条数据时,SQL语句如下:

- 1 public void InsertDataRow(Dictionary<string, object> dataRow)
- 2 {
- 3 StringBuilder sbCmdText = new StringBuilder();
- 4 sbCmdText.AppendFormat("INSERT INTO {0}(", m_TableName);
- 5 sbCmdText.Append(string.Join(",", dataRow.Keys.ToArray()));
- 6 sbCmdText.Append(") VALUES (");
- 7 sbCmdText.Append(":" + string.Join(",:", dataRow.Keys.ToArray()));
- 8 sbCmdText.Append(")");
- 9
- 10 using (OracleConnection conn = new OracleConnection())
- 11 {
- 12 using (OracleCommand cmd = conn.CreateCommand())
- 13 {
- 14 cmd.CommandType = CommandType.Text;
- 15 cmd.CommandText = sbCmdText.ToString();
- 16 OracleParameter parameter = null;
- 17 OracleDbType dbType = OracleDbType.Object;
- 18 foreach (string colName in dataRow.Keys)
- 19 {
- 20 dbType = GetOracleDbType(dataRow[colName]);
- 21 parameter = new OracleParameter(colName, dbType);
- 22 parameter.Direction = ParameterDirection.Input;
- 23 parameter.OracleDbTypeEx = dbType;
- 24 parameter.Value = dataRow[colName];
- 25 cmd.Parameters.Add(parameter);
- 26 }
- 27 conn.Open();
- 28 int result = cmd.ExecuteNonQuery();
- 29 }
- 30 }
- 31 }
此时,每一个 OracleParameter 的 Value 值都赋予单个字段的 一个具体值,这种也是最为传统的插入数据的方法。
Oracle V6 中 OCI 编程接口加入了数组接口特性。
当采用 ArrayBind 时,OraleParameter 的 Value 值则是赋予单个字段的 一个数组,即多条数据的该字段组合成的一个数组。此时 Oracle 仅需要执行一次 SQL 语句,即可在内存中批量解析并导入数据,减少程序与数据库之间来回的操作,其优点就是数据导入的总体时间明显减少,尤其是进程占用CPU的时间。
如果数据源是 DataTable 类型,首先把 DataTable 数据源,转换成 object[][] 类型,然后绑定 OracleParameter 的 Value 值为对应字段的一个 Object[] 数组即可;参考代码如下:
- 1 /// <summary>
- 2 /// 批量插入大数据量
- 3 /// </summary>
- 4 /// <param name="columnData">列名-列数据字典</param>
- 5 /// <param name="dataCount">数据量</param>
- 6 /// <returns>插入数据量</returns>
- 7 public int InsertBigData(Dictionary<string, object> columnData, int dataCount)
- 8 {
- 9 int result = 0;
- 10 if (columnData == null || columnData.Count < 1)
- 11 {
- 12 return result;
- 13 }
- 14 string[] colHeaders = columnData.Keys.ToArray();
- 15 StringBuilder sbCmdText = new StringBuilder();
- 16 if (columnData.Count > 0)
- 17 {
- 18 // 拼接INSERT的SQL语句
- 19 sbCmdText.AppendFormat("INSERT INTO {0}(", m_TableName);
- 20 sbCmdText.Append(string.Join(",", colHeaders));
- 21 sbCmdText.Append(") VALUES (");
- 22 sbCmdText.Append(m_ParameterPrefix + string.Join("," + m_ParameterPrefix, colHeaders));
- 23 sbCmdText.Append(")");
- 24 OracleConnection connection = null;
- 25 try
- 26 {
- 27 connection = new OracleConnection(GetConnectionString());
- 28 using (OracleCommand command = connection.CreateCommand())
- 29 {
- 30 command.ArrayBindCount = dataCount;
- 31 command.BindByName = true;
- 32 command.CommandType = CommandType.Text;
- 33 command.CommandText = sbCmdText.ToString();
- 34 command.CommandTimeout = 1800;
- 35 OracleParameter parameter;
- 36 OracleDbType dbType = OracleDbType.Object;
- 37 foreach (string colName in colHeaders)
- 38 {
- 39 dbType = GetOracleDbType(columnData[colName]);
- 40 parameter = new OracleParameter(colName, dbType);
- 41 parameter.Direction = ParameterDirection.Input;
- 42 parameter.OracleDbTypeEx = dbType;
- 43 parameter.Value = columnData[colName];
- 44 command.Parameters.Add(parameter);
- 45 }
- 46 connection.Open();
- 47 OracleTransaction trans = connection.BeginTransaction();
- 48 try
- 49 {
- 50 command.Transaction = trans;
- 51 result = command.ExecuteNonQuery();
- 52 trans.Commit();
- 53 }
- 54 catch (Exception ex)
- 55 {
- 56 trans.Rollback();
- 57 throw ex;
- 58 }
- 59 }
- 60 }
- 61 finally
- 62 {
- 63 if (connection != null)
- 64 {
- 65 connection.Close();
- 66 connection.Dispose();
- 67 }
- 68 GC.Collect();
- 69 GC.WaitForFullGCComplete();
- 70 }
- 71 }
- 72 return result;
- 73 }
说明:如果采用分次(每次1万数据)执行 InsertBigData 方法,速度反而比一次性执行 InsertBigData 方法慢,详见下面测试结果;
测试结果:
无索引,数据类型:4列NVARCHAR2,2列NUMBER
30+万(7.36M):一次性导入用时 15:623,每次10000导入用时
60+万(14.6M):一次性导入用时 28:207,每次10000导入用时 1:2:300
100+万(24.9M):一次性导入报如下异常
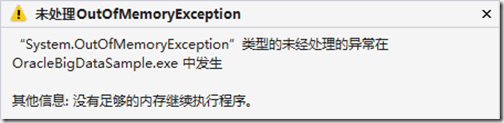
此时实际上从资源监视器上可以得知仍有可用内存,但是仍旧报 OutOfMemoryException,所以猜测应该是一个 bug;
如果每次10000导入用时 2:9:252
如果每次50000导入用时 58:101
附加 InsertBigData 方法使用示例:
方式二:OracleBulkCopy
说明:
1. OracleBulkCopy 采用 direct path 方式导入;
2. 不支持 transaction,无法 Rollback;
3. 如果该表存在触发器时,无法使用 OracleBulkCopy(报异常信息 Oracle Error: ORA-26086),除非先禁用该表的所有触发器;
4. 过程中会自动启用 NOT NULL、UNIQUE 和 PRIMARY KEY 三种约束,其中 NOT NULL 约束在列数组绑定时验证,任何违反 NOT NULL 约束条件的行数据都会舍弃;UNIQUE 约束是在导入完成后重建索引时验证,但是在 bulk copy 时,允许违反索引约束,并在完成后将索引设置成禁用(UNUSABLE)状态;而且,如果索引一开始状态就是禁用(UNUSABLE)状态时,OracleBulkCopy 是会报错的。
参考代码如下:
- 1 /// <summary>
- 2 /// 批量插入数据
- 3 /// 该方法需要禁用该表所有触发器,并且插入的数据如果为空,是不会采用默认值
- 4 /// </summary>
- 5 /// <param name="table">数据表</param>
- 6 /// <param name="targetTableName">数据库目标表名</param>
- 7 /// <returns></returns>
- 8 public bool InsertBulkData(DataTable table, string targetTableName)
- 9 {
- 10 bool result = false;
- 11 string connStr = GetConnectionString();
- 12 using (OracleConnection connection = new OracleConnection(connStr))
- 13 {
- 14 using (OracleBulkCopy bulkCopy = new OracleBulkCopy(connStr, OracleBulkCopyOptions.Default))
- 15 {
- 16 if (table != null && table.Rows.Count > 0)
- 17 {
- 18 bulkCopy.DestinationTableName = targetTableName;
- 19 for (int i = 0; i < table.Columns.Count; i++)
- 20 {
- 21 string col = table.Columns[i].ColumnName;
- 22 bulkCopy.ColumnMappings.Add(col, col);
- 23 }
- 24 connection.Open();
- 25 bulkCopy.WriteToServer(table);
- 26 result = true;
- 27 }
- 28 bulkCopy.Close();
- 29 bulkCopy.Dispose();
- 30 }
- 31 }
- 32
- 33 return result;
- 34 }
测试结果:
数据类型:4列NVARCHAR2,2列NUMBER
30+万(7.36M):用时 14:590
60+万(14.6M):用时 28:28
1048576(24.9M):用时 52:971
附加,禁用表的所有外键SQL:
总结
1、在30+万和60+万数据时,ArrayBind一次性导入和OracleBulkCopy时间相差不是很大,但是ArrayBind方式一般都需要转换数据形式,占用了一些时间,而 OracleBulkCopy 则只需要简单处理一下 DataTable 数据源即可导入;
2、当数据量达到100+万时,ArrayBind很容易出现内存不足异常,此时只能采用分批次执行导入,根据测试结果可知,次数越少,速度越快;而采用 OracleBulkCopy 方式则很少出现内存不足现象,由此可见 OracleBulkCopy 占用内存比 ArrayBind 方式少;
3、采用 OracleBulkCopy 导入时,先要禁用该表所有触发器,如果该表存在自增 ID 触发器,就比较麻烦了,得先禁用改变的自增 ID 的触发器,然后手动自增设置要导入的数据,最后才可以导入;同时,这种导入方式不可并发,一个时刻只能有一个用户在导入(因为自增ID交由程序处理),此时还需要锁表,防止其他人同时批量导入数据;
参考资料:
1、ArrayBind http://www.oracle.com/technetwork/issue-archive/2009/09-sep/o59odpnet-085168.html
2、ArrayBind http://www.soaspx.com/dotnet/csharp/csharp_20130911_10501.html
3、Oracle数据导入方法 http://dbanotes.net/Oracle/All_About_Oracle_Data_Loading.htm
4、介绍OracleBulkCopy类 https://docs.oracle.com/cd/E11882_01/win.112/e23174/OracleBulkCopyClass.htm#ODPNT7446
出处:http://www.cnblogs.com/Memento/
Bulk Insert Data的更多相关文章
- [Oracle] Bulk Insert Data
命名空间:Oracle.DataAccess.Client 组件:Oracle.DataAccess.dll(2.112.1.0) ODP.NET 版本:ODP.NET for .NET Framew ...
- bulk insert data into database with table type .net
1. Create Table type in Sqlserver2008. CREATE TYPE dbo.WordTable as table ( [WordText] [nchar]() NUL ...
- Bulk Insert:将文本数据(csv和txt)导入到数据库中
将文本数据导入到数据库中的方法有很多,将文本格式(csv和txt)导入到SQL Server中,bulk insert是最简单的实现方法 1,bulk insert命令,经过简化如下 BULK INS ...
- SQL Server Bulk Insert批量数据导入
SQL Server的Bulk Insert语句可以将本地或远程的数据文件批量导入到数据库中,速度非常的快.远程文件必须共享才行,文件路径须使用通用约定(UNC)名称,即"\\服务器名或IP ...
- Bulk Insert的用法 .
/******* 导出到excel */EXEC master..xp_cmdshell 'bcp SettleDB.dbo.shanghu out c:/temp1.xls -c -q -S&quo ...
- Bulk Insert & BCP执行效率对比
我们以BCP导出的CSV数据文件,分别使用Bulk insert与BCP导入数据库,对比两种方法执行效率 备注:导入目标表创建了分区聚集索引 1.BCP导出csv数据文件 数据量:15000000行, ...
- Bulk Insert命令具体
Bulk Insert命令具体 BULK INSERT以用户指定的格式复制一个数据文件至数据库表或视图中. 语法: BULK INSERT [ [ 'database_name'.][ 'owner' ...
- Bulk Insert 高效快速插入数据
BULK INSERT以用户指定的格式复制一个数据文件至数据库表或视图中. 语法: BULK INSERT [ [ 'database_name'.][ 'owner' ].]{ 'table_nam ...
- 从一个Bug说开去--解决问题的思路,Linked Server, Bulk Insert, DataTable 作为参数传递
声名— 部分内容为杜撰,如有雷同,不胜荣幸! 版权所有,如要引用,请标明出处! 如果打赏,请自便! 1 背景介绍 最近一周在忙一个SQL Server 的Bug,一个简单的Bug,更新两张 ...
随机推荐
- 获取信息的有关Windows API(最有意思是OpenProcess和GetProcessMemoryInfo)
1.窗口信息MS为我们提供了打开特定桌面和枚举桌面窗口的函数.hDesk = OpenDesktop(lpszDesktop, 0, FALSE, DESKTOP_ENUMERATE);// 打开我们 ...
- SDL Guide 中文译版
SDL即Simple DirectMedia Layer,类似DirectX,是完整的游戏.多媒体开发包,但不同的是它跨越几乎所有的平台,有各种语言的接口,多种语言的文档,而这一切都是广大志愿者完成的 ...
- Spring MVC 数据验证——validate注解方式
1.说明 学习注解方式之前,应该先学习一下编码方式的spring注入.这样便于理解验证框架的工作原理.在出错的时候,也能更好的解决这个问题.所以本次博客教程也是基于编码方式.仅仅是在原来的基础加上注解 ...
- FatMouse' Trade(杭电1009)
FatMouse' Trade Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Tot ...
- c#soap调用WebService
辅助类 /// <summary> /// 上传数据参数 /// </summary> public class UploadEventArgs : EventArgs { i ...
- WebSocket是一种协议
WebSocket,并非HTML 5独有,WebSocket是一种协议.只是在handshake的时候,发送的链接信息头和HTTP相似.HTML 5只是实现了WebSocket的客户端.其实,难点在于 ...
- vc笔记六
通知消息(Notification message)是指这样一种消息,一个窗口内的子控件发生了一些 事情,需要通 知父窗口.通知消息只适用于标准的窗口控件如按钮.列表框.组合框.编辑框,以及 Wind ...
- DOM4J解析XML文档
Tip:DOM4J解析XML文档 Dom4j是一个简单.灵活的开放源代码的库.Dom4j是由早期开发JDOM的人分离出来而后独立开发的.与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j ...
- 小议common lisp程序开发流程 - Ever 17 - 博客频道 - CSDN.NET
小议common lisp程序开发流程 - Ever 17 - 博客频道 - CSDN.NET 小议common lisp程序开发流程 分类: lisp 2011-04-17 20:59 1316人阅 ...
- oracle乱码问题
oracle乱码问题通常是因为oracle字符集设置和操作系统字符集设置不一致造成的,这里不得不提到两个操作系统环境变量,LANG和NLS_LANG LANG是针对Linux系统的语言.地区.字符集的 ...