spring容器启动的加载过程(三)
第十步:
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
/**
* Load bean definitions from the specified XML file.
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
//这里是调用的入口
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
//这里是载入XML形式的BeanDefinition的地方
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//这里得到XML文件,并得到IO的InputStream准备进行读取
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
...
}
第十一步:
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
//具体的读取过程。这是从特定的XML文件中实际载入的BeanDefinition的地方
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
int validationMode = getValidationModeForResource(resource);
//取得XML文件的Document对象,这个解析过程由DocumentLoader完成,这个DocumentLoader是DefaultDocumentLoader,在定义DocumentLoader的地方创建
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
//启动对BeanDefinition解析的详细过程,这个解析会使用到Spring的Bean配置规则。
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
第十二步:
public class XmlBeanDefinitionReader extends AbstractBeanDefinitionReader {
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//这里得到BeanDefinitionDocumentReader来对XML的BeanDefinition进行解析
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
//根据通用的XML进行解析,并没有根据Spring的Bean规则
int countBefore = getRegistry().getBeanDefinitionCount();
//具体的解析过程在这个registerBeanDefinitions中完成,这里是按照Spring的Bean规则进行解析
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//总的Bean减去通用的,剩下就是spring的bean规则的bean个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
/**
* Create the {@link BeanDefinitionDocumentReader} to use for actually
* reading bean definitions from an XML document.
* <p>The default implementation instantiates the specified "documentReaderClass".
* @see #setDocumentReaderClass
*/
//创建BeanDefinitionDocumentReader
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.instantiateClass(this.documentReaderClass));
}
}
第十三步:
public class DefaultBeanDefinitionDocumentReader implements BeanDefinitionDocumentReader {
/**
* {@inheritDoc}
* <p>This implementation parses bean definitions according to the "spring-beans" XSD
* (or DTD, historically).
* <p>Opens a DOM Document; then initializes the default settings
* specified at the {@code <beans/>} level; then parses the contained bean definitions.
*/
//根据spring的bean规则解析bean的定义
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
protected void doRegisterBeanDefinitions(Element root) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
Assert.state(this.environment != null, "environment property must not be null");
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!this.environment.acceptsProfiles(specifiedProfiles)) {
return;
}
}
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(readerContext, root, parent);
preProcessXml(root);
//委派给delegate解析
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
...
}
第十四步:
public class BeanDefinitionParserDelegate {
//在这里面定义了大量的bean的属性
public BeanDefinition parseCustomElement(Element ele) {
return parseCustomElement(ele, null);
}
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(ele);
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
...
}
第十五步:
public abstract class NamespaceHandlerSupport implements NamespaceHandler {
public BeanDefinition parse(Element element, ParserContext parserContext) {
//这里就是解析Bean得到BeanDefinition的地方了
return findParserForElement(element, parserContext).parse(element, parserContext);
}
/**
* Locates the {@link BeanDefinitionParser} from the register implementations using
* the local name of the supplied {@link Element}.
*/
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
String localName = parserContext.getDelegate().getLocalName(element);
BeanDefinitionParser parser = this.parsers.get(localName);
if (parser == null) {
parserContext.getReaderContext().fatal(
"Cannot locate BeanDefinitionParser for element [" + localName + "]", element);
}
return parser;
}
...
}
在上面的BeanDefinitionParser中的parse,有很多种BeanDefinitionParser对其进行解析,BeanDefinitionParser接口就定义了一个BeanDefinition parse(Element element, ParserContext parserContext);专业用来解析bean的,具体的实现交给他的具体。结构如下图:
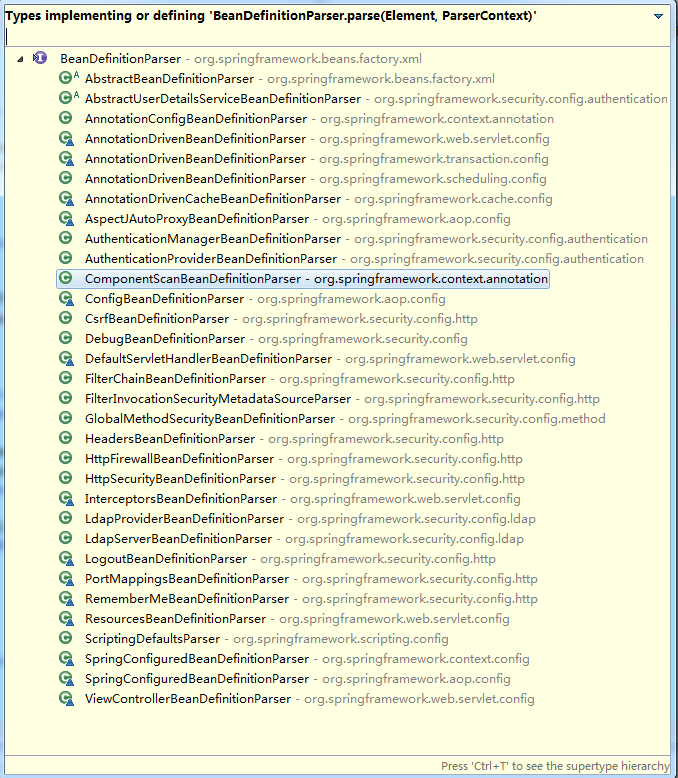
我们来看下这个ComponentScanBeanDefinitionParser
public class ComponentScanBeanDefinitionParser implements BeanDefinitionParser {
//这两个是我们常用的属性配置 当然还有别的
private static final String ANNOTATION_CONFIG_ATTRIBUTE = "annotation-config";
private static final String BASE_PACKAGE_ATTRIBUTE = "base-package";
...
//这里就是他解析的地方了
public BeanDefinition parse(Element element, ParserContext parserContext) {
String[] basePackages = StringUtils.tokenizeToStringArray(element.getAttribute(BASE_PACKAGE_ATTRIBUTE),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
//得到ClassPathBeanDefinitionScanner,通过它去扫描包中的类文件,注意:这里是类文件而不是类,因为现在这些类还没有被加载,只是ClassLoader能找到这些class的路径而已。
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
...
}
第十六步:再来看看ClassPathBeanDefinitionScanner的doScan方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
//用来保存BeanDefinitionHolder,即Bean的属性
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<BeanDefinitionHolder>();
for (String basePackage : basePackages) {
//得到扫描出来的类
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//得到扫描出来的类后,把他加进beanDefinitions中
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
第十七:ClassPathScanningCandidateComponentProvider的findCandidateComponents方法
public class ClassPathScanningCandidateComponentProvider implements EnvironmentCapable, ResourceLoaderAware {
static final String DEFAULT_RESOURCE_PATTERN = "**/*.class";
private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
//创建一个candidates,用来保存BeanDefinition
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + "/" + this.resourcePattern;
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
//封装一个ScannedGenericBeanDefinition,并设置属性,然后添加进candidates中。
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
}
来看这两句:
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + "/" + this.resourcePattern;
假设我们配置的需要扫描的包名为com.cengle.service,那么packageSearchPath的值就是classpath*:com.cengle.service/**/*.class,意思就是com.cengle.service包(包括子包)下所有class文件;如果配置的是*,那么packageSearchPath的值就是classpath*:*/**/*.class。这里的表达式是Spring自己定义的。Spring会根据这种表达式找出相关的class文件。
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
这些资源是怎么得到的。看下面:
public Resource[] getResources(String locationPattern) throws IOException {
Assert.notNull(locationPattern, "Location pattern must not be null");
//判断是否以classpath*:开头
if (locationPattern.startsWith(CLASSPATH_ALL_URL_PREFIX)) {
// a class path resource (multiple resources for same name possible)
//判断多个资源是否有相同的名称
if (getPathMatcher().isPattern(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()))) {
// a class path resource pattern
//得到类路径的资源模式
return findPathMatchingResources(locationPattern);
}
else {
// all class path resources with the given name
//得到所有的类路径资源名字
return findAllClassPathResources(locationPattern.substring(CLASSPATH_ALL_URL_PREFIX.length()));
}
}
else {
// Only look for a pattern after a prefix here
// (to not get fooled by a pattern symbol in a strange prefix).
int prefixEnd = locationPattern.indexOf(":") + 1;
if (getPathMatcher().isPattern(locationPattern.substring(prefixEnd))) {
// a file pattern
//得到文件模式
return findPathMatchingResources(locationPattern);
}
else {
// a single resource with the given name
//得到一个给定名称的资源
return new Resource[] {getResourceLoader().getResource(locationPattern)};
}
}
}
/**
* Find all class location resources with the given location via the ClassLoader.
* @param location the absolute path within the classpath
* @return the result as Resource array
* @throws IOException in case of I/O errors
* @see java.lang.ClassLoader#getResources
* @see #convertClassLoaderURL
*/
protected Resource[] findAllClassPathResources(String location) throws IOException {
String path = location;
if (path.startsWith("/")) {
path = path.substring(1);
}
//根据路径,将资源存进一个迭代器中
Enumeration<URL> resourceUrls = getClassLoader().getResources(path);
Set<Resource> result = new LinkedHashSet<Resource>(16);
while (resourceUrls.hasMoreElements()) {
URL url = resourceUrls.nextElement();
//将迭代器的元素存进set集合中
result.add(convertClassLoaderURL(url));
}
//将集合转化为数组
return result.toArray(new Resource[result.size()]);
}
protected Resource[] findPathMatchingResources(String locationPattern) throws IOException {
String rootDirPath = determineRootDir(locationPattern);
String subPattern = locationPattern.substring(rootDirPath.length());
//根据路径,得到一个资源数组
Resource[] rootDirResources = getResources(rootDirPath);
Set<Resource> result = new LinkedHashSet<Resource>(16);
//循环数组,将数组元素放进一个set集合中。
for (Resource rootDirResource : rootDirResources) {
rootDirResource = resolveRootDirResource(rootDirResource);
if (isJarResource(rootDirResource)) {
result.addAll(doFindPathMatchingJarResources(rootDirResource, subPattern));
}
else if (rootDirResource.getURL().getProtocol().startsWith(ResourceUtils.URL_PROTOCOL_VFS)) {
result.addAll(VfsResourceMatchingDelegate.findMatchingResources(rootDirResource, subPattern, getPathMatcher()));
}
else {
result.addAll(doFindPathMatchingFileResources(rootDirResource, subPattern));
}
}
if (logger.isDebugEnabled()) {
logger.debug("Resolved location pattern [" + locationPattern + "] to resources " + result);
}
//将集合转化为数组
return result.toArray(new Resource[result.size()]);
}
Spring也是用的ClassLoader加载的class文件。一路追踪,原始的ClassLoader是Thread.currentThread().getContextClassLoader();。到此为止,就拿到class文件了。
Spring会将class信息封装成BeanDefinition,然后再放进DefaultListableBeanFactory的beanDefinitionMap中。
spring容器启动的加载过程(三)的更多相关文章
- spring容器启动的加载过程(一)
使用spring,我们在web.xml都会配置ContextLoaderListener <listener> <listener-class> org.springframe ...
- spring容器启动的加载过程(二)
第六步: public abstract class AbstractApplicationContext extends DefaultResourceLoader implements Confi ...
- 微服务架构 | *2.3 Spring Cloud 启动及加载配置文件源码分析(以 Nacos 为例)
目录 前言 1. Spring Cloud 什么时候加载配置文件 2. 准备 Environment 配置环境 2.1 配置 Environment 环境 SpringApplication.prep ...
- 1. spring5源码 -- Spring整体脉络 IOC加载过程 Bean的生命周期
可以学习到什么? 0. spring整体脉络 1. 描述BeanFactory 2. BeanFactory和ApplicationContext的区别 3. 简述SpringIoC的加载过程 4. ...
- 启动就加载(三)initializingbean实现afterPropertiesSet方法
TransactionTemplate,就直接以TransactionTemplate为入口开始学习. TransactionTemplate的源码如下: public class Transacti ...
- Tomcat源码分析三:Tomcat启动加载过程(一)的源码解析
Tomcat启动加载过程(一)的源码解析 今天,我将分享用源码的方式讲解Tomcat启动的加载过程,关于Tomcat的架构请参阅<Tomcat源码分析二:先看看Tomcat的整体架构>一文 ...
- 深入理解 spring 容器,源码分析加载过程
Spring框架提供了构建Web应用程序的全功能MVC模块,叫Spring MVC,通过Spring Core+Spring MVC即可搭建一套稳定的Java Web项目.本文通过Spring MVC ...
- spring启动component-scan类扫描加载过程(转)
文章转自 http://www.it165.net/pro/html/201406/15205.html 有朋友最近问到了 spring 加载类的过程,尤其是基于 annotation 注解的加载过程 ...
- 【Spring源码分析系列】启动component-scan类扫描加载过程
原文地址:http://blog.csdn.net/xieyuooo/article/details/9089441/ 在spring 3.0以上大家都一般会配置一个Servelet,如下所示: &l ...
随机推荐
- CentOS 6.5 部署Unison双向同步服务
环境介绍: 服务器 IP Server1 192.168.30.131 Server2 192.168.30.132 1.添加主机互信: a.添加host文件(在Server1.Serve ...
- macos上安装wget命令
首先从Apple Store下载Xcode,然后安装Xcode,接着安装Homebrew包管理,类似于Ubuntu下的apt-get: 终端下输入ruby -e "$(curl -fsSL ...
- schemes-universalLink-share_IOS-android-WeChat-chunleiDemo
schemes-universalLink-share_IOS-android-WeChat-chunleiDemo The mobile terminal share page start APP ...
- 今天学习的裸板驱动之GPIO实验学习心得
GPIO分成很多组今天学习的这个芯片的GPIO有GPA-GPJ个组.具体可在芯片手册中看到. GPIO有很多寄存器,今天学习的这个芯片,他的寄存器分为以下几种类型: (1)端口控制寄存器 (2)端口数 ...
- Unity3DGUI:常用控件
- XTU 1249 Rolling Variance
$2016$长城信息杯中国大学生程序设计竞赛中南邀请赛$G$题 前缀和. 把公式化开来,会发现只要求一段区间的和以及一段区间的平方和就可以了. #pragma comment(linker, &quo ...
- c#简单易用的短信发送服务 悠逸企业短信服务
悠逸企业短信发送服务,是一种比较简单易操作的短信发送服务,使用POST的方式,请求相应地址就可以实现短信发送功能 1 /// <summary> /// 短信发送服务 /// </ ...
- ng-Directive
伪代码: var myModule = angular.module(...); myModule.directive('namespaceDirectiveName', function facto ...
- 301跳转:IIS服务器网站整站301永久重定向设置方法(阿里云)
欢迎来到重庆SEO俱乐部:搜索引擎优化学习交流QQ群224306761. 承接:seo优化.网站建设.论坛搭建.博客制作.全网营销 博主可接:百度百家.今日头条.一点资讯等软文发布,有需要请联系PE! ...
- ubuntu 文件编码错误
linux 打开出现中文编码错误(invalid encoding): convmv -f gbk -t utf-8 -r --notest /filename