Mahout实战---编写自己的相似度计算方法
Mahout本身提供了很多的相似度计算方法,如PCC,COS等。但是当需要验证自己想出来的相似度计算公式是否是好的,这时候需要自己实现相似度类。研究了Mahout-core-0.9.jar的源码后,自己实现了一篇论文上面的相似度公式。:
论文题目:An effective collaborative filtering algorithm based on user preference clustering
具体公式如下:
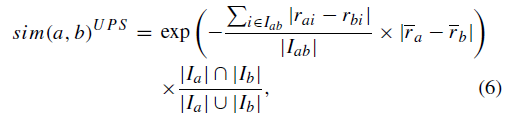
实现过程:具体实现参考了LogLikeHoodSimilarity类的实现
1,实现org.apache.mahout.cf.taste.similarity.UserSimilarity接口
该接口有三个方法:
public interface UserSimilarity extends Refreshable {
double userSimilarity(long userID1, long userID2) throws TasteException;
void setPreferenceInferrer(PreferenceInferrer inferrer);
void refresh(Collection<Refreshable> alreadyRefreshed);//是Refreshable的方法
}
2,void refresh(Collection<Refreshable> alreadyRefreshed);
该方法用于刷新组件(Mahout对于数据改变的时候做出的应对方法。《Mahout实战》中3.2.3节可刷新组件中提到);具体实现如下:
public void refresh(Collection<Refreshable> alreadyRefreshed) {
// TODO Auto-generated method stub
alreadyRefreshed = RefreshHelper.buildRefreshed(alreadyRefreshed);
RefreshHelper.maybeRefresh(alreadyRefreshed, getDataModel());
}
3,void setPreferenceInferrer(PreferenceInferrer inferrer);
这个方法我没有实现,它的作用:可以通过PreferenceInferrer 得到对未打分项的预测评分。
4,double userSimilarity(long userID1, long userID2) throws TasteException;
该方法需要根据公式实现:计算user1和user2的相似度。
在这之前需要传递一个DataModel进来(定义成类的成员变量,由构造函数传递进来)。
具体实现如下:
/**
* 实现该方法即实现了相似度计算方法
*/
public double userSimilarity(long userID1, long userID2) throws TasteException {
// TODO Auto-generated method stub
DataModel dataModel = getDataModel();
//获取用户打分项的id集合
FastIDSet prefs1 = dataModel.getItemIDsFromUser(userID1);
FastIDSet prefs2 = dataModel.getItemIDsFromUser(userID2); long prefs1Size = prefs1.size();
long prefs2Size = prefs2.size(); /*
* long intersectionSize = prefs1Size < prefs2Size ?
* prefs2.intersectionSize(prefs1) : prefs1.intersectionSize(prefs2);
*/
// 计算交集的大小和产生新的FastIDSet作为交集
FastIDSet pre_a, pre_b;// a为大的集合
FastIDSet pre_com = new FastIDSet();
if (prefs1Size < prefs2Size) {
pre_a = prefs2;
pre_b = prefs1;
} else {
pre_a = prefs1;
pre_b = prefs2;
}
int intersectionSize = 0;
Iterator<Long> iterator = pre_b.iterator();
while (iterator.hasNext()) {
long type = (long) iterator.next();
if (pre_a.contains(type)) { pre_com.add(type);
}
}
intersectionSize = pre_com.size();
// 如果交集为0,则相似度为0
if (intersectionSize == 0) {
return 0;
}
// 计算并集的大小
long unionSize = unionSize(pre_a, pre_b); // 计算userID1的平均打分
float avg_1 = avgPreferences(userID1, prefs1);
// 计算userID2的平均打分
float avg_2 = avgPreferences(userID2, prefs2); // 计算共同打分项的打分差的和
double sum = 0.0;
iterator = pre_com.iterator();
while (iterator.hasNext()) {
long itemID = iterator.next();
sum += Math
.abs(dataModel.getPreferenceValue(userID1, itemID) - dataModel.getPreferenceValue(userID2, itemID));
}
return Math.exp(-((sum * 1.0) / intersectionSize) * Math.abs(avg_1 - avg_2))
* ((intersectionSize * 1.0) / unionSize);
}
/**
* FastIDSet只实现了intersectionSize(求交集), 现实现求并
*/
private int unionSize(FastIDSet a, FastIDSet b) {
int count = a.size();
Iterator<Long> iterator = b.iterator();
while (iterator.hasNext()) {
long type = (long) iterator.next();
if (!a.contains(type)) {
count++;
}
}
return count;
} /**
* 计算用户的打分平均值
*
* @throws TasteException
*/
private float avgPreferences(long userID, FastIDSet set) throws TasteException {
float score = (float) 0.0;
Iterator<Long> iterator = set.iterator();
while (iterator.hasNext()) {
long type = (long) iterator.next();
score += dataModel.getPreferenceValue(userID, type);
}
return score / set.size();
}
5,测试实现的正确性
根据论文的测试数据对实现的正确性进行测试
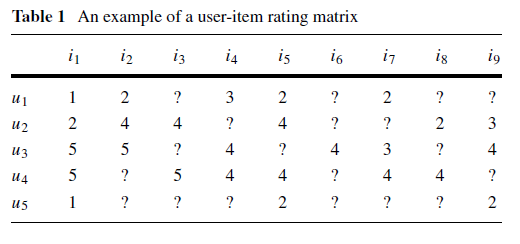
生成ups.csv
1,101,1.0
1,102,2.0
1,104,3.0
1,105,2.0
1,107,2.0 2,101,2.0
2,102,4.0
2,103,4.0
2,105,4.0
2,108,2.0
2,109,3.0 3,101,5.0
3,102,5.0
3,104,4.0
3,106,4.0
3,107,3.0
3,109,4.0 4,101,5.0
4,103,5.0
4,104,4.0
4,105,4.0
4,107,4.0
4,108,4.0 5,101,1.0
5,105,2.0
5,109,2.0
测试程序如下:
public class UPSTest {
public static void main(String[] args) throws IOException, TasteException {
String projectDir = System.getProperty("user.dir");
DataModel model = new FileDataModel(new File(projectDir + "/src/main/ups.csv"));
UserSimilarity similarity = new UPSSimiliarity(model);
DecimalFormat df = new DecimalFormat("#,##0.0000");// 保留4位小数
System.out.println(df.format(similarity.userSimilarity(1, 2)));
System.out.println(df.format(similarity.userSimilarity(1, 3)));
System.out.println(df.format(similarity.userSimilarity(1, 4)));
System.out.println(df.format(similarity.userSimilarity(1, 5)));
System.out.println(df.format(similarity.userSimilarity(2, 3)));
System.out.println(df.format(similarity.userSimilarity(2, 4)));
System.out.println(df.format(similarity.userSimilarity(2, 5)));
System.out.println(df.format(similarity.userSimilarity(3, 4)));
System.out.println(df.format(similarity.userSimilarity(3, 5)));
System.out.println(df.format(similarity.userSimilarity(4, 5)));
}
}
运行结果如下:
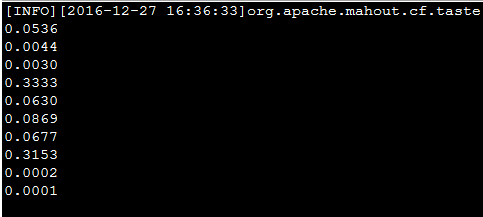
与论文中的结果基本相同:

参考 论文:[1] Zhang, Jia, et al. "An effective collaborative filtering algorithm based on user preference clustering." Applied Intelligence (2016): 1-11.
[2] Mahout实战
Mahout实战---编写自己的相似度计算方法的更多相关文章
- hadoop Mahout中相似度计算方法介绍(转)
来自:http://blog.csdn.net/samxx8/article/details/7691868 相似距离(距离越小值越大) 优点 缺点 取值范围 PearsonCorrelation 类 ...
- 《mahout实战》
<mahout实战> 基本信息 原书名:Mahout in action 作者: (美)Sean Owen Robin Anil Ted Dunning Ellen Fr ...
- Mahout实战---运行第一个推荐引擎
创建输入 创建intro.csv文件,内容如下 1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101, ...
- Mahout实战---评估推荐程序
推荐程序的一般评测标准有MAE(平均绝对误差),Precision(查准率),recall(查全率) 针对Mahout实战---运行第一个推荐引擎 的推荐程序,将使用上面三个标准分别测量 MAE(平均 ...
- Mahout的taste里的几种相似度计算方法
欧几里德相似度(Euclidean Distance) 最初用于计算欧几里德空间中两个点的距离,以两个用户x和y为例子,看成是n维空间的两个向量x和y, xi表示用户x对itemi的喜好值,yi表示 ...
- Dapr 与 NestJs ,实战编写一个 Pub & Sub 装饰器
Dapr 是一个可移植的.事件驱动的运行时,它使任何开发人员能够轻松构建出弹性的.无状态和有状态的应用程序,并可运行在云平台或边缘计算中,它同时也支持多种编程语言和开发框架.Dapr 确保开发人员专注 ...
- 大规模向量相似度计算方法(Google在07年发表的文章)
转载请注明出处:http://www.cnblogs.com/zz-boy/p/3648878.html 更多精彩文章在:http://www.cnblogs.com/zz-boy/ 最近看了Goog ...
- McCabe环路复杂度计算方法
环路复杂度用来定量度量程序的逻辑复杂度.以McCabe方法来表示. 在程序控制流程图中,节点是程序中代码的最小单元,边代表节点间的程序流.一个有e条边和n个节点的流程图F,可以用下述3种方法中的任何一 ...
- 专项测试实战 | 如何测试 App 流畅度(基于 FPS 和丢帧率)
本文为霍格沃兹测试学院学员学习笔记. FPS 和丢帧率可以在一定程度上作为 APP 流畅度的一项衡量标准,本文介绍利用 adb shell dumpsys gfxinfo 命令获取软件渲染加载过程的数 ...
随机推荐
- Win10系统下编译OSG3.4
环境说明 1.Win10专业版.64位: 2.VS2012旗舰版:QT5.2.0: 3.cmake-3.9.0.64位: 资源准备 1.OSG3.4源码包 http://trac.opensceneg ...
- Dalsa线扫相机配置-一台工控机同时连接多个GigE相机
如图,我强悍的工控机,有六个网口. 实际用的时候连了多台相机,为了偷懒我就把六个网口的地址分别设为192.168.0.1~192.168.0.6,以为相机的IP只要设在192.168.0这个网段然后随 ...
- windows服务器让WEB通过防火墙的问题
服务器环境:windows server 2012 X64WEB服务器:IIS开放8080,PHPSduty开放80 如果关闭防火墙的情况下,不论是IIS还是安装的其他的WEB服务器,都可以正常访问. ...
- 使用nexus来搭建Nuget私服
近期在搭建nuget私服.选择nexus这个产品.nexus支持npm,.nuget等,功能比较强大. 前言 博主使用centos7.5来搭建nexus,遇到了不少的问题.最后还是搞定了. 1:下载n ...
- MaxScript调用DotNet时命名空间的问题
Fn GetSpecialFolder argEnumName = (DotNetClass "System.Environment").GetFolderPath (Execut ...
- Cordova - CordovaError: Promise rejected with non-error: 'ios-deploy was not found
错误信息: CordovaError: Promise rejected with non-error: 'ios-deploy was not found. Please download, bui ...
- iOS - 安全
1. CheckList http://www.jianshu.com/p/d3cc2d5c177d a 数据安全.分为数据传输安全和数据存储安全 数据存储安全为保存在App中的数据安全.不允许明文存 ...
- Zookeeper原理分析之存储结构Snapshot
Zookeeper内存结构 Zookeeper数据在内存中的结构类似于linux的目录结构,DataTree代表这个目录结构, DataNode代表一个节点.DataTree默认初始化三个目录:&qu ...
- 位域(bit fields)简介
使用位域或位操作移动一个字节中的位 Java中EnumSet代替位域代码详解 关于位域的一些东西 深入理解Java枚举类型(enum) 位域是指信息在存储时,并不需要占用一个完整的字节, 而只需占几个 ...
- Android Ble4.0开发
最近在做一个蓝牙的项目,是Blu4.0,Android系统支持是4.3版本以上(为此特地卖了个手机,). 当然也参考了不少大牛的的微博,说的都不错,再次特地感谢 http://blog.csdn.ne ...