自然语言处理--TF-IDF(关键词提取)
TF-IDF算法
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。该算法在数据挖掘、文本处理和信息检索等领域得到了广泛的应用,如从一篇文章中找到它的关键词。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上就是 TF*IDF,其中 TF(Term Frequency),表示词条在文章Document 中出现的频率;IDF(Inverse Document Frequency),其主要思想就是,如果包含某个词 Word的文档越少,则这个词的区分度就越大,也就是 IDF 越大。对于如何获取一篇文章的关键词,我们可以计算这边文章出现的所有名词的 TF-IDF,TF-IDF越大,则说明这个名词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
计算步骤
计算词频(TF)
词频 = 某个词在文章中的出现次数 / 文章总次数
计算逆文档频率(IDF)
逆文档频率 = log(语料库的文档总数 / (包含和改词的文档数 + 1)) (10为底)
计算词频-逆文档频率(TF-IDF)
TF-IDF = 词频 * 逆文档频率
举例
对《中国的蜜蜂养殖》进行词频(Term Frequency,缩写为TF)统计
出现次数最多的词是----“的”、“是”、“在”----这一类最常用的词(停用词),不计入统计范畴。
发现“中国”、“蜜蜂”、“养殖”这三个词的出现次数一样多,重要性是一样的?
"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见
《中国的蜜蜂养殖》:假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次, 则这三个词的"词频"(TF)都为0.02
假定搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。
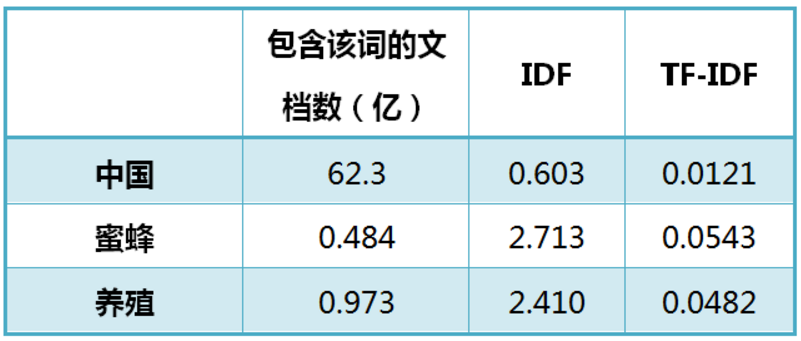
可见蜜蜂和养殖比中国在文档中更‘关键’,即更具有代表性。
自然语言处理--TF-IDF(关键词提取)的更多相关文章
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- 关键词提取算法TF-IDF与TextRank
一.前言 随着互联网的发展,数据的海量增长使得文本信息的分析与处理需求日益突显,而文本处理工作中关键词提取是基础工作之一. TF-IDF与TextRank是经典的关键词提取算法,需要掌握. 二.TF- ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- python实现关键词提取
今天我来弄一个简单的关键词提取的代码 文章内容关键词的提取分为三大步: (1) 分词 (2) 去停用词 (3) 关键词提取 分词方法有很多,我这里就选择常用的结巴jieba分词:去停用词,我用了一个停 ...
- 关键词提取TF-IDF算法/关键字提取之TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术.TF的意思是词频(Term - frequency), ...
- Gradle +HanLP +SpringBoot 构建关键词提取,摘要提取 。入门篇
前段时间,领导要求出一个关键字提取的微服务,要求轻量级. 对于没写过微服务的一个小白来讲.有点赶鸭子上架,但是没办法,硬着头皮上也不能说不会啊. 首先了解下公司目前的架构体系,发现并不是分布式开发,只 ...
- NLP之关键词提取(TF-IDF、Text-Rank)
1.文本关键词抽取的种类: 关键词提取方法分为有监督.半监督和无监督三种,有监督和半监督的关键词抽取方法需要浪费人力资源,所以现在使用的大多是无监督的关键词提取方法. 无监督的关键词提取方法又可以分为 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
随机推荐
- hdu 5882 Balanced Game 2016-09-21 21:22 80人阅读 评论(0) 收藏
Balanced Game Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) To ...
- iOS应用开发最佳实践
<iOS应用开发最佳实践> 基本信息 作者: 王浩 出版社:电子工业出版社 ISBN:9787121207679 上架时间:2013-7-22 出版日期:2013 年8月 开本:16 ...
- 【转】【译】【Win10】在你的程序标题栏中显示后退按钮
原文地址:http://www.sharpgis.net/post/2015/05/21/Displaying-a-backbutton-in-your-app-window 免责声明:这篇文章基于 ...
- LeetCode151:Reverse Words in a String
题目: Given an input string, reverse the string word by word. For example, Given s = "the sk ...
- Checkpoint--查看各DB上的脏页
可以使用sys.dm_os_buffer_descriptors来看数据页在buffer pool中的状态,其中is_modified来标示数据页是否为脏页 --------------------- ...
- Alwayson--与复制的影响
在主副本上建立复制后,复制的事务日志读取代理(log reader)不会读取尚未同步到辅助副本的日志,因为辅助副本可能在下一时刻转化成为主副本,变为新的复制发布服务器,为此需要保证复制处理的日志总慢于 ...
- 新建/初始化git项目
Command line instructions Git global setup git config --global user.name "你的名字" git config ...
- 【加密算法】MD5
一.简介 MD5的全称是Message-Digest Algorithm 5(信息摘要算法),在90年代初由MIT Laboratory for Computer Science和RSA Data S ...
- dorado7-发布
1.首先将configure.properties中Debug删除 2.eclipse自带的打包方式进行打包 2.1 next==>选择打包文件存放的路径==>finish==>xx ...
- NetCore入门篇:(八)Net Core项目使用Controller之三
一.简介 1.本节主要说明入参的几种接收方式 二.不限定模式 1.定义一个id入参与一个model入参. 2.get\post分别查看访问效果. api代码 public class OneContr ...