盘古分词+一元/二元分词Lucene
本文参考自:https://blog.csdn.net/mss359681091/article/details/52078147
http://www.cnblogs.com/top5/archive/2011/08/18/2144030.html
本文所有需要用到的文件下载包含项目:
1.一元分词 / 2.二元分词 / 3.盘古分词 / 4.中文分词 / 5.简单搜索
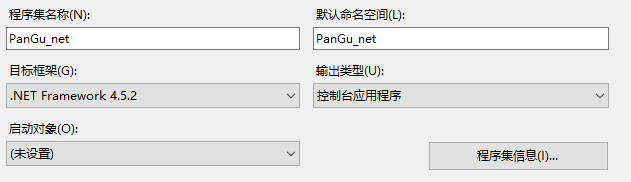
用vs2015创建Windows窗体应用程序,创建好项目时记得将其属性改为“控制台应用程序”,当然也可以是默认的,只是这样方便些。如下图
1.一元分词法
除此外,还需要引用’Lucene.Net.dll‘
/// <summary>
/// 一元分词法
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button1_Click(object sender, EventArgs e)
{
Analyzer analyzer = new StandardAnalyzer(); // 标准分词 → 一元分词
TokenStream tokenStream = analyzer.TokenStream("", new StringReader("喝奶只喝纯牛奶,这是不可能的——黑夜中的萤火虫"));
Token token = null;
while ((token = tokenStream.Next()) != null) // 只要还有词,就不返回null
{
string word = token.TermText(); // token.TermText() 取得当前分词
Console.Write(word + " | ");
}
}
一元分词法
2.二元分词法
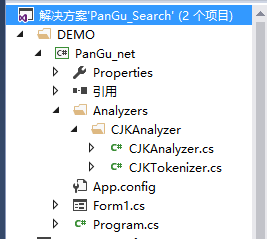
在刚才的基础上,再引用文件夹“Analyzers”中的两个.cs文件,如下图
/// <summary>
/// 二元分词
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button2_Click(object sender, EventArgs e)
{
Analyzer analyzer = new CJKAnalyzer(); // 标准分词 → 一元分词
TokenStream tokenStream = analyzer.TokenStream("", new StringReader("喝奶只喝纯牛奶,这是不可能的——黑夜中的萤火虫"));
Token token = null;
while ((token = tokenStream.Next()) != null) // 只要还有词,就不返回null
{
string word = token.TermText(); // token.TermText() 取得当前分词
Console.Write(word + " | ");
}
}
二元分词法
3.盘古分词法
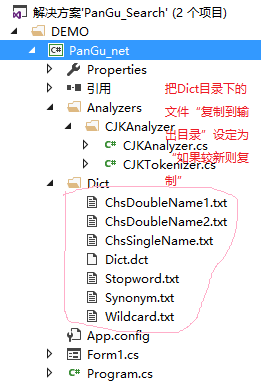
再引用以下两个配置文件

/// <summary>
/// 盘古分词法
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button3_Click(object sender, EventArgs e)
{
Analyzer analyzer = new PanGuAnalyzer(); // 盘古分词
TokenStream tokenStream = analyzer.TokenStream("", new StringReader("喝奶只喝纯牛奶,这是不可能的——黑夜中的萤火虫"));
Token token = null;
while ((token = tokenStream.Next()) != null) // 只要还有词,就不返回null
{
string word = token.TermText(); // token.TermText() 取得当前分词
Console.Write(word + " | ");
}
}
盘古分词法
如果不去更改,盘古词包中并不包含所需词汇,以下是运行效果图

而用‘DictManage.exe‘来打开项目中的Dict.dct文件,添加词汇,并加以保存。
下图是修改后的运行效果:

4.中文分词算法

private void button1_Click(object sender, EventArgs e)
{
StringBuilder sb = new StringBuilder();
sb.Remove(, sb.Length);
string t1 = "";
int i = ;
Analyzer analyzer = new Lucene.China.ChineseAnalyzer();
StringReader sr = new StringReader(richTextBox1.Text);
TokenStream stream = analyzer.TokenStream(null, sr); long begin = System.DateTime.Now.Ticks;
Token t = stream.Next();
while (t != null)
{
t1 = t.ToString(); //显示格式: (关键词,0,2) ,需要处理
t1 = t1.Replace("(", "");
char[] separator = { ',' };
t1 = t1.Split(separator)[]; sb.Append(i + ":" + t1 + "\r\n");
t = stream.Next();
i++;
}
richTextBox2.Text = sb.ToString();
long end = System.DateTime.Now.Ticks; //100毫微秒
int time = (int)((end - begin) / ); //ms richTextBox2.Text += "耗时" + (time) + "ms \r\n=================================\r\n";
}
中文分词测试后台代码
5.简单搜索
创建web窗体SearchWords.aspx,如下图
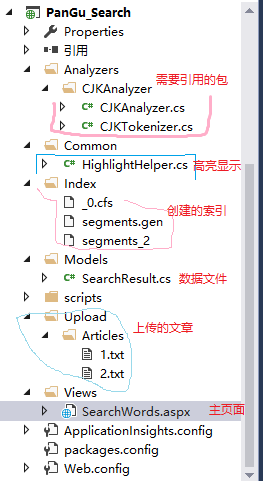
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="SearchWords.aspx.cs" Inherits="PanGu_Search.Views.SearchWords" %> <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<title>最简单的搜索引擎</title>
<script>
$(document).keydown(function (event) {
if (event.keyCode == ) {
$("#btnGetSearchResult").click();
}
});
</script>
</head>
<body>
<form id="mainForm" runat="server">
<div align="center">
<asp:Button ID="btnCreateIndex" runat="server" Text="Create Index" OnClick="btnCreateIndex_Click" />
<asp:Label ID="lblIndexStatus" runat="server" Visible="false" />
<hr />
<asp:TextBox ID="txtKeyWords" runat="server" Text="" Width=""></asp:TextBox>
<asp:Button ID="btnGetSearchResult" runat="server" Text="Search" OnClick="btnGetSearchResult_Click" />
<hr />
</div>
<div>
<ul>
<asp:Repeater ID="rptSearchResult" runat="server">
<ItemTemplate>
<li>Id:<%#Eval("Id") %><br /><%#Eval("Msg") %></li>
</ItemTemplate>
</asp:Repeater>
</ul>
</div>
</form>
</body>
</html>
前台aspx设计
/// <summary>
/// 创建索引方法
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
protected void btnCreateIndex_Click(object sender, EventArgs e)
{
string indexPath = Context.Server.MapPath("~/Index"); // 索引文档保存位置
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
bool isUpdate = IndexReader.IndexExists(directory); //判断索引库是否存在
if (isUpdate)
{
// 如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁
// Lucene.Net在写索引库之前会自动加锁,在close的时候会自动解锁
// 不能多线程执行,只能处理意外被永远锁定的情况
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory); //unlock:强制解锁,待优化
}
}
// 创建向索引库写操作对象 IndexWriter(索引目录,指定使用盘古分词进行切词,最大写入长度限制)
// 补充:使用IndexWriter打开directory时会自动对索引库文件上锁
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate,
IndexWriter.MaxFieldLength.UNLIMITED); for (int i = ; i < ; i++)
{
string txt = File.ReadAllText(Context.Server.MapPath("~/Upload/Articles/") + i + ".txt");
// 一条Document相当于一条记录
Document document = new Document();
// 每个Document可以有自己的属性(字段),所有字段名都是自定义的,值都是string类型
// Field.Store.YES不仅要对文章进行分词记录,也要保存原文,就不用去数据库里查一次了
document.Add(new Field("id", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
// 需要进行全文检索的字段加 Field.Index. ANALYZED
// Field.Index.ANALYZED:指定文章内容按照分词后结果保存,否则无法实现后续的模糊查询
// WITH_POSITIONS_OFFSETS:指示不仅保存分割后的词,还保存词之间的距离
document.Add(new Field("msg", txt, Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
// 防止重复索引,如果不存在则删除0条
writer.DeleteDocuments(new Term("id", i.ToString()));// 防止已存在的数据 => delete from t where id=i
// 把文档写入索引库
writer.AddDocument(document);
Console.WriteLine("索引{0}创建完毕", i.ToString());
} writer.Close(); // Close后自动对索引库文件解锁
directory.Close(); // 不要忘了Close,否则索引结果搜不到 lblIndexStatus.Text = "索引文件创建成功!";
lblIndexStatus.Visible = true;
btnCreateIndex.Enabled = false;
}
创建索引方法
/// <summary>
/// 搜索方法
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
protected void btnGetSearchResult_Click(object sender, EventArgs e)
{
string keyword = txtKeyWords.Text; string indexPath = Context.Server.MapPath("~/Index"); // 索引文档保存位置
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
// 查询条件
PhraseQuery query = new PhraseQuery();
// 等同于 where contains("msg",kw)
query.Add(new Term("msg", keyword));
// 两个词的距离大于100(经验值)就不放入搜索结果,因为距离太远相关度就不高了
query.SetSlop();
// TopScoreDocCollector:盛放查询结果的容器
TopScoreDocCollector collector = TopScoreDocCollector.create(, true);
// 使用query这个查询条件进行搜索,搜索结果放入collector
searcher.Search(query, null, collector);
// 从查询结果中取出第m条到第n条的数据
// collector.GetTotalHits()表示总的结果条数
ScoreDoc[] docs = collector.TopDocs(, collector.GetTotalHits()).scoreDocs;
// 遍历查询结果
IList<SearchResult> resultList = new List<SearchResult>();
for (int i = ; i < docs.Length; i++)
{
// 拿到文档的id,因为Document可能非常占内存(DataSet和DataReader的区别)
int docId = docs[i].doc;
// 所以查询结果中只有id,具体内容需要二次查询
// 根据id查询内容:放进去的是Document,查出来的还是Document
Document doc = searcher.Doc(docId);
SearchResult result = new SearchResult();
result.Id = Convert.ToInt32(doc.Get("id"));
result.Msg = HighlightHelper.HighLight(keyword, doc.Get("msg")); resultList.Add(result);
} // 绑定到Repeater
rptSearchResult.DataSource = resultList;
rptSearchResult.DataBind();
}
搜索方法
protected void Page_Load(object sender, EventArgs e)
{
if (!IsPostBack)
{
// 检查是否已存在生成的索引文件
CheckIndexData();
}
} /// <summary>
/// 检查索引是否创建成功
/// </summary>
private void CheckIndexData()
{
string indexPath = Context.Server.MapPath("~/Index"); // 索引文档保存位置
var files = System.IO.Directory.GetFiles(indexPath);
if (files.Length > )
{
btnCreateIndex.Visible = false;
lblIndexStatus.Text = "简单搜索";
lblIndexStatus.Visible = true;
}
}
检查索引是否存在方法
运行效果如图:

盘古分词+一元/二元分词Lucene的更多相关文章
- 让盘古分词支持最新的Lucene.Net 3.0.3
原文:让盘古分词支持最新的Lucene.Net 3.0.3 好多年没升级过的Lucene.Net最近居然升级了,到了3.0.3后接口发生了很大变化,原来好多分词库都不能用了,所以上次我把MMSeg给修 ...
- ElasticSearch已经配置好ik分词和mmseg分词(转)
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进行数据索引 ...
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- .添加索引和类型,同时设定edgengram分词和charsplit分词
1.添加索引和类型,同时设定edgengram分词和charsplit分词 curl -XPUT 'http://127.0.0.1:9200/userindex/' -d '{ "se ...
- 为Elasticsearch添加中文分词,对比分词器效果
http://keenwon.com/1404.html Elasticsearch中,内置了很多分词器(analyzers),例如standard (标准分词器).english(英文分词)和chi ...
- Elasticsearch拼音分词和IK分词的安装及使用
一.Es插件配置及下载 1.IK分词器的下载安装 关于IK分词器的介绍不再多少,一言以蔽之,IK分词是目前使用非常广泛分词效果比较好的中文分词器.做ES开发的,中文分词十有八九使用的都是IK分词器. ...
- 和我一起打造个简单搜索之IK分词以及拼音分词
elasticsearch 官方默认的分词插件,对中文分词效果不理想,它是把中文词语分成了一个一个的汉字.所以我们引入 es 插件 es-ik.同时为了提升用户体验,引入 es-pinyin 插件.本 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
随机推荐
- Android logcat输出中文乱码
使用adb的logcat 命令查看系统日志缓冲区的内容,会发现在CMD的界面面,直接输出的中文内容是乱码. 这个问题出现在使用logcat将日志直接打印在当前的DOS窗口的时候会出现:使用logcat ...
- goim源码分析与二次开发-comet分析一
因为要完成一个聊天的项目,所以借鉴了goim,第一篇分析打算半原版,先摘抄http://www.jianshu.com/p/8bd96a9a473d他的一些理解,写这些还是为了让自己更好的理解这个项目 ...
- preset
preset - 必应词典 美[.pri'set]英[.priː'set] v.预置:事先安排:预调:给…预定时间 网络预设:预先装置:预置位
- linux下每次git clone不需输入账号密码的方法
在~/下, touch创建文件 .git-credentials, 用vim编辑此文件,输入内容格式: ame@zhenyun ~ $touch .git-credentials ame@zhenyu ...
- js手机号码正则表达式
function checkMobile(){ var sMobile = document.mobileform.mobile.value if(!(/^1[3|4|5|8][0-9]\d{4,8} ...
- 关于前一篇innodb自增列自己的一点补充
上篇文章是我转载的,忘记注明了出处,在这里深感歉意.但是上篇文章中关于自增列预留ID的计算我当时怎么弄明白,后来自己想了想终于想通了,在这里详细解释一下. 我们以一次性插入10行为例,表格如下: 插 ...
- PAT 1010 一元多项式求导 (25)(STL-map+思路)
1010 一元多项式求导 (25)(25 分)提问 设计函数求一元多项式的导数.(注:x^n^(n为整数)的一阶导数为n*x^n-1^.) 输入格式:以指数递降方式输入多项式非零项系数和指数(绝对值均 ...
- Ui设计流行趋势,对颜色的探讨
设计风向转换的趋势越来越短,在设计圈中,流行设计的跟新换代更是快.在设计时间越来越短的今天,在经理领导不断催促的时下,如何准确的把握当下的流行趋势,如何在设计之初就能定好设计的基调.这对于还是刚入设计 ...
- laravel的函数asset()、url()
1.asset():用于引入静态文件,如 css/JavaScript/images,文件必须存放在public文件目录下 src="{{ asset('home') }}/images/t ...
- Vue2.0 keep-alive 组件的最佳实践
1.基本用法 vue2.0提供了一个keep-alive组件用来缓存组件,避免多次加载相应的组件,减少性能消耗 <keep-alive> <component> <!-- ...