PHP利用二叉堆实现TopK-算法的方法详解
前言
在以往工作或者面试的时候常会碰到一个问题,如何实现海量TopN,就是在一个非常大的结果集里面快速找到最大的前10或前100个数,同时要保证 内存和速度的效率,我们可能第一个想法就是利用排序,然后截取前10或前100,而排序对于量不是特别大的时候没有任何问题,但只要量特别大是根本不可能 完成这个任务的,比如在一个数组或者文本文件里有几亿个数,这样是根本无法全部读入内存的,所以利用排序解决这个问题并不是最好的,所以我们这里就用 php去实现一个小顶堆来解决这个问题.
二叉堆
二叉堆是一种特殊的堆,二叉堆是完全二叉树或者是近似完全二叉树,二叉堆有两种,最大堆 和 最小堆,最大堆:父结点的键值总是大于或等于任何一个子节点的键值;最小堆:父结点的键值总是小于或等于任何一个子节点的键值

小顶堆-(图片来自网络)
二叉堆一般用数组来表示(看上图),例如,根节点在数组中的位置是0,第n个位置的子节点分别在2n+1和 2n+2,因此,第0个位置的子节点在1和2,1的子节点在3和4,以此类推,这种存储方式便於寻找父节点和子节点。
具体概念问题这里就不在多说了,如果对二叉堆有疑问的可以在好好了解下这个数据结构,下面我们就针对上述topN问题来用php代码实现并解决,为了看出区别这里先用排序的方式去实现下看下效果如何。
利用快速排序算法来实现 TopN
- //为了测试运行内存调大一点
- ini_set('memory_limit', '2024M');
- //实现一个快速排序函数
- function quick_sort(array $array){
- $length = count($array);
- $left_array = array();
- $right_array = array();
- if($length <= 1){
- return $array;
- }
- $key = $array[0];
- for($i=1;$i<$length;$i++){
- if($array[$i] > $key){
- $right_array[] = $array[$i];
- }else{
- $left_array[] = $array[$i];
- }
- }
- $left_array = quick_sort($left_array);
- $right_array = quick_sort($right_array);
- return array_merge($right_array,array($key),$left_array);
- }
- //构造500w不重复数
- for($i=0;$i<5000000;$i++){
- $numArr[] = $i;
- }
- //打乱它们
- shuffle($numArr);
- //现在我们从里面找到top10最大的数
- var_dump(time());
- print_r(array_slice(quick_sort($all),0,10));
- var_dump(time());
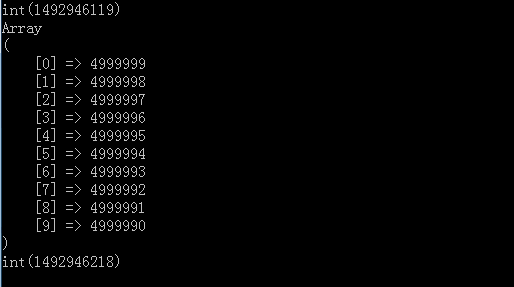
运行之后结果
可以看到上面打印出了top10的结果,并输出了下运行时间,大概99s左右,但这只是500w个数且全部能装入内存的情况,如果我们有一个文件里面有5kw或5亿个数,肯定就会有些问题了.
利用二叉堆算法来实现 TopN
实现流程是:
1、先读取10个或100个数到数组里面,这就是我们的topN数.
2、调用生成小顶堆函数,把这个数组生成一个小顶堆结构,这个时候堆顶一定是最小的.
3、从文件或者数组依次遍历剩余的所有数.
4、每遍历出来一个则跟堆顶的元素进行大小比较,如果小于堆顶元素则抛弃,如果大于堆顶元素则替换之.
5、跟堆顶元素替换完毕之后,在调用生成小顶堆函数继续生成小顶堆,因为需要再找出来一个最小的.
6、重复以上4~5步骤,这样当全部遍历完毕之后,我们这个小顶堆里面的就是最大的topN,因为我们的小顶堆永远都是排除最小的留下最大的,而且这个调整小顶堆速度也很快,只是相对调整下,只要保证根节点小于左右节点就可以.
7、算法复杂度的话按top10最坏的情况下,就是每遍历一个数,如果跟堆顶进行替换,需要调整10次的情况,也要比排序速度快,而且也不是把所有的内容全部读入内存,可以理解成就是一次线性遍历.
- //生成小顶堆函数
- function Heap(&$arr,$idx){
- $left = ($idx << 1) + 1;
- $right = ($idx << 1) + 2;
- if (!$arr[$left]){
- return;
- }
- if($arr[$right] && $arr[$right] < $arr[$left]){
- $l = $right;
- }else{
- $l = $left;
- }
- if ($arr[$idx] > $arr[$l]){
- $tmp = $arr[$idx];
- $arr[$idx] = $arr[$l];
- $arr[$l] = $tmp;
- Heap($arr,$l);
- }
- }
- //这里为了保证跟上面一致,也构造500w不重复数
- /*
- 当然这个数据集并不一定全放在内存,也可以在
- 文件里面,因为我们并不是全部加载到内存去进
- 行排序
- */
- for($i=0;$i<5000000;$i++){
- $numArr[] = $i;
- }
- //打乱它们
- shuffle($numArr);
- //先取出10个到数组
- $topArr = array_slice($numArr,0,10);
- //获取最后一个有子节点的索引位置
- //因为在构造小顶堆的时候是从最后一个有左或右节点的位置
- //开始从下往上不断的进行移动构造(具体可看上面的图去理解)
- $idx = floor(count($topArr) / 2) - 1;
- //生成小顶堆
- for($i=$idx;$i>=0;$i--){
- Heap($topArr,$i);
- }
- var_dump(time());
- //这里可以看到,就是开始遍历剩下的所有元素
- for($i = count($topArr); $i < count($numArr); $i++){
- //每遍历一个则跟堆顶元素进行比较大小
- if ($numArr[$i] > $topArr[0]){
- //如果大于堆顶元素则替换
- $topArr[0] = $numArr[$i];
- /*
- 重新调用生成小顶堆函数进行维护,只不过这次是从堆顶
- 的索引位置开始自上往下进行维护,因为我们只是把堆顶
- 的元素给替换掉了而其余的还是按照根节点小于左右节点
- 的顺序摆放这也就是我们上面说的,只是相对调整下,并
- 不是全部调整一遍
- */
- Heap($topArr,0);
- }
- }
- var_dump(time());
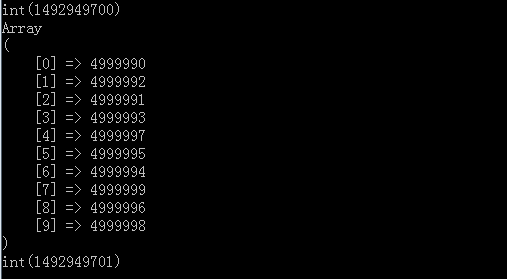
运行之后结果
可以看到最终的结果也是top10,只不过时间只用了1s左右,而且无论是内存还是时间效率都满足我们的要求,而且跟排序比最好的一点就是不用把所
有的数据集都读如到内存里面来,因为我们不需要排序,而上面是为了演示,所以直接在内存构造了500w元素,然而我们可以把这个全部转移到文件里面去,然
后一行一行读取进行比较,因为我们这个数据结构的核心点就是线性遍历跟内存里面很小的小顶堆结构进行比较,最终得到TopN.
总结
最后想说的就是 算法+数据结构 真的非常重要,一个好的算法可以使我们的效率大大提高。好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
原文链接:http://www.jianshu.com/p/df71c71cdc57
PHP利用二叉堆实现TopK-算法的方法详解的更多相关文章
- 利用C#实现AOP常见的几种方法详解
利用C#实现AOP常见的几种方法详解 AOP面向切面编程(Aspect Oriented Programming) 是通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术. 下面这篇文章主要 ...
- 【数据结构与算法Python版学习笔记】树——利用二叉堆实现优先级队列
概念 队列有一个重要的变体,叫作优先级队列. 和队列一样,优先级队列从头部移除元素,不过元素的逻辑顺序是由优先级决定的. 优先级最高的元素在最前,优先级最低的元素在最后. 实现优先级队列的经典方法是使 ...
- java多线程并发(二)--线程的生命周期及方法详解
上篇随笔介绍了线程的相关基础知识以及新启线程的几种方法,本片将继续介绍线程的生命周期及方法详解. 一.线程的生命周期 在Thread代码中,线程的状态被分为6种 public enum State { ...
- PHP-利用二叉堆实现TopK-算法
介绍 在以往工作或者面试的时候常会碰到一个问题,如何实现海量TopN,就是在一个非常大的结果集里面快速找到最大的前10或前100个数,同时要保证内存和速度的效率,我们可能第一个想法就是利用排序,然后截 ...
- Java实现的二叉堆以及堆排序详解
一.前言 二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1.二叉堆类型分为最大堆( ...
- 最短路径——Dijkstra算法以及二叉堆优化(含证明)
一般最短路径算法习惯性的分为两种:单源最短路径算法和全顶点之间最短路径.前者是计算出从一个点出发,到达所有其余可到达顶点的距离.后者是计算出图中所有点之间的路径距离. 单源最短路径 Dijkstra算 ...
- 《Algorithms算法》笔记:优先队列(2)——二叉堆
二叉堆 1 二叉堆的定义 堆是一个完全二叉树结构(除了最底下一层,其他层全是完全平衡的),如果每个结点都大于它的两个孩子,那么这个堆是有序的. 二叉堆是一组能够用堆有序的完全二叉树排序的元素,并在数组 ...
- C# 最大二叉堆算法
C#练习二叉堆算法. namespace 算法 { /// <summary> /// 最大堆 /// </summary> /// <typeparam name=&q ...
- 图论——Dijkstra+prim算法涉及到的优先队列(二叉堆)
[0]README 0.1)为什么有这篇文章?因为 Dijkstra算法的优先队列实现 涉及到了一种新的数据结构,即优先队列(二叉堆)的操作需要更改以适应这种新的数据结构,我们暂且吧它定义为Dista ...
随机推荐
- 文件触发式实时同步 Rsync+Sersync Rsync+Inotify-tools
一.概述 1.Rsync+Sersync 是什么? 1)Sersync使用c++编写基于inotify开发的触发机制: 2)Sersync可以监控所监听的目录发生的变化(包括新建.修改.删除),具体到 ...
- sparkthriftserver启动及调优
Sparkthriftserver启用及优化 1. 概述 sparkthriftserver用于提供远程odbc调用,在远端执行hive sql查询.默认监听10000端口,Hiveserver2默 ...
- Java连接GBase并封装增删改查
1.介绍 GBase 是南大通用数据技术有限公司推出的自主品牌的数据库产品,目前在国内数据库市场具有较高的品牌知名度;GBase品牌的系列数据库都具有自己鲜明的特点和优势:GBase 8a 是国内第一 ...
- oracle 一对多数据分页查询筛选
今天项目测试运行的时候,遇到了一个奇怪的问题,这个问题说起来按sql语法的话是没有错误的 但是呢按照我们的业务来做区分就有些逻辑上的错误了, 下面请听我慢慢道来,在数据库中有两个数据, 先来看下第一次 ...
- 使用jdk压缩war包
首先安装jdk 压缩 ..../jdk/bin/jar -cvf file.war file 解压 ..../jdk/bin/jar -xvf file.war
- [转]微信小程序支付简单小结与梳理
本文转自:https://www.cnblogs.com/onetwo/p/6667424.html 公司最近在做微信小程序,被分配到做支付这一块,现在对这一块做一个简单的总结和梳理. 支付,对于购物 ...
- APICloud APP前端框架——手机APP开发、APP制作、APP定制平台
概述 APICloud前端框架,包括api.js和api.css.api.css处理不同平台浏览器的默认样式.api.js是一个JavaScript库.是APICloud为混合移动开发定制的轻量Jav ...
- lombok入门
pom.xml加入依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lo ...
- win Apache服务消失或无法启动
在bin目录中找到httpd.exe命令,如下图所示.启动cmd,即命令行,使用管理员身份运行,cd至该bin目录下. 使用cmd执行如下命令进行服务的安装:httpd.exe -k instal ...
- Ubuntu使用心得
因为开发学习需要,也接触了一些Ubuntu系统,玩崩了两次系统之后,也学到了一些东西. -------------------------------------------------------- ...