Hadoop的简单使用
Hadoop的简单使用
- 使用Hadoop提供的命令行,向文件系统中创建一个文件。
./hadoop fs -put temp.txt hdfs://localhost:8888/
说明:
- ./hadoop 是bin目录下
- fs 表明对文件系统进行操作
- -put 就是传输
- temp.txt 是我要传输的文件
- hdfs://localhost:8888 是hdfs的入口
检测是否成功上传:
然后点击browse the filesystem
可以看到:

一个简单的MapReduce任务
任务说明: 使用Hadoop自动的一个案例,来统计多个文件的的各个单词出现的次数。
步骤如下:
- 通过ssh上传一些文件。为了方便,我们最好上传文本文件。从 apache的extra目录下把文件上传到ubuntu下

- 将这些文件上传到hadoop的文件系统
2.1先创建一个目录
./hadoop fs -mkdir /task1 【如果要看 hadoop有哪些指令,可以 ./hadoop 如果要看 还可以通过 ./hadoop fs 来看分项的命令】
- 将 /home/hsp/test 的所有文件上传到 /task1目录下
./hadoop fs -put /home/hsp/test/*.* /task1
- 执行一个MapReduce任务,这个是已经写好的,自带的,后面详解,现在体验
./bin/hadoop jar hadoop-examples-1.0.3.jar wordcount /task1 /result1
说明:这个指令一定要在 hadoop的bin目录下执行,因为 hadoop-examples-1.0.3.jar 是在hadoop/bin 目录下的.
结果:

- 验证是否正确
http://localhost:50030 , [这个就是MapReduce的管理界面]可以看到MapReduce 任务的完成情况

点击job_201506...可以看到详细情况,如下:
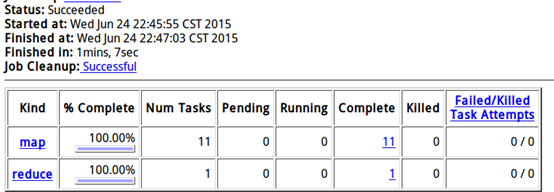
说明: 这个任务被Map了11个,有一个reduce操作。
http://localhost:50070 ,点击 part-r-00000 ,就可以看到结果
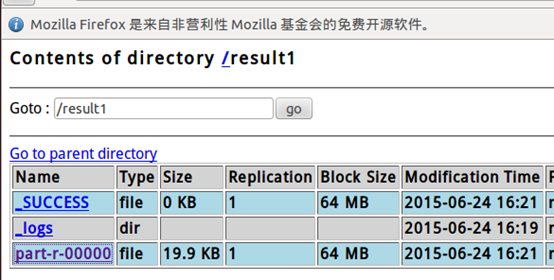
both 是5次,我们在ubuntu 直接统计一下
grep both /home/hsp/test/*.* 可以看到一个5个
grep both /home/hsp/test/*.*|wc 也可以直接得到结果.
Hadoop的简单使用的更多相关文章
- 结合Hadoop,简单理解SSH
在启动dfs和yarn时,需要多次输入密码,不但启动本机进程还有辅服务器启动那些节点也需要相应密码,主与辅服务器之间是通过SSH连接的,并发送操作指令 一.ssh密码远程登录 1.使用ssh连接另一台 ...
- Linux下Hadoop的简单安装
Hadoop 的安装极为简单,一共只有三步: 安装JDK 安装Hadoop 配置Hadoop 1,安装JDK 下载JDK,ftp传到linux或者linux中下载 切换 ...
- Hadoop RPC简单例子
jdk中已经提供了一个RPC框架-RMI,但是该PRC框架过于重量级并且可控之处比较少,所以Hadoop RPC实现了自定义的PRC框架. 同其他RPC框架一样,Hadoop RPC分为四个部分: ( ...
- Hadoop之简单文件读写
文件简单写操作: import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream ...
- Hadoop RPC简单实例
1.导入Hadoop-Common-2.6.0.jar导入工程,里面的IPC实现RPC需要的文件. 2.服务器端 (1)服务接口 package com.neu.rpc.server; /** * ...
- (7)基于hadoop的简单网盘应用实现3
一.login.jsp登陆界面实现 解压bootmetro-master.zip,然后将\bootmetro-master\src\下的assets目录复制到project里. bootmetro下载 ...
- hadoop mapreduce 简单例子
本例子统计 用空格分开的单词出现数量( 这个Main.mian 启动方式是hadoop 2.0 的写法.1.0 不一样 ) 目录结构: 使用的 maven : 下面是maven 依赖. <de ...
- Hadoop的简单序列化框架
Hadoop提供了一个加单的序列化框架API,用于集成各种序列化实现.该框架由Serialization实现. 其中Serialization是一个接口,使用抽象工厂的设计模式,提供了一系列和序列化相 ...
- Hadoop的简单了解与安装
hadoop 一, Hadoop 分布式 简介Hadoop 是分布式的系统架构,是 Apache 基金会顶级金牌项目 分布式是什么?学会用大数据的思想来看待和解决问题 思 想很重要 1-1 . ...
随机推荐
- IO流-批量修改文件名称案例
/* * 源文件名: 桌面-我们今天学习IO流了哈哈哈哈-001.jpg * 修改后文件名: 桌面-000x.jpg */public class File_listFiles_upda ...
- hadoop 2.7.1 高可用安装部署
hadoop集群规划 目标:创建2个NameNode,做高可用,一个NameNode挂掉,另一个能够启动:一个运行Yarn,3台DataNode,3台Zookeeper集群,做高可用. 在hadoop ...
- WCF实现将服务器端的错误信息返回到客户端
转载:http://www.cnblogs.com/zeroone/articles/2299001.html http://www.it165.net/pro/html/201403/11033.h ...
- Entityframework:“System.Data.Entity.Internal.AppConfig”的类型初始值设定项引发异常。
<configSections> <!-- For more information on Entity Framework configuration, visit http:// ...
- Eclipse设置打印线
在调出Preferences之后,选中Text Editors.先选中Show print margin,在Print margin column框中填入180就可以,然后选择以下的Print mar ...
- 程序员眼中的RSA算法
RSA算法是数学应用于实际的一项伟大发明,起数学过程相对而言还是比较专业的,有兴趣可以看看. RSA算法的证明过程,详见:http://www.ruanyifeng.com/blog/2013/06/ ...
- 实现Hadoop的Writable接口Implementing Writable interface of Hadoop
As we saw in the previous posts, Hadoop makes an heavy use of network transmissions for executing it ...
- 语义后承(semantic consequence),句法后承(syntactic consequence),实质蕴含(material implication / material conditional)
作者:罗心澄链接:https://www.zhihu.com/question/21191299/answer/17469774来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- 【BZOJ】【3771】Triple
生成函数+FFT Orz PoPoQQQ 这个题要算组合的方案,而且范围特别大……所以我们可以利用生成函数来算 生成函数是一个形式幂级数,普通生成函数可以拿来算多重集组合……好吧我承认以上是在瞎扯→_ ...
- JDBC操作数据库的批处理
在JDBC开发中,操作数据库需要与数据库建立连接,然后将要执行的SQL语句传送到数据库服务器,最后关闭数据库连接,都是按照这样一个流程进行操作的.如果按照该流程执行多条SQL语句,那么就需要建立多个数 ...