An overview of gradient descent optimization algorithms (更新到Adam)
Momentum:解快了收敛速度,同时也减弱了SGD的波动
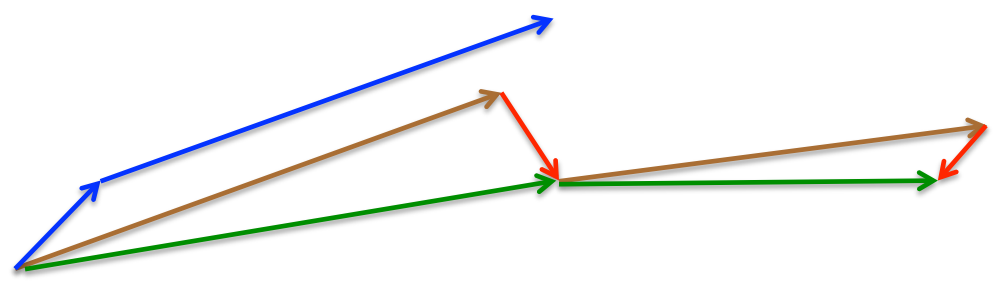
NAG: 减速了Momentum更新参数太快
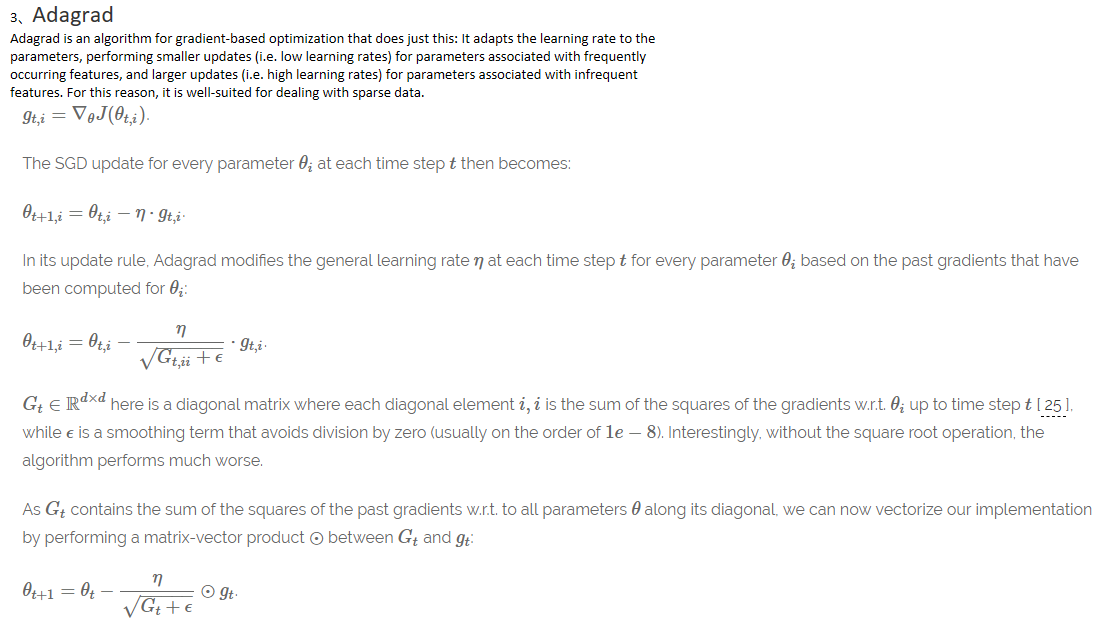
Adagrad: 出现频率较低参数采用较大的更新,对于出现频率较高的参数采用较小的,不共用一个学习率
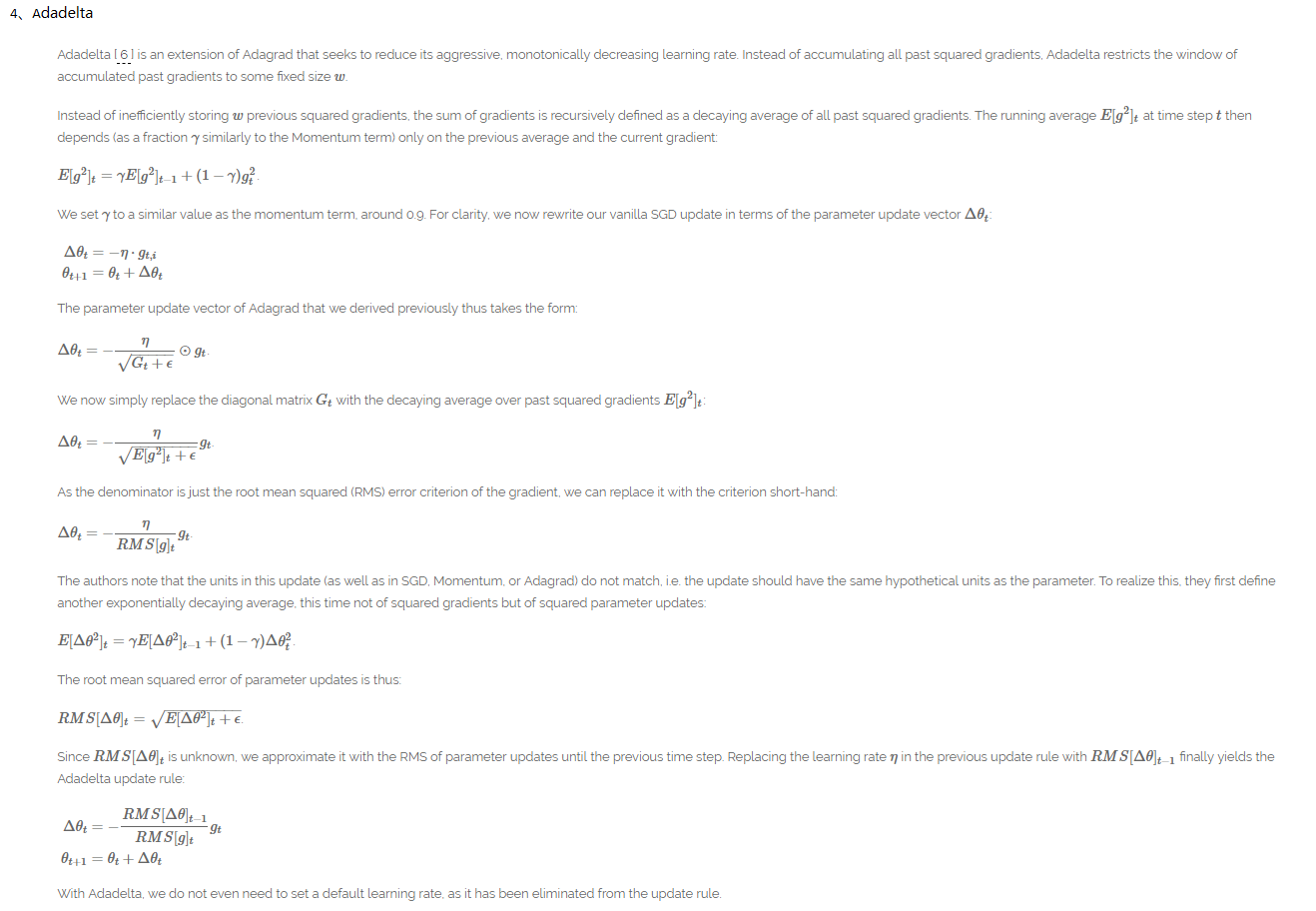
Adadelta:解决了Adagrad后续学习率为0的缺点,同时不要defalut 学习率
RMSprop:解决了Adagrad后续学习率为0的缺点
Adam: 结合了RMSprop和Momentum的优点,Adam might be the best overall choice
参考博客:http://ruder.io/optimizing-gradient-descent/index.html#batchgradientdescent(真大神)




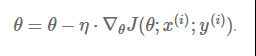


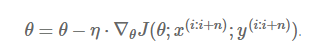





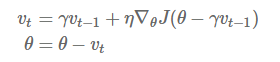

An overview of gradient descent optimization algorithms (更新到Adam)的更多相关文章
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- (转)Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning
Introduction Optimization is always the ultimate goal whether you are dealing with a real life probl ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- [Converge] Gradient Descent - Several solvers
solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}, default: ‘liblinear’ Algorithm to use in the op ...
- [C2W2] Improving Deep Neural Networks : Optimization algorithms
第二周:优化算法(Optimization algorithms) Mini-batch 梯度下降(Mini-batch gradient descent) 本周将学习优化算法,这能让你的神经网络运行 ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
随机推荐
- 利用poi来向execl中写入对象
附上jar包下载链接: 附上百度网盘下载连接: 链接:https://pan.baidu.com/s/1t_jXUq3CuhZo9j_UI4URAQ 密码:r2qi package com.wz.po ...
- 实现运行在独立线程池的调度功能,基于Spring和Annotation
使用Spring的注解(@Scheduled)声明多个调度的时候,由于其默认实现机制,将导致多个调度方法之间相互干扰(简单理解就是调度不按配置的时间点执行). 为了解决该问题尝试了修改线程池大小,但是 ...
- android 布局的两个属性 dither 和 tileMode
tileMode(平铺)tileMode(平铺) 的效果类似于 让背景小图不是拉伸而是多个重复(类似于将一张小图设置电脑桌面时的效果) dither(抖动) Dither(图像的抖动处理,当每个颜色值 ...
- 2017 3 11 分治FFT
考试一道题的递推式为$$f[i]=\sum_{j=1}^{i} j^k \times (i-1)! \times \frac{f[i-j]}{(i-j)!}$$这显然是一个卷积的形式,但$f$需要由自 ...
- loj6070【山东集训第一轮Day4】基因
题解: 分块对每个块的起点$st[i]$到$n$做一次回文自动机; 由于子串的回文自动机是原串的子图,所以并不需要重新构图,在原来的图上做即可: 做的时候记录某个终点的本质不同的回文串和$sum[i] ...
- python检测服务器是否ping通
好想在2014结束前再赶出个10篇博文来,~(>_<)~,不写博客真不是一个好兆头,至少说明对学习的欲望和对知识的研究都不是那么积极了,如果说这1天的时间我能赶出几篇精致的博文,你们信不信 ...
- salt源码安装
salt是什么? 一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯. salt底层采用动态的连接总线, 使其可以用于编配, 远 ...
- 主角场景Shader效果:遮挡透明
基本原理:被遮挡的部分关闭深度写入, 显示透明效果:未被遮挡的部分不关闭深度测试,显示正常贴图效果,即使用两个Pass即可. Pass1:关闭深度写入(ZWrite Off),深度测试渲染较远的物体, ...
- Nginx Upstream Keepalive 分析 保持长连接
Nginx Upstream长连接由upstream模式下的keepalive指令控制,并指定可用于长连接的连接数,配置样例如下: upstream http_backend { server ...
- 将SQL Server账户对应到Windows系统账户
应用场景举例: SQL Server账户要访问外部资源,例如所拥有的Job要访问文件系统,而此文件系统需要Windows账户才有权限. 步骤: 1. 服务器新建凭据(Credentials ...