D05——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D05
20180815内容纲要:
1 模块
2 包
3 import的本质
4 内置模块详解
(1)time&datetime
(2)datetime
(3)random
(4)os
(5)sys
(6)json&pickle
(7)shelve
(8)xml
(9)shutil
(10)PyYaml
(11)configpaser
(12)hashlib
(13)re
5 练习:开发一个简单的python计算器(挑战性很强)
1 模块
模块:
>>>定义:本质就是.py结尾的PYTHON文件,用来从逻辑上组织python代码(变量、函数、类、逻辑),实现一个功能。
>>>导入方法:
import module_name 调用module_name.xxx
from module_name import * 直接调用即可(导入优化)
from module_name import func_module_name as func
form . improt module_name 从当前目录下导入module_name
导入方法
>>>模块分类
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
自定义模块和开源模块的使用参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
2 包
包:用来从逻辑上组织模块,本质就是一个目录,(必须带有一个__init__.py文件),
那么在导入包之后改如何调用包下面的.py文件呢?

#Author:ZhangKanghui
print("我最美")
from . import foo
__init__.py
#Author:ZhangKanghui
def foo():
print("我喜欢你")
foo.py
#Author:ZhangKanghui
import package package.foo.foo()
调用(必须与包在同级目录下)
3 import的本质
import的本质(路径搜索和搜索路径):
>>>导入模块的本质就是把python文件解释一遍
>>>导入包的本质就是执行包下的__inint__.py文件
在导入的过程中,要确保存储路径在同级目录下。如果不在那怎么解决呢?
#Author:ZhangKanghui import package#直接运行 import sys
print(sys.path) #获取当前文件的存储位置 import os
print(os.path.abspath(__file__)) #获取当前文件的存储路径
print(os.path.dirname(os.path.abspath(__file__))) #添加路径:
sys.path.append() #追加到sys.path的最后,如果想放到前面怎么办
sys.path.insert() #os、sys模块下面有详解
访问目录
4 内置模块详解
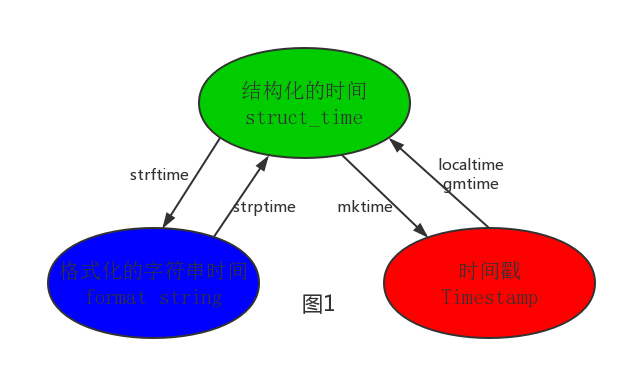
(1)time
首先,在python中有这么几种表示时间的方法:
(1)时间戳
(2)元组(struct_time)共有九个元素:年,月,日,小时,分钟,秒,一周的第几天,一年的第几天,时区
(3)格式化的时间字符串
>>> import time
>>> time.time()
1534000340.4254425 #这是从1970年开始计算至今的秒数。
#这是命令行操作
时间戳time.time()
>>> time.localtime()
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=11, tm_hour=23, tm_min=17, tm_sec=19, tm_wday=5, tm_yday=223, tm_isdst=0)
元组 localtime()
x =time.localtime()
>>> x
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=12, tm_hour=0, tm_min=0, tm_sec=43, tm_wday=6, tm_yday=224, tm_isdst=0)
>>> time.strftime("%Y-%m-%d %H:%m:%S",x)
'2018-08-12 00:08:43'
格式化的时间字符串time.strftime()
科普:
>>>UTC(Coordinated Universal Time,世界协调时)即格林威治天文时间,世界标准时间。在中国为UTC+8,
>>>DST(Daylight Saving Time)即夏令时
在补充一点格式:
>>>comomly used format code:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
commmonly used format code
a time.localtime() 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
b time.gmtime() 将一个时间戳转换为UTC时区(0时区)的struct_time。
>>> time.localtime()
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=15, tm_hour=10, tm_min=3, tm_sec=22, tm_wday=2, tm_yday=227, tm_isdst=0)
>>> time.gmtime()
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=15, tm_hour=2, tm_min=3, tm_sec=30, tm_wday=2, tm_yday=227, tm_isdst=0)
#这也验证了中国时区是UTC+8
二者有什么区别呢?
c time.mktime() 将一个struct_time转化为时间戳
>>> x =time.localtime()
>>> x
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=15, tm_hour=10, tm_min=7, tm_sec=30, tm_wday=2, tm_yday=227, tm_isdst=0)
>>> time.mktime(x)
1534298850.0
time.mktime()
d time.strftime(format[,t])
>>>import time
>>> x =time.localtime()
>>> x
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=15, tm_hour=10, tm_min=13, tm_sec=47, tm_wday=2, tm_yday=227, tm_isdst=0)
>>> time.strftime("%Y-%m-%d %H:%m:%S",x)
'2018-08-15 10:08:47'
time.strftime()
e time.strptime([格式化时间, format]) 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
>>>import time
>>>time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, tm_wday=3, tm_yday=125, tm_isdst=-1)
time.strptime([格式化时间,format])
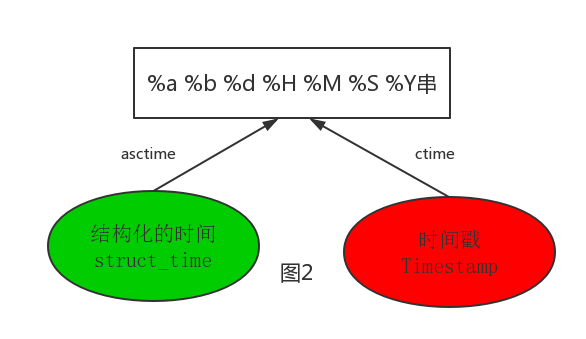
f asctime([t]) 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。如果没有参数,将会将time.localtime()作为参数传入。
g ctime([seconds]) 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。
>>> time.asctime()
'Sun Aug 12 23:27:28 2018'
>>> time.ctime()
'Sun Aug 12 23:52:40 2018'
#不要忘记导入time模块哟
一起来看看
接下来上图~
(2)datetime
a datetime.datetime.now()
>>> import datetime
>>> datetime.datetime.now()
datetime.datetime(2018, 8, 12, 23, 54, 0, 324086)
datetime.datetime.now()
b datetime.date.fromtimestamp(time.time()) 时间戳直接转成日期格式
>>> datetime.date.fromtimestamp(time.time())
datetime.date(2018, 8, 12)
时间戳
>>> datetime.datetime.now() + datetime.timedelta(3)
datetime.datetime(2018, 8, 15, 23, 55, 31, 676392)
当前时间+3天
>>> datetime.datetime.now() + datetime.timedelta(-3)
datetime.datetime(2018, 8, 9, 23, 55, 57, 20937)
当前时间-3天
>>> datetime.datetime.now() + datetime.timedelta(hours=3)
datetime.datetime(2018, 8, 13, 2, 56, 25, 388509)
当前时间+3小时
>>> datetime.datetime.now() + datetime.timedelta(minutes=30)
datetime.datetime(2018, 8, 13, 0, 26, 53, 300279)
当前时间+30分
(3)random
#random.random() 生成一个0-1的随机浮点数
>>> random.random()
0.6813665412962242
#那么能不能指定范围呢?
#random.uniform(a,b)
>>> random.uniform(2,5)
3.7103054399886606
#random.randint(a,b) 用于生成一个指定范围内的整数,包括a,b
>>> random.randint(1,3)
3
>>> random.randint(1,3)
3
>>> random.randint(1,3)
1
#random.randrange(start,stop,step) 从指定范围获得一个随机数,但不包括stop
>>> random.randrange(1,3)
2
>>> random.randrange(1,3)
1
#random.choice("序列") 从序列中获取一个随机元素
>>> random.choice('hello')
'e'
>>> random.choice('hello')
'o'
>>> random.choice('hello')
'o'
>>> random.choice('hello')
'o'
>>> random.choice('hello')
'e'
#random.sample("序列",k) 从序列中获取k个随机元素,必须指定k
>>> random.sample('hello',2)
['l', 'h']
>>> random.sample('hello',2)
['h', 'o']
>>> random.sample('hello',2)
['h', 'o']
random.shuffle() 洗牌
>>> l =[1,2,3,4,5,6]
>>> import random
>>> random.shuffle(l)
>>> l
[4, 6, 3, 2, 1, 5]
random模块
(2)os模块
os模块是与操作系统交互的一个接口
a os.getcwd() 获取当前工作目录
b os.chdir() 改变工作目录
os.getcwd()
'C:\\Users\\miraacle'
>>> os.chdir('C:\\Users')
>>> os.getcwd()
'C:\\Users'
>>> os.chdir(r"C:\Users\miraacle") #对比上一条chdir命令有什么区别/
>>> os.getcwd()
'C:\\Users\\miraacle'
如何操作
c os.curdir() 返回当前目录
d os.pardir() 返回当前目录的上一级目录
>>> os.curdir
'.'
>>> os.pardir
'..'
看操作
d os.makedirs(r"C:\a\b\c\d") 生成多层递归目录
e os.removesdirs(r"C:\a\b\c\d") 若目录为空,则删除,并递归到上一级目录,若也为空则删除,以此类推。
f os.mkdir() 生成单级目录
g os.rmdir() 删除单级目录
h os.listdir()
>>> os.listdir('.')
['.android', '.astropy', '.conda', '.ipython', '.matplotlib', '.oracle_jre_usage', '.Origin', '.PyCharm2017.1', '.QtWebEngineProcess','3D Objects', 'Anaconda3', 'AppData', 'Application Data', 'Contacts', 'Cookies', 'Desktop', 'Documents', 'Downloads', 'Evernote', 'Favorites', 'IntelGraphicsProfiles', 'Links', 'Local Settings', 'LocalStorage', 'MicrosoftEdgeBackups', 'Music', 'My Documents', 'NetHood', 'NTUSER.DAT', 'ntuser.dat.LOG1', 'ntuser.dat.LOG2', 'NTUSER.DAT{2fe3e105-6421-11e8-b183-74e6e23ee3d1}.TM.blf', 'NTUSER.DAT{2fe3e105-6421-11e8-b18374e6e23ee3d1}.TMContainer00000000000000000001.regtrans-ms', 'NTUSER.DAT{2fe3e105-6421-11e8-b183-74e6e23ee3d1}.TMContainer00000000000000000002.regtrans-ms', 'ntuser.ini', 'OneDrive', 'OneDrive.old', 'Pictures', 'PrintHood', 'PyCharm 2017.1.2', 'PycharmProjects','Recent', 'Saved Games', 'Searches', 'SendTo', 'Templates', 'Videos', 'WebpageIcons.db', '「开始」菜单', '微博图片', '新建文件夹']
一堆东西
>>> os.listdir('..')
['Administrator', 'All Users', 'Default', 'Default User', 'Default.migrated', 'desktop.ini', 'miraacle', 'Public']
这就清楚多了
i os.remove() 删除一个文件
j os.rename('oldname','newname')
k os.stat('path') 详细信息属性
>>> os.stat('微博图片')
os.stat_result(st_mode=16895, st_ino=5910974511128476, st_dev=43069414, st_nlink=1, st_uid=0, st_gid=0, st_size=0,
st_atime=1481191549, st_mtime=1481191549, st_ctime=1462148410)
详细属性
l os.sep 输出操作系统特定的路径分隔符
m os.linesep 输出当前平台使用的行终止符 dd
n os.pathsep 输出用于分割文件路径的字符串
o os.name 输出字符串当前使用的平台
>>> os.sep
'\\'
>>> os.linesep
'\r\n'
>>> os.pathsep
';'
>>> os.name
'nt'
操作集锦
p os.environ 获取系统环境变量
>>> os.environ
environ({'ACTEL_FOR_ALTIUM_OVERRIDE': ' ', 'ALLUSERSPROFILE': 'C:\\ProgramData', 'ALTERA_FOR_ALTIUM_OVERRIDE': ' ', 'ALTIUMPATH': 'C:\\Program Files (x86)\\Altium2004 SP2\\System', 'APPDATA': 'C:\\Users\\miraacle\\AppData\\Roaming',
'CM2015DIR': 'C:\\Program Files (x86)\\Common Files\\Autodesk Shared\\Materials\\', 'COMMONPROGRAMFILES':
'C:\\Program Files (x86)\\Common Files', 'COMMONPROGRAMFILES(X86)': 'C:\\Program Files (x86)\\Common Files',
'COMMONPROGRAMW6432': 'C:\\Program Files\\Common Files', 'COMPUTERNAME': 'MIRACLE', 'COMSPEC': 'C:\\WINDOWS\\system32\\cmd.exe',
'DRIVERDATA': 'C:\\Windows\\System32\\Drivers\\DriverData', 'FPS_BROWSER_APP_PROFILE_STRING': 'Internet Explorer',
'FPS_BROWSER_USER_PROFILE_STRING': 'Default', 'HOMEDRIVE': 'C:', 'HOMEPATH': '\\Users\\miraacle', 'LOCALAPPDATA':
'C:\\Users\\miraacle\\AppData\\Local', 'LOGONSERVER': '\\\\MIRACLE', 'NUMBER_OF_PROCESSORS': '', 'ONEDRIVE':
'C:\\Users\\miraacle\\OneDrive', 'OS': 'Windows_NT', 'PATH': 'C:\\WINDOWS\\system32;C:\\WINDOWS;C:\\WINDOWS\\System32\\Wbem;C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\;C:\\Program Files\\WIDCOMM\\Bluetooth Software\\;C:\\Program Files\\WIDCOMM\\BluetoothSoftware\\syswow64;;C:\\WINDOWS\\System32\\OpenSSH\\;C:\\Program Files (x86)\\Altium2004 SP2\\System;C:\\Users\\miraacle\\AppData\\Local\\Programs\\Python\\Python36-32\\Scripts\\;
C:\\Users\\miraacle\\AppData\\Local\\Programs\\Python\\Python36-32\\;C:\\Users\\miraacle\\Anaconda3;
C:\\Users\\miraacle\\Anaconda3\\Scripts;C:\\Users\\miraacle\\Anaconda3\\Library\\bin;
C:\\Users\\miraacle\\AppData\\Local\\Microsoft\\WindowsApps;', 'PATHEXT': '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC',
'PROCESSOR_ARCHITECTURE': 'x86', 'PROCESSOR_ARCHITEW6432': 'AMD64', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 61 Stepping 4,
GenuineIntel', 'PROCESSOR_LEVEL': '6', 'PROCESSOR_REVISION': '3d04', 'PROGRAMDATA': 'C:\\ProgramData', 'PROGRAMFILES':
'C:\\Program Files (x86)', 'PROGRAMFILES(X86)': 'C:\\Program Files (x86)', 'PROGRAMW6432': 'C:\\Program Files', 'PROMPT':
'$P$G', 'PSMODULEPATH': 'C:\\Program Files\\WindowsPowerShell\\Modules;C:\\WINDOWS\\system32\\WindowsPowerShell\\v1.0\\Modules',
'PUBLIC': 'C:\\Users\\Public', 'SESSIONNAME': 'Console', 'SYNAPROGDIR': 'Synaptics\\SynTP', 'SYSTEMDRIVE': 'C:', 'SYSTEMROOT':
'C:\\WINDOWS', 'TEMP': 'C:\\Users\\miraacle\\AppData\\Local\\Temp', 'TMP': 'C:\\Users\\miraacle\\AppData\\Local\\Temp',
'USERDOMAIN': 'MIRACLE', 'USERDOMAIN_ROAMINGPROFILE': 'MIRACLE', 'USERNAME': 'miraacle', 'USERPROFILE': 'C:\\Users\\miraacle',
'WINDIR': 'C:\\WINDOWS'})
可怕的环境变量
q os.system()
>>> os.system('dir')
驱动器 C 中的卷是 我的磁盘
卷的序列号是 0291-2FE6
C:\Users\miraacle 的目录
2018/08/10 00:17 <DIR> .
2018/08/10 00:17 <DIR> ..
2015/05/10 21:32 <DIR> .android
2018/07/04 22:40 <DIR> .astropy
2018/07/23 01:27 <DIR> .conda
2018/07/04 22:38 <DIR> .ipython
2018/07/04 22:51 <DIR> .matplotlib
2016/11/23 22:45 <DIR> .oracle_jre_usage
2017/01/17 22:43 <DIR> .Origin
2018/06/17 00:53 <DIR> .PyCharm2017.1
2017/01/17 22:43 <DIR> .QtWebEngineProcess
2018/07/18 17:47 <DIR> 3D Objects
2018/08/13 10:23 <DIR> Anaconda3
2018/07/18 17:47 <DIR> Contacts
2018/08/13 14:04 <DIR> Desktop
2018/07/18 17:47 <DIR> Documents
2018/08/12 23:49 <DIR> Downloads
2016/10/21 18:36 <DIR> Evernote
2018/07/18 17:47 <DIR> Favorites
2018/07/18 17:47 <DIR> Links
2017/01/15 16:13 <DIR> LocalStorage
2018/07/18 17:47 <DIR> Music
2018/04/05 01:08 <DIR> OneDrive
2015/05/21 18:28 <DIR> OneDrive.old
2018/07/18 17:47 <DIR> Pictures
2018/06/17 00:50 <DIR> PyCharm 2017.1.2
2018/07/04 23:11 <DIR> PycharmProjects
2018/07/18 17:47 <DIR> Saved Games
2018/07/18 17:47 <DIR> Searches
2018/07/18 17:47 <DIR> Videos
2017/06/14 00:26 22,528 WebpageIcons.db
2016/12/08 18:05 <DIR> 微博图片
2017/05/04 09:33 <DIR> 新建文件夹
1 个文件 22,528 字节
32 个目录 43,556,442,112 可用字节
0
看看系统
>>> os.system('ipconfig/all')
Windows IP 配置
主机名 . . . . . . . . . . . . . : miracle
主 DNS 后缀 . . . . . . . . . . . :
节点类型 . . . . . . . . . . . . : 混合
IP 路由已启用 . . . . . . . . . . : 否
WINS 代理已启用 . . . . . . . . . : 否
以太网适配器 以太网:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Realtek PCIe FE Family Controller
物理地址. . . . . . . . . . . . . : 74-E6-E2-3E-E3-D1
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
无线局域网适配器 本地连接* 2:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Microsoft Wi-Fi Direct Virtual Adapter
物理地址. . . . . . . . . . . . . : 2E-33-7A-FC-F0-B5
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
无线局域网适配器 本地连接* 4:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Microsoft Wi-Fi Direct Virtual Adapter #
物理地址. . . . . . . . . . . . . : 2E-33-7A-FC-F8-B5
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
无线局域网适配器 WLAN:
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Dell Wireless 1704 802.11b/g/n (2.4GHz)
物理地址. . . . . . . . . . . . . : 2C-33-7A-FC-F0-B5
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
IPv6 地址 . . . . . . . . . . . . : 2001:250:20a:1900:1c19:8fdc:c570:89f6(首选)
临时 IPv6 地址. . . . . . . . . . : 2001:250:20a:1900:5d56:4217:aa5a:e812(首选)
本地链接 IPv6 地址. . . . . . . . : fe80::1c19:8fdc:c570:89f6%3(首选)
IPv4 地址 . . . . . . . . . . . . : 10.20.72.135(首选)
子网掩码 . . . . . . . . . . . . : 255.255.224.0
获得租约的时间 . . . . . . . . . : 2018年8月13日 9:30:01
租约过期的时间 . . . . . . . . . : 2018年8月13日 14:58:54
默认网关. . . . . . . . . . . . . : fe80::276:86ff:febe:7a41%3
10.20.95.254
DHCP 服务器 . . . . . . . . . . . : 10.100.100.100
DHCPv6 IAID . . . . . . . . . . . : 36451194
DHCPv6 客户端 DUID . . . . . . . : 00-01-00-01-1E-59-AF-DE-74-E6-E2-3E-E3-D1
DNS 服务器 . . . . . . . . . . . : 202.112.209.122
202.112.209.123
TCPIP 上的 NetBIOS . . . . . . . : 已启用
0
看看ip配置
r os.path.xxx
os.path.abspath() 获取某一文件的绝对路径
os.path.split(path) 分割路径
os.path.diranme(path) 返回path的目录,其实就是os.path.split()的第一个元素
os.path.basename(path) 返回path的最后一个文件名
os.path.exists(path) 判断路径是否存在
os.path.isabs(path) 判断是否为绝对路径
os.path.isfile(path) 判断是否为文件
os.path.isdir(path) 判断是否为目录
os.path.join() 将说个路径组合返回
os.path.getatime(path) 返回path所指向的文件或目录的最后存储时间
so.path.getmtime(path) 返回path所指向的文件或目录的最后修改时间
关于os.path.xxx
终于完了~
(5)sys模块
a sys.version 获取python解释器的版本信息
b sys.platform 获取操作系统平台名称
c sys.argv 命令行参数list,第一个元素是程序本身路径
d sys.path 返回模块的搜索路径,初始化时使用python环境变量的值
e sys.exit(n) 退出程序,正常退出时exit(0)
>>> sys.version
'3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 16:07:46) [MSC v.1900 32 bit (Intel)]'
>>> sys.platform
'win32'
>>>C:\Users\miraacle\PycharmProjects\s\day5>module_sys.py 1 2 3 4 5
['C:\\Users\\miraacle\\PycharmProjects\\s\\day5\\module_sys.py', '', '', '', '', '']
sys模块操作
(6)json&pickle模块
json把字符串、列表、字典等各语言通用的数据类型写进文件里。便于各平台和语言之前进行数据交互。
pickle,用于python特有的类型和python的数据类型间进行转换。
#Author:ZhangKanghui
import json info ={
'name':'Kanghui',
'age':23
}
#强行转成字符串,不推荐使用。因为反序列化不好办。
'''
f =open('文本.txt','w')
#f.write(info) #TypeError: write() argument must be str, not dict
f.write(str(info))
f.close()
'''
#推荐使用json.dumps或者dump
f =open('文本.txt','w')
f.write( json.dumps(info) ) #等价于json.dump(info,f)
f.close()
json序列化
#Author:ZhangKanghui import json
#json只能处理简单的数据类型,例如字典,列表字符串。json在所有语言之间都一样。因为不同语言进行数据交互,能够使用不同语言。
#xml用于在不同语言之间进行数据交互,在不断地被json取代,主流的在不同平台和语言之间数据交互。因为跨语言,所以不能处理复杂的 f =open('文本.txt','r')
#f.write(info) TypeError: write() argument must be str, not dict
# data =f.read()
# f.close()
# print(data)
#print(data["age"]) 此时TypeError: string indices must be integers因为是字符串,现在需要变回字典
#那怎么办呢?
'''
data =eval( f.read() )
f.close()
print(data["age"])
'''
#不用eval呢?eval不是一个通用的
data =json.loads(f.read())
print(data["age"])
json反序列化
#Author:ZhangKanghui
import pickle
date ={"k1":123,"k2":'hello'}
#pickle.dumps 将数据通过特殊形式转换为只有python语言认识的字符串
p_str =pickle.dumps(data)
print(p_str) #pickle.dump 将数据通过特殊形式转换为只有python语言认识的字符串,并写入文件
with open('pickle序列化文本.txt','w') as f:
pickle.dump(date,f)
pickle序列化
#Author:ZhangKanghui
#pickle和json的用法几乎完全一样
import pickle def sayhi(name):
print("hello",name)
info ={
'name':'Kanghui',
'age':23,
'func':sayhi
}
f =open('文本.txt','wb')
f.write( pickle.dump(info) )
f.close()
可以dump不一样可以load
pickle的用于与json完全一样。
(7)shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。
#Author:ZhangKanghui import shelve
import datetime
d =shelve.open("text.txt",'w') #打开一个文件
'''
info ={"age":23,"job":'std'}
name =["a","b"]
d['name']=name #持久化列表
d['info']=info #持久化字典
d["date"]=datetime.datetime.now()
d.close()
'''
print(d.get("name"))
print(d.get("info"))
print(d.get("date"))
shelve模块
运行的结果会生成三个文件:text.txt.bak、text.txt.dir,text.txt.dat。貌似很好用的样子~
(8)xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml格式
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
遍历xml文档
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
只遍历节点
还可以修改和删除xml文档:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
xml修改和删除
还可以自行创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = ''
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = ''
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
xml文档创建
(9)shutil模块
高级的 文件、文件夹、压缩包 处理模块。
#Author:ZhangKanghui
#将一个文件拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old xml','r'),open('new xml','w')) #拷贝文件和权限
shutil.copy('f1.log','f2.log') #目标文件无需存在 #shutil.copy2(src, dst)拷贝文件和状态信息
shutil.copy2('f1.log', 'f2.log') #仅拷贝权限。内容、组、用户均不变。
shutil.copymode('f1.log','f2.log') #目标文件必须存在 #仅拷贝文件的状态信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在 #shutil.ignore_patterns(*patterns)
#shutil.copytree(src, dst, symlinks=False, ignore=None)
#递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2',ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
# 目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除 #shutil.rmtree(path[, ignore_errors[, onerror]])递归的去删除文件
shutil.rmtree('folder1') #shutil.move(src, dst)递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('folder1', 'folder3')
shutil乱七八糟的操作
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile # 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close() # 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
zipfile压缩&解压
import tarfile # 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close() # 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()
tarfile压缩&解压
(10)PyYaml模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,
参考文档 http://pyyaml.org/wiki/PyYAMLDocumentation
(11)cofigpaser模块
用于生成和修改常见配置文档
来看一个好多软件的常见文档格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
我是没见过
如果想用python生成一个这样的文档怎么做呢?
import configparser config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '',
'Compression': 'yes',
'CompressionLevel': ''} config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
python写配置文档
写完了还能再读:
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
''
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
python读取配置文档
[section1]
k1 = v1
k2:v2 [section2]
k1 = v1 import ConfigParser config = ConfigParser.ConfigParser()
config.read('i.cfg') # ########## 读 ##########
#secs = config.sections()
#print secs
#options = config.options('group2')
#print options #item_list = config.items('group2')
#print item_list #val = config.get('group1','key')
#val = config.getint('group1','key') # ########## 改写 ##########
#sec = config.remove_section('group1')
#config.write(open('i.cfg', "w")) #sec = config.has_section('wupeiqi')
#sec = config.add_section('wupeiqi')
#config.write(open('i.cfg', "w")) #config.set('group2','k1',11111)
#config.write(open('i.cfg', "w")) #config.remove_option('group2','age')
#config.write(open('i.cfg', "w"))
增删改查
(12)hashlib模块
用于加密相关的操作,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass '''
import hashlib # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
hashlib模块,试试吧
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
import hmac
h = hmac.new(b'天王盖地虎', b'宝塔镇河妖')
print h.hexdigest()
hmac加密
更多关于md5,sha1,sha256等介绍的文章看这里
https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
(13)re模块
常用正则表达式符号:五种匹配语法、三种匹配模式
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
常用的正则表达式1
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
常用的正则表达式2
'(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city") 结果{'province': '', 'city': '', 'birthday': ''}
分组匹配身份证号
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
匹配语法
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
匹配模式
下面来看看实例操作:(命令行操作)
>>> re.match("^Kanghui","Kanghui123")
<_sre.SRE_Match object; span=(0, 7), match='Kanghui'>
#这是匹配到的情况,如果匹配不到呢?是没有反应的。就是none
>>> re.match("^aKanghui","Kanghui123")
>>> re.match("^aKanghui","Kanghui123")
#查看匹配内容
>>> res =re.match("^Kanghui","Kanghui123")
>>> res.group()
'Kanghui'
#现在这样还没用到正则,那么接下来~我要把后面的数字也匹配进来
>>> res =re.match("^Kang\d","Kang123hui123")
>>> res.group()
'Kang1'
#现在只有一个数字,多个数字就再加一个+
>>> res =re.match("^Kang\d+","Kang123hui123")
>>> res.group()
'Kang123'
#接下来开始正式使用正则表示式符号
>>> re.match("^.\d+","Kang123hui123")
>>> re.match("^.\d+","Kang123hui123")
#这样为什么没有反应呢?原因是因为 ^匹配字符开头, .默认匹配除\n之外的任意一个字符 一个字符之后就是数字所以不行
>>> re.match("^.+\d+","Kang123hui123")
<_sre.SRE_Match object; span=(0, 13), match='Kang123hui123'>
>>> re.match("^.+","Kang123hui123")
<_sre.SRE_Match object; span=(0, 13), match='Kang123hui123'>
>>> re.match(".+","Kang123hui123")
<_sre.SRE_Match object; span=(0, 13), match='Kang123hui123'>
>>> re.match(".","Kang123hui123")
<_sre.SRE_Match object; span=(0, 1), match='K'>
>>> re.match("^K.+","Kang123hui123")
<_sre.SRE_Match object; span=(0, 13), match='Kang123hui123'>
#如果我只想要数字中间的部分呢?
>>> re.search("^h.+i","Kang123hui321") #^匹配字符开头
>>> re.search("h.+i","Kang123hui321")
<_sre.SRE_Match object; span=(7, 10), match='hui'>
re模块引入
>>> re.search("^h.+i","Kang123hui321")
>>> re.search("h.+i","Kang123hui321")
<_sre.SRE_Match object; span=(7, 10), match='hui'>
>>> re.search("$","Kang123hui321a")
<_sre.SRE_Match object; span=(14, 14), match=''>
>>> re.search("a$","Kang123hui321a")
<_sre.SRE_Match object; span=(13, 14), match='a'>
>>> re.search(".+a$","Kang123hui321a")
<_sre.SRE_Match object; span=(0, 14), match='Kang123hui321a'>
>>> re.search(".+a","Kang123hui321a")
<_sre.SRE_Match object; span=(0, 14), match='Kang123hui321a'>
这样看起来$貌似没有什么用,因为.+是匹配任意字符。
>>> re.search("h[a-z]+","Kang123hui321a")
<_sre.SRE_Match object; span=(7, 10), match='hui'>
>>> re.search("h[a-z]+i","Kang123hui321i")
<_sre.SRE_Match object; span=(7, 10), match='hui'>
>>> re.search("h[a-z]+i$","Kang123hui321i")
>>> re.search("h[a-zA-Z]+i","Kang123huiKAnghui321i")
<_sre.SRE_Match object; span=(7, 17), match='huiKAnghui'>
>>> re.search("#.+#","123#hello#")
<_sre.SRE_Match object; span=(3, 10), match='#hello#'>
>>> re.search("aaa?","alexaaa")
<_sre.SRE_Match object; span=(4, 7), match='aaa'>
>>> re.search("aaa?","aalexaaa")
<_sre.SRE_Match object; span=(0, 2), match='aa'>
>>> re.search("aal?","aalexaaa")
<_sre.SRE_Match object; span=(0, 3), match='aal'>
>>> re.search("aal?","aaexaaa")
<_sre.SRE_Match object; span=(0, 2), match='aa'>
>>> re.search("[0-9]{3}","a8l26e456x")
<_sre.SRE_Match object; span=(6, 9), match=''>
>>> re.search("[0-9]{1,3}","a8l26e456x")
<_sre.SRE_Match object; span=(1, 2), match=''>
#如果想要匹配所有的数字呢?用findall试试:
re.search
>>> re.search("[0-9]{1,3}","a8l26e456x")
<_sre.SRE_Match object; span=(1, 2), match=''>
>>> re.findall("[0-9]{1,2}","a8l26e456x")
['', '', '', '']
>>> re.findall("[0-9]{1,3}","a8l26e456x")
['', '', '']
>>> re.search("abc|ABC","ABCabcCDE")
<_sre.SRE_Match object; span=(0, 3), match='ABC'>
>>> re.search("abc|ABC","ABCabcCDE").group()
'ABC'
>>> re.findall("abc|ABC","ABCabcCDE").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'group'
>>> re.findall("abc|ABC","ABCabcCDE")
['ABC', 'abc']
>>> re.search("(abc){2}","subjectabccccabc")
>>> re.search("(abc){2}","subjectabccccabcabc")
<_sre.SRE_Match object; span=(13, 19), match='abcabc'>
>>> re.search("(abc){2}\|","subjectabccccabcabc|")
<_sre.SRE_Match object; span=(13, 20), match='abcabc|'>
>>> re.search("(abc){2}\|\|=","subjectabccccabcabc||=||=")
<_sre.SRE_Match object; span=(13, 22), match='abcabc||='>
>>> re.search("\D+","123#abc")
<_sre.SRE_Match object; span=(3, 7), match='#abc'>
>>> re.search("\s+","123#abc \r\n ")
<_sre.SRE_Match object; span=(7, 11), match=' \r\n\t'>
re.findall
>>> re.split("[0-9]","abc12de3f45g6HGD")
['abc', '', 'de', 'f', '', 'g', 'HGD']
>>> re.split("[0-9]+","abc12de3f45g6HGD")
['abc', 'de', 'f', 'g', 'HGD']
re.split
>>> re.sub("[0-9]+","|","abc12de3f45g6HGD")
'abc|de|f|g|HGD'
>>> re.sub("[0-9]+","|","abc12de3f45g6HGD",count=2)
'abc|de|f45g6HGD'
re.sub
最后来个使用性的例子:身份证号码的每个数字都代表着什么你知道吗?
科普:
身份证号码编排规则(18位身份证号码)
公民身份证号码是特征组合码,由17位数字本体码和1位校验码组成。前1、2位数字表示:所在省份的代码;第3、4位数字表示:所在城市的代码;第5、 6位数字表示:所在区县的代码;第7~14位数字表示:出生年、月、日;第15、16位数字表示:所在地的派出所的代码;第17位数字表示性别:奇数表示男性,偶数表示女性;第18位数字是校检码:用来检验身份证号码的正确性,校检码由0~9的数字、及X表示。
>>> re.search("(?P<province>[0-9]{2})(?P<city>[0-9]{2})(?P<county>[0-9]{2})(?P<birthday>[0-9]{4})","").groupdict("city")
{'province': '', 'city': '', 'county': '', 'birthday': ''}
通过正则取出身份信息
5 练习(开发一个简单的python计算器)
需求:
1实现加减乘除和括号优先级的解析
2用户输入1-2*((60-30)+(40/5)*)等类的公式后,必须自己解析里面的运算符号,运算后得出结果,结果必须与真实计算器一致。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
该计算器思路:
1、递归寻找表达式中只含有 数字和运算符的表达式,并计算结果
2、由于整数计算会忽略小数,所有的数字都认为是浮点型操作,以此来保留小数
使用技术:
1、正则表达式
2、递归 执行流程如下:
******************** 请计算表达式: 1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) ********************
before: ['1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
-40.0/5=-8.0
after: ['1-2*((60-30+-8.0*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
========== 上一次计算结束 ==========
before: ['1-2*((60-30+-8.0*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
9-2*5/3+7/3*99/4*2998+10*568/14=173545.880953
after: ['1-2*((60-30+-8.0*173545.880953)-(-4*3)/(16-3*2))']
========== 上一次计算结束 ==========
before: ['1-2*((60-30+-8.0*173545.880953)-(-4*3)/(16-3*2))']
60-30+-8.0*173545.880953=-1388337.04762
after: ['1-2*(-1388337.04762-(-4*3)/(16-3*2))']
========== 上一次计算结束 ==========
before: ['1-2*(-1388337.04762-(-4*3)/(16-3*2))']
-4*3=-12.0
after: ['1-2*(-1388337.04762--12.0/(16-3*2))']
========== 上一次计算结束 ==========
before: ['1-2*(-1388337.04762--12.0/(16-3*2))']
16-3*2=10.0
after: ['1-2*(-1388337.04762--12.0/10.0)']
========== 上一次计算结束 ==========
before: ['1-2*(-1388337.04762--12.0/10.0)']
-1388337.04762--12.0/10.0=-1388335.84762
after: ['1-2*-1388335.84762']
========== 上一次计算结束 ==========
我的计算结果: 2776672.69524
""" import re def compute_mul_div(arg):
""" 操作乘除
:param expression:表达式
:return:计算结果
""" val = arg[0]
mch = re.search('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val)
if not mch:
return
content = re.search('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val).group() if len(content.split('*'))>1:
n1, n2 = content.split('*')
value = float(n1) * float(n2)
else:
n1, n2 = content.split('/')
value = float(n1) / float(n2) before, after = re.split('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', val, 1)
new_str = "%s%s%s" % (before,value,after)
arg[0] = new_str
compute_mul_div(arg) def compute_add_sub(arg):
""" 操作加减
:param expression:表达式
:return:计算结果
"""
while True:
if arg[0].__contains__('+-') or arg[0].__contains__("++") or arg[0].__contains__('-+') or arg[0].__contains__("--"):
arg[0] = arg[0].replace('+-','-')
arg[0] = arg[0].replace('++','+')
arg[0] = arg[0].replace('-+','-')
arg[0] = arg[0].replace('--','+')
else:
break if arg[0].startswith('-'):
arg[1] += 1
arg[0] = arg[0].replace('-','&')
arg[0] = arg[0].replace('+','-')
arg[0] = arg[0].replace('&','+')
arg[0] = arg[0][1:]
val = arg[0]
mch = re.search('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val)
if not mch:
return
content = re.search('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val).group()
if len(content.split('+'))>1:
n1, n2 = content.split('+')
value = float(n1) + float(n2)
else:
n1, n2 = content.split('-')
value = float(n1) - float(n2) before, after = re.split('\d+\.*\d*[\+\-]{1}\d+\.*\d*', val, 1)
new_str = "%s%s%s" % (before,value,after)
arg[0] = new_str
compute_add_sub(arg) def compute(expression):
""" 操作加减乘除
:param expression:表达式
:return:计算结果
"""
inp = [expression,0] # 处理表达式中的乘除
compute_mul_div(inp) # 处理
compute_add_sub(inp)
if divmod(inp[1],2)[1] == 1:
result = float(inp[0])
result = result * -1
else:
result = float(inp[0])
return result def exec_bracket(expression):
""" 递归处理括号,并计算
:param expression: 表达式
:return:最终计算结果
"""
# 如果表达式中已经没有括号,则直接调用负责计算的函数,将表达式结果返回,如:2*1-82+444
if not re.search('\(([\+\-\*\/]*\d+\.*\d*){2,}\)', expression):
final = compute(expression)
return final
# 获取 第一个 只含有 数字/小数 和 操作符 的括号
# 如:
# ['1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
# 找出:(-40.0/5)
content = re.search('\(([\+\-\*\/]*\d+\.*\d*){2,}\)', expression).group() # 分割表达式,即:
# 将['1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
# 分割更三部分:['1-2*((60-30+( (-40.0/5) *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
before, nothing, after = re.split('\(([\+\-\*\/]*\d+\.*\d*){2,}\)', expression, 1) print 'before:',expression
content = content[1:len(content)-1] # 计算,提取的表示 (-40.0/5),并活的结果,即:-40.0/5=-8.0
ret = compute(content) print '%s=%s' %( content, ret) # 将执行结果拼接,['1-2*((60-30+( -8.0 *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))']
expression = "%s%s%s" %(before, ret, after)
print 'after:',expression
print "="*10,'上一次计算结束',"="*10 # 循环继续下次括号处理操作,本次携带者的是已被处理后的表达式,即:
# ['1-2*((60-30+ -8.0 *(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))'] # 如此周而复始的操作,直到表达式中不再含有括号
return exec_bracket(expression) # 使用 __name__ 的目的:
# 只有执行 python index.py 时,以下代码才执行
# 如果其他人导入该模块,以下代码不执行
if __name__ == "__main__":
#print '*'*20,"请计算表达式:", "1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )" ,'*'*20
#inpp = '1 - 2 * ( (60-30 +(-40.0/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) '
inpp = "1-2*-30/-12*(-20+200*-3/-200*-300-100)"
#inpp = "1-5*980.0"
inpp = re.sub('\s*','',inpp)
# 表达式保存在列表中
result = exec_bracket(inpp)
print result
代码示例
6 小结
做一名程序猿是真的不容易。
最近才觉得好多东西要学啊,亚历山大~~!!!自己就像一张白纸,慢慢填~
坚持~
为什么明明才二十几岁,就感觉一辈子好像就这样了呢?
别忘了看书。
我是尾巴~
这次推荐一个远程控制电脑的黑科技:
https://mp.weixin.qq.com/s/SE5QGzwJhA1lKbVuhS9_bg
虽不才,才要坚持~
D05——C语言基础学PYTHON的更多相关文章
- D10——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D10 20180906内容纲要: 1.协程 (1)yield (2)greenlet (3)gevent (4)gevent实现单线程下socket多并发 2. ...
- D16——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D16 20180927内容纲要: 1.JavaScript介绍 2.JavaScript功能介绍 3.JavaScript变量 4.Dom操作 a.获取标签 b ...
- D15——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D15 20180926内容纲要: 1.CSS介绍 2.CSS的四种引入方式 3.CSS选择器 4.CSS常用属性 5.小结 6.练习 1 CSS介绍 层叠样式表 ...
- D07——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D07 20180826内容纲要: 面向对象进阶学习 1 静态方法 2 类方法 3 属性方法 4 类的特殊成员方法(本节重点) 5 反射(本节重点) 6 异常(本 ...
- D06——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D06 20180821内容纲要: 面向对象初级学习 1 面向对象 2 类 (1)封装 (2)继承 (3)多态 3 小结 4 练习:选课系统 5 课外拓展:答题系 ...
- D17——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D17 20181014内容纲要: 1.jQuery介绍 2.jQuery功能介绍 (1)jQuery的引入方式 (2)选择器 (3)筛选 (4)文本操作 (5) ...
- D14——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D14 20180919内容纲要: 1.html认识 2.常用标签 3.京东html 4.小结 5.练习(简易淘宝html) 1.html初识(HyperText ...
- D13——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D13 20180918内容纲要: 堡垒机运维开发 1.堡垒机的介绍 2.堡垒机的架构 3.小结 4.堡垒机的功能实现需求 1 堡垒机的介绍 百度百科 随着信息安 ...
- D12——C语言基础学PYTHON
C语言基础学习PYTHON——基础学习D12 20180912内容纲要: 1.数据库介绍 2.RDMS术语 3.MySQL数据库介绍和基本使用 4.MySQL数据类型 5.MySQL常用命令 6.外键 ...
随机推荐
- 设计模式之java源码-工厂方法模式
工厂方法模式 8.1 女娲造人的故事 东汉<风俗通>记录了一则神话故事:“开天辟辟,未有人民,女娲搏,黄土作人……”,讲述的内容就是大家非常熟悉的女娲造人的故事.开天辟地之初,大地上并没有 ...
- async 和 await
win8 app开发中使用async,await可以更方便地进行异步开发. async,await的使用可参考代码:Async Sample: Example from "Asynchron ...
- Jfinal框架是什么框架?适用于什么项目呢?
Jfinal框架是什么框架?适用于什么项目呢? jfinal 基于spring MVC研发的框架,操作简单.节省代码,适用于所有web项目.适合中小型项目开发.10分钟写出一个页面的增删改查.目前所在 ...
- SimpleAdapter 网络视图:带预览的图片浏览器
MainActivity.java public class MainActivity extends Activity { GridView grid; ImageView imageView; i ...
- Spring3.x错误----Bean named "txAdvice" must be of type[org.aopallibance.aop.Advice
Spring3.x错误: 解决方法: aopalliance-1.0.jar 和 aopalliance-alpha1.jar之间的冲突.
- 16)maven lifecycle
http://maven.apache.org/guides/introduction/introduction-to-the-lifecycle.html http://maven.apache.o ...
- spring mvc与mybatis整合错误提示
java.lang.AbstractMethodError: org.mybatis.spring.transaction.SpringManagedTransaction.getTimeout()L ...
- ACM STEPS——Chapter Two——Section One
数学题小关,做得很悲剧,有几道题要查数学书... 记下几道有价值的题吧 The area(hdoj 1071) http://acm.hdu.edu.cn/showproblem.php?pid=10 ...
- java.util.Date与java.sql.Date的关系和转换方法(转)
在ResultSet中我们经常使用的setDate或getDate的数据类型是java.sql.Date,而在平时java程序中我们一般习惯使用 java.util.Date. 因此在DAO层我们经常 ...
- Android-控制整个APP的异常收集与处理
控制整个App的异常收集与处理,使用前记得要在Application中初始化initCrasHandler CrasHandler APP异常收集类: package common.library.e ...