预防Redis缓存穿透、缓存雪崩解决方案
最近面试中遇到redis缓存穿透、缓存雪崩等问题,特意了解下。
redis缓存穿透:
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
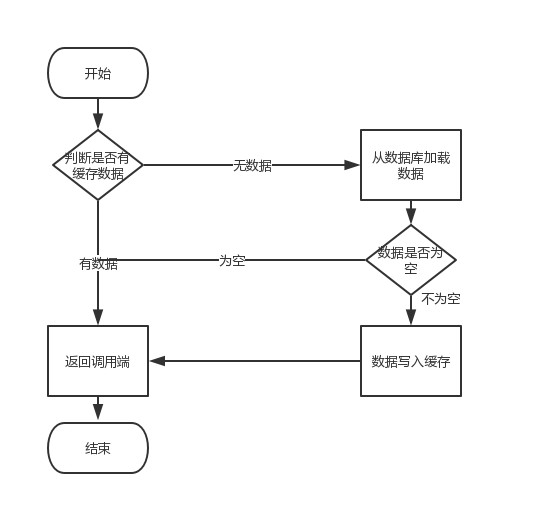
解决的办法:
1. 如果查询数据库也为空,直接设置一个默认值存放到缓存,后续不会继续访问数据库,同时设置过期时间保证高并发情况下保障不被穿透,后续也能及时更新。
2. 假如key是有一定规则的,可key来过滤一部分无效查询。
3. 采用布隆过滤器(Bloom Filter),将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力。
redis缓存雪崩:
大并发的缓存穿透,导致所有请求都跑去了数据库,引起数据库IO、内存和CPU压力过大,甚至导致宕机,使得整个系统崩溃,这就是缓存雪崩(缓存失效)。
解决的办法:
1. 减少缓存穿透的影响。
2. 使用主备机制,redis双缓存涉及到更新事务的问题,需解决update可能读到脏数据。
redis热点key:
热点key:某个key访问非常频繁,当key失效的时候有大量线程来构建缓存,导致负载增加,系统崩溃。
解决办法:
1. 使用锁,单机用synchronized,lock等,分布式用分布式锁。(性能低)
2. 缓存过期时间不设置,在key对应的value里设置过期时间。如果检测到存的时间超过过期时间则异步更新缓存。
3. 在value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作。
推荐使用后俩种模式,虽然需要一定的硬编码,但不影响性能。
预防Redis缓存穿透、缓存雪崩解决方案的更多相关文章
- Redis中几个简单的概念:缓存穿透/击穿/雪崩,别再被吓唬了
Redis中几个“看似”高大上的概念,经常有人提到,某些好事者喜欢死扣概念,实战没多少,嘴巴里冒出来的全是高大上的名词,个人一向鄙视概念党,呵呵! 其实这几个概念:缓存穿透/缓存击穿/缓存雪崩,有一个 ...
- Java Redis缓存穿透/缓存雪崩/缓存击穿,Redis分布式锁实现秒杀,限购等
package com.example.redisdistlock.controller; import com.example.redisdistlock.util.RedisUtil; impor ...
- Redis 17 缓存穿透 缓存击穿 缓存雪崩
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 使用缓存的问题 ...
- redis缓存穿透,缓存击穿,缓存雪崩
缓存穿透 缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有.这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询).这样请求就会绕过 ...
- 缓存穿透 & 缓存击穿 & 缓存雪崩
参考文档: 缓存穿透和缓存失效的预防和解决:https://blog.csdn.net/qq_16681169/article/details/75138876 缓存穿透 缓存穿透是指查询一个一定不存 ...
- redis的缓存穿透 缓存并发 缓存失效
我们在用缓存的时候,不管是Redis或者Memcached,基本上会通用遇到以下三个问题: 缓存穿透 缓存并发 缓存失效 一.缓存穿透 Paste_Image.png Paste_Image.png ...
- 缓存穿透、雪崩、热点与Redis
(拼多多问:Redis雪崩解决办法) 导读:互联网系统中不可避免要大量用到缓存,在缓存的使用过程中,架构师需要注意哪些问题?本文以 Redis 为例,详细探讨了最关键的 3 个问题. 一.缓存穿透预防 ...
- 什么是redis缓存穿透, 缓存雪崩, 缓存击穿
什么是redis? redis是一个非关系型数据库,相对于其他数据库而言,它的查询速度极快,且能承受的瞬时并发量非常的高.所以常常被用来存放网站的缓存,以减少主要数据库(如mysql)的服务器压力. ...
- Redis系列(八)--缓存穿透、雪崩、更新策略
1.缓存更新策略 1.LRU/LFU/FIFO算法剔除:例如maxmemory-policy 2.超时剔除,过期时间expire,对于一些用户可以容忍延时更新的数据,例如文章简介内容改了几个字 3.主 ...
- Redis缓存穿透和雪崩
缓存穿透 用户想要查询一个数据 在redis缓存数据库中没有获取到 就会向后端的数据库中查询. 当用户很多 都去访问后端数据库的话,这就会给数据库带来很大的压力. 常见场景:秒杀活动 等 解决方法: ...
随机推荐
- 【2017-10-1】雅礼集训day1
今天的题是ysy的,ysy好呆萌啊. A: 就是把一个点的两个坐标看成差分一样的东西,以此作为区间端点,然后如果点有边->区间没有交. B: cf原题啊.....均摊分析,简单的那种. 线段树随 ...
- 【Android开发】之Fragment开发1
一直知道Fragment很强大,但是一直都没有去学习,现在有些空闲的时间,所以就去学习了一下Fragment的简单入门.我也会把自己的学习过程写下来,如果有什么不足的地方希望大牛指正,共同进步! 一. ...
- 转:vue-cli的webpack模板项目配置文件分析
转载地址:http://blog.csdn.net/hongchh/article/details/55113751 一.文件结构 本文主要分析开发(dev)和构建(build)两个过程涉及到的文件, ...
- 移动端Touch事件
案例1: <!doctype html> <html lang="en"> <head> <meta charset="UTF- ...
- JAVA随笔(二)
在函数传参时,double传给int是不行的,反过来可以.参数只能传值.当参数是字符串时,传递的只是串值:但对于数组来说,传递的是管理权,也就是指针 对象变量是对象管理者. cast转型:基本类型与对 ...
- 洛谷P3203弹飞绵羊
传送门啦 非常神奇的分块大法. 每块分 √N 个元素 , 预处理出来:对于每个点,记录两个量:一个是它要弹几次才能出它所在的这个块,另外一个是它弹出这个块后到哪个点. 查询操作:一块一块跳过去 单次复 ...
- C#比较时分秒大小,终止分钟默认加十分钟,解决跨天、跨月、跨年的情况
private void cmbInHostimes_SelectedIndexChanged(object sender, EventArgs e) { DataRow[] dr; if (chkM ...
- Struts 2 Overview
Struts2 is popular and mature web application framework based on the MVC design pattern. Struts2 is ...
- EFK收集Kubernetes应用日志
本节内容: EFK介绍 安装配置EFK 配置efk-rbac.yaml文件 配置 es-controller.yaml 配置 es-service.yaml 配置 fluentd-es-ds.yaml ...
- Rookey.Frame之系统初始化
昨天介绍了数据库的配置,今天继续介绍系统的初始化功能:针对系统初始化在开发中也是很重要的一部分,它可以提前将相关数据提前自动初始化到系统中,同时也可以为上线测试提供方便,可以很方便进行系统测试演练,防 ...