Hadoop自定义类型处理手机上网日志
job提交源码分析
在eclipse中的写的代码如何提交作业到JobTracker中的哪?
(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法
connect();
info = jobClient.submitJobInternal(conf);
(2)在connect()方法中,实际上创建了一个JobClient对象。
在调用该对象的构造方法时,获得了JobTracker的客户端代理对象JobSubmissionProtocol。
JobSubmissionProtocol的实现类是JobTracker。
(3)在jobClient.submitJobInternal(conf)方法中,调用了
JobSubmissionProtocol.submitJob(...),
即执行的是JobTracker.submitJob(...)。
Hadoop数据类型
1.Hadoop的数据类型要求必须实现Writable接口。
2.java基本类型与Hadoop常见基本类型的对照
Long LongWritable
Integer IntWritable
Boolean BooleanWritable
String Text
java类型如何转化为hadoop基本类型?
调用hadoop类型的构造方法,或者调用set()方法。
new LongWritable(123L);
hadoop基本类型如何转化为java类型?
对于Text,需要调用toString()方法,其他类型调用get()方法。
使用Hadoop自定义类型处理手机上网日志
1、首先,将手机上网日志文件HTTP_20130313143750.dat通过WinSCP工具复制到/usr/local目录下
2、将日志文件上传到hdfs://chaoren:9000/wlan文件夹下
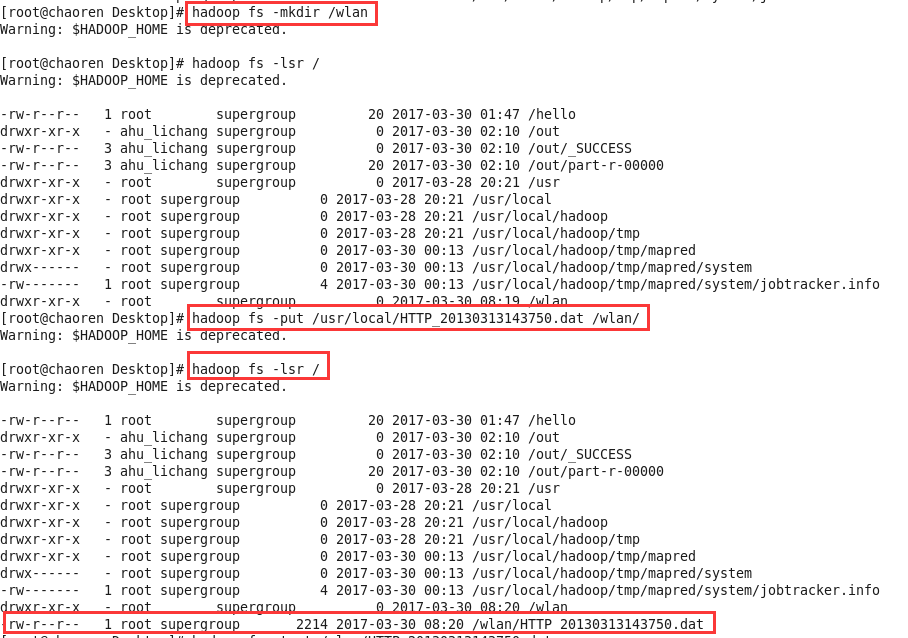
日志文件:

日志文件中各字段含义:
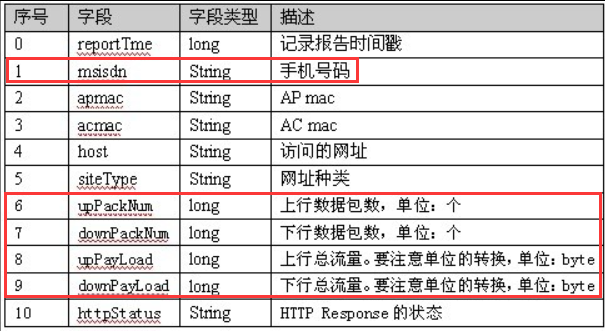
3、编写Java代码将日志文件中想要的数据统计出来。
package mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class KpiApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/wlan";//wlan是个文件夹,日志文件放在/wlan目录下
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
final Job job = new Job(new Configuration(),
KpiApp.class.getSimpleName());
// 1.1 指定输入文件路径
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定哪个类用来格式化输入文件
job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的Mapper类
job.setMapperClass(MyMapper.class);
// 指定输出<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class); // 1.3 指定分区类
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1); // 1.4 TODO 排序、分区 // 1.5 TODO (可选)归约 // 2.2 指定自定义的reduce类
job.setReducerClass(MyReducer.class);
// 指定输出<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(KpiWritable.class); // 2.3 指定输出到哪里
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
// 设定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class); // 把代码提交给JobTracker执行
job.waitForCompletion(true);
} static class MyMapper extends Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
final String[] splited = value.toString().split("\t");
final String msisdn = splited[1];
final Text k2 = new Text(msisdn);
final KpiWritable v2 = new KpiWritable(splited[6], splited[7],
splited[8], splited[9]);
context.write(k2, v2);
};
} static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
/**
* @param k2
* 表示整个文件中不同的手机号码
* @param v2s
* 表示该手机号在不同时段的流量的集合
*/
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L; for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
} final KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum
+ "", upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
} class KpiWritable implements Writable {
long upPackNum;
long downPackNum;
long upPayLoad;
long downPayLoad; public KpiWritable() {
} public KpiWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
this.upPayLoad = Long.parseLong(upPayLoad);
this.downPayLoad = Long.parseLong(downPayLoad);
} public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
} public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
} @Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t"
+ downPayLoad;
}
}
4、运行结果
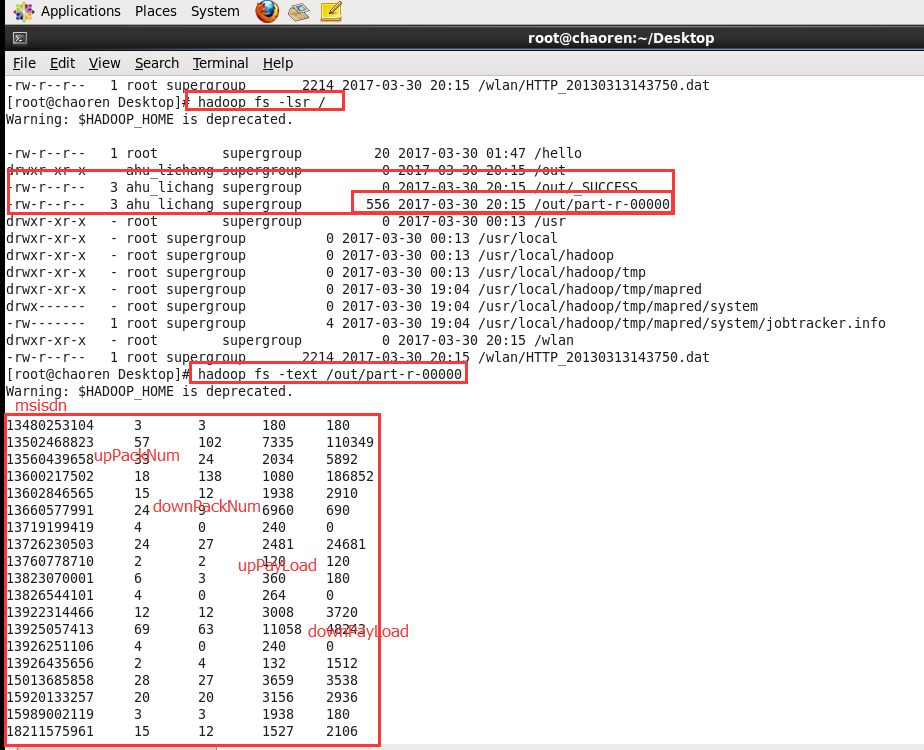
Hadoop自定义类型处理手机上网日志的更多相关文章
- Hadoop日记Day13---使用hadoop自定义类型处理手机上网日志
测试数据的下载地址为:http://pan.baidu.com/s/1gdgSn6r 一.文件分析 首先可以用文本编辑器打开一个HTTP_20130313143750.dat的二进制文件,这个文件的内 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- 使用Pig对手机上网日志进行分析
在安装成功Pig的基础上.本文将使用Pig对手机上网日志进行分析,详细过程例如以下: 写在前面: 手机上网日志文件phone_log.txt.文件内容 及 字段说明部分截图例如以下 需求分析 显示每一 ...
- MapReduce实现手机上网日志分析(分区)
一.问题背景 实际业务的需要,比如以移动为例,河南的用户去了北京上网,那么他的上网信息默认保存在了北京的基站,那么我们想要查询北京地区的上网日志信息默认也包含了其他地区用户的在本区的上网信息,否则只能 ...
- MapReduce实现手机上网日志分析(排序)
一.背景 1.1 流程 实现排序,分组拍上一篇通过Partitioner实现了. 实现接口,自动产生接口方法,写属性,产生getter和setter,序列化和反序列化属性,写比较方法,重写toStri ...
- 2017.9.2Java中的自定义类型的定义及使用&&自定义类的内存图
今日内容介绍 1.自定义类型的定义及使用 2.自定义类的内存图 3.ArrayList集合的基本功能 4.随机点名器案例及库存案例代码优化 01引用数据类型_类 * A: 数据类型 * a: java ...
- hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量 数据库类型如下: 数据库内容如下: 下面自定义类型SimLines,类似于平时编写的model import java.io.DataIn ...
- CMWAP CMWAP是手机上网使用的接入点的名称
CMWAP 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . CMWAP是手机上网使用的接入点的名称.CMWAP使用HTTP代理协议和WAP网关协议可以访问到Internet.移动用 ...
- APN APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络。
apn 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络. 对于手机用户来说,可 ...
随机推荐
- python3.6.4的importlib模块重载用法
了解:模块的重载 考虑到性能的原因,每个模块只被导入一次,放入字典sys.module中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块, 有的同学可能会想到直 ...
- jmeter上传图片附件-小插曲
背景 最近,接到新项目的接口测试,发现该接口是需要上传图片,开始折腾了好久没有搞定,最后才发现st和sid,并不是作为请求实体,而是url的一部分,好吧,是我没有仔细 请求参数 { "con ...
- HDU 1256 画8 模拟题
解题报告:这题我觉得题目有一个没有交代清楚的地方就是关于横线的字符的宽度的问题,题目并没有说,事实上题目要求的是在保证下面的圈高度不小于上面的圈的高度的情况下,横线的宽度就是等于下面的圈的高度. #i ...
- POJ 1986 Distance Queries (Tarjan算法求最近公共祖先)
题目链接 Description Farmer John's cows refused to run in his marathon since he chose a path much too lo ...
- JavaScript数组的概念
数组 1.数组是什么? 数组就是一组变量存放在里面就是数组. 例如:var list=['apple','goole','alibaba',520] (1.这些数据有一些相关性的. ( ...
- IIS 问题集锦
本文主要记录IIS中遇到的各种问题以及注意事项 一.在IIS中.NET Framework的版本选择为什么没有v3.0,v3.5? 首先需要澄清的是这里有两个关于版本的东西:ASP.NET和.NET ...
- 如何开启mysql5.5的客户端服务 命令行打开方法
MySQL分为两个部分,服务器端和客户端,只有服务器端的服务开启后,才可以通过客户端登录到MySQL数据库.这里介绍如何用命令行方式开启mysql的客户端服务. 在计算机上安装好mysql软件 我 ...
- 十九、springboot使用@ControllerAdvice(二)之深入理解
前言: 接口类项目开发时,为了便于后期查找问题,一般会拦截器或过滤器中记录每个接口请求的参数与响应值记录, 请求参数很容易从request中获取,但controller的返回值无法从response中 ...
- python面向对象(三)之继承
继承 介绍 继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力.继承即常说的is-a关系.子类继承父类的特征和行为,使得子类具有父类的各种属性和方法.或子类从父类继承 ...
- tf.nn.embedding_lookup函数
tf.nn.embedding_lookup(params, ids, partition_strategy='mod', name=None, validate_indices=True, max_ ...