Kubernetes监控:部署Heapster、InfluxDB和Grafana
本节内容:
- Kubernetes 监控方案
- Heapster、InfluxDB和Grafana介绍
- 安装配置Heapster、InfluxDB和Grafana
- 访问 grafana
- 访问 influxdb admin UI
- heapster采集的metric
一、Kubernetes 监控方案
可选的方案:
- Heapster + InfluxDB + Grafana
- Prometheus + Grafana
- Cadvisor + InfluxDB + Grafana
本篇文章介绍的是Heapster + InfluxDB + Grafana,kubernetes集群(1.6.0)搭建见前面的文章。
二、Heapster、InfluxDB和Grafana介绍
开源软件cAdvisor(Container cAdvisor)是用于监控容器运行状态的利器之一(cAdvisor项目的主页为https://github.com/cAdvisor),它被用于多个与Docker相关的开源项目中。
在kubernetes系统中,cAdvisor已经被默认集成到了kubelet组件内,当kubelet服务启动时,它会自动启动cAdvisor服务,然后cAdvisor会实时采集所在节点的性能指标及节点上运行的容器的性能指标。kubelet的启动参数--cadvisor-port可自定义cAdvisor对外提供服务的端口号,默认是4194。
cAdvisor提供了web页面可供浏览器访问,例如本kubernetes集群中的一个Node的ip是172.16.7.151,那么浏览器输入http://172.16.7.151:4194可以访问cAdvisor的监控页面。cAdvisor主页显示了主机的实时运行状态,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况等信息。
但是cAdvisor只提供了单机的容器资源占用情况,而在大规模容器集群中,需要对所有的Node和全部容器进行性能监控。这就需要一套工具来实现集群性能数据的采集、存储和展示:Heapster、InfluxDB和Grafana。
Heapster提供了整个集群的资源监控,并支持持久化数据存储到InfluxDB、Google Cloud Monitoring或者其他的存储后端。Heapster从kubelet提供的API采集节点和容器的资源占用。另外,Heapster的 /metrics API提供了Prometheus格式的数据。
InfluxDB是一个开源分布式时序、事件和指标数据库;而Grafana则是InfluxDB的 dashboard,提供了强大的图表展示功能。它们常被组合使用展示图表化的监控数据。
Heapster、InfluxDB和Grafana均以Pod的形式启动和运行,其中Heapster需要与Kubernetes Master进行安全连接。
三、安装配置Heapster、InfluxDB和Grafana
到 heapster release 页面 下载heapster。
[root@node1 opt]# wget https://github.com/kubernetes/heapster/archive/v1.3.0.zip
[root@node1 opt]# unzip v1.3.0.zip
[root@node1 opt]# cd heapster-1.3./deploy/kube-config/influxdb
[root@node1 influxdb]# ls *.yaml
grafana-deployment.yaml heapster-deployment.yaml influxdb-deployment.yaml
grafana-service.yaml heapster-service.yaml influxdb-service.yaml
1. 创建文件heapster-rbac.yaml
[root@node1 influxdb]# vim heapster-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: heapster
namespace: kube-system --- kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: heapster
subjects:
- kind: ServiceAccount
name: heapster
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
heapster-rbac.yaml
2. 修改 grafana-deployment.yaml
[root@node1 influxdb]# vim grafana-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas:
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: index.tenxcloud.com/jimmy/heapster-grafana-amd64:v4.0.2
ports:
- containerPort:
protocol: TCP
volumeMounts:
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GRAFANA_PORT
value: ""
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
value: /api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/
#value: /
volumes:
- name: grafana-storage
emptyDir: {}
grafana-deployment.yaml
【说明】:
- 如果后续使用 kube-apiserver 或者 kubectl proxy 访问 grafana dashboard,则必须将 GF_SERVER_ROOT_URL 设置为/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/,否则后续访问grafana时访问时提示找不到http://10.64.3.7:8086/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/api/dashboards/home 页面。
3. 修改heapster-deployment.yaml
[root@node1 influxdb]# vim heapster-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas:
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: index.tenxcloud.com/jimmy/heapster-amd64:v1.3.0-beta.
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
- --sink=influxdb:http://monitoring-influxdb:8086
heapster-deployment.yaml
【说明】:Heapster需要设置的启动参数如下:
- source:配置采集源,为Master URL地址:--source=kubernetes:https://kubernetes.default
- sink:配置后端存储系统,使用InfluxDB系统:--sink=influxdb:http://monitoring-influxdb:8086
其他参数可以通过进入heapster容器执行 # heapster --help 命令查看和设置。
【注意】:URL中的主机名地址使用的是InfluxDB的Service名字,这需要DNS服务正常工作,如果没有配置DNS服务,则也可以使用Service的ClusterIP地址。
另外,InfluxDB服务的名称没有加上命名空间,是因为Heapster服务与InfluxDB服务属于相同的命名空间kube-system。也可以使用上命名空间的全服务名,例如:http://monitoring-influxdb.kube-system:8086
4. 修改 influxdb-deployment.yaml
influxdb 官方建议使用命令行或 HTTP API 接口来查询数据库,从 v1.1.0 版本开始默认关闭 admin UI,将在后续版本中移除 admin UI 插件。
开启镜像中 admin UI的办法如下:先导出镜像中的 influxdb 配置文件,开启 admin 插件后,再将配置文件内容写入 ConfigMap,最后挂载到镜像中,达到覆盖原始配置的目的。
# 导出镜像中的 influxdb 配置文件
[root@node1 influxdb]# docker run --rm --entrypoint 'cat' -ti lvanneo/heapster-influxdb-amd64:v1.1.1 /etc/config.toml >config.toml.orig
[root@node1 influxdb]# cp config.toml.orig config.toml
# 修改配置:启用 admin 接口
[root@node1 influxdb]# vim config.toml
[admin]
enabled = true
# 将修改后的配置写入到 ConfigMap 对象中(kubectl 可以通过 --namespace 或者 -n 选项指定namespace。如果不指定, 默认为default)
[root@node1 influxdb]# kubectl create configmap influxdb-config --from-file=config.toml -n kube-system
configmap "influxdb-config" created
修改influxdb-deployment.yaml:
[root@node1 influxdb]# vim influxdb-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: monitoring-influxdb
namespace: kube-system
spec:
replicas:
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
image: index.tenxcloud.com/jimmy/heapster-influxdb-amd64:v1.1.1
volumeMounts:
- mountPath: /data
name: influxdb-storage
- mountPath: /etc/
name: influxdb-config
volumes:
- name: influxdb-storage
emptyDir: {}
- name: influxdb-config
configMap:
name: influxdb-config
influxdb-deployment.yaml
5. 修改 influxdb-service.yaml
[root@node1 influxdb]# vim influxdb-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-influxdb
name: monitoring-influxdb
namespace: kube-system
spec:
type: NodePort
ports:
- port:
targetPort:
name: http
- port:
targetPort:
name: admin
selector:
k8s-app: influxdb
influxdb-service.yaml
【说明】:
- 定义端口类型为 NodePort,将InfluxDB暴露在宿主机Node的端口上,以便后续浏览器访问 influxdb 的 admin UI 界面。
6. 执行所有定义文件进行安装
[root@node1 influxdb]# pwd
/opt/heapster-1.3./deploy/kube-config/influxdb
[root@node1 influxdb]# ls
grafana-deployment.yaml heapster-deployment.yaml heapster-service.yaml influxdb-deployment.yaml
grafana-service.yaml heapster-rbac.yaml influxdb-cm.yaml influxdb-service.yaml
[root@node1 influxdb]# kubectl create -f .
deployment "monitoring-grafana" created
service "monitoring-grafana" created
deployment "heapster" created
serviceaccount "heapster" created
clusterrolebinding "heapster" created
service "heapster" created
deployment "monitoring-influxdb" created
service "monitoring-influxdb" created
7. 检查执行结果
(1)检查 Deployment
# kubectl get deployments -n kube-system | grep -E 'heapster|monitoring'
heapster 12m
monitoring-grafana 12m
monitoring-influxdb 12m
(2)检查 Pods
# kubectl get pods -n kube-system | grep -E 'heapster|monitoring'
heapster--6hv9s / Running 10m
monitoring-grafana--n54fk / Running 10m
monitoring-influxdb--029q8 / Running 10m
(3)检查 kubernets dashboard 界面,看是显示各 Nodes、Pods 的 CPU、内存、负载等利用率曲线图
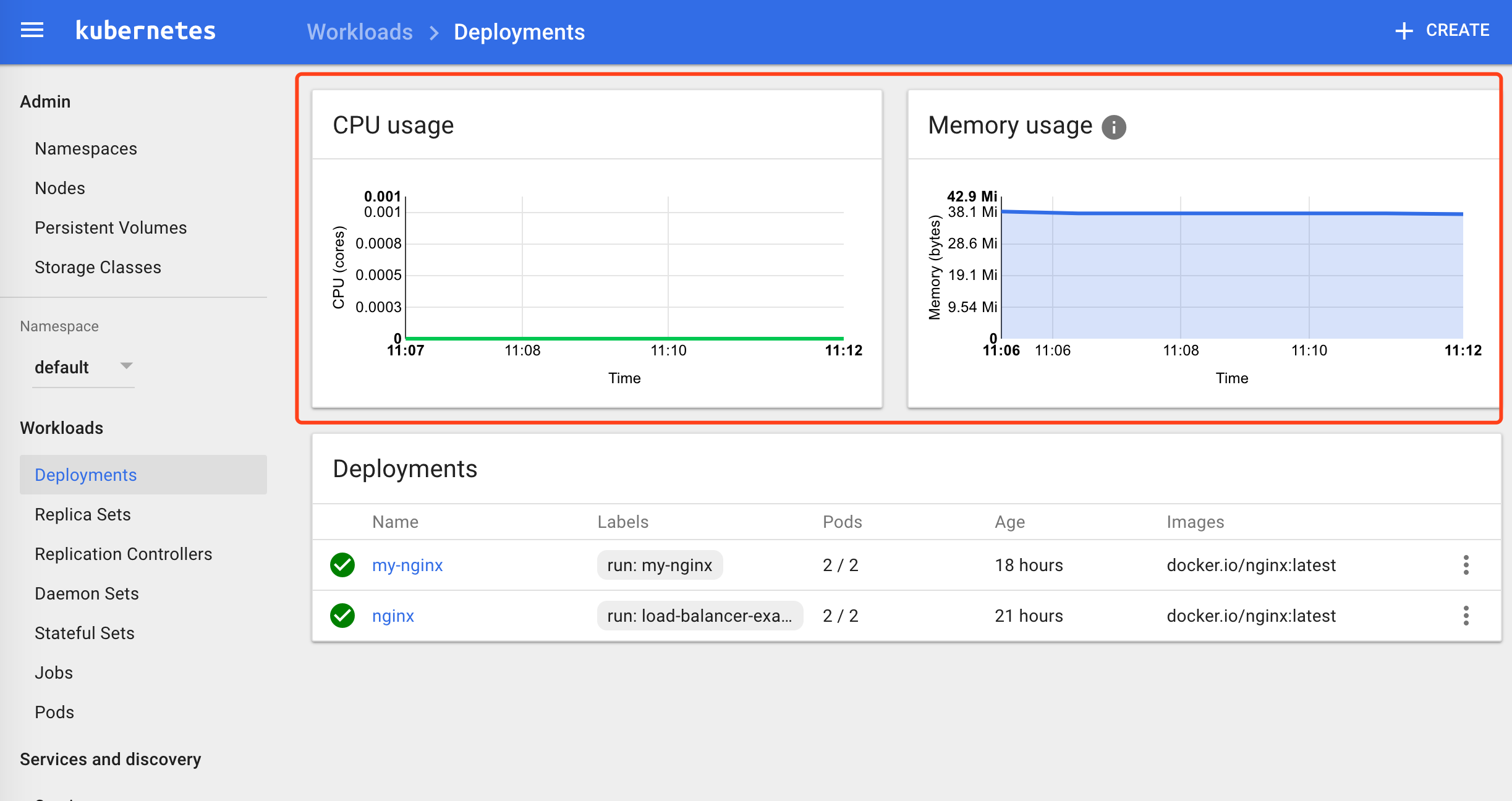
四、访问 grafana
1. 通过 kube-apiserver 访问
获取 monitoring-grafana 服务 URL:
[root@node1 influxdb]# kubectl cluster-info
Kubernetes master is running at https://172.16.7.151:6443
Heapster is running at https://172.16.7.151:6443/api/v1/proxy/namespaces/kube-system/services/heapster
KubeDNS is running at https://172.16.7.151:6443/api/v1/proxy/namespaces/kube-system/services/kube-dns
kubernetes-dashboard is running at https://172.16.7.151:6443/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard
monitoring-grafana is running at https://172.16.7.151:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana
monitoring-influxdb is running at https://172.16.7.151:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
浏览器访问 URL: http://172.16.7.151:8080/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana
2. 通过 kubectl proxy 访问
创建代理:
# kubectl proxy --address='172.16.7.151' --port= --accept-hosts='^*$'
浏览器访问 URL:http://172.16.7.151:8086/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana
3. Grafana页面查看和操作
浏览器访问 URL: http://172.16.7.151:8080/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana
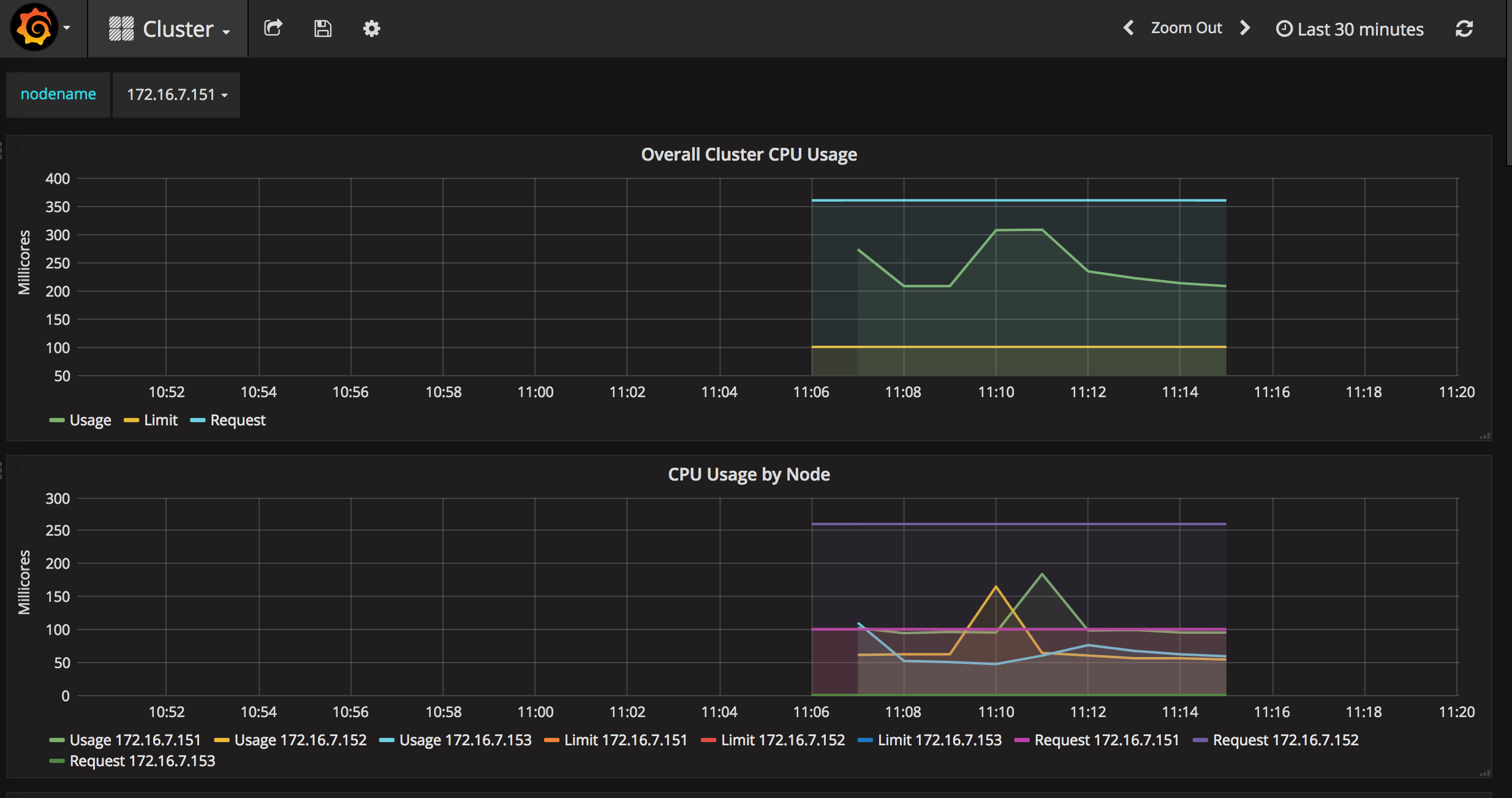
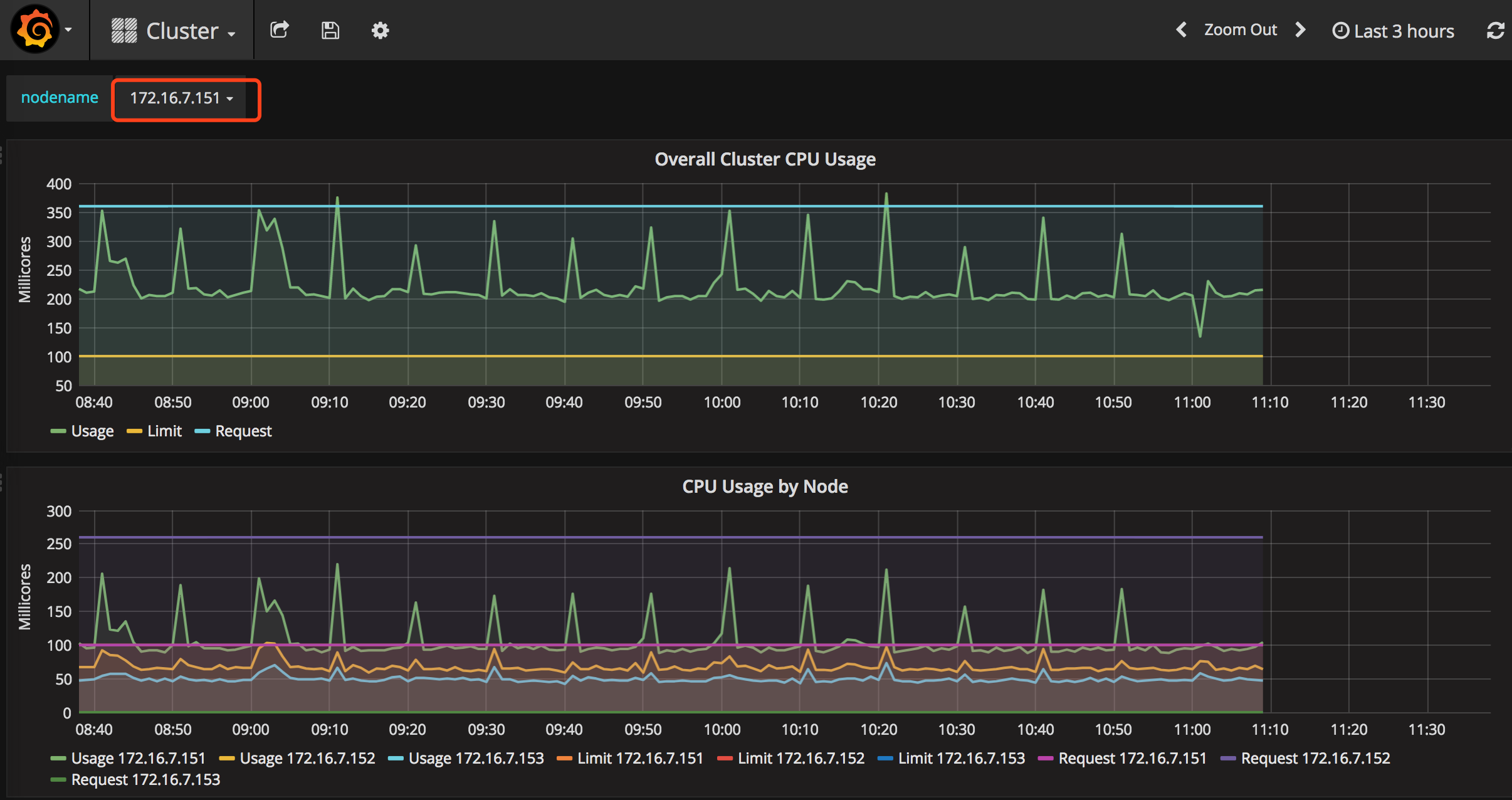
点击“Home”下拉列表,选择cluster,如下图。图中显示了Cluster集群的整体信息,以折线图的形式展示了集群范围内各Node的CPU使用率、内存使用情况等信息。
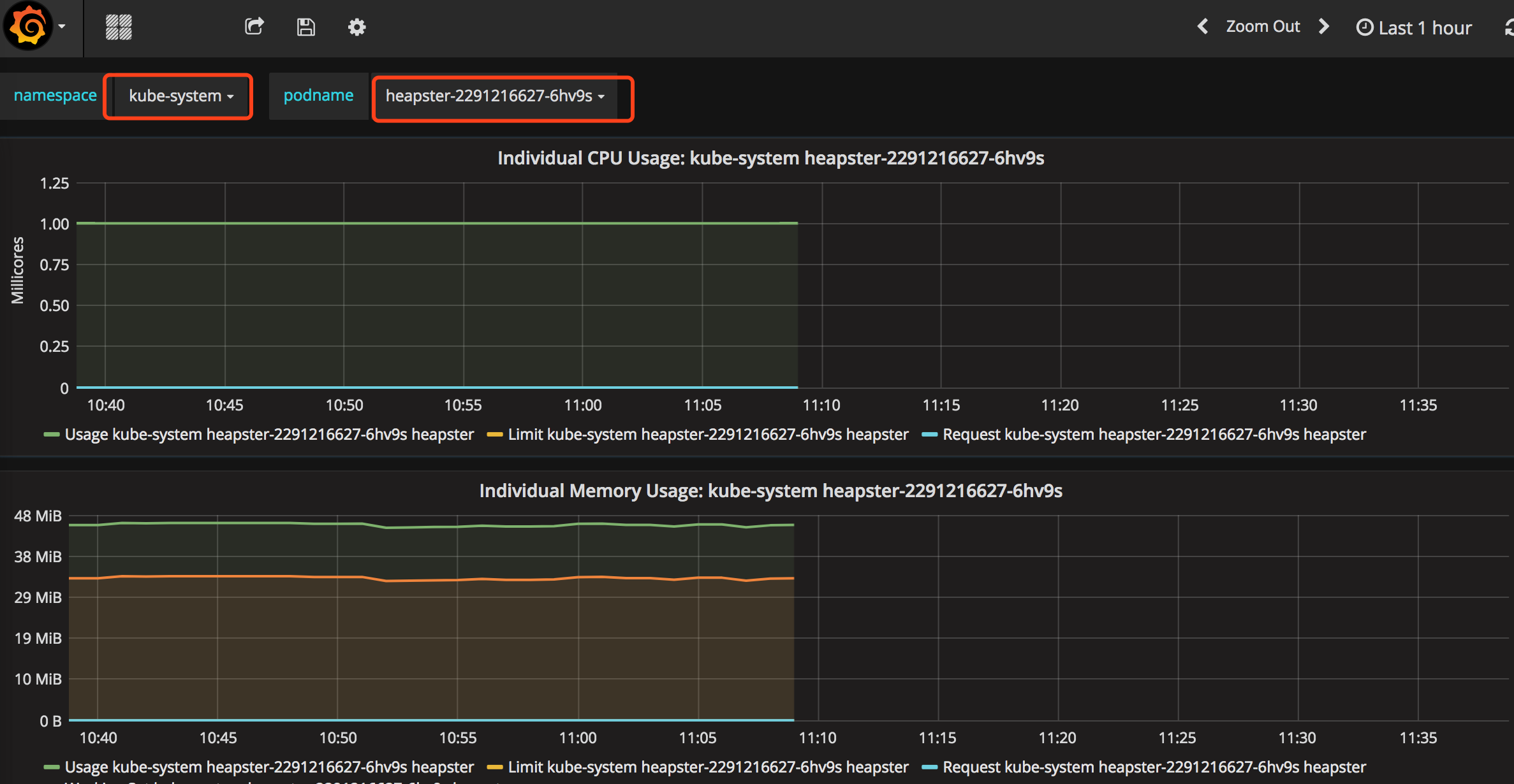
点击“Home”下拉列表,选择Pods,如下图。图中展示了Pod的信息,以折线图的形式展示了集群范围内各Pod的CPU使用率、内存使用情况、网络流量、文件系统使用情况等信息。
五、访问 influxdb admin UI
获取 influxdb http 8086 映射的 NodePort:
[root@node1 influxdb]# kubectl get svc -n kube-system|grep influxdb
monitoring-influxdb 10.254.66.133 <nodes> :/TCP,:/TCP 17m
通过 kube-apiserver 的非安全端口访问 influxdb 的 admin UI 界面:http://172.16.7.151:8080/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb:8083/
在页面的 “Connection Settings” 的 Host 中输入 node IP, Port 中输入 8086 映射的 nodePort 如上面的 32570,点击 “Save” 即可(我的集群中的地址是172.16.7.151:32570)。
通过右上角齿轮按钮可以修改连接属性。单击右上角的Database下拉列表可以选择数据库,heapster创建的数据库名为k8s。
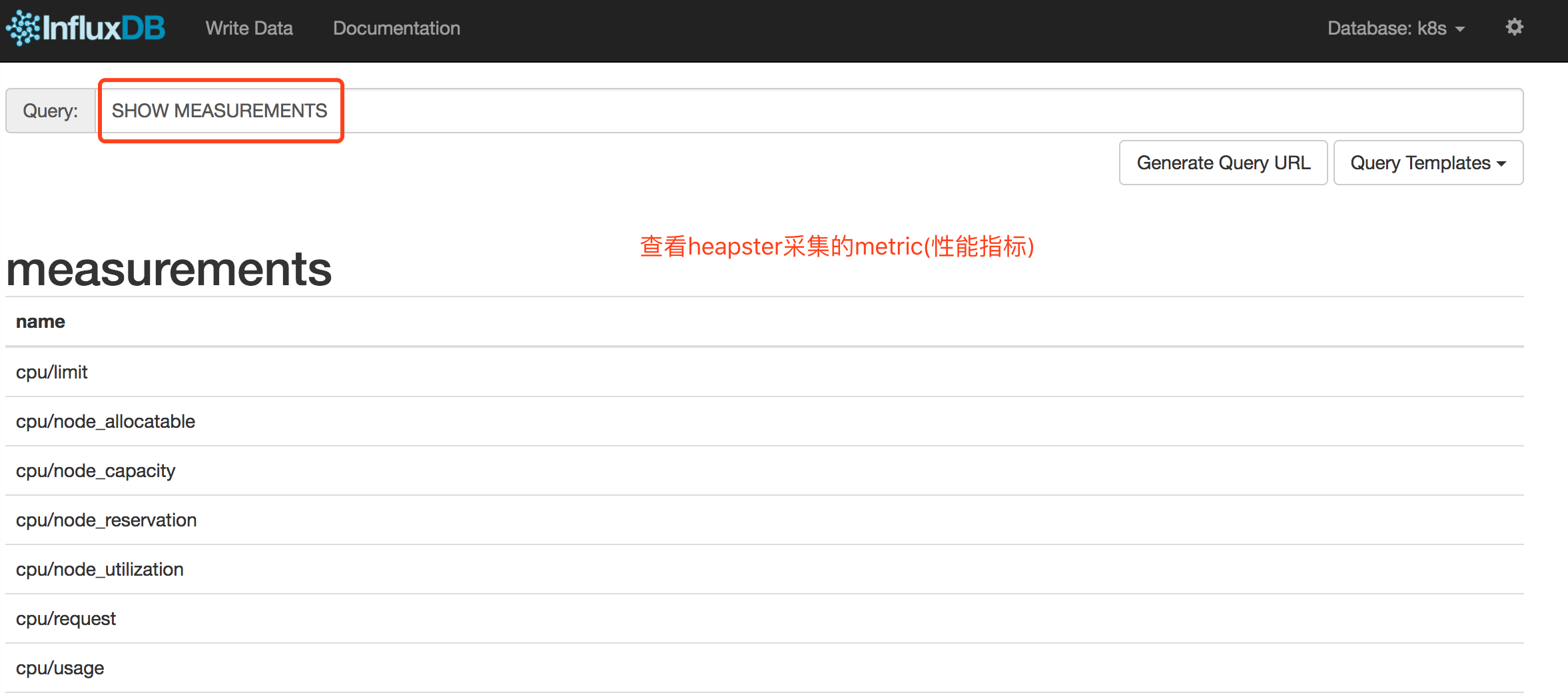
六、heapster采集的metric
| metric名称 | 说明 |
| cpu/limit | CPU hard limit,单位为毫秒 |
| cpu/usage | 全部Core的CPU累计使用时间 |
| cpu/usage_rate | 全部Core的CPU累计使用率,单位为毫秒 |
| filesystem/limit | 文件系统总空间限制,单位为字节 |
| filesystem/usage | 文件系统已用的空间,单位为字节 |
| memory/limit | Memory hard limit,单位为字节 |
| memory/major_page_faults | major page faults数量 |
| memory/major_page_faults_rate | 每秒的major page faults数量 |
| memory/node_allocatable | Node可分配的内存容量 |
| memory/node_capacity | Node的内存容量 |
| memory/node_reservation | Node保留的内存share |
| memory/node_utilization | Node的内存使用值 |
| memory/page_faults | page faults数量 |
| memory/page_faults_rate | 每秒的page faults数量 |
| memory/request | Memory request,单位为字节 |
| memory/usage | 总内存使用量 |
| memory/working_set | 总的Working set usage,Working set是指不会被kernel移除的内存 |
| network/rx | 累计接收的网络流量字节数 |
| network/rx_errors | 累计接收的网络流量错误数 |
| network/rx_errors_rate | 每秒接收的网络流量错误数 |
| network/rx_rate | 每秒接收的网络流量字节数 |
| network/tx | 累计发送的网络流量字节数 |
| network/tx_errors | 累计发送的网络流量错误数 |
| network/tx_errors_rate | 每秒发送的网络流量错误数 |
| network/tx_rate | 每秒发送的网络流量字节数 |
| uptime | 容器启动总时长 |
每个metric可以看作一张数据库表,表中每条记录由一组label组成,可以看成字段。如下表所示:
| Label名称 | 说明 |
| pod_id | 系统生成的Pod唯一名称 |
| pod_name | 用户指定的Pod名称 |
| pod_namespace | Pod所属的namespace |
| container_base_image | 容器的镜像名称 |
| container_name | 用户指定的容器名称 |
| host_id | 用户指定的Node主机名 |
| hostname | 容器运行所在主机名 |
| labels | 逗号分隔的Label列表 |
| namespace_id | Pod所属的namespace的UID |
| resource_id | 资源ID |
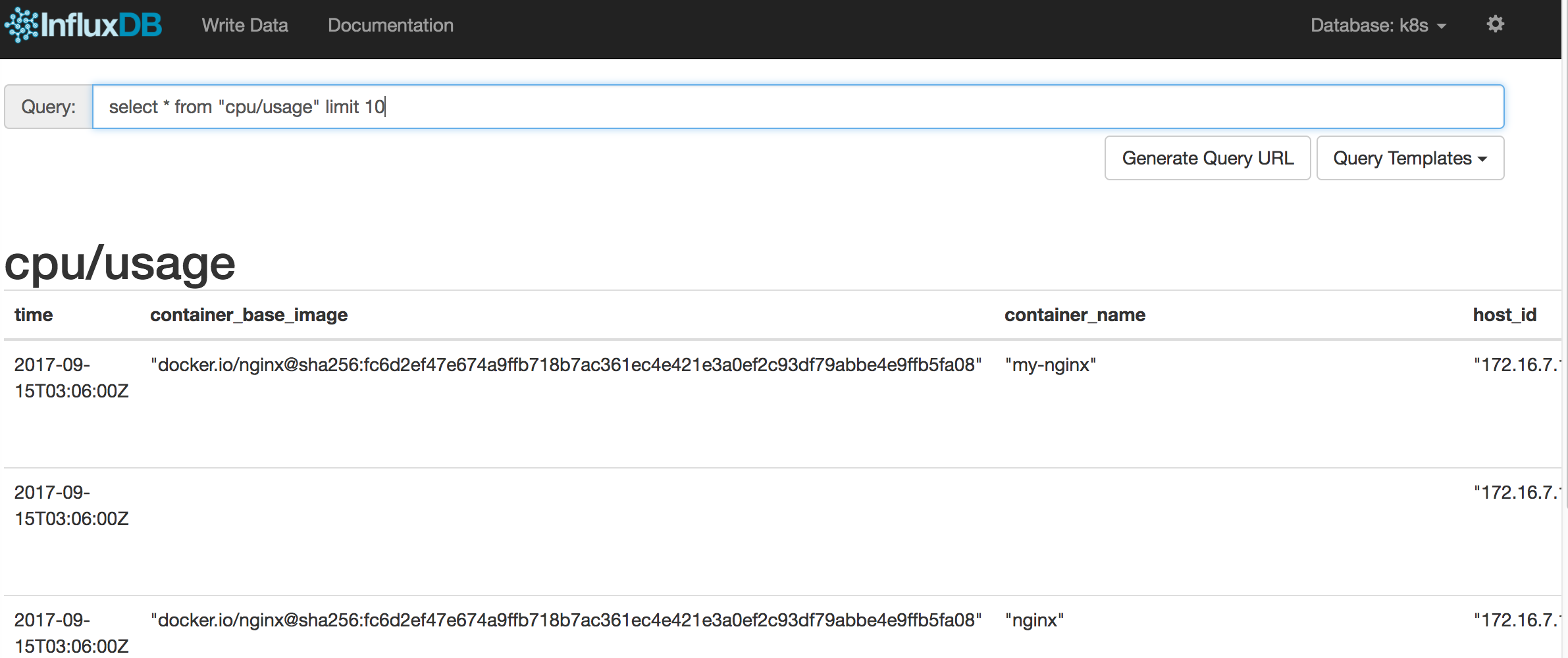
可以使用SQL SELECT语句对每个metric进行查询,例如查询CPU的使用时间:
select * from "cpu/usage" limit 10
结果如下图所示:
Kubernetes监控:部署Heapster、InfluxDB和Grafana的更多相关文章
- 详解k8s原生的集群监控方案(Heapster+InfluxDB+Grafana) - kubernetes
1.浅析监控方案 heapster是一个监控计算.存储.网络等集群资源的工具,以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu.内存.netwo ...
- 性能测试监控:Jmeter +InfluxDB +collectd +Grafana
虚拟机ip 192.168.180.128 Influxdb Influxdb是一个开源的分布式时序.时间和指标数据库,使用go语言编写,无需外部依赖. 它有三大特性: 时序性(Time Series ...
- 详解k8s一个完整的监控方案(Heapster+Grafana+InfluxDB) - kubernetes
1.浅析整个监控流程 heapster以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu.内存.网络流量等,然后将这些数据输出到外部存储,如Inf ...
- kubernetes监控-Heapster+InfluxDB+Grafana(十五)
cAdvisor+InfluxDB+Grafana cAdvisor:是谷歌开源的一个容器监控工具,采集主机上容器相关的性能指标数据.比如CPU.内存.网络.文件系统等. Heapster是谷歌开源的 ...
- kubernetes 监控方案之:heapster+influxdb+grafana(十八)
目录 一.Heapster 介绍 二.部署 三.使用 heapster 已经 deprecated 了:https://github.com/kubernetes/heapster,所以下面的演示主要 ...
- kubernetes监控和性能分析工具:heapster+influxdb+grafana
1.部署heapster 下载 heapster 相关 yaml 文件 [root@master dashboard]# wget https://raw.githubusercontent.com/ ...
- 建立Heapster Influxdb Grafana集群性能监控平台
依赖于kubenets dns服务 图形化展示度量指标的实现需要集成k8s的另外一个Addons组件: Heapster .Heapster原生支持K8s(v1.0.6及以后版本)和 CoreOS , ...
- 在Marathon 上部署 cAdvisor + InfluxDB + Grafana Docker监控
关于 Docker 容器的监控,google cAdvisor 是个很好的工具,但是它默认只显示实时数据,不储存历史数据.为了存储和显示历史数据.自定义展示图,可以把将cAdvisor与InfluxD ...
- 介绍Kubernetes监控Heapster
什么是Heapster? Heapster是容器集群监控和性能分析工具,天然的支持Kubernetes和CoreOS,Kubernetes有个出名的监控agent—cAdvisor.在每个kubern ...
随机推荐
- Linux各种重要配置文件详解
1:网卡文件/etc/sysconfig/network-scripts/ifcfg-eth0 [root@Gin scripts]# cat /etc/sysconfig/network-scrip ...
- P2787 语文1(chin1)- 理理思维
P2787 语文1(chin1)- 理理思维 1.获取第x到第y个字符中字母k出现了多少次 2.将第x到第y个字符全部赋值为字母k 3.将第x到第y个字符按照A-Z的顺序排序 读字符串我再单个单个读我 ...
- VS2013配置 OpenCV3.0【实测有效】
下载OpenCV3.0.0 到OpenCV官网下载对应版本http://opencv.org/downloads.html,然后安装到相应目录,本例是安装到D:\opencv300目录中. 配置环境变 ...
- bzoj千题计划167:bzoj3527: [Zjoi2014]力
http://www.lydsy.com/JudgeOnline/problem.php?id=3527 给出n个数qi,给出Fj的定义如下: 令Ei=Fi/qi,求Ei. 以n=4为例: ...
- php设计模式-工厂设计模式
概念: 工厂设计模式提供获取某个对象的新实例的一个接口,同时使调用代码避免确定实际实例化基类步骤. 很多高级模式都是依赖于工厂模式.
- 设置view controller到iPhone或者iPad模式
在写iOS程序时,view controller的显示大小以及控件大小的调节是在是一个费力的事,尤其是对于用mac本的童鞋,更难驾驭,这时我们可以根据需要设置专门针对iphone或者ipad的view ...
- 【HDU】2191 多重背包问题
原题目:悼念512汶川大地震遇难同胞——珍惜现在,感恩生活 [算法]多重背包(有限背包) 动态规划 [题解]http://blog.csdn.net/acdreamers/article/detail ...
- 【51nod】1766 树上的最远点对
[题意]给定n个点的树,m次求[a,b]和[c,d]中各选出一个点的最大距离.abcd是标号区间,n,m<=10^5 [算法]LCA+树的直径理论+线段树 [题解] 树的直径性质:距离树上任意点 ...
- 20155217 2016-2017-2 《Java程序设计》第8周学习总结
20155217 2016-2017-2 <Java程序设计>第8周学习总结 教材学习内容总结 15.1日志 15.1.1日志API简介 java.util.logging包提供了日志功能 ...
- Python练习-基于socket的FTPServer
# 编辑者:闫龙 import socket,json,struct class MySocket: with open("FtpServiceConfig","r&qu ...