hadoop学习笔记(四):HDFS
一、HDFS体系结构
1 HDFS假设条件
数据流访问
大数据集
简单相关模型
移动计算比移动数据便宜
多种软硬件平台中的可移植性
2 HDFS的设计目标
非常巨大的分布式文件系统
运行于普通硬件上
优化批处理
用户控件可以位于异构的操作系统中
在整个集群中使用单一的命名空间
数据一致性
文件被分为各个小块
智能客户端
程序采用“数据就近”原则分配节点执行
客户端对文件没有缓存机制
3 HDFS 架构
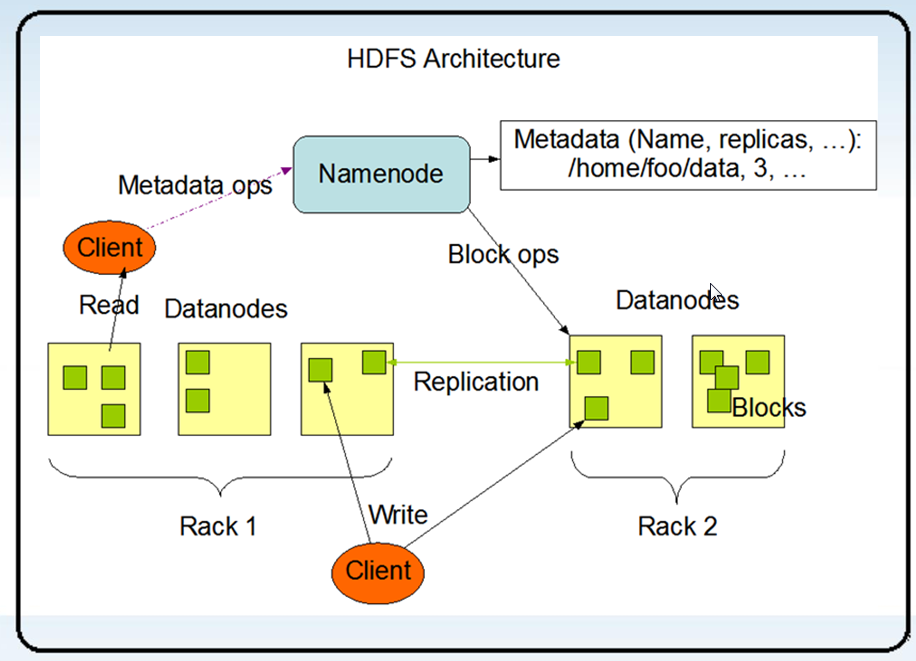
1 HDFS架构-文件
文件被切分为块(默认大小64M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)。
NameNode是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等。
DataNode在本地文件系统存储文件块数据,以及块数据校验和。
可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
2 HDFS文件权限
与 linux文件权限类似。
r:read;w:write;x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容。
如果linux系统用户zhangsan使用hadoop命令创建了一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS权限目的:阻止好人做错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
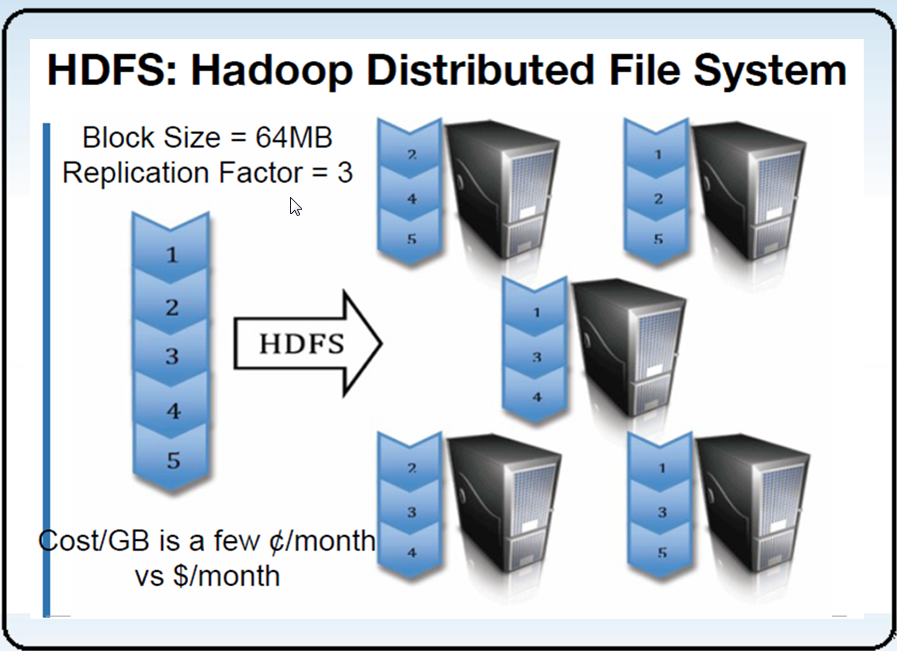
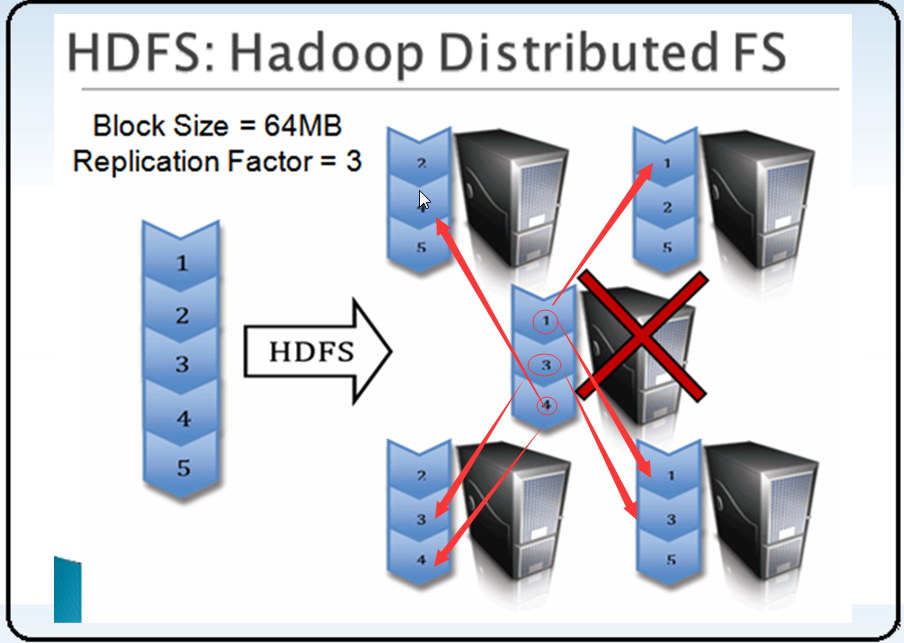
3 HDFS架构-组件功能
| NameNode | DataNode |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘中 |
| 保存文件、block、DataNode之间的映射关系 | 维护了blockId到DataNode本地文件的映射关系 |
NameNode:
是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
文件操作,NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问跟哪个DataNode的联系,否则NameNode会成为系统瓶颈。
副本存放在哪些DataNode上由NameNode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带宽消耗和读取延时。
NameNode全权管理数据块的复制,它周期性地从集群中的每一个DataNode接收心跳信号和块状态报告(BlockReport)。接收到心跳信号意味着该DataNode节点工作正常。块状态报告包含了一个该DataNode上所有数据块的列表。
DataNode:
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
DataNode启动后向NameNode注册,通过后,周期性(1小时)地向NameNode上报所有的块信息。
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
集群运行中可以安全加入和退出一些机器。
4 HDFS副本放置策略
| hadoop 0.17之前 | hadoop 0.17之后 |
| 副本1:同机架的不同节点 | 副本1:同Client的节点上 |
| 副本2:同机架的另一个节点 | 副本2:不同机架中的节点上 |
| 副本3:不同机架的另一个节点 | 副本3:同第二个副本的机架中的另一个节点 |
| 其他副本:随机挑选 | 其他副本:随机挑选 |
5 HDFS数据损坏(corruption)处理
当DataNode读取block的时候,它会计算checksum。
如果计算后的checksum与block创建时值不一样,说明该block已经损坏。
Client读取其他DN上的block。
NameData标记该块已经损坏,然后复制block达到预期设置的文件备份数。
DataNode在其文件创建后三周验证其checksum。
6 HDFS架构-Client&SNN
| Client | Secondary NameNode |
|
文件切分 与NameNode交互,获取文件位置信息 与DataNode交互,读取或写入数据 管理HDFS 访问HDFS |
并非NameNode的热备 辅助NameNode,分担其工作量 定期合并fsimage和fsedits,推送给NameNode 在紧急情况下,可辅助恢复NameNode |
7 HDFS架构-NN&SNN
NameNode两个重要的文件:
fsimage:元数据镜像文件(保存文件系统的目录树)
edits:元数据操作日志(针对目录树的修改操作)
元数据镜像:
内存中保存一份最新的
内存中的镜像=fsimage+edits
定期合并fsimage和edits:
edits文件过大导致NameNode重启速度慢
Secondary NameNode负责定期合并他们
NameNode启动过程与fsimag和edits的变化:
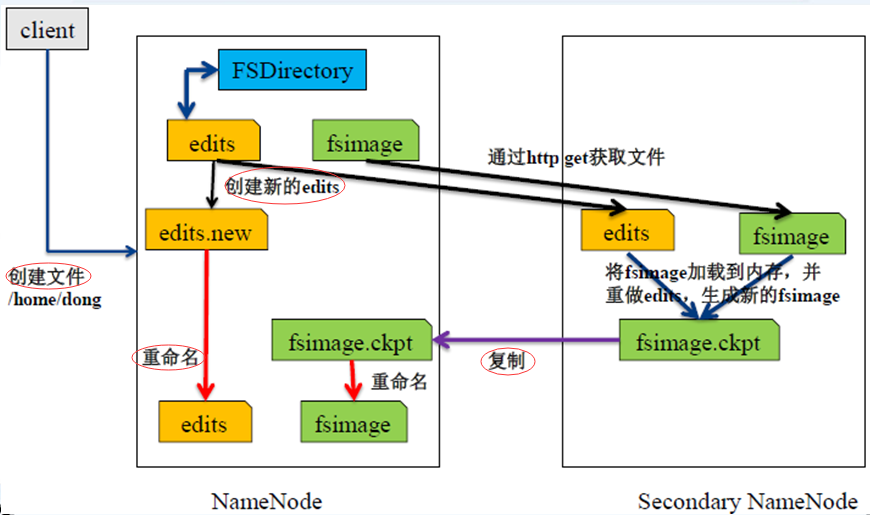
执行过程:
Secondary NN通知NN切换editlog -->
Secondary NN从NN获得fsimage和editlog(通过http方式)-->
Secondary NN将fsimage载入内存,然后开始合并editlog -->
Secondary NN将新的fsimage发回给NN -->
NN用新的fsimage替换旧的fsimage
hadoop学习笔记(四):HDFS的更多相关文章
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- Hadoop学习笔记四
一.fsimage,edits和datanode的block在本地文件系统中位置的配置 fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:// ...
- hadoop学习笔记贰 --HDFS及YARN的启动
1.初始化HDFS :hadoop namenode -format 看到如下字样,说明初始化成功. 启动HDFS,start-dfs.sh 终于启动成功了,原来是core-site.xml 中配置 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- hadoop学习笔记(四)——eclipse+maven+hadoop2.5.2源代码
Eclipse同maven进口hadoop源代码 1) 安装和配置maven环境变量 M2_HOME: D:\profession\hadoop\apache-maven-3.3.3 PATH: % ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- 【C#进阶】委托那些事儿(二)
二.传统的委托 接下来讲一讲方法参数.下面以“餐馆服务员为客户下单”[2]的事件作为描述.一般对事件的做法分3个部分: 1. 方法参数 EventArgs,一般用于传送数据.在本例场景中 public ...
- BitAdminCore框架应用篇:(一)使用Cookiecutter创建应用项目
框架演示:http://bit.bitdao.cn 框架源码:https://github.com/chenyinxin/cookiecutter-bitadmin-core 一.简介 1.Coo ...
- .NET Core 玩一玩 Ocelot API网关
.net 这几年国内确实不好过. 很多都选择转行.不过.net Core跨平台 开源之后 .社区的生态在慢慢建立.往好的趋势发展. 对于坚守在.NET战线的开发者来说 是个挺不错的消息. 特别是微软 ...
- Day 14 列表推导式、表达器、内置函数
一. 列表推导式# l1 = []# for i in range(1,11):# l1.append(i)# print(l1)# #输出结果:[1, 2, 3, 4, 5, 6, 7, 8, 9, ...
- jvm高级特性(4)(内存分配回收策略)
JVM高级特性与实践(四):内存分配 与 回收策略 一. 内存分配 和 回收策略 1,对象内存分配的概念: 往大方向讲,它就是在堆上分配(但也可能经过JIT编译后被拆散为标量类型并间接地栈上分配), ...
- jmeter报错
1.检测服务性能是报超时时问题 解决:因为服务器限制只能域名访问不能用ip+端口访问,但是jmter使用的是IP+端口访问 如图: 所以需要服务器放开这个端口,改成可以使用这个IP+端口访问
- python pip安装模块提示错误failed to create process
python pip安装模块提示错误failed to create process 原因: 报这个错误的原因,是因为python的目录名称或位置发生改动. 解决办法: 1.找到修改python所在的 ...
- day 46 Django 学习3 数据库单表操作以及反向解析
前情提要: Django 已经学了不少了, 今天学习链接数据库的操作.以及相关的反向解析等 一:反向解析 1:反向解析模板层 跳转时设定url会随着前面的路由改变而改变 2:反向解析之 ...
- Python小白学习之路(十八)—【内置函数三】
一.对象操作 help() 功能:返回目标对象的帮助信息 举例: print(help(input)) #执行结果 Help on built-in function input in module ...
- 【bzoj4240】 有趣的家庭菜园 树状数组
这一题最终要构造的序列显然是一个单峰序列 首先有一个结论:一个序列通过交换相邻的元素,进行排序,最少的交换次数为该序列的逆序对个数 (该结论很久之前打表意外发现的,没想到用上了.....) 考虑如何构 ...