大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
2.
cd apache-flume-1.6.0-bin;
cd conf;
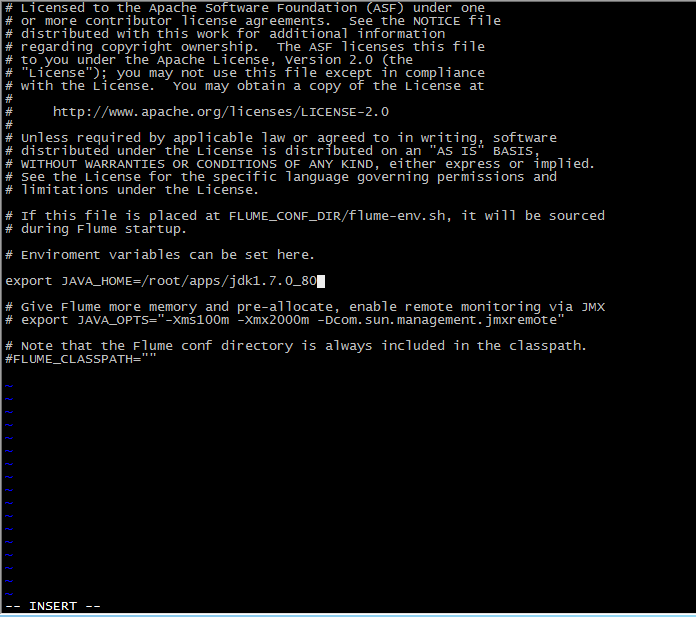
-- 修改环境变量
-- 重命名
mv flume-env.sh.template flume-env.sh vi flume-env.sh

测试小案例
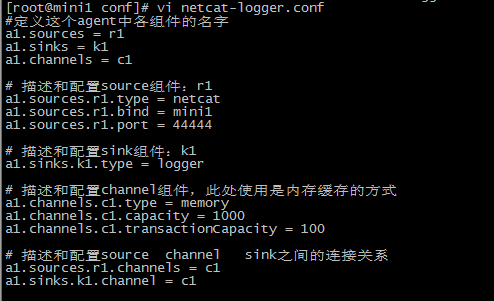
1 在 flume的conf文件下建一个文件
vi netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = itcast01
a1.sources.r1.port = 44444 # 描述和配置sink组件:k1
a1.sinks.k1.type = logger # 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2 启动agent去采集数据
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
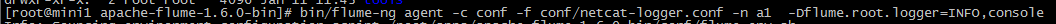
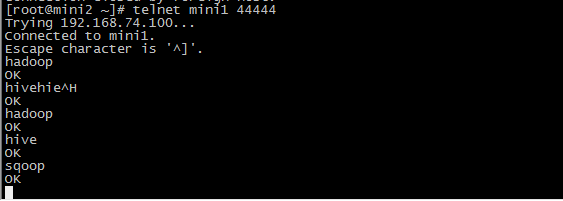
3 测试
先要往agent采集监听的端口上发送数据,让agent有数据可采
随便在一个能跟agent节点联网的机器上
telnet anget-hostname port (telnet itcast01 44444)
没有安装telnet的话先安装telnet(yum -y install telnet)


大数据学习——flume安装部署的更多相关文章
- 大数据学习——hive安装部署
1上传压缩包 2 解压 tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps 3 重命名 mv apache-hive-1.2.1-bin hive 4 设置环 ...
- 大数据学习——flume日志分类采集汇总
1. 案例场景 A.B两台日志服务机器实时生产日志主要类型为access.log.nginx.log.web.log 现在要求: 把A.B 机器中的access.log.nginx.log.web.l ...
- 大数据学习——flume拦截器
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 大数据学习——hadoop安装
上传centOS6.7-hadoop-2.6.4.tar.gz 解压 tar -zxvf centOS6.7-hadoop-2.6.4.tar.gz hadoop相关修改配置 1 修改 /root/a ...
- 大数据学习——redis安装
用源码工程来编译安装 / 到官网下载最新stable版 / 解压源码并进入目录 .tar.gz -C ./redis-src/ / make 如果报错提示缺少gcc,则安装gcc : yum inst ...
- 大数据学习——yum安装tomcat
https://www.cnblogs.com/jtlgb/p/5726161.html 安装tomcat6 yum install tomcat6 tomcat6-webapps tomcat6-a ...
- 大数据学习——VMware安装
---恢复内容开始--- 一.下载VMware,安装 二.新建虚拟机 1.FIle-->new virtual machine 后面进入硬件资源分配,其中cpu给1个,内存至少给1G,网卡的选择 ...
- 大数据学习——spark安装
一主多从 1 上传压缩包 2 解压 -bin-hadoop2..tgz 删除安装包 -bin-hadoop2..tgz 重命名 mv spark-1.6.2-bin-hadoop2.6/ spark ...
- 大数据学习——本地安装redis
下载安装包 https://github.com/MicrosoftArchive/redis 下载后解压 运行cmd 然后到redis路径 运行命令: redis-server redis.wind ...
随机推荐
- April Fools Contest 2017 C
Description DO YOU EXPECT ME TO FIND THIS OUT? WHAT BASE AND/XOR LANGUAGE INCLUDES string? DON'T BYT ...
- 480 Sliding Window Median 滑动窗口中位数
详见:https://leetcode.com/problems/sliding-window-median/description/ C++: class Solution { public: ve ...
- Myisamchk使用
Myisam损坏的情况: . 服务器突然断电导致数据文件损坏;强制关机,没有先关闭mysql 服务;mysqld 进程在写表时被杀掉.因为此时mysql可能正在刷新索引. . 磁盘损坏. . 服务器死 ...
- Java GUI 布局管理器
容器可设置布局管理器,管理容器中组件的布局: container.setLayout(new XxxLayout()); Java有6种布局管理器,AWT提供了5种: FlowLayout Borde ...
- Apache CXF 框架结构和基本原理
CXF旨在为服务创建必要的基础设施,它的整体架构主要由以下几个部分组成: 1.Bus 它是C X F架构的主干,为共享资源提供了一个可配置的场所,作用非常类似于S p r i n g的Applicat ...
- jstat查看JVM的GC情况
jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上 ...
- subprocess使用小方法
import subprocess def create_process(cmd): p = subprocess.Popen(cmd, shell=True, stdout=subp ...
- liunx中安装软件的几种方式
服务器安装包一般有四种方式 1.源代码包安装 自由度高 需要预编译,安装速度慢 2.rpm包手动安装 安装的缺点是文件的关联性太大 3. 二进制tar.gz格式 直接解压即可 如tomca ...
- 汇编2.汇编版本的helloworld
寻址方式 立即数寻址 寄存器寻址 存储器寻址 直接寻址 : mov ax, [ 01000h ]; 直接在[]内给出一个内存地址 寄存器间接寻址: mov ax ,[si]; 在[]以寄存器的值给出内 ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...