mysql优化----大数据下的分页,延迟关联,索引与排序的关系,重复索引与冗余索引,索引碎片与维护
理想的索引,高效的索引建立考虑:
1:查询频繁度(哪几个字段经常查询就加上索引) 2:区分度要高 3:索引长度要小 4: 索引尽量能覆盖常用查询字段(如果把所有的列都加上索引,那么索引就会变得很大) 1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多). 针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度. 所以, 我们要在 区分度 + 长度 两者上,取得一个平衡. 惯用手法: 截取不同长度,并测试其区分度, mysql> select count(distinct left(word,6))/count(*) from dict;
+---------------------------------------------------+
| count(distinct left(word,6))/count(*) |
+---------------------------------------------------+
| 0.9992 |
+---------------------------------------------------+
1 row in set (0.30 sec)

对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
2:对于左前缀不易区分的列 ,建立索引的技巧
如 url列http://www.baidu.com,http://www.zixue.it,列的前11个字符都是一样的,不易区分, 可以用如下2个办法来解决。 1: 把列内容倒过来存储,并建立索引
Moc.udiab.www//:ptth
Ti.euxiz.www//://ptth
这样左前缀区分度大, 2: 伪hash索引效果,存一个伪哈希列,把字符串转成整形降低索引长度。
同时存 url_hash列
explain select * from t9 where url=’http://www.baidu.com’ \G
mysql> select crc32('http://wwww.baidu.com.cn');
+-----------------------------------+
| crc32('http://wwww.baidu.com.cn') |
+-----------------------------------+
| 3865391929 |
+-----------------------------------+
索引长度key_len:50,
mysql> select * from t41 where crcstr=3865391929;
大数据下的分页:
limit 及翻页优化,limit offset,N, 当offset非常大时, 效率极低,
原因是mysql并不是跳过offset行,然后单取N行,
而是取offset+N行(跳过100万行,就是返回100万行,然后返回n行,再把其他的行扔掉)
效率较低,当offset越大时,效率越低 mysql> select * from emp limit 1000000,3;
+---------+--------+----------+-----+------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+---------+--------+----------+-----+------------+---------+--------+--------+
| 1100002 | JItXJo | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 266 |
| 1100003 | LdkQxP | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 347 |
| 1100004 | YOcUrZ | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 460 |
+---------+--------+----------+-----+------------+---------+--------+--------+
3 rows in set (0.48 sec)
mysql> select * from emp limit 3000000,3;
+---------+--------+----------+-----+------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+---------+--------+----------+-----+------------+---------+--------+--------+
| 3100002 | HsQcNK | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 106 |
| 3100003 | TOpgMq | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 202 |
| 3100004 | XHtWAN | SALESMAN | 1 | 2018-01-05 | 2000.00 | 400.00 | 143 |
+---------+--------+----------+-----+------------+---------+--------+--------+
3 rows in set (1.11 sec)
当跳过数量过多时,时间就长了。 优化办法:
1: 从业务上去解决
办法: 不允许翻过100页
以百度为例,一般翻页到70页左右. 1:不用offset,用条件查询.
例:
mysql> select id,name from lx_com limit 5000000,10;
+---------+--------------------------------------------+
| id | name |
+---------+--------------------------------------------+
| 5554609 | 温泉县人民政府供暖中心 |
..................
| 5554618 | 温泉县邮政鸿盛公司 |
+---------+--------------------------------------------+
10 rows in set (5.33 sec) mysql> select id,name from lx_com where id>5000000 limit 10;
+---------+--------------------------------------------------------+
| id | name |
+---------+--------------------------------------------------------+
| 5000001 | 南宁市嘉氏百货有限责任公司 |
.................
| 5000002 | 南宁市友达电线电缆有限公司 |
+---------+--------------------------------------------------------+
10 rows in set (0.00 sec)
这种方式要求数据没有删过,id是连续的。 问题: 2次的结果不一致
原因: 数据被物理删除过,有空洞.
解决: 数据不进行物理删除(可以逻辑删除). (一般来说,大网站的数据都是不物理删除的,只做逻辑删除,逻辑标记 ,比如 is_delete=1) 3: 非要物理删除,还非要用offset精确查询,还不能限制用户分页,用户可以直接跳到100万页,怎么办? 延迟关联。
分析: 优化思路是 不查,少查,查索引,少取.
我们现在必须要查,则只查索引,不查数据,得到id,id索引再内存里面, 再用id去查具体条目. 这种技巧就是延迟索引.
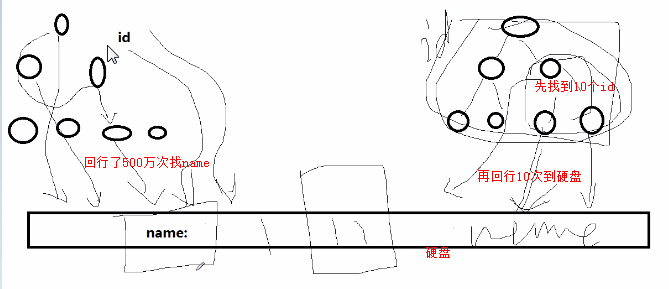
mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id); 之前的select * from emp limit 5000000,10;是在索引数上找了500万行并且回行了500万次来找name,因此回行到硬盘找了500万次。
select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);这个是先再索引树上找到10行,然后回行10次到硬盘就可以了。
+---------+-----------------------------------------------+
| id | name |
+---------+-----------------------------------------------+
| 5050425 | 陇县河北乡大谈湾小学 |
........
| 5050434 | 陇县堎底下镇水管站 |
+---------+-----------------------------------------------+
10 rows in set (1.35 sec) 延迟关联:
mysql> select * from it_area where name like '%东山%';
+------+-----------+------+
| id | name | pid |
+------+-----------+------+
| 757 | 东山区 | 751 |
| 1322 | 东山县 | 1314 |
| 2118 | 东山区 | 2116 |
| 3358 | 东山区 | 3350 |
+------+-----------+------+
4 rows in set (0.00 sec) 分析: 这句话用到了索引覆盖没有?
答: 没有,1 查询了所有列, 没有哪个索引,覆盖了所有列.
2 like %xx%”,左右都是模糊查询, name本身,都没用上索引 第2种做法:
select a.* from it_area as a inner join (select id from it_area where name like '%东山%') as t on a.id=t.id; Show profiles; 查看效率:
| 18 | 0.00183800 | select * from it_area where name like '%东山%'
| 20 | 0.00169300 | select a.* from it_area as a inner join (select id from it_area where name like '%东山%') as t on a.id=t.id | 发现 第2种做法,虽然语句复杂,但速度却稍占优势. 第2种做法中, 内层查询,只沿着name索引层顺序走, name索引层包含了id值的.
所以,走完索引层之后,找到所有合适的id,
再通过join, 用id一次性查出所有列. 走完name列再取. 第1种做法: 沿着name的索引文件走, 走到满足的条件的索引,就取出其id,
并通过id去取数据, 边走边回行取. 通过id查找硬盘行的过程被延后了. --- 这种技巧,称为”延迟关联”.
3:多列索引
3.1 多列索引的考虑因素---
列的查询频率 , 列的区分度,
以ecshop商城为例, goods表中的cat_id,brand_id,做多列索引
从区分度看,Brand_id区分度更高,
mysql> select count(distinct cat_id) / count(*) from goods;
+-----------------------------------+
| count(distinct cat_id) / count(*) |
+-----------------------------------+
| 0.2903 |
+-----------------------------------+
1 row in set (0.00 sec) mysql> select count(distinct brand_id) / count(*) from goods;
+-------------------------------------+
| count(distinct brand_id) / count(*) |
+-------------------------------------+
| 0.3871 |
+-------------------------------------+
1 row in set (0.00 sec) 但从 商城的实际业务业务看, 顾客一般先选大分类->小分类->品牌,
最终选择 index(cat_id,brand_id)来建立索引 有如下表(innodb引擎), sql语句在笔记中,
给定日照市,查询子地区, 且查询子地区的功能非常频繁,
如何优化索引及语句? +------+-----------+------+
| id | name | pid |
+------+-----------+------+
| .... | .... | .... |
| 1584 | 日照市 | 1476 |
| 1586 | 东港区 | 1584 |
| 1587 | 五莲县 | 1584 |
| 1588 | 莒县 | 1584 |
+------+-----------+------+ 1: 不加任何索引,自身连接查询
mysql> explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where; Using join buffer
2 rows in set (0.00 sec) 2: 给name加索引
mysql> explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3243
Extra: Using where; Using join buffer
2 rows in set (0.00 sec) 3: 在Pid上也加索引
mysql> explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ref
possible_keys: pid
key: pid
key_len: 5
ref: big_data.p.id
rows: 4
Extra: Using where
2 rows in set (0.00 sec)
索引与排序的关系:
排序可能发生2种情况:
1: 对于覆盖索引,直接在索引上查询时,就是有顺序的, using index
2: 先取出数据,形成临时表做filesort(文件排序,但文件排序可能在磁盘上,也可能在内存中) 我们的争取目标-----取出来的数据本身就是有序的! 免得还要排序。也就是利用索引来排序.索引不仅仅是利用在where查询上,排序也可以的。 比如: goods商品表, (cat_id,shop_price)组成联合索引,
where cat_id=N order by shop_price ,可以利用索引来排序,
select goods_id,cat_id,shop_price from goods order by shop_price;
order by shop_price按照shop_price索引取出的结果,本身就是有序的.不用file sort了。 select goods_id,cat_id,shop_price from goods order by click_count;
// using filesort 用到了文件排序,即取出的结果再次排序,order by click_count要根据click_count排序,而click_count无序。 所以索引可以提高查询、排序、分组效率。
重复索引与冗余索引:
重复索引:一个列增加了多次索引,index1(x)给x加一个索引名字叫index1,后来忘记了又加一个index2(x)给x又加了一个索引叫index2。叫重复索引, mysql允许重复索引,但是重复索引没有任何帮助,只会增大索引文件,拖慢更新速度, 去掉. 冗余索引:
冗余索引是指2个索引所覆盖的列有重叠, 称为冗余索引,比如 x,m,列,给x单加索引index x(x), 给x和m加多列索引index xm(x,m),两者的x列重叠了,这种情况,称为冗余索引。 Index(m,x)与index(x,m)叫冗余索引,不叫重复索引,因为这2个索引不是同一回事。(m,x)是再m排好序的基础上排x,而(x,m)是在x的下面排m。他们2个的索引文件是截然不同的,不是同一个索引。
索引碎片与维护:
在长期的数据更改过程中, 索引文件和数据文件,都将产生空洞,形成碎片。比如删除之后就会留下空的地方,增大了就会多出来地方。 这时候索引的效率和表的查询效率都会降低。
我们可以通过一个nop操作(no operate不产生对数据实质影响的操作), 来修改表.
比如: 表的引擎为innodb , 可以 alter table xxx engine innodb也可以optimize table 表名 ,也可以修复,重新规整数据和文件。(表大的话比较耗时,夜间操作) 注意: 修复表的数据及索引碎片,就会把所有的数据文件重新整理一遍,使之对齐.
这个过程,如果表的行数比较大,也是非常耗费资源的操作.所以,不能频繁的修复. 如果表的Update操作很频率,可以按周/月,来修复.如果不频繁,可以更长的周期来做修复.
mysql优化----大数据下的分页,延迟关联,索引与排序的关系,重复索引与冗余索引,索引碎片与维护的更多相关文章
- Mysql优化-大数据量下的分页策略
一.前言 通常,我们分页时怎么实现呢? 1 SELECT * FROM table ORDER BY id LIMIT 1000, 10; 但是,数据量猛增以后呢? 1 SELECT * FROM t ...
- [转] MySql 优化 大数据优化
一.我们可以且应该优化什么? 硬件 操作系统/软件库 SQL服务器(设置和查询) 应用编程接口(API) 应用程序 ------------------------------------------ ...
- mysql的大数据量的查询
mysql的大数据量查询分页应该用where 条件进行分页,limit 100000,100,mysql先查询100100数据量,查询完以后,将 这些100000数据量屏蔽去掉,用100的量,但是如果 ...
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- 【阿里云产品公测】大数据下精确快速搜索OpenSearch
[阿里云产品公测]大数据下精确快速搜索OpenSearch 作者:阿里云用户小柒2012 相信做过一两个项目的人都会遇到上级要求做一个类似百度或者谷歌的站内搜索功能.传统的sql查询只能使用like ...
- mysql优化, 删除数据后物理空间未释放(转载)
mysql优化, 删除数据后物理空间未释放(转载) OPTIMIZE TABLE 当您的库中删除了大量的数据后,您可能会发现数据文件尺寸并没有减小.这是因为删除操作后在数据文件中留下碎片所致.OPTI ...
- 大数据下的数据分析平台架构zz
转自http://www.cnblogs.com/end/archive/2012/02/05/2339152.html 随着互联网.移动互联网和物联网的发展,谁也无法否认,我们已经切实地迎来了一个海 ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- 【CSWS2014 Summer School】大数据下的游戏营销模式革新-邓大付
大数据下的游戏营销模式革新 邓大付博士腾讯专家工程师 Bio:毕业于华中科技大学,现任腾讯IEG运营部数据中心技术副总监,负责腾讯游戏的数据挖掘相关工作,包括有用户画像,推荐系统,基础算法研究等.主要 ...
随机推荐
- 刷题总结——电影(ssoi)
题目: 题目背景 SOURCE:NOIP2014-SXYZ T2 题目描述 小美去看电影,发现这个电影票很神奇,有一个编号 (x,y) 表示为第 x 排第 y 位. 小美是个聪明的女孩子,她有自己的一 ...
- yum update 出错解决办法
卸载掉yum和python 于是我卸载了python和yum,觉得自己重新安装python和yum. 步骤1:卸载python rpm -qa|grep python|xargs rpm -e --a ...
- 【bzoj1299】[LLH邀请赛]巧克力棒 博弈+模拟
Description TBL和X用巧克力棒玩游戏.每次一人可以从盒子里取出若干条巧克力棒,或是将一根取出的巧克力棒吃掉正整数长度.TBL先手两人轮流,无法操作的人输. 他们以最佳策略一共进行了10轮 ...
- Codevs 5564 陶陶摘苹果2
5564 陶陶摘苹果2 时间限制: 1 s 空间限制: 16000 KB 题目等级 : 白银 Silver 题目描述 Description 陶陶已经够高摘到所有苹果了,但是他力量有限,最大承受质量为 ...
- JS 操作XML
loadXML = function(xmlFile) { var xmlDoc; if(window.ActiveXObject) { xmlDoc ...
- T1013 求先序排列 codevs
http://codevs.cn/problem/1013/ 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Descr ...
- sring->list->del->string->int:解析左右编码器的,和#号
#def test_sprintf(): import string ' str1="1234567890," print'str1 is',str1 list_raw=list( ...
- express---express-session axios
express---express-session axios 使用axios访问后台获取session中的属性值为undefined 在main.js中导入axios import axios fr ...
- lib无法访问另外lib中的头文件
工程中app已经有设置User Header Search Paths来包含了需要的头文件,但是个别的lib依然找不到头文件.解决方法: 选择这个lib,在Build Settings中查找选项Use ...
- flask如何使模板返回大文件,又不消耗大量内存
当我们要往客户端发送大量的数据,比如一个大文件时,将它保存在内存中再一次性发到客户端开销很大.比较好的方式是使用流,本篇就要介绍怎么在Flask中通过流的方式来将响应内容发送给客户端.此外,我们还会演 ...