3.11-3.15 HDFS HA
一、背景
1、
Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。对于只有一个NameNode的集群,
若NameNode机器出现故障,则整个集群将无法使用,直到NameNode重新启动。 NameNode主要在以下两个方面影响HDFS集群
>NameNode 机器发生意外,如宕机,集群将无法使用,直到管理员重启
>NameNode 机器需要升级,包括软件、硬件升级,此时集群也将无法使用 HDFS HA功能通过配置Active/Standby 两个NameNodes 实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2、配置HA要点
*share edits
JournalNode *NameNode
Active,standby *Client E
Proxy *fence
同一时刻仅仅有一个NameNode对外提供服务
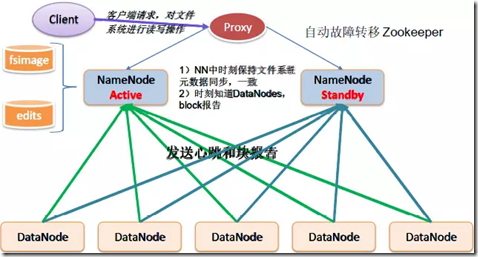
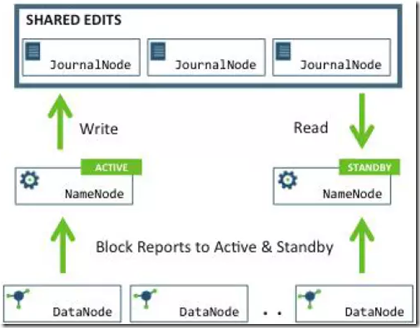
解释:
1、在HA中,如图会部署两台NameNode节点,一台为active状态,一台为 standby状态。
在正常情况下,由active节点向外提供服务。当active节点挂掉有,standby节点就会切换成active状态并向外提供服务。 2、NameNode active节点和standby节点是通过JounalNode集群实时同步数据的。
JounalNode是一个日志集群,相当于NameNode active里的所有操作日志editlog都会同步到JounalNode里面去,
然后standby节点实时从JounnalNode里面取这些操作日志并写入到自己的节点中,使自己的元数据和active节点保持一致。
这样,当active节点挂掉时,standby节点可以立即切换为active节点。
JounalNode一般部署2n+1个。(生产一般3-5台) 3、DataNode节点在HA架构中,会向NameNode active和standby节点同时发送心跳包和块报告。 4、对于两个NameNode节点,是通过zkfc(zookeeperFailoverController)来控制谁来做active。zkfc是单独的进程,
它负责监控NameNode的状态。NameNode会定期向zookeeper发送心跳,使得自己可以被选举,当其中一个被zk选举为主的时候,
zkfc进程通过RPC调用使得被选举的NameNode状态变为active,对外提供服务。
在典型的HA集群中,Active Namenode响应客户端的操作请求,而Standby Namenode作为一个slave执行,
只是保持跟Active Namenode的状态一致。Active namenode和Standby namenode为了保持一致,
他们都与JournalNodes(JNs)进行通信。每当Active node修改namespace时,都会将修改日志计入JNs中,
Standby node从JNs读取edit logs,并时刻监控JNs(只要Edit Logs有改动就同步),因为Standy node在时刻监控,
就可以保证在故障转移发生时,Standby node的edit Logs与Active node完全一致,从而直接切换成Active状态。 为了实现快速故障转移,Standby node必须清楚集群中数据块的位置,为datanodes配置这2个Namenods(Active/Standby),
并且datanodes同时向两个namenodes发送块信息和心跳。 在HDFS HA集群中,必须保证只有一个Active节点,否则会造成错误和混乱。 JournalNode daemon是轻量级的,可以和其他hadoop daemons(namenode,resourcemanager等)共同运行在一台主机。
JournalNode主机和Zookeeper主机很相似,必须要有奇数个(2N+1)主机(最少3个),其中N代表可以宕机的数量,
如果宕机的数量超过了N,JournalNode集群就不可用了。 Standby namenode不可以代替Secondary Node的作用。
二、部署
1、节点规划
HA 架构不需要secondaryNode了;
| master | slave1 | slave2 |
| namenode | namenode | |
| JournalNode | JournalNode | JournalNode |
| datanode | datanode | datanode |
2、备份目录
##############master#################
#备份配置文件
[root@master etc]# pwd
/opt/app/hadoop-2.5.0/etc [root@master etc]# cp -r hadoop/ dist-hadoop
[root@master etc]# ls
bak-hadoop dist-hadoop hadoop #备份data/tmp
[root@master data]# pwd
/opt/app/hadoop-2.5.0/data [root@master data]# mv tmp/ dist-tmp
[root@master data]# mkdir tmp ##############slave1#################
[root@slave1 zookeeper-3.4.5]# cd /opt/app/hadoop-2.5.0/etc/
[root@slave1 etc]# cp -r hadoop dist-hadoop
[root@slave1 etc]# cd ..
[root@slave1 hadoop-2.5.0]# cd data/
[root@slave1 data]# mv tmp/ dist-tmp
[root@slave1 data]# mkdir tmp ##############slave2#################
[root@slave2 zookeeper-3.4.5]# cd /opt/app/hadoop-2.5.0/etc/
[root@slave2 etc]# cp -r hadoop dist-hadoop
[root@slave2 etc]# cd ..
[root@slave2 hadoop-2.5.0]# cd data/
[root@slave2 data]# mv tmp/ dist-tmp
[root@slave2 data]# mkdir tmp
3、编辑配置文件
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
hdfs-site.xml
#sshfence方式的fence,两个namenode之间必须可以免密登陆;
<configuration>
<!-- namenode HA -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave1:8020</value>
</property>
<!-- namenode http web -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave1:50070</value>
</property>
<!-- journalnode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/data/dfs/jn</value>
</property>
<!-- proxy client-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- namenode fence-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
4、同步配置文件
[root@master hadoop]# pwd
/opt/app/hadoop-2.5.0/etc/hadoop [root@master hadoop]# scp -r core-site.xml hdfs-site.xml slaves root@slave1:/opt/app/hadoop-2.5.0/etc/hadoop/ [root@master hadoop]# scp -r core-site.xml hdfs-site.xml slaves root@slave2:/opt/app/hadoop-2.5.0/etc/hadoop/
5、QJM HA启动
1、启动journalnode,每个节点都要逐一启动
[root@master hadoop-2.5.0]# sbin/hadoop-daemon.sh start journalnode [root@slave1 hadoop-2.5.0]# sbin/hadoop-daemon.sh start journalnode [root@slave2 hadoop-2.5.0]# sbin/hadoop-daemon.sh start journalnode 可以jps看一下; 2、在[nn1]上初始化文件系统,启动namenode(nn1)
[root@master hadoop-2.5.0]# bin/hdfs namenode -format [root@master hadoop-2.5.0]# sbin/hadoop-daemon.sh start namenode 可以jps看一下; 3、在[nn2]上,同步nn1的元数据信息,启动namenode(nn2)
[root@slave1 hadoop-2.5.0]# bin/hdfs namenode -help #查看帮助 [root@slave1 hadoop-2.5.0]# bin/hdfs namenode -bootstrapStandby #同步 [root@slave1 hadoop-2.5.0]# sbin/hadoop-daemon.sh start namenode 现在master和slave1都是namenode了,可以用web查看,
现在两个都是standby; 4、上启动所有DataNode,每个节点都要逐一启动
[root@master hadoop-2.5.0]# sbin/hadoop-daemon.sh start datanode [root@slave1 hadoop-2.5.0]# sbin/hadoop-daemon.sh start datanode [root@slave2 hadoop-2.5.0]# sbin/hadoop-daemon.sh start datanode 5、将nn1变为Active
[root@master hadoop-2.5.0]# bin/hdfs haadmin #查看帮助
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId> [--forceactive]]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>] #将nn1变为Active
[root@master hadoop-2.5.0]# bin/hdfs haadmin -transitionToActive nn1
19/04/17 17:45:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable #查看nn1的状态,可见已经是active了
[root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn1
19/04/17 17:45:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active #查看nn2的状态,是standby
root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn2
19/04/17 17:46:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
三、HA集群测试
1、创建目录
[root@master hadoop-2.5.0]# bin/hdfs dfs -mkdir -p /user/root/ [root@master hadoop-2.5.0]# bin/hdfs dfs -mkdir -p /user/root/conf/ [root@master hadoop-2.5.0]# bin/hdfs dfs -ls -R /user
19/04/17 17:54:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
drwxr-xr-x - root supergroup 0 2019-04-17 17:54 /user/root
drwxr-xr-x - root supergroup 0 2019-04-17 17:54 /user/root/conf
2、上传测试文件
[root@master hadoop-2.5.0]# bin/hdfs dfs -put etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml /user/root/conf/ [root@master hadoop-2.5.0]# bin/hdfs dfs -ls -R /user
19/04/17 17:58:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
drwxr-xr-x - root supergroup 0 2019-04-17 17:54 /user/root
drwxr-xr-x - root supergroup 0 2019-04-17 17:58 /user/root/conf
-rw-r--r-- 3 root supergroup 1075 2019-04-17 17:58 /user/root/conf/core-site.xml
-rw-r--r-- 3 root supergroup 2140 2019-04-17 17:58 /user/root/conf/hdfs-site.xml
3、读取文件,看是否可以读取
[root@master hadoop-2.5.0]# bin/hdfs dfs -text /user/root/conf/core-site.xml
四、active和standby手动切换
#把nn1变成standby
[root@master hadoop-2.5.0]# bin/hdfs haadmin -transitionToStandby nn1 #把nn2变成active
[root@master hadoop-2.5.0]# bin/hdfs haadmin -transitionToActive nn2 此时可以查看一下状态,也可以在web中查看;
3.11-3.15 HDFS HA的更多相关文章
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- 3.配置HDFS HA
安装zookeeper下载zookeeper编辑zookeeper配置文件创建myid文件启动zookeeper配置HDFS HA配置手动HA配置自动HA启动HDFS HA namenode负责管理整 ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- 数据库管理工具GUI - PremiumSoft Navicat Premium Enterprise 11.2.15 x86/x64 KEY
转载自: 数据库管理工具GUI - PremiumSoft Navicat Premium Enterprise 11.2.15 x86/x64 KEY Navicat Premium(数据库管理工具 ...
- 2016年11月15日 星期二 --出埃及记 Exodus 20:6
2016年11月15日 星期二 --出埃及记 Exodus 20:6 but showing love to a thousand of those who love me and keep my c ...
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- 【解决】HDFS HA无法自动切换问题
[解决]HDFS HA无法自动切换问题 原因: 最早设置为root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件.更改为hdfs账号免密钥登录恢复正常. ...
- Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
其他的配置跟HDFS-HA部署方式完全一样.但JournalNOde的配置不一样>hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的 ...
- Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压 step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建) 包括 ...
随机推荐
- 深入GCD(五):资源竞争
概述我将分四步来带大家研究研究程序的并发计算.第一步是基本的串行程序,然后使用GCD把它并行计算化.如果你想顺着步骤来尝试这些程序的话,可以下载源码.注意,别运行imagegcd2.m,这是个反面教材 ...
- 【lombok】使用lombok注解,在代码编写过程中可以调用到get/set方法,但是在编译的时候无法通过,提示找不到get/set方法
错误如题:使用lombok注解,在代码编写过程中可以调用到get/set方法,但是在编译的时候无法通过,提示找不到get/set方法 报错如下: 解决方法: 1.首先查看你的lombok插件是否下载安 ...
- JavaSE Map的使用
1.Map概述 Map与Collection并列存在.用来保存具有映射关系的数据:Key-Value Map 中的 key 和 value都能够是不论什么引用类型的数据 Map 中的 key 用Se ...
- 全文索引--自己定义chinese_lexer词典
本文来具体解释一下怎样自己定义chinese_lexer此法分析器的词典 初始化数据 create table test2 (str1 varchar2(2000),str2varchar2(2000 ...
- Cocos2d-x 精灵碰撞检測(方法一)
声明函数碰撞检測函数,两个精灵和重写update bool isCollision( CCPoint p1,CCPoint p2,int w1,int h1,int w2,int h2 ); CCSp ...
- 李洪强iOS开发之 - enum与typedef enum的用法
李洪强iOS开发之 - enum与typedef enum的用法 01 - 定义枚举类型 上面我们就在ViewController.h定义了一个枚举类型,枚举类型的值默认是连续的自然数,例如例子中的T ...
- Linux fork函数具体图解-同一时候分析一道腾讯笔试题
原创blog.转载请注明出处 头文件: #include<unistd.h> #include<sys/types.h> 函数原型: pid_t fork( void); (p ...
- 6.游戏特别离不开脚本(4)-应该避免将集合框架对象传给JS
java map 传给 javascript 不是自动关联的,最好别传啊,遍历起来也麻烦(尽量避开集合框架吧),用数组或者自建一个对象.这里虽然有种方法: // build a Map Map< ...
- DELPHI中的消息处理机制(三种消息处理方法的比较,如何截断消息)
DELPHI中的消息处理机制 Delphi是Borland公司提供的一种全新的WINDOWS编程开发工具.由于它采用了具有弹性的和可重用的面向对象Pascal(object-orientedpasca ...
- VC++ 对话框下使用工具栏
关于这一技术网上也有很多的记录,下面仅记录我测试OK的代码. 在CXXDlg.h中添加如下成员变量: CToolBar m_ToolBar; CBitmap m_bmpTool; 在CXXDlg ...