python3爬取”理财大视野”中的股票,并分别写入txt、excel和mysql
需求:爬取“理财大视野”网站的排名、代码、名称、市净率、市盈率等信息,并分别写入txt、excel和mysql
环境:python3.6.5
网站:http://www.dashiyetouzi.com/tools/value/Graham.php
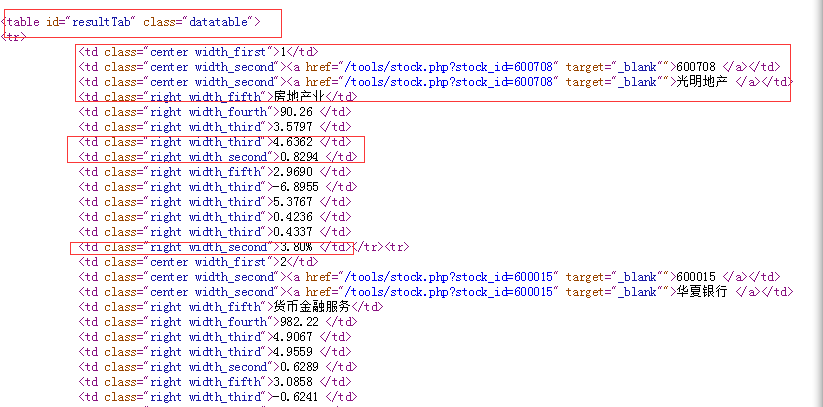
查看html源码:信息在html中以table形式存在,每个股票信息是一行,存放在tr中,单元格信息存放在td中
因此思路为:通过id或者class查找table→查找tr→查找td
第三方库
from bs4 import BeautifulSoup
from urllib import request
import time
import xlrd
import xlwt
import pymysql
获取html源码
url = "http://www.dashiyetouzi.com/tools/value/Graham.php"
htmlData = request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(htmlData, 'lxml')
#print(soup.prettify())
allData = soup.find("table", {'class': 'datatable'})
遍历表格中的每一行进行查找
for tr in allData.find_all('tr'):
eachData = tr.find_all('td')
#print(eachData)
rank = eachData[0].string#排名
code = eachData[1].find('a').string#代码
name = eachData[2].find('a').string#名称
industry = eachData[3].string#行业
PE = eachData[6].string#市净率
PBV = eachData[7].string#市盈率
#返回类型不一样,get_text()返回的是字符串,末尾有空格。需要先去掉末尾的空格,再去掉百分号
GXL = eachData[-1].get_text().rstrip().strip('%')#股息率
股息率用string取的类型不是字符串,无法进行后续操作
将股息率大于4的结果保存成一位数组形式allIms。
同时写入txt文档,本次写入的方式是生成一个股票信息info立马写入(无需整合成数组eachIms),而不是最后整体写入,因此直接写到循环里面了
if float(GXL) > 4:
# 写入txt文件,循环写入
info = "排名:" + rank + ",代码:" + code + ",股票名称:" + name + ",所属行业:" + industry + ",市盈率:" + PE + ",市净率:" + PBV + ",股息率:" + GXL +'\n'
#print(info,type(info))
txtFile.writelines(info) eachIms = [rank,code,name,industry,PE,PBV,GXL]
allIms.append(eachIms)
#print(eachIms) #print(allIms)
txtFile.close()
输出结果: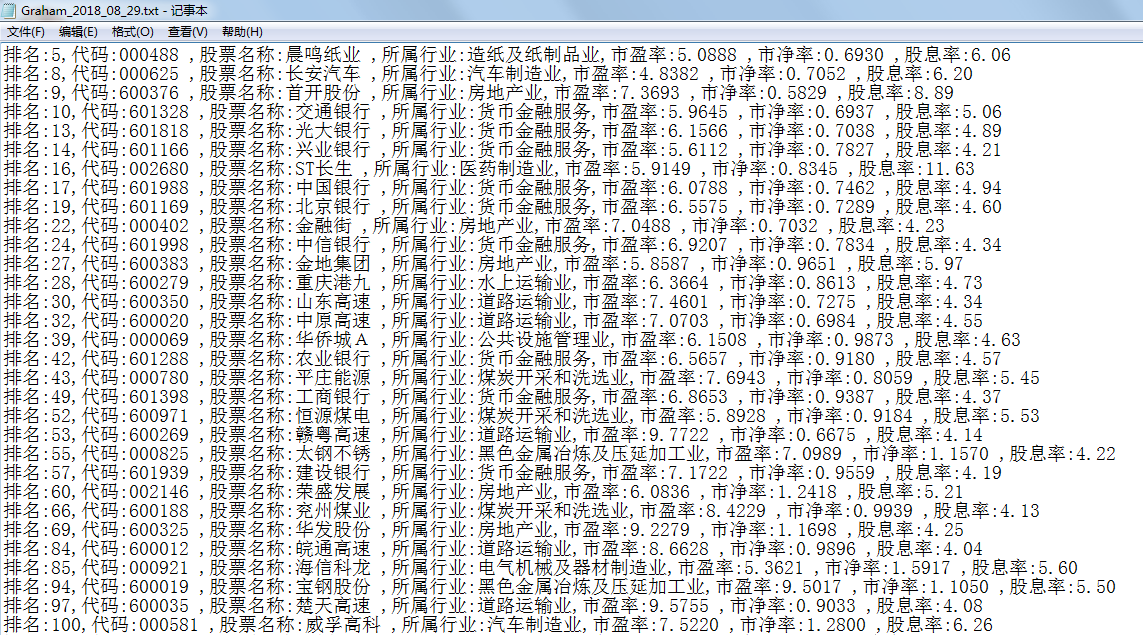
写入excel,python对excel支持的一版,插件对excel版本的支持也略有差别,本次采用xls这个格式,此次无法写覆盖
写入方法就是按照行坐标、列坐标循环写入
#写入excel文件,数据以二维数组的形式存放于allIms中,无法写覆盖
workbook = xlwt.Workbook(encoding='utf-8')# 创建工作簿
# 创建sheet
data_sheet = workbook.add_sheet('格雷厄姆选股票1')#表单的名字而不是excel文件名
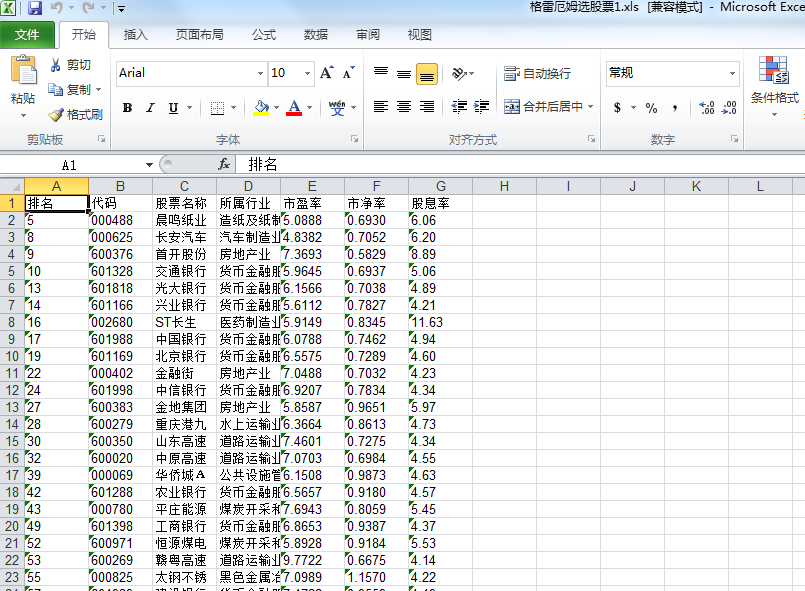
title = ['排名','代码','股票名称','所属行业','市盈率','市净率','股息率']
for j in range(len(title)):#先写入标题行
data_sheet.write(0, j, title[j])
#print(len(allIms),len(title)) for i in range(len(allIms)):#i表示行数
for j in range(len(title)):#j表示列数
data_sheet.write(i+1,j, allIms[i][j])#行坐标、列坐标、数据 workbook.save('格雷厄姆选股票1.xls')#文件名
输出结果:
写入数据库mysql,首先在mysql中新建一个库graham,然后测试python与mysql连通性,这里采用返回数据库版本的形式验证
#测试与mysql中的graham库的连通性
import pymysql
db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8')
cur= db.cursor()#SQLServer的游标
cur.execute("SELECT VERSION()")
data = cur.fetchone()#读一行
print(data)
可以在数据库中创建表单,也可在python中创建,这里我直接在navicat中创建了,python只是写入具体数据
#写入数据库mysql,数据以二维数组的形式存放于allIms中
#提前新建数据graham和字段,字段属性需要与eachIms中的各个属性一致(本程序中均为字符串)
db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8')
cur= db.cursor()#SQLServer的游标
sql="""
INSERT INTO 格雷厄姆选股票1(排名,代码, 股票名称, 所属行业, 市盈率,市净率,股息率)
VALUES (%s,%s,%s,%s,%s,%s,%s)
"""
for i in allIms:
cur.execute(sql,i)#执行数据库相应的语句
db.commit()
db.close()
输出结果:
源代码:
"""
通过理财大视野,获取股票的名称、代码、行业、市净率、市盈率、股息率
并将股息率大于4%的结果分别写入txt、excel和mysql
""" from bs4 import BeautifulSoup
from urllib import request
import time
import xlrd
import xlwt
import pymysql url = "http://www.dashiyetouzi.com/tools/value/Graham.php"
htmlData = request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(htmlData, 'lxml')
#print(soup.prettify())
allData = soup.find("table", {'class': 'datatable'}) time = time.strftime('%Y_%m_%d', time.localtime(time.time()))#获取当前时间年_月_日
filename = "Graham_" + time # Graham格雷厄姆
txtFile = open(filename + ".txt", 'w')
allIms = []
for tr in allData.find_all('tr'):
#eachData是每一行信息(一位数组)
eachData = tr.find_all('td')
#print(eachData)
rank = eachData[0].string#排名
code = eachData[1].find('a').string#代码
name = eachData[2].find('a').string#名称
industry = eachData[3].string#行业
PE = eachData[6].string#市净率
PBV = eachData[7].string#市盈率
#返回类型不一样,get_text()返回的是字符串,末尾有空格。需要先去掉末尾的空格,再去掉百分号
GXL = eachData[-1].get_text().rstrip().strip('%')#股息率 if float(GXL) > 4:
# 写入txt文件,循环写入
info = "排名:" + rank + ",代码:" + code + ",股票名称:" + name + ",所属行业:" + industry + ",市盈率:" + PE + ",市净率:" + PBV + ",股息率:" + GXL +'\n'
#print(info,type(info))
txtFile.writelines(info) eachIms = [rank,code,name,industry,PE,PBV,GXL]#每条股票信息,一位数组
allIms.append(eachIms)#所有股票信息,二维数组通过append()整合
#print(eachIms)
print(allIms)
txtFile.close() #写入excel文件,数据以二维数组的形式存放于allIms中,无法写覆盖
workbook = xlwt.Workbook(encoding='utf-8')# 创建工作簿
# 创建sheet
data_sheet = workbook.add_sheet('格雷厄姆选股票1')#表单的名字而不是excel文件名
title = ['排名','代码','股票名称','所属行业','市盈率','市净率','股息率']
for j in range(len(title)):#先写入标题行
data_sheet.write(0, j, title[j])
#print(len(allIms),len(title)) for i in range(len(allIms)):#i表示行数
for j in range(len(title)):#j表示列数
data_sheet.write(i+1,j, allIms[i][j])#行坐标、列坐标、数据 workbook.save('格雷厄姆选股票1.xls')#文件名 #写入数据库mysql,数据以二维数组的形式存放于allIms中
#提前新建数据graham和字段,字段属性需要与eachIms中的各个属性一致(本程序中均为字符串)
db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8')
cur= db.cursor()#SQLServer的游标
sql="""
INSERT INTO 格雷厄姆选股票1(排名,代码, 股票名称, 所属行业, 市盈率,市净率,股息率)
VALUES (%s,%s,%s,%s,%s,%s,%s)
"""
for i in allIms:
cur.execute(sql,i)#执行数据库相应的语句
db.commit()
db.close()
python3爬取”理财大视野”中的股票,并分别写入txt、excel和mysql的更多相关文章
- python3 爬取简书30日热门,同时存储到txt与mongodb中
初学python,记录学习过程. 新上榜,七日热门等同理. 此次主要为了学习python中对mongodb的操作,顺便巩固requests与BeautifulSoup. 点击,得到URL https: ...
- 1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的, 环境准备: pip install lxml pip install bs4 pip install urllib #!/usr/bin/env pytho ...
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Python3 爬取微信好友基本信息,并进行数据清洗
Python3 爬取微信好友基本信息,并进行数据清洗 1,登录获取好友基础信息: 好友的获取方法为get_friends,将会返回完整的好友列表. 其中每个好友为一个字典 列表的第一项为本人的账号信息 ...
- Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记: 11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国 ...
- python3爬取微博评论并存为xlsx
python3爬取微博评论并存为xlsx**由于微博电脑端的网页版页面比较复杂,我们可以访问手机端的微博网站,网址为:https://m.weibo.cn/一.访问微博网站,找到热门推荐链接我们打开微 ...
- Python 爬虫练习: 爬取百度贴吧中的图片
背景:最近开始看一些Python爬虫相关的知识,就在网上找了一些简单已与练习的一些爬虫脚本 实现功能:1,读取用户想要爬取的贴吧 2,读取用户先要爬取某个贴吧的页数范围 3,爬取每个贴吧中用户输入的页 ...
- python3爬取全民K歌
Python3爬取全民k歌 环境 python3.5 + requests 1.通过歌曲主页链接爬取 首先打开歌曲主页,打开开发者工具(F12). 选择Network,点击播放,会发现有一个请求返回的 ...
随机推荐
- 机器学习框架ML.NET学习笔记【9】自动学习
一.概述 本篇我们首先通过回归算法实现一个葡萄酒品质预测的程序,然后通过AutoML的方法再重新实现,通过对比两种实现方式来学习AutoML的应用. 首先数据集来自于竞赛网站kaggle.com的UC ...
- php文件缓存数据
最近在做微信的摇一摇跑马活动,实现原理是用户摇动手机,通过ajax往数据库写入数据(小马跑的步数),然后PC端用过ajax每一秒钟从数据库中调取一次数据(小马跑的步数),然后显示在PC屏幕上,这样就会 ...
- memcache和iptables开启11211端口
linux下安装完memcached后,netstat -ant | grep LISTEN 看到memcache用的11211端口已在监听状态,但建立php文件连接测试发现没有输出结果,iptabl ...
- webpack.config.js====CSS相关:css和scss配置loader
1. 安装: //loader加载器加载css和sass模块 cnpm install style-loader css-loader node-sass sass-loader --save-dev ...
- Android中的GreenDao框架修改数据库的存储路径
目前android中比较热门的数据库框架有greenDAO.OrmLite.AndrORM,其中我比较喜欢用GreenDao,其运行效率最高,内存消耗最少,性能最佳.具体怎么使用GreenDao,网上 ...
- [dp][uestc oj]J - 男神的约会
J - 男神的约会 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submit ...
- 生成gt数据出问题
使用cout打印uchar类型数据时,打印出来是其相应的ascii码
- 修改Windows默认调试器
程序崩溃时,系统会弹窗让你选择是否进行调试,可以设置系统默认调试器. 注册表位置: HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Windows NT/CurrentVe ...
- mysql5.7.24 解压版安装步骤以及遇到的问题
1.下载 https://dev.mysql.com/downloads/mysql/ 2.解压到固定位置,如D:\MySQL\mysql-5.7.24 3.添加my.ini文件 跟bin同级 [my ...
- 源自http://www.cnblogs.com/sciencefans/p/4394861.html
人脸识别的四大块:Face detection, alignment, verification and identification(recognization),本别代表从一张图中识别出人脸位置, ...