语义分割丨DeepLab系列总结「v1、v2、v3、v3+」
花了点时间梳理了一下DeepLab系列的工作,主要关注每篇工作的背景和贡献,理清它们之间的联系,而实验和部分细节并没有过多介绍,请见谅。
DeepLabv1
Semantic image segmentation with deep convolutional nets and fully connected CRFs
link:https://arxiv.org/pdf/1412.7062v3.pdf
引言
DCNN在像素标记存在两个问题:信号下采用和空间不变性(invariance)
第一个问题是由于DCNN中重复的最大池化和下采样造成分辨率下降,DeepLabv1通过带孔(atrous)算法解决。
第二个问题是分类器获得以对象为中心的决策需要空间不变性,从而限制了DCNN的空间精度,DeepLabv1通过条件随机场(CRF)提高模型捕获精细细节的能力。
DeepLabv1主要贡献
- 速度:带孔算法的DCNN速度可达8fps,全连接CRF平均预测只需0.5s。
- 准确:在PASCAL语义分割挑战中获得第二名。
- 简洁:DeepLab可看作DCNN和CRF的级联。
相关工作
DeepLab有别于two stage的RCNN模型,RCNN没有完全利用DCNN的feature map。
DeepLab和其他SOTA模型的主要区别在于DCNN和CRF的组合。
方法
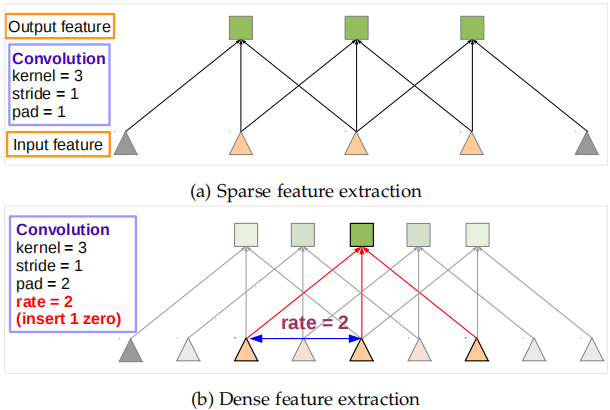
空洞卷积
一维空洞卷积
kernel size=3,Input stride=2,stride=1。
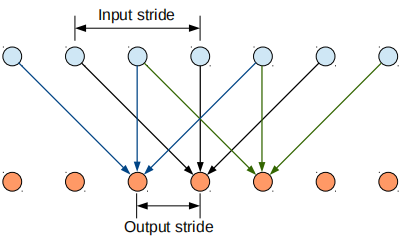
理解空洞卷积
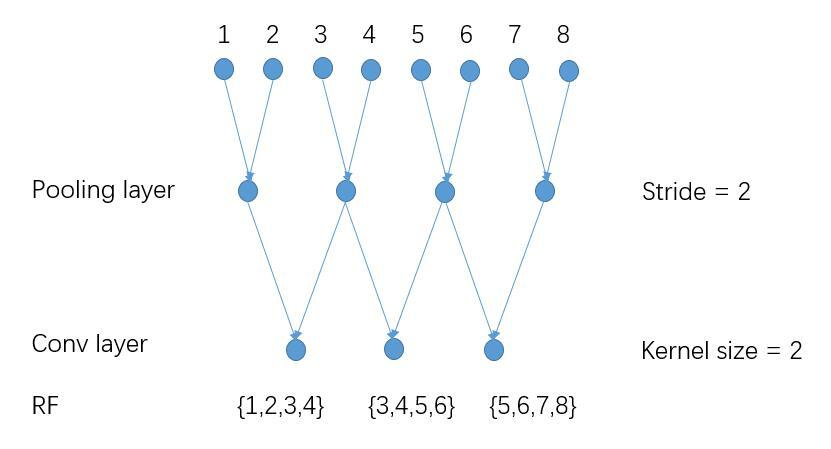
feature map变小主要是由于卷积层和池化层引起的,若另所有层的stride=1,输出feature map将会变大。
原始情况下Pooling layer stride=2,receptive field=4
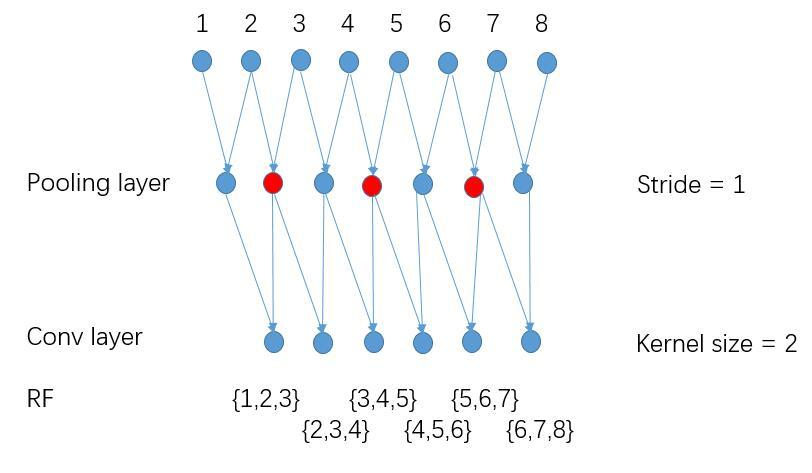
另Pooling layer stride=1,receptive field=3,输出更dense,但感受野变小。
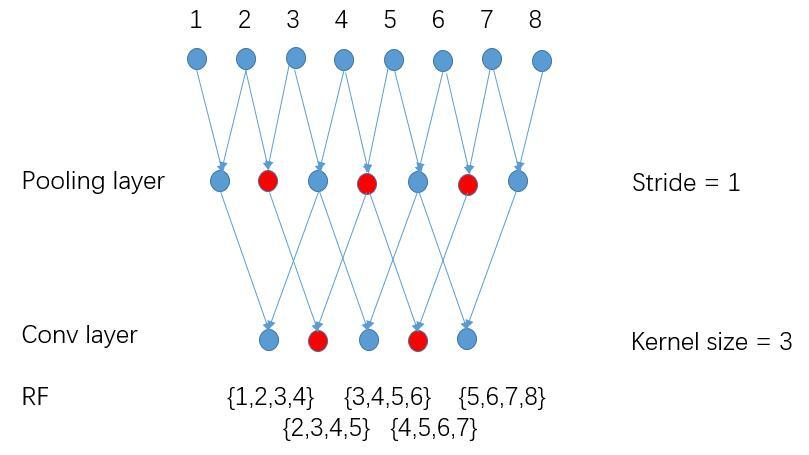
采用空洞卷积后,receptive field=4
跟第一张图相比,在蓝色节点的基础上多了红色节点,在保持感受野使输出更加dense。
条件随机场
全连接CRF模型使用的能量函数\(E(x)\)
\[
E(x)=\sum_i\theta_i(x_i)+\sum_{ij}\theta_{ij}(x_i,y_j)
\]
分为一元势能函数\(\theta_i(x_i)\)和二元势能函数\(\theta_{ij}(x_i,y_j)\)。
一元势能函数\(\theta_i(x_i)\)刻画观测序列对标记变量的影响。
\[
\theta_i(x_i)=-\log P(x_i)
\]
当我们观察到像素点\(i\),\(P(x_i)\)是DCNN计算像素\(i\)的输出标签的分配概率。
二元势能函数\(\theta_{ij}(x_i,y_j)\)刻画变量之间的相关性以及观测序列对其影响,实质是像素之间的相关性。
\[
\theta_{ij} (x_i,y_j)=u(x_i,x_j)\sum^K_{m=1}\omega_m\cdot k^m(f_i,f_j)
\]
当\(x_i\neq x_j\)则\(u(x_i,x_j)=1\),否则为\(0\),因此每个像素对之间都会有值,是全连接的。
\(k^m(f_i,f_j)\)是\((f_i,f_j)\)之间的高斯核,\(f_i\)是像素\(i\)的特征向量,对应的权重为\(\omega_m\),高斯核为:
\[
\omega_1 \exp(\frac{||p_i-p_j||^2}{2\sigma^2_{\alpha}}-\frac{||I_i-I_j||^2}{2\sigma^2_{\beta}})+\omega_2 \exp(-\frac{||p_i-p_j||^2}{2\sigma^2_{\gamma}})
\]
\({\alpha}、\sigma_{\beta}、\sigma_{\gamma}\)控制高斯核的“尺度”。
多尺度预测
多尺度预测有性能提升,但是不如CRF明显。
DeepLabv2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
link:https://arxiv.org/pdf/1606.00915.pdf
引言
DCNN在语义分割中有三个挑战:
(1)特征分辨率下降
(2)存在物体多尺度
(3)由于DCNN的空间不变性使得空间精度下降
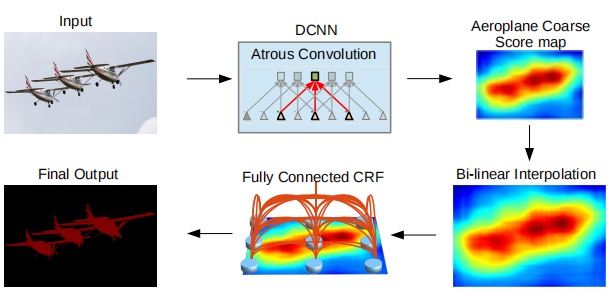
(1)是由于DCNN中的重复池化和下采样降低了空间分辨率,一种方法是采用转置卷积(deconvolutional layer),但是需要额外的空间和计算量。DeepLabv2在最后几个最大池化层用空洞卷积替代下采样,以更高的采样密度计算feature map。
(2)物体存在多尺度,解决该问题的一个标准方法是将图片缩放成不同尺寸,汇总特征得到结果。这种方法可以提高性能,但是增加了计算成本。受SPPNet启发,DeepLabv2提出一个类似结构,对给定输入以不同采样率的空洞卷积进行采样,以多比例捕捉图像上下文,称为ASPP(astrous spatial pyramid pooling)。
(3)分类器要求空间不变性,从而限制了DCNN的空间精度。解决该问题的一个方法是使用跳级结构融合不同层的特征从而计算最终的分割结果。DeepLabv2更高效的方法是采用条件随机场增强模型捕捉细节的能力。
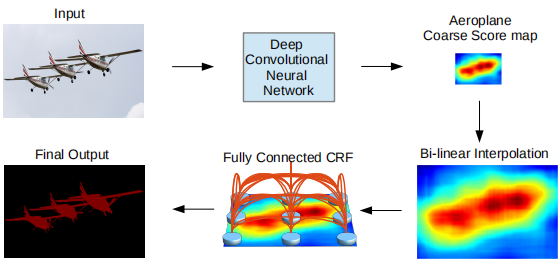
DeepLabv2结构
首先经过采用空洞卷积的DCNN如VGG-16或ResNet101得到粗略的分割结果,然后通过双线性插值将feature map恢复成原图分辨率,最后用全连接的CRF来精细化分割结果。
DeepLabv2贡献
采用多尺度处理和ASPP达到了更好的性能。
在DeepLab基础上将VGG-16换成ResNet,在PASCAL VOC 2012和其他数据上上达到SOTA。
相关工作
语义分割的核心是将分割与分类结合。
语义分割中DCNN模型主要有三类:
(1)采样基于DCNN的自下而上的图像分割级联。
(2)依靠DCNN做密集计算得到预测结果,并将多个独立结果做耦合。
(3)使用DCNN直接做密集的像素级分类。
方法
空洞卷积
一维情况
一维信号,空洞卷积输入\(x[i]\),输出\(y[i]\),长度\(K\)的滤波器为\(\omega[k]\)。
\[
y[i]=\sum^K_{k=1}x[i+r\cdot k]\omega [k]
\]
\(r\)为输入信号的采样步长,标准卷积中\(r=1\)。
二维情况
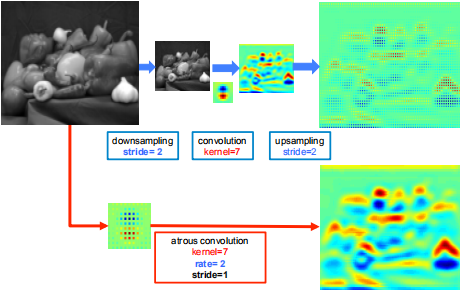
- 首先下采样将分辨率降低2倍,做卷积,再上采样得到结果。本质是和原图的1/4位置做响应。
- 对全分辨率图做\(r=2\)的空洞卷积,直接得到结果。可以计算整张图的响应。
使用空洞卷积可以增大感受野,采样率为\(r\)的空洞卷积插入\(r-1\)个零,将\(k\times k\)的卷积核变为\(k_e=k+(k-1)(r-1)\)而不增加计算量。
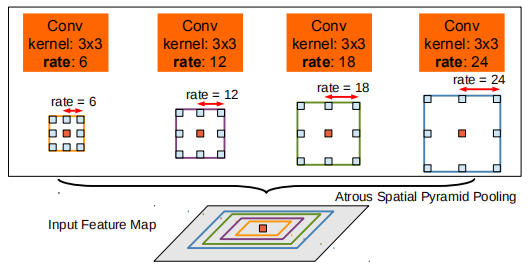
ASPP
并行采用多个采样率的空洞卷积提取特征,再将特征进行融合,该结构称为空洞空间金字塔池化(atrous spatial pyramid pooling)。
条件随机场
同DeepLabv1
DeepLabv3
Rethinking Atrous Convolution for Semantic Image Segmentation
link:https://arxiv.org/pdf/1706.05587.pdf
引言
语义分割中,应用DCNN有两个挑战
1)连续池化或卷积带来的分辨率下降,让DCNN学习更抽象的特征表示。然而,空间不变性会阻碍分割任务,因为其需要详细的空间信息。为了解决该问题,DeepLab引入空洞卷积。
2)物体存在多尺度,有许多方法解决该问题,我们主要考虑四类:
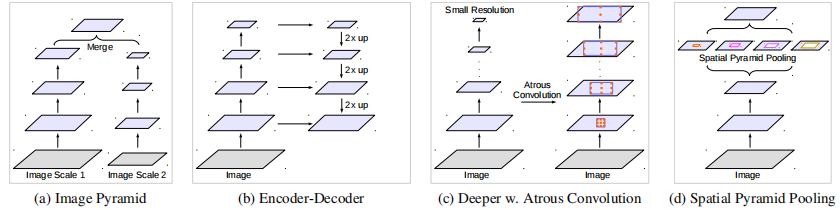
①将DCNN应用于图像金字塔来提取不同尺度输入的特征,将预测结果融合得到最终输出。
②encoder-decoder结构,利用encoder的多尺度特征到解码器上恢复分辨率。
③在原网络的顶端增加额外的模块来捕获长程信息,如DenseCRF。
④SPP空间金字塔池化具有不同采样率和感受野的卷积核,能以多尺度捕获对象。
DeepLabv3的贡献
- 回顾了空洞卷积,在级联模块和金字塔池化框架下也能扩大感受野提取多尺度信息。
- 改进了ASPP:由不同的采样率的空洞卷积和BN层组成,以级联或并行的方式布局。
- 大采样率的\(3\times3\)空洞卷积由于图像边界效应无法捕获长程信息,将退化为\(1\times1\)的卷积,我们建议将图像特征融入ASPP。
- 阐述训练细节和方法。
相关工作
现有多个工作表明全局特征或上下文之间的互相作用有助于做语义分割,我们讨论四种不同类型利用上下文信息做语义分割的全卷积网络。
图像金字塔
同一模型使用共享权重,适用于多尺度输入。
小尺度输入的特征相应编码了长程的语义信息,大尺度输入的特征相应保留了小对象的细节。
该方法通过拉普拉斯金字塔将输入变换成多尺度,并送入DCNN。
主要缺点是由于GPU存储的限制,在更大更深的DCNN上不能很好地拓展,通常其用于测试阶段。
编码器-解码器
该模型主要包含两部分:
1)编码器,该阶段feature map的维度逐渐降低并且深层次的特征容易捕获远程信息。
2)解码器,该阶段恢复物体细节和空间维度。
SegNet、U-Net、RefineNet
上下文模块
模型包含额外的模块来编码远程上下文信息。
DenseCRF
空间金字塔池化
采用SPP来捕获多尺度上下文。
ParseNet、DeepLabv2(ASPP)、PSPNet(PSP)
DeepLabv3提出将空洞卷积作为上下文模块和空间金字塔池化的工具。
方法
回顾空洞卷积如何提取密集特征、讨论空洞卷积模块以级联(串行)和并行布局。
空洞卷积
见DeepLabv1、v2
级联ResNet
将空洞卷积应用于级联结构,在ResNet最后一个block(block4)后连接许多级联模块。
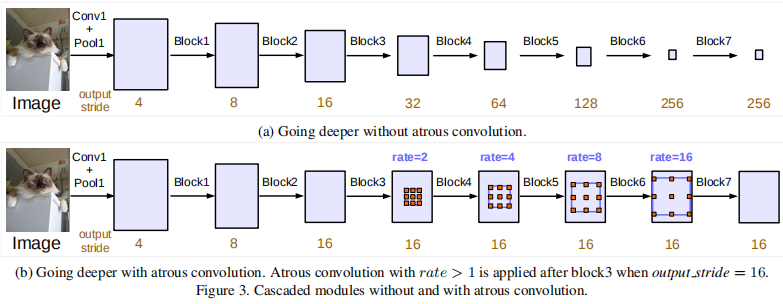
图(a)中整体信息汇聚到非常小的feature map,实验表明其不利于分割。
Multi-grid Method
定义\(Multi\_Gird=(r_1,r_2,r_3)\)为block4到block7三个卷积层的unit rates。则\(rates=2\cdot(1,2,4)=(2,4,8)\)
ASPP+
在ASPP中加入BN层。
当采样率变大,卷积核的有效权重变小。
在\(65\times65\)的feature map上以不同采样率采用\(3\times3\)的卷积核。当采样率接近于feature map尺寸时,\(3\times 3\)退化为\(1\times 1\)卷积核,只有中心的权重是有效的。
为了解决该问题并在模型中整合全局上下文信息,我们对最后的feature map采用全局池化,并经过256个\(1\times1\)的卷积核(BN),然后双线性插值到所需空间维度。
最终ASPP包含
(a)一个\(1\times1\)的卷积和三个\(3\times3、rates=(6,12,18)、output\_stride=16\)的空洞卷积(256+BN)。
(b)图像级特征。将特征做全局平均池化,后卷积,再上采样。
(a)中不同\(rates\)的空洞卷积通过控制不同的\(padding\)输出相同的尺寸,(b)中上采样后与(a)尺寸一致。
所有分支的结果被拼接起来并经过\(1\times1\)的卷积(256+BN),最后经过\(1\times1\)卷积生成分割结果。
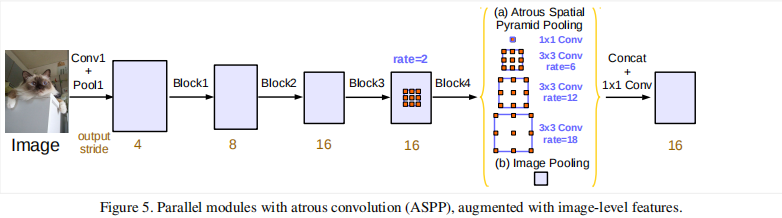
当\(output\_stride=8\),采样率加倍。
DeepLabv3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Link:https://arxiv.org/abs/1802.02611.pdf
引言
语义分割中的DCNN主要有两种结构:空间金字塔池化SPP和编码器-解码器encoder-decoder
SPP通过多种感受野池化不同分辨率的特征来挖掘上下文信息。
Encoder-decoder逐步重构空间信息来更好的捕捉物体的边缘。
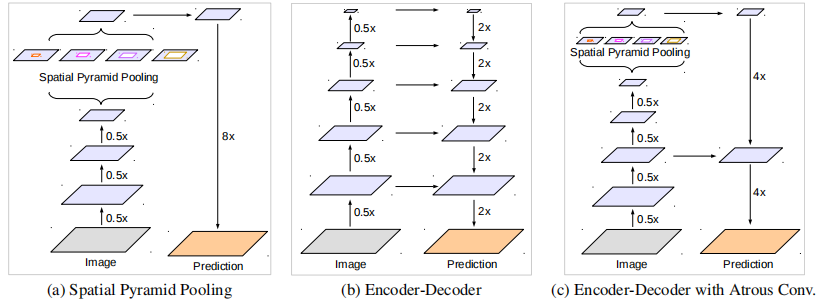
DeepLabv3+对DeepLabv3进行了拓展,在encoder-decoder结构上采用SPP模块。encoder提取丰富的语义信息,decoder恢复精细的物体边缘。encoder允许在任意分辨率下采用空洞卷积。
DeepLabv3+贡献
- 提出一个encoder-decoder结构,其包含DeepLabv3作为encoder和高效的decoder模块。
- encoderdecoder结构中可以通过空洞卷积来平衡精度和运行时间,现有的encoder-decoder结构是不可行的。
- 在语义分割任务中采用Xception模型并采用depthwise separable convolution,从而更快更有效。
相关工作
SPP
收集多尺度信息。
PSPNet、DeepLab
Encoder-decoder
encoder逐渐减小feature map并提取高层语义信息。
decoder逐渐恢复空间信息。
Depthwise separable convolution
深度可分离卷积或group convolution,在保持性能前提下,有效降低了计算量和参数量。
方法
Encoder-Decoder
空洞卷积
该部分见DeepLabv2
\[y[i]=\sum_kx[i+r\cdot k]w[k]\]
深度可分离卷积
深度可分离卷积将标准卷积分解为\(depthwise\ conv\)后跟一个\(pointwise\ conv\),有效地降低了计算复杂度。
\(depthwise\ conv\)对每个输入通道分别进行spatial conv。
\(pointwise\ conv\)合并\(depthwise\ conv\)的输出。
我们提出\(atrous\ separable\ conv\),其在保持性能前提下,有效降低了计算量和参数量。
DeepLabv3作为encoder
令\(output stride\)等于输入图像分辨率和输出分辨率的比值。
图像分类任务,最终的feature map通常比输入图像分辨率小32倍,因此\(output stride=32\)。
语义分割任务,令\(output stride=16 or8\),通过移除最后\(1or2\)个blocks并应用空洞卷积(\(rate=2or4\))来密集提取特征。
在我们的encoder-decoder结构中,采用DeepLabv3最后的feature map作为encoder的输出,包含\(256\)个通道并富含语义信息。此外,可以通过空洞卷积以任意分辨率提取特征,取决于计算量。
decoder
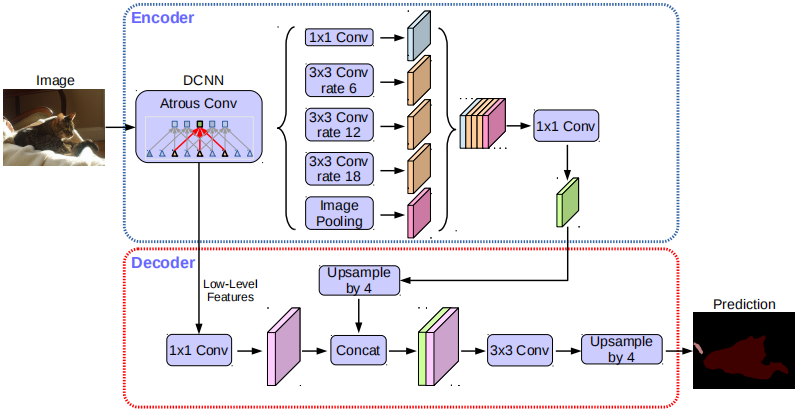
DeepLabv3以\(factor=16\)上采样。
DeepLabv3+首先以\(factor=4\)上采样,然后和尺寸相同的低层特征相拼接。低层特征采用\(1\times 1\)卷积降维,因为低层特征维度一般比较高(\(256or512\)),将占较大权重(我们的模型只有\(256\)),使得训练变困难。拼接之后,我们采用\(3\times 3\)的卷积来细化特征,然后再以\(factor=4\)双线性插值。
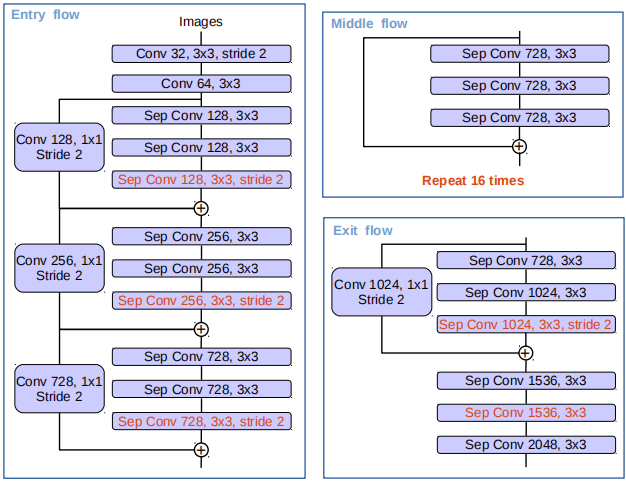
改进 Aligned Xception
Xception模型用于图像分类任务,Aligned Xception用于物体检测任务,我们对Xception做了一些变化使其可用于语义分割任务。
1)更多的层,为了计算量和内存,不对Entry flow网络结构进行修改。
2)所有池化层替换为\(depthwise\ separable\ conv\),以便采用 \(atrous\ separable\ conv\)提取任意分辨率的特征。
3)类似于MobileNet,在每个\(3\times 3\)后添加额外的BN和ReLU。
总结
| DeepLabv1 | DeepLabv2 | DeepLabv3 | DeepLabv3+ | |
|---|---|---|---|---|
| Backbone | VGG-16 | ResNet | ResNet+ | Xception |
| Atrous Conv | √ | √ | √ | √ |
| CRF | √ | √ | × | × |
| ASPP | × | ASPP | ASPP+ | ASPP+ |
| Encoder-decoder | × | × | × | √ |
参考
[1]Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected crfs[J]. arXiv preprint arXiv:1412.7062, 2014.
[2]Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(4): 834-848.
[3]Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
[4]Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 801-818.
[5]https://www.imooc.com/article/35025
[6]http://hellodfan.com/2018/01/22/语义分割论文-DeepLab系列/
[7]https://www.twblogs.net/a/5ca1c085bd9eee59d3326c76/zh-cn
[8]https://zhuanlan.zhihu.com/p/33796585
语义分割丨DeepLab系列总结「v1、v2、v3、v3+」的更多相关文章
- 语义分割丨PSPNet源码解析「测试阶段」
引言 本文接着上一篇语义分割丨PSPNet源码解析「网络训练」,继续介绍语义分割的测试阶段. 模型训练完成后,以什么样的策略来进行测试也非常重要. 一般来说模型测试分为单尺度single scale和 ...
- 语义分割丨PSPNet源码解析「训练阶段」
引言 之前一段时间在参与语义分割的项目,最近有时间了,正好把这段时间的所学总结一下. 在代码上,语义分割的框架会比目标检测简单很多,但其中也涉及了很多细节.在这篇文章中,我以PSPNet为例,解读一下 ...
- 从0开始学习 GITHUB 系列之「向GITHUB 提交代码」【转】
本文转载自:http://stormzhang.com/github/2016/06/04/learn-github-from-zero4/ 版权声明:本文为 stormzhang 原创文章,可以随意 ...
- GitHub 系列之「团队合作利器 Branch」
Git 相比于 SVN 最强大的一个地方就在于「分支」,Git 的分支操作简直不要太方便,而实际项目开发中团队合作最依赖的莫过于分支了,关于分支前面的系列也提到过,但是本篇会详细讲述什么是分支.分支的 ...
- 从0开始学习 GITHUB 系列之「团队合作利器 BRANCH」【转】
本文转载自:http://stormzhang.com/github/2016/07/09/learn-from-github-from-zero6/ 版权声明:本文为 stormzhang 原创文章 ...
- GitHub 系列之「向GitHub 提交代码」
1.SSH 你拥有了一个 GitHub 账号之后,就可以自由的 clone 或者下载其他项目,也可以创建自己的项目,但是你没法提交代码.仔细想想也知道,肯定不可能随意就能提交代码的,如果随意可以提交代 ...
- GitHub 系列之「怎样使用 GitHub?」
1.写在前边的话,为什么要写CitHub? 跟朋友在交流的时候听到求职的时候发现有些公司要附Github帐号,一个优秀的 GitHub 账号当然能让你增色不少.自己之前听说过,但没有花时间研究,最后花 ...
- 🏆【Alibaba微服务技术系列】「Dubbo3.0技术专题」回顾Dubbo2.x的技术原理和功能实现及源码分析(温故而知新)
RPC服务 什么叫RPC? RPC[Remote Procedure Call]是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范.它允许程序调用另一个地址空间(通常是共享网络的另 ...
- 从0開始学习 GitHub 系列之「07.GitHub 常见的几种操作」
之前写了一个 GitHub 系列,反响非常不错,突然发现居然还落下点东西没写,前段时间 GitHub 也改版了,借此机会补充下. 我们都说开源社区最大的魅力是人人多能够參与进去,发挥众人的力量,让一个 ...
随机推荐
- YCSB-mapkeer-leveldb实测
使用thrift0.8.0编译好java版的mapkeeper并安装到ycsb下,使用thrift0.9.2编译好c++版的mapkeeper并编译leveldb客户端运行. 测试成功.recordc ...
- requireJS 加载css、less文件
-- requireJS 同样可以加载css 文件,有require-css的插件,只需要把插件放入main.js同文件夹,在依赖处 采用 ‘css! test.css’的形式就可以加载css文件 - ...
- idea提交新项目到远程git创库
1.创建远程版本库 http://192.168.28.130:81 登陆用户:maohx/123456 版本库名称最后与本地项目名称一致 如:spring-cloud-demo 2.创建本地版本库 ...
- BZOJ_2216_[Poi2011]Lightning Conductor_决策单调性
BZOJ_2216_[Poi2011]Lightning Conductor_决策单调性 Description 已知一个长度为n的序列a1,a2,...,an. 对于每个1<=i<=n, ...
- ubuntu16.04 跑Apollo Demo
1.安装docker(参考网址:https://docs.docker.com/install/linux/docker-ce/ubuntu/) Uninstall old versions Olde ...
- DIY一个DNS查询器:程序实现
上一篇文章<DIY一个DNS查询器:了解DNS协议>中讲了DNS查询协议的原理和数据结构.经过两个星期的开发,完成了该查询器的编写.期间也遇到了一些问题,如: 1资源记录(Resource ...
- 基于WinDbg的内存泄漏分析
在前面C++中基于Crt的内存泄漏检测一文中提到的方法已经可以解决我们的大部分内存泄露问题了,但是该方法是有前提的,那就是一定要有源代码,而且还只能是Debug版本调试模式下.实际上很多时候我们的程序 ...
- Nagios监控Windows的网卡流量
Nagios监控Windows的网卡流量 使用/usr/local/nagios/libexec/中的check_traffic.sh,不但可以监控Linux的网卡流量,也可以监控Windows服务器 ...
- bzoj4827
FFT+数学 先开始觉得枚举c就行了,不过我naive了 事实上c是确定的,通过化简式子可以得出一个二次函数,那么c就可以解出来了. 然后把a翻转,fft一下就行了 难得的良心题 #include&l ...
- vscode实现列编辑
ctrl + shift + 左键选择要编辑的列 好用,再也不用使用\n替换了