Hibernate总结(转)
原文:http://blog.csdn.net/yuebinghaoyuan/article/details/7300599
那我们看一下hibernate中整体的内容:
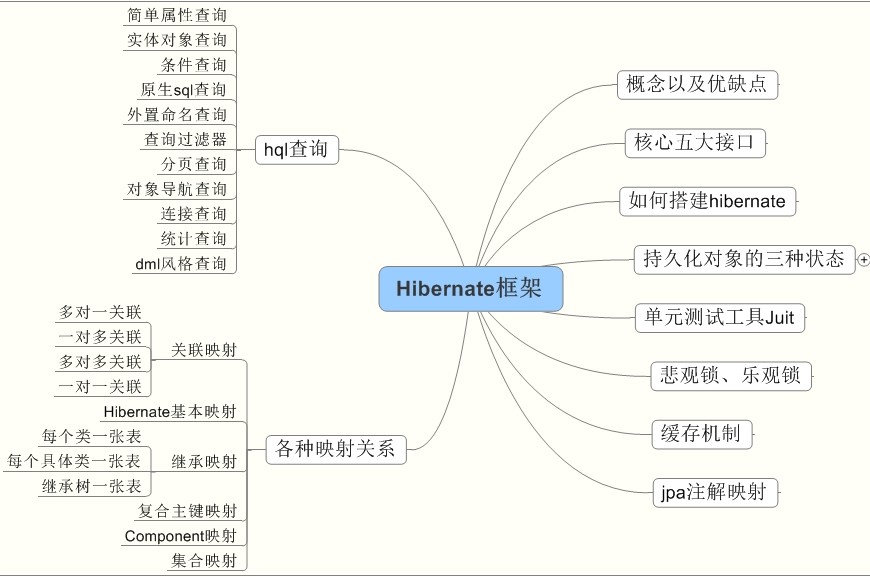
我们一一介绍其中的内容。
- Hibernate出现的原因上篇博客已经介绍,可以参考《Hibernate介绍》
- Hibernate中的核心五大接口,在上篇博客中也已经介绍,可以参考《Hibernate介绍》
- 如何搭建Hibernate,请参考《八步详解Hibernate的搭建及使用》
- 持久化对象的三种状态。
分别为:瞬时状态(Transient),持久化状态(Persistent),离线状态(Detached)。三种状态下的对象的生命周期如下:

三种状态的区别是:瞬时状态的对象:没有被session管理,在数据库没有;持久化状态的对象:被session管理,在数据库存在,当属性发生改变,在清理缓存时,会自动和数据库同步;离线状态:没有被session管理,但是在数据库中存在。
5.测试工具Juit。
测试类需要继承TestCase,编写单元测试方法,方法名称必须为test开头,方法没有参数没有返回值,采用public修饰。其中在测试中,查询对象时,使用get或者load两种方法进行加载,这种方法的区别:get不支持延迟加载,而load默认情况下是支持延迟加载。并且get查询对象不存在时,返回null;而load查询对象不存在时,则抛出ObjectNotFoundException异常。
6.悲观锁和乐观锁解释。
悲观锁为了解决并发性,跟操作系统中的进程中添加锁的概念一样。就是在整个过程中在事务提交之前或回滚之前,其他的进程是无法访问这个资源的。悲观锁的实现方式有两种:一种使用数据库中的独占锁;另一种是在数据库添加一个锁的字段。hibernate中声明锁如下:
Account account = (Account)session.get(Account.class, 1, LockMode.UPGRADE);而net.sf.hibernate.LockMode类表示锁模式,当取值LockMode.UPGRADE时,则表示使用悲观锁for update;而乐观锁是为了解决版本冲突的问题。就是在数据库中添加version字段,每次更新时,则把自己的version与数据库中的version进行比较,若是版本相比较低,则不允许进行修改更新。
7.H ibernate中的缓存机制。
缓存是什么呢?缓存是应用程序和数据库之间的内存的一片区域。主要的目的是:为了减少对数据库读取的时间。当查询数据时,首先在缓存中查询,若存在,则直接取出,若不存在,然后再向数据库中查询。所以应该把经常访问数据库的数据放到缓存中,至于缓存中的数据如何不断的置换,这也需要涉及一种淘汰数据的算法。
谈到这个hibernate中的缓存,你想到了什么呢?刚才叙述缓存时,是否感觉很熟悉,感觉从哪也听过似的。嗯呢,是呢,是很熟悉,写着写着就很熟悉,这个刚才的缓存以及缓存的置换算法就和计算机组成中的cache类似。
好吧,来回到我们hibernate中的缓存。
hibernate中的缓存可以分为两种:一级缓存,也称session缓存;二级缓存,是由sessionFactory管理。
那一级缓存和二级缓存有什么区别呢?区别的关键关于:缓存的生命周期,也就是缓存的范围不同。
那首先介绍一下缓存的生命周期,也就是缓存的范围。
1.事务缓存,每个事务都有自己的缓存,当事务结束,则缓存的生命周期同样结束,正如上篇博客中我们提到,对数据库的操作,增删改查都是放到事务中的,和事务保持同步,若是事务提交完毕,一般是不允许是再次对数据库进行操作。所以session是属于事务缓存的。
2.应用缓存,一个应用程序中的缓存,也就是应用程序中的所有事务的缓存。只有当应用程序结束时,此时的缓存的额生命周期结束。二级缓存就是应用缓存。
3.集群缓存,被一台机器或多台机器的进程共享。
这下明白了一级缓存和二级缓存的区别了吧。那一级缓存和二级缓存的共同点是:都是缓存实体属性,
二级缓存一般情况都是由第三方插件实现的。第三方插件如:
EHCache,JbossCache(是由Jboss开源组织提供的),osCache(open symphony),swarmCache。前三种对hibernate中的查询缓存是支持的,后一种是不支持hibernate查询缓存。
那什么是hibernate查询缓存呢?
查询缓存是用来缓存普通属性的,对于实体对象而言,是缓存实体对象的id。
8.hql查询。
Hibernate query language。hql查询中关键字不区分大小写,但是类和属性都是区分大小写的。
1.简单属性查询。
单一属性查询,返回属性结果集列表,元素类型和实体类的相应的类型一致。
- List students = session.createQuery("select name from Student").list();
- for (Iterator iter=students.iterator(); iter.hasNext();) {
- String name = (String)iter.next();
- System.out.println(name);
- }
//返回结果集属性列表,元素类型和实体类中的属性类型一致
多个属性查询,多个属性查询返回数组对象,对象数组的长度取决于属性的个数,对象数组中的元素类型与实体类中属性一致。
- List students = session.createQuery("select id, name from Student").list();
- for (Iterator iter=students.iterator(); iter.hasNext();) {
- Object[] obj = (Object[])iter.next();
- System.out.println(obj[0] + ", " + obj[1]);
- }
2.实体对象查询
List students = session.createQuery("from Student").list();
当然这种hql语句,可以使用别名,as可以省去,如:from Student as s,若是使用select关键字,则必须使用别名。如:select s from Student as s.但是不支持select * from Student格式。
查询中使用list和Iterate区别:
list查询是直接运行查询的结果,所以只有一句sql语句。而iterate方法则有可能会产生N+1条sql语句。这是怎么回事呢?要理解N+1条语句,首先得弄明白iterate是如何执行查询的?
首先发出一条查询对象ID的语句,然后根据对象的ID到缓存(缓存的概念上篇博客已经提到)中查找,若是存在查询出此对象的其他的属性,否则会发出N条语句,此时的N语句,是刚才第一次查询的记录条数。这种现象就是N+1sql语句。
其中list是默认情况下都发出sql语句,查询出的结果会放到缓存中,但是它不会利用缓存,即使放进去,下次执行时,仍然继续发出sql语句。
而:iterate默认情况下会利用缓存,若是缓存中有则不会发出N+1条语句。
3.条件查询。
这种方式就是传入参数,使用参数占位符“?”。也可以使用“:参数名”
java代码如下:
- List students = session.createQuery("select s.id, s.name from Student s where s.name like ?")
- .setParameter(0, "%0%")
- .list();
- List students = session.createQuery("select s.id, s.name from Student s where s.name like :myname")
- .setParameter("myname", "%0%")
- .list();
4.使用原生sql语句。
和咱们原先写入的sql语句一样。在此不介绍了。
5.外置命名查询。
这个听起来有点晦涩,怎么理解呢?其实通俗的说就是把hql语句写在外面,写在映射文件中。使用标签:
- <query name="queryStudent">
- <![CDATA[
- select s from Student s where s.id <?
- ]]>
- </query>
那在程序中是如何使用此标签的呢?使用session.getNameQuery(),并进行赋值,代码如下:
- List students = session.getNamedQuery("queryStudent")
- .setParameter(0, 10)
- .list();
6.查询过滤器。
这个是什么意思呢?过滤器大家很熟悉吧,不熟悉的可以参考我的以前博客<>.原来我们接触过编码过滤器,编码过滤器就是为了避免当时每个页面需要设置编码格式而提出的。这个查询过滤器其实也是这个意思。若是代码都需要某一句sql语句的话,可以考虑使用它。这样可以避免每次都写查询语句。
使用如下:首先在映射文件中配置标签:
- <filter-def name="testFilter">
- <filter-param type="integer" name="myid"/>
- </filter-def>
然后程序中如下使用并进行赋值:
- session.enableFilter("testFilter")
- .setParameter("myid", 10);
7.分页查询。
分页查询,这个肯定不陌生,因为在做drp项目时,做的最多的是分页,当时使用oracle数据库,分页查询涉及到三层嵌套。直接传入的参数为:每页的大小(记录数),页号。
Hibernate中给我们已经封装好了,只要设置开始的页号以及每页的大小即可,不用亲自动手写嵌套的sql语句。
代码如下:
- List students = session.createQuery("from Student")
- .setFirstResult(1)
- .setMaxResults(2)
- .list();
8.对象导航查询。
这个什么意思呢?这个只要是用于一个类的属性是另一个类的引用。比如:student类中有一个classes属性。其中的classes也是一个类Class的引用。
当我们查询的时候可以这样使用:
- List students = session.createQuery("from Student s where s.classes.name like '%t%'")
- .list();
相当于:s.getClasses.getName(),直接使用get后面的属性,然后首字母小写。
这种语法,是不是很熟悉?想想我们在哪是不是也用过?想起来了吗?估计你猜出来啦,呵呵,是JSTL(jsp standard tag library)中。若是想进一步了解,可以参考我的博客哈,当时是转载滴貌似。
9.连接查询。
连接分为:内连接和外连接,其中外连接分为左连接,右连接,完全连接。这个跟数据库中的左右连接其实是一样的。我们通俗解释一下:
左连接:以左边为准,右边即使没哟匹配的,也要把这条记录查询出来,此时没有匹配的右边以null填充。
右连接:以右边为准,左边即使没有匹配的,也要把这条记录查询出来,此时没有匹配的左边以null填充。
完全连接:只要一方存在即可。
内连接:必须两方都存在才可以查询提取此记录。
10.统计查询。
其实就是查询count的记录数。其中查询出来的额count是long类型。
11.DML风格的操作。
DML?其实DML=Data Manipulate Language(数据操作语言),举个例子:
- session.createQuery("update Student s set s.name=? where s.id<?")
- .setParameter(0, "王斌")
- .setParameter(1, 2)
- .executeUpdate();
假若原来的名字是:李四,更新完数据库后变成王斌,若是我们此时取出数据,其姓名是李四还是王斌?按照道理应该是王斌,但是结果确实李四,若不信,可以自己去实践一下。
这个原因,是因为更新了数据库,但是缓存中没有更新,才会造成这种数据库和缓存不同步的问题。
所以,我们应该尽量不使用这种形式。扬其长避其短嘛。
Hibernate总结(转)的更多相关文章
- hibernate多对多关联映射
关联是类(类的实例)之间的关系,表示有意义和值得关注的连接. 本系列将介绍Hibernate中主要的几种关联映射 Hibernate一对一主键单向关联Hibernate一对一主键双向关联Hiberna ...
- 解决 Springboot Unable to build Hibernate SessionFactory @Column命名不起作用
问题: Springboot启动报错: Caused by: org.springframework.beans.factory.BeanCreationException: Error creati ...
- hibernate多对一双向关联
关联是类(类的实例)之间的关系,表示有意义和值得关注的连接. 本系列将介绍Hibernate中主要的几种关联映射 Hibernate一对一主键单向关联Hibernate一对一主键双向关联Hiberna ...
- Hibernate中事务的隔离级别设置
Hibernate中事务的隔离级别,如下方法分别为1/2/4/8. 在Hibernate配置文件中设置,设置代码如下
- Hibernate中事务声明
Hibernate中JDBC事务声明,在Hibernate配置文件中加入如下代码,不做声明Hibernate默认就是JDBC事务. 一个JDBC 不能跨越多个数据库. Hibernate中JTA事务声 ...
- spring applicationContext.xml和hibernate.cfg.xml设置
applicationContext.xml配置 <?xml version="1.0" encoding="UTF-8"?> <beans ...
- [原创]关于Hibernate中的级联操作以及懒加载
Hibernate: 级联操作 一.简单的介绍 cascade和inverse (Employee – Department) Casade用来说明当对主对象进行某种操作时是否对其关联的从对象也作类似 ...
- hibernate的基本xml文件配置
需要导入基本的包hibernate下的bin下的required和同bin下optional里的c3p0包下的所有jar文件,当然要导入mysql的驱动包了.下面需要注意的是hibernate的版本就 ...
- Maven搭建SpringMVC+Hibernate项目详解 【转】
前言 今天复习一下SpringMVC+Hibernate的搭建,本来想着将Spring-Security权限控制框架也映入其中的,但是发现内容太多了,Spring-Security的就留在下一篇吧,这 ...
- 1.Hibernate简介
1.框架简介: 定义:基于java语言开发的一套ORM框架: 优点:a.方便开发; b.大大减少代码量; c.性能稍高(不能与数据库高手相比,较一般数据库使用者 ...
随机推荐
- QQ客服代码,支持临时会话
<a target="_blank" href="http://wpa.qq.com/msgrd?v=3&uin=QQ号&site=qq&m ...
- php set_time_limit(0) 设置程序执行时间的函数
一个简单的例子,在网页里显示1500条语句,如果未设置失效时间,则程序执行到791时结束了,如果把 set_time_limit(0); 前的注释符//去除,则程序直到1才结束. set_time ...
- spring boot--日志、开发和生产环境切换、自定义配置(环境变量)
Spring Boot日志常用配置: # 日志输出的地址:Spring Boot默认并没有进行文件输出,只在控制台中进行了打印 logging.file=/home/zhou # 日志级别 debug ...
- Requery,Refresh,Adoquery.Close,Open 区别
经过测试发现: Requery 相当于 Adq.Close,Open:并且比Close,Open方法有个优点就是不丢失排序,Sort Adq.Close,Open 后,原来的 Adq.Sort 会丢失 ...
- Python Challenge 第四关
进入了第四关.只有一张图,我还是像往常一样查看源代码.果然,发现了一行注释:urllib may help. DON'T TRY ALL NOTHINGS, since it will never e ...
- 小程序-支持的最小像素px
经过我手机多次测试,支持的最小px为: 8px;
- js-在url后面添加时间戳清除浏览器打开页面的缓存
这个解决办法还是在网上搜出来的,我还没有测试呢: 我有想既然可以添加时间戳,那可以添加随机数吗?我感觉是可以的,尽管没有测试过. 2018-3-13 几天前我就这个问题询问过我们的后台,加时间戳能否真 ...
- UVA 10635 Prince and Princess【LCS 问题转换为 LIS】
题目链接: http://acm.hust.edu.cn/vjudge/problem/visitOriginUrl.action?id=19051 题意: 有两个长度分别为p+1和q+1的由1到n2 ...
- 优雅的使用ImageGetter
https://daihanglin.github.io/2017/10/13/imageGetter/ 1. 使用ImageGetter的场景 Android中用于显示文本的控件为textVie ...
- BZOJ 2085 [POI2010] Hamsters
题面 Description Tz养了一群仓鼠,他们都有英文小写的名字,现在Tz想用一个字母序列来表示他们的名字,只要他们的名字是字母序列中的一个子串就算,出现多次可以重复计算.现在Tz想好了要出现多 ...