GA求解TSP
遗传算法中包含了如下5个基本要素:
(1)对参数进行编码;
(2)设定初始种群大小;
(3)适应度函数的设计;
(4)遗传操作设计;
(5)控制参数设定(包括种群大小、最大进化代数、交叉率、变异率等)。
下面使用python编程对中国28个省会城市的TSP问题进行了求解,python的版本是2.7.14。百度地图提供了JavaScript API,能够很方便地获取各城市之间的路径距离。这里有一段获取28个城市之间距离的JS代码,将其复制到百度地图JavaScript API的一些示例网页上,然后点击运行,再点击右侧相应的按钮即可获取各城市之间的距离。
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<style type="text/css">
body, html{width: 100%;height: 100%;overflow: hidden;margin:0;font-family:"微软雅黑";}
#l-map{height:100px;width:100%;}
#r-result{width:100%; font-size:1px;line-height:12px;}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak=您的密钥"></script>
<title>计算驾车时间与距离</title>
</head>
<body>
<div id="l-map"></div>
<div id="r-result">
<input type="button" value = "计算各省会城市间距离矩阵" onclick = "getCityDistance()" />
<div id="result"></div>
</div>
</body>
</html>
<script type="text/javascript">
// 百度地图API功能
var map = new BMap.Map("l-map");
map.centerAndZoom(new BMap.Point(116.404, 39.915), 5);
var city = [
"北京", "长春", "沈阳", "哈尔滨", "石家庄", "济南",
"呼和浩特", "太原", "郑州", "南京", "上海", "杭州",
"福州", "南昌", "武汉", "合肥", "长沙", "广州",
"重庆", "西安", "海口", "贵阳", "昆明", "成都",
"兰州", "西宁", "拉萨", "乌鲁木齐"
]; var i = 0, j = 1; function getCityDistance()
{
setInterval(getCityDistance1, 6000);
} function getCityDistance1()
{
if(i >= city.length - 1)
{
return;
}
var output = "";
city1 = city[i];
city2 = city[j];
var searchComplete = function (results)
{
if(transit.getStatus() != BMAP_STATUS_SUCCESS)
{
return ;
}
var plan = results.getPlan(0);
output += plan.getDistance(false) + ", "; //获取距离
document.getElementById("result").innerHTML += output;
}
var transit = new BMap.DrivingRoute(
map,
{renderOptions: {map: map, autoViewport: false}, onSearchComplete: searchComplete, onPolylinesSet: function(){}}
); transit.search(city1, city2); j++;
if(j >= city.length)
{
i++;
j = i + 1;
} }
</script>
第一步,初始化种群
# 创造生命集
for i in range(self.life_count):
self.lives.append(Life(self.make_life()))
# 创造新生命
def make_life(self):
lst = range(self.gene_length)
# 随机顺序
random.shuffle(lst)
return lst
第二步,计算个体适应度
使用每个个体对应的路线总长度的倒数作为个体的适应度,也就是每个个体的得分
# 评价函数
def judge(self):
self.bounds = 0.0
self.best = Life()
self.best.setScore(-1.0)
for lf in self.lives:
lf.score = 1.0/self.distance(lf.gene)
if lf.score > self.best.score:
self.best = lf
self.bounds += lf.score
# 得到当前顺序下连线总长度
def distance(self, order):
distance = 0
for i in range(-1, self.gene_length - 1):
i1, i2 = order[i], order[i + 1]
distance += self.get_city_distance(self.dist_matrix, self.gene_length, i1, i2)
return distance
第三步,更新种群
(1)将种群中适应度最高(得分最高)的个体加入下一代种群中
(2)从种群中选择一些个体用于产生下一代,每个个体被选到的可能性与它的得分成正比。选择概率计算方式为

(3)从种群中选择两个个体后,以一定的概率进行交叉。交叉的方法为:从第二个个体基因的前段截取一段随机长度的基因接到第一个个体基因的前面,然后剔除其与截取基因段中重复的元素,最终得到一个新的基因
(4)以一定的概率对第(3)步得到的基因进行变异。变异的方法为:从基因中随机选取两个位置,将这两个位置的元素互换,并将其中一个元素转移到基因的末尾
(5)重复(2)到(4),直到产生的新个体数与原种群个体数相同为止
# 演化至下一代
def next(self):
# 评估群体
self.judge()
# 新生命集
newLives = []
# 将最好的父代加入竞争
newLives.append(Life(self.best.gene))
# 产生新的生命集个体
while(len(newLives) < self.life_count):
newLives.append(self.bear())
# 更新新的生命集
self.lives = newLives
self.generation += 1
# 产生后代
def bear(self):
lf1 = self.get_onelife()
lf2 = self.get_onelife()
# 交叉
r = random.random()
if r < self.overlapping_rate:
gene = self.overlapping_func(lf1, lf2)
else:
gene = lf1.gene
# 突变
r = random.random()
if r < self.mutation_rate:
gene = self.mutation_func(gene)
self.mutation_count += 1
# 返回生命体
return Life(gene)
# 根据得分情况,随机取得一个个体,机率正比于个体的score属性
def get_onelife(self):
# 轮盘
r = random.uniform(0, self.bounds)
for lf in self.lives:
r -= lf.score;
if r <= 0:
return lf
# 交叉函数:选择lf2序列前子序列交叉到lf1前段,删除重复元素
def overlapping_func(self, lf1, lf2):
p2 = random.randint(1, self.gene_length - 1)
# 截取if2
g1 = lf2.gene[0:p2] + lf1.gene
g11 = []
for i in g1:
if i not in g11:
g11.append(i)
return g11
# 变异函数:选择两个不同位置基因交换,第一个选择的基因重新加入到序列尾端
def mutation_func(self, gene):
p1 = random.randint(0, self.gene_length - 1)
p2 = random.randint(0, self.gene_length - 1)
while p2 == p1:
p2 = random.randint(0, self.gene_length - 1)
gene[p1], gene[p2] = gene[p2], gene[p1]
gene.append(gene[p2])
del gene[p2]
return gene
完整的代码如下
# -*- coding: utf-8 -*- import random
import math class Life(object): # 初始化
def __init__(self, gene = None):
self.gene = gene
self.score = -1.0 # 设置评估分数
def setScore(self, v):
self.score = v #----------- TSP问题 -----------
class MyTSP(object): # 初始化
def __init__(self, gene_length = 28, overlapping_rate = 0.7, mutation_rate = 0.03, life_count = 30, max_iteration = 4000): self.overlapping_rate = overlapping_rate # 交叉率
self.mutation_rate = mutation_rate # 突变率
self.mutation_count = 0 # 突变次数
self.generation = 0 # 进化代数
self.lives = [] # 生命集合
self.bounds = 0.0 # 得分总数
self.best = None # 种群每代中的最优个体
self.best_gene = [] # 所有代种群中的最优基因
self.best_gene_distance = 1e20 # 所有代种群中的最优基因所对应的路径长度
self.life_count = life_count # 生命个数
self.gene_length = gene_length # 基因长度,此处即为城市个数
self.max_iteration = max_iteration
self.min_distance = [] # 创造生命集
for i in range(self.life_count):
self.lives.append(Life(self.make_life())) # 读取各城市间的距离
with open('distance.txt', 'r') as f:
data = f.read()
data = data.replace(",", "")
odom = data.split()
self.dist_matrix = map(float, odom) print self.lives[6].gene
print self.distance(self.lives[6].gene) # 进化计算
def evolve(self):
while self.generation < self.max_iteration:
# 下一步进化
self.next()
self.min_distance.append(self.distance(self.best.gene))
if self.distance(self.best.gene) < self.best_gene_distance:
self.best_gene_distance = self.distance(self.best.gene)
self.best_gene = self.best.gene
if self.generation % 200 == 0:
print("迭代次数:%d, 变异次数%d, 最佳路径总距离:%d" % (self.generation, self.mutation_count, self.distance(self.best.gene)))
print self.best_gene
print self.best_gene_distance
return # 创造新生命
def make_life(self):
lst = range(self.gene_length)
# 随机顺序
random.shuffle(lst)
return lst # 演化至下一代
def next(self):
# 评估群体
self.judge()
# 新生命集
newLives = []
# 将最好的父代加入竞争
newLives.append(Life(self.best.gene))
# 产生新的生命集个体
while(len(newLives) < self.life_count):
newLives.append(self.bear())
# 更新新的生命集
self.lives = newLives
self.generation += 1 # 评价函数
def judge(self):
self.bounds = 0.0
self.best = Life()
self.best.setScore(-1.0)
for lf in self.lives:
lf.score = 1.0/self.distance(lf.gene)
if lf.score > self.best.score:
self.best = lf
self.bounds += lf.score # 得到当前顺序下连线总长度
def distance(self, order):
distance = 0
for i in range(-1, self.gene_length - 1):
i1, i2 = order[i], order[i + 1]
distance += self.get_city_distance(self.dist_matrix, self.gene_length, i1, i2)
return distance def get_city_distance(self, dist_matrix, n, i, j):
if i == j:
return 0
elif i > j:
i, j = j, i
return dist_matrix[i * (2 * n - i - 1)/2 + j - i - 1] # 产生后代
def bear(self):
lf1 = self.get_onelife()
lf2 = self.get_onelife()
# 交叉
r = random.random()
if r < self.overlapping_rate:
gene = self.overlapping_func(lf1, lf2)
else:
gene = lf1.gene
# 突变
r = random.random()
if r < self.mutation_rate:
gene = self.mutation_func(gene)
self.mutation_count += 1
# 返回生命体
return Life(gene) # 根据得分情况,随机取得一个个体,机率正比于个体的score属性
def get_onelife(self):
# 轮盘
r = random.uniform(0, self.bounds)
for lf in self.lives:
r -= lf.score;
if r <= 0:
return lf # 交叉函数:选择lf2序列前子序列交叉到lf1前段,删除重复元素
def overlapping_func(self, lf1, lf2):
p2 = random.randint(1, self.gene_length - 1)
# 截取if2
g1 = lf2.gene[0:p2] + lf1.gene
g11 = []
for i in g1:
if i not in g11:
g11.append(i)
return g11 # 变异函数:选择两个不同位置基因交换,第一个选择的基因重新加入到序列尾端
def mutation_func(self, gene):
p1 = random.randint(0, self.gene_length - 1)
p2 = random.randint(0, self.gene_length - 1)
while p2 == p1:
p2 = random.randint(0, self.gene_length - 1)
gene[p1], gene[p2] = gene[p2], gene[p1]
gene.append(gene[p2])
del gene[p2]
return gene import matplotlib.pyplot as plt overlapping_rate = [0.1, 0.2, 0.3, 0.4, 0.5, 0.7, 0.8, 0.9, 1.0]
mutation_rate = [0.005, 0.01, 0.03, 0.05, 0.07, 0.1, 0.2, 0.4, 0.7, 1.0]
life_count = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
yy = [] for i in range(len(overlapping_rate)):
tsp = MyTSP(gene_length = 28, overlapping_rate = overlapping_rate[i], mutation_rate = 0.03, life_count = 30, max_iteration = 40)
tsp.evolve()
yy.append(tsp.best_gene_distance)
plt.figure('overlapping rate and minimum distance')
plt.plot(overlapping_rate, yy)
plt.xlabel('overlapping rate')
plt.ylabel("minimum distance of all generations") yy = []
for i in range(len(mutation_rate)):
tsp = MyTSP(gene_length = 28, overlapping_rate = 0.7, mutation_rate = mutation_rate[i], life_count = 30, max_iteration = 40)
tsp.evolve()
yy.append(tsp.best_gene_distance)
plt.figure("mutation rate and minimum distance")
plt.plot(mutation_rate, yy)
plt.xlabel('mutation rate')
plt.ylabel("minimum distance of all generations") yy = []
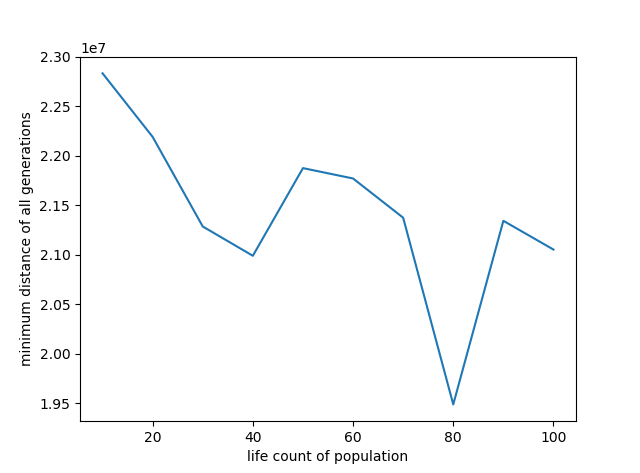
for i in range(len(life_count)):
tsp = MyTSP(gene_length = 28, overlapping_rate = 0.7, mutation_rate = 0.03, life_count = life_count[i], max_iteration = 40)
tsp.evolve()
yy.append(tsp.best_gene_distance)
plt.figure('life count of population and minimum distance')
plt.plot(life_count, yy)
plt.xlabel('life count of population')
plt.ylabel("minimum distance of all generations") yy = []
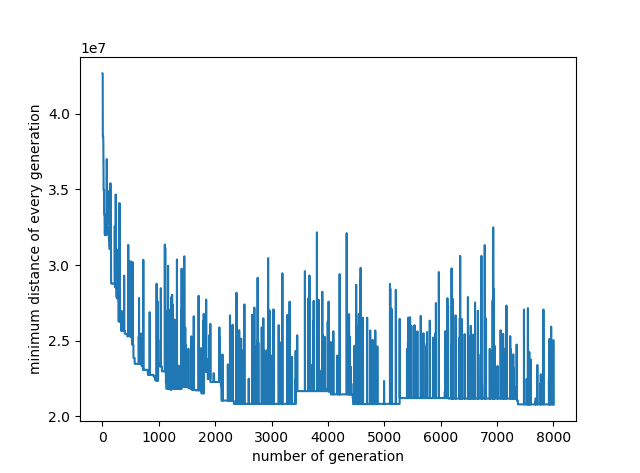
tsp = MyTSP(28, 0.5, 0.03, 30, 40)
tsp.evolve()
plt.figure('number of generation and minimum distance')
plt.plot(range(1, tsp.max_iteration + 1), tsp.min_distance)
plt.xlabel('number of generation')
plt.ylabel("minimum distance of every generation") plt.show()
代码中探究了迭代次数、交叉概率、变异概率、种群中生命体个数对求解效果的影响,分别如下面的4张曲线图


GA求解TSP的更多相关文章
- 遗传算法的C语言实现(二)-----以求解TSP问题为例
上一次我们使用遗传算法求解了一个较为复杂的多元非线性函数的极值问题,也基本了解了遗传算法的实现基本步骤.这一次,我再以经典的TSP问题为例,更加深入地说明遗传算法中选择.交叉.变异等核心步骤的实现.而 ...
- 基于粒子群算法求解求解TSP问题(JAVA)
一.TSP问题 TSP问题(Travelling Salesman Problem)即旅行商问题,又译为旅行推销员问题.货郎担问题,是数学领域中著名问题之一.假设有一个旅行商人要拜访n个城市,他必须选 ...
- 模拟退火算法(SA)求解TSP 问题(C语言实现)
这篇文章是之前写的智能算法(遗传算法(GA).粒子群算法(PSO))的补充.其实代码我老早之前就写完了,今天恰好重新翻到了,就拿出来给大家分享一下,也当是回顾与总结了. 首先介绍一下模拟退火算法(SA ...
- 基于爬山算法求解TSP问题(JAVA)
一.TSP问题 TSP问题(Travelling Salesman Problem)即旅行商问题,又译为旅行推销员问题.货郎担问题,是数学领域中著名问题之一.假设有一个旅行商人要拜访n个城市,他必须选 ...
- 基于贪心算法求解TSP问题(JAVA)
概述 前段时间在搞贪心算法,为了举例,故拿TSP来开刀,写了段求解算法代码以便有需之人,注意代码考虑可读性从最容易理解角度写,没有优化,有需要可以自行优化! 详细 代码下载:http://www.de ...
- 自适应大邻域搜索代码系列之(1) - 使用ALNS代码框架求解TSP问题
前言 上次出了邻域搜索的各种概念科普,尤其是LNS和ALNS的具体过程更是描述得一清二楚.不知道你萌都懂了吗?小编相信大家早就get到啦.不过有个别不愿意透露姓名的热心网友表示上次没有代码,遂不过瘾啊 ...
- 干货 | 10分钟掌握branch and cut(分支剪界)算法原理附带C++求解TSP问题代码
00 前言 branch and cut其实还是和branch and bound脱离不了干系的.所以,在开始本节的学习之前,请大家还是要务必掌握branch and bound算法的原理. 01 应 ...
- 【优化算法】变邻域搜索算法(VNS)求解TSP(附C++详细代码及注释)
00 前言 上次变邻域搜索的推文发出来以后,看过的小伙伴纷纷叫好.小编大受鼓舞,连夜赶工,总算是完成了手头上的一份关于变邻域搜索算法解TSP问题的代码.今天,就在此给大家双手奉上啦,希望大家能ENJO ...
- 利用遗传算法求解TSP问题
转载地址 https://blog.csdn.net/greedystar/article/details/80343841 目录 一.问题描述 二.算法描述 三.求解说明 四.参考资料 五.源代码 ...
随机推荐
- 一张游览PHP内核迷宫的藏宝图
PHP内核就像一个迷宫,假设没有一个纵览全局的图,仅仅是面对当中的一个点,就会像进了迷宫一样,走着走着就走到了死胡同.在这个迷宫里转悠了非常久之后,近期得到了一张PHP藏宝图.然后看着这张图去游览PH ...
- P4396 [AHOI2013]作业 分块+莫队
这个题正解是莫队+树状数组,但是我个人非常不喜欢树状数组这种东西,所以决定用分块来水这个题.直接在莫队维护信息的时候,维护单点同时维护块内信息就行了. 莫队就是这几行核心代码: void add(in ...
- Vue2.0框架搭建基础操作及目录说明
一.概述 vue.js是一套构建用户界面的渐进式框架.vue采用自底向上增量开发的设计.vue的核心库只关心视图层,非常容易学习,非常容易与其它库和已有项目整合.vue完全有能力驱动采用单文件组件和v ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Android进程与线程
我们都知道,在操作系统中进程是OS分配资源的最小单位,而线程是执行任务的最小单位.一个进程可以拥有多个线程执行任务,这些线程可以共享该进程分配到的资源.当我们的app启动运行后,在该app没有其他组件 ...
- [hihocoder][Offer收割]编程练习赛44
扫雷游戏 #pragma comment(linker, "/STACK:102400000,102400000") #include<stdio.h> #includ ...
- 等等空格用法
平时经常用到 空格转移字符,记住一个 表示一个字符就可以了. Non-Breaking SPace 记住它是什么的缩写,更有助于我们记忆和使用.下面的字符转义自己视图翻译一下. 记录一下,空格的转 ...
- Fragment_动态加载
1.新建Fragment的XML布局文件. 2.在activity.xml中添加需要加载Fragment.列如: <?xml version="1.0" encoding=& ...
- PhotoZoom Classic 7有什么用?高品质的放大模糊图片!
PhotoZoom Classic 7专门用于放大照片,同时保持质量.该软件配备了BenVista独特的S-Spline技术,可轻松超越Photoshop的双三次插值等替代解决方案. PhotoZoo ...
- vc++如何创建程序-构造函数02
1.若忘记了赋值,出现运行结果是很大的负值(因为我们定义的x与y这两个成员变量存储在内存中是一个随机的值) 当我们调用时,随机输出. //包含输入输出的头文件#include<iostream. ...