2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码
- html = requests.get(YieldCurveUrl, headers=headers)
- html=html.content.decode('UTF-8')
- # print(html)
- soup = BeautifulSoup(html, 'lxml')
之前是这样的
- html = requests.get(YieldCurveUrl, headers=headers)
- soup = BeautifulSoup(html.text, 'lxml')
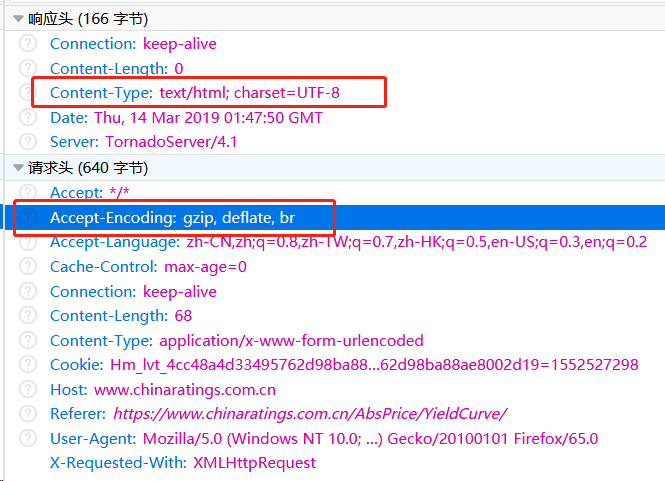
出现乱码,一般是两种原因,charset使用了geb2312的编码方式,而非utf-8
这里用的是utf-8,所以问题出在使用了gzip的压缩方式
2019-03-14 Python爬虫问题 爬取网页的汉字打印出来乱码的更多相关文章
- python 爬虫(爬取网页的img并下载)
from urllib.request import urlopen # 引用第三方库 import requests #引用requests/用于访问网站(没安装需要安装) from pyquery ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
随机推荐
- Java基础学习总结(64)——Java内存管理
本文介绍的Java虚拟机(JVM)的自动内存管理机制主要是参照<深入理解Java虚拟机>(第2版)一书中的内容,主要分为两个部分:Java内存区域和内存溢出异常.垃圾回收和内存分配策略.因 ...
- JavaScript原生值与JSON的转换
---------------------------------- ---------------------------- stringify方法的另外两种参数: ---------------- ...
- ASP.NET中的Webconfig 和 Global.asax区别
Web.Config与Global.asax的区别: Config可以根据不同的错误类型定义不同的错误页,网站重定义转向新的错误页面. Global,在全局错误中写入应用程序事件错误信息,并在当前页输 ...
- HDU 5172
超内存了,呃...不知道如何优化了. 首先要判断区间的和是否和1~n的和相等. 再个,记录下每个数字前一次出现的位置,求这些位置的最大值,如果小于左端点,则表示有这样的一个序列. 呃~~~第二个条件当 ...
- [HTML5] a tag, rel="noopener"
It is a good pratice to add ref="noopener" <a href="/some/domain" target=&quo ...
- js代码从页面移植到文件里失效或js代码改动后不起作用的解决的方法
近期在做关于站点的项目,总是发生这种问题 写的javascript代码在页面上没有问题,可是将js代码移植到.js的文件里,在页面上进行调用,总是出现失效等错误 另外改动后的js代码,又一次刷新网页仍 ...
- Unity3D_c#脚本注意要点
1. Inherit from MonoBehaviour 继承自MonoBehaviour All behaviour scripts must inherit from MonoBehaviour ...
- iOS开发之autoLayout constraint
前言 ios设备的尺寸越来越多,针对一款app可能要适配到多种设备.多种尺寸.所以.我们期望我们的app可以autoLayout.本文主要介绍在Xcode中使用constraint.未来会不定期对此文 ...
- <LeetCode OJ> 100. Same Tree
100. Same Tree Total Accepted: 100129 Total Submissions: 236623 Difficulty: Easy Given two binary tr ...
- Common webpart properties in kentico
https://devnet.kentico.com/docs/7_0/devguide/index.html?common_web_part_properties.htm HTML Envelope ...