Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1。
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一)
这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码。这里不多赘述,直接送上代码。
MRUnit 框架
MRUnit是Cloudera公司专为Hadoop MapReduce写的单元测试框架,API非常简洁实用。MRUnit针对不同测试对象使用不同的Driver:
MapDriver:针对单独的Map测试
ReduceDriver:针对单独的Reduce测试
MapReduceDriver:将map和reduce串起来测试
PipelineMapReduceDriver:将多个MapReduce对串志来测试
记得,将这个jar包,放到工程项目里。我这里是在工程项目的根目录下的lib下。
代码版本2

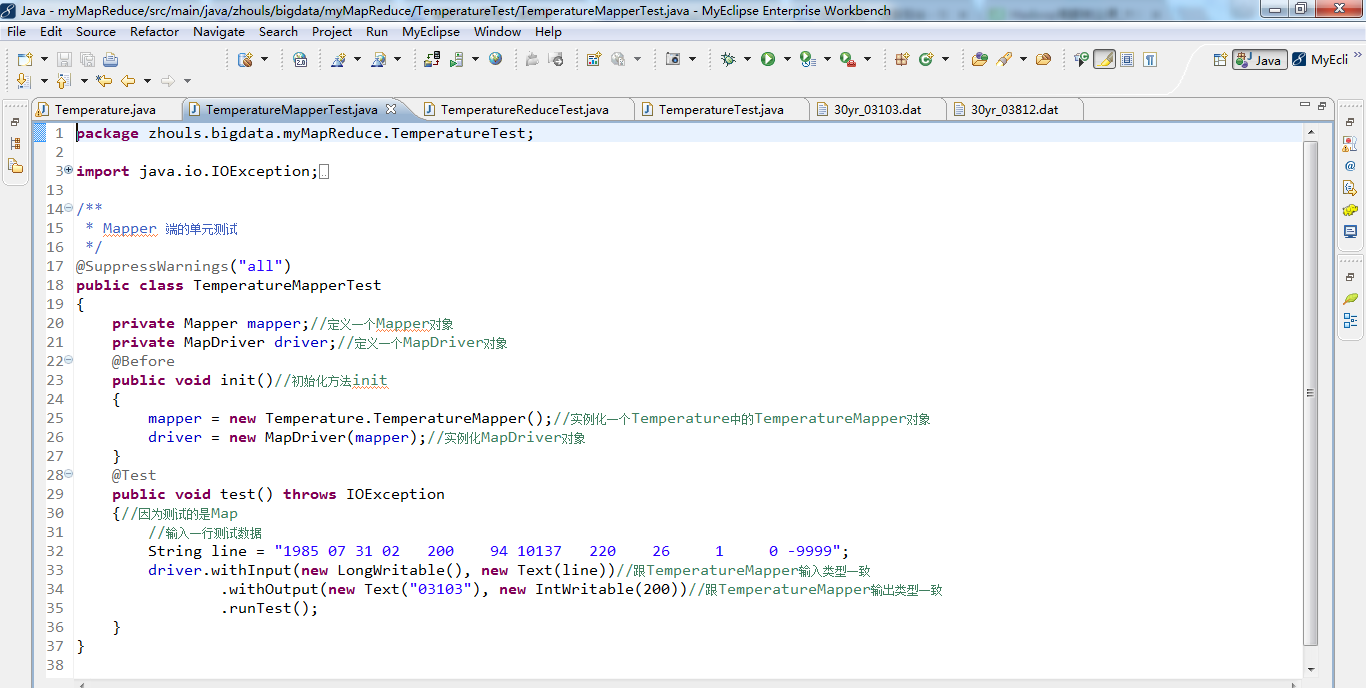
编写TemperatureMapperTest.java的代码。 编译,出现以下,则说明无误。
在test()方法中,withInput的key/value参数分别为偏移量和一行气象数据,其类型要与TemperatureMapper的输入类型一致即为LongWritable和Text。 withOutput的key/value参数分别是我们期望输出的new Text("03103")和new IntWritable(200),我们要达到的测试效果就是我们的期望输出结果与 TemperatureMapper 的实际输出结果一致。
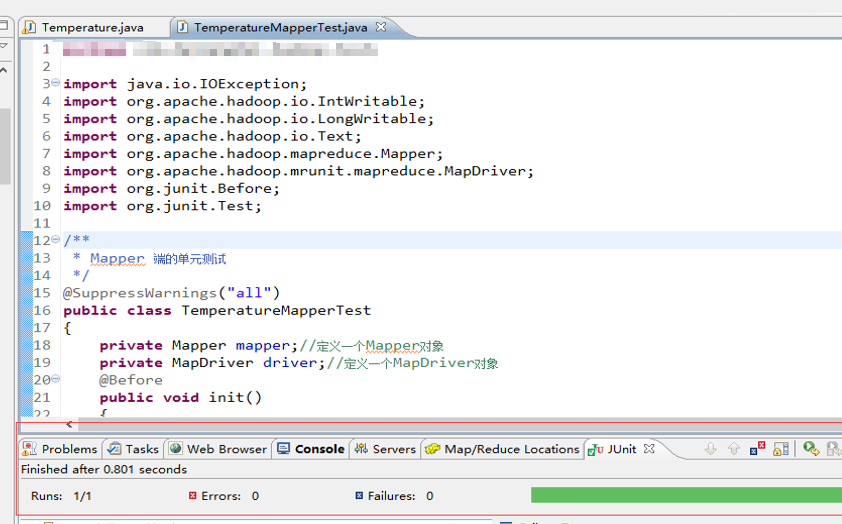
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 Mapper 测试成功了。

创建TemperatureReduceTest.java,来对Reduce进行测试。
在test()方法中,withInput的key/value参数分别为new Text(key)和List类型的集合values。withOutput 的key/value参数分别是我们所期望输出的new Text(key)和new IntWritable(150),我们要达到的测试效果就是我们的期望输出结果与TemperatureReducer实际输出结果一致。
编写TemperatureReduceTest.java的代码。 编译,出现以下,则说明无误。

Reducer 端的单元测试,鼠标放在 TemperatureReduceTest 类上右击,选择 Run As ——> JUnit test,运行结果如下所示。
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 Reducer 测试成功了。

MapReduce 单元测试
把 Mapper 和 Reducer 集成起来的测试案例代码如下。
创建TemperatureTest.java,来进行测试。
在 test() 方法中,withInput添加了两行测试数据line和line2,withOutput 的key/value参数分别为我们期望的输出结果new Text("03103")和new IntWritable(150)。我们要达到的测试效果就是我们期望的输出结果与Temperature实际的输出结果一致。
编写TemperatureTest.java的代码。 编译,出现以下,则说明无误。
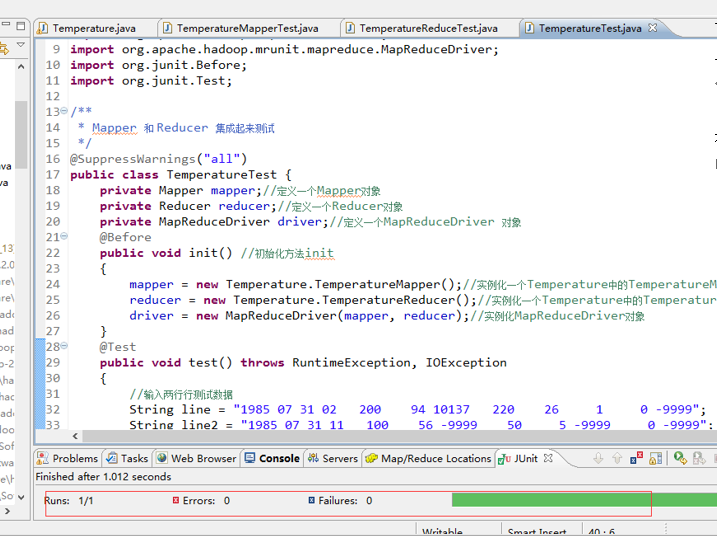
Reducer 端的单元测试,鼠标放在 TemperatureTest.java类上右击,选择 Run As ——> JUnit test,运行结果如下所示。
测试方法为 test() 方法,左边的对话框里显示"Runs:1/1,Errors:0,Failures:0",说明 MapReduce 测试成功了。
Temperature.java代码
package zhouls.bigdata.myMapReduce.TemperatureTest; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /*
Hadoop内置的数据类型:
BooleanWritable:标准布尔型数值
ByteWritable:单字节数值
DoubleWritable:双字节数值
FloatWritable:浮点数
IntWritable:整型数
LongWritable:长整型数
Text:使用UTF8格式存储的文本
NullWritable:当<key, value>中的key或value为空时使用
*/ /**
* 统计美国每个气象站30年来的平均气温
* 1、编写map()函数
* 2、编写reduce()函数
* 3、编写run()执行方法,负责运行MapReduce作业
* 4、在main()方法中运行程序
*
* @author zhouls
*
*/
//继承Configured类,实现Tool接口
public class Temperature extends Configured implements Tool{
public static class TemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//输入的key,输入的value,输出的key,输出的value
//输入的LongWritable键是某一行起始位置相对于文件起始位置的偏移量,不过我们不需要这个信息,所以将其忽略。 // 在这种情况下,我们将气象站id按 Text 对象进行读/写(因为我们把气象站id当作键),将气温值封装在 IntWritale 类型中。只有气温数据不缺失,这些数据才会被写入输出记录中。 // map 函数的功能仅限于提取气象站和气温信息 /**
* @function Mapper 解析气象站数据
* @input key=偏移量 value=气象站数据
* @output key=weatherStationId value=temperature
*/
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//map()函数还提供了context实例,用于键值对的输出 或者说 map() 方法还提供了 Context 实例用于输出内容的写入 // 就本示例来说,输入键是一个长整数偏移量,输入值是一行文本,输出键是气象站id,输出值是气温(整数)。
// 同时context作为了map和reduce执行中各个函数的一个桥梁,这个设计和Java web中的session对象、application对象很相似 //第一步,我们将每行气象站数据转换为每行的String类型
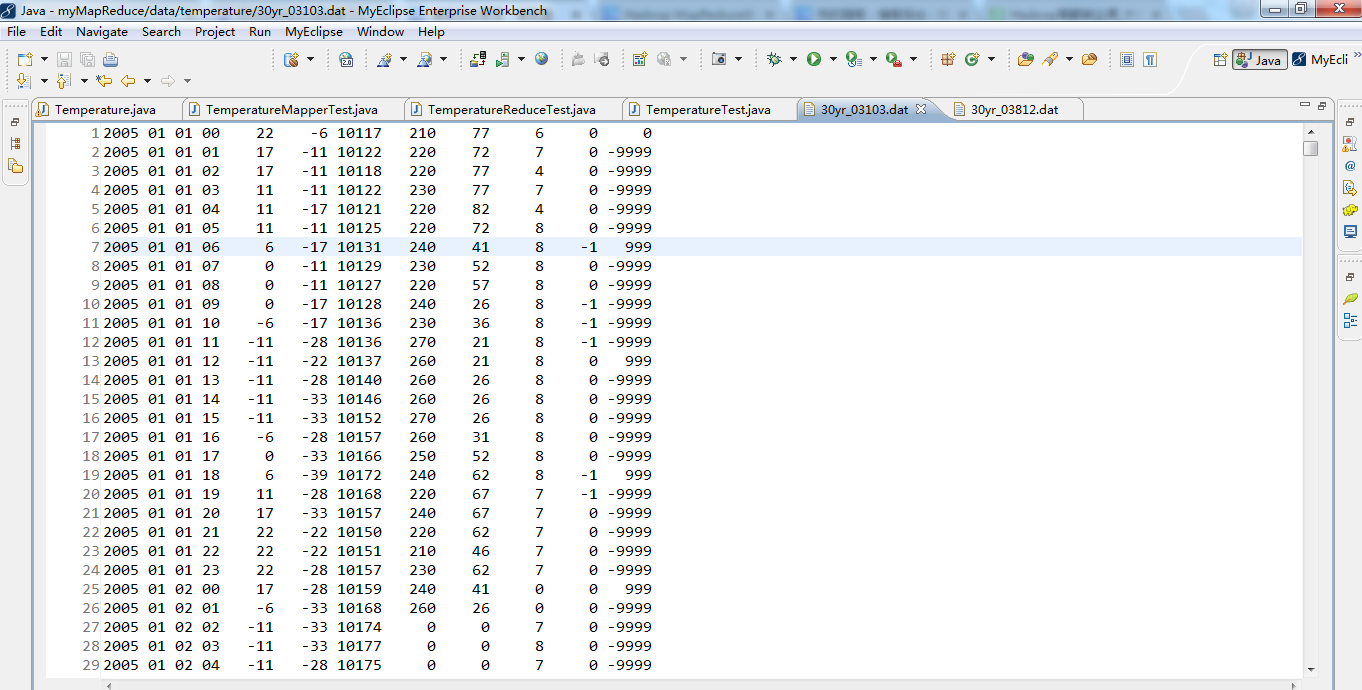
String line = value.toString(); //每行气象数据
// values是1980 12 01 00 78 -17 10237 180 21 1 0 0
// line是"1980 12 01 00 78 -17 10237 180 21 1 0 0" //第二步:提取气温值
int temperature = Integer.parseInt(line.substring(14, 19).trim());//每小时气温值
//需要转换为整形,截取第14位到19位,从第0位开始,trim()的功能是去掉首尾空格。
//substring()方法截取我们业务需要的值 // substring(start, stop)其内容是从 start 处到 stop-1 处的所有字符,其长度为 stop 减 start。 // 如Hello world! 若是substring(3,7) 则是lo w // Integer.parseInt() 返回的是一个int的值。在这里, 给temperature // new Integer.valueof()返回的是Integer的对象。
// Integer.parseInt() 返回的是一个int的值。
// new Integer.valueof().intValue();返回的也是一个int的值。 // 1980 12 01 00 78 -17 10237 180 21 1 0 0
//78是气温值 // temperature是78 // 30yr_03103.dat
// 30yr_03812.dat
// 30yr_03813.dat
// 30yr_03816.dat
// 30yr_03820.dat
// 30yr_03822.dat
// 30yr_03856.dat
// 30yr_03860.dat
// 30yr_03870.dat
// 30yr_03872.dat // (0,1985 07 31 02 200 94 10137 220 26 1 0 -9999)
// (62,1985 07 31 03 172 94 10142 240 0 0 0 -9999)
// (124,1985 07 31 04 156 83 10148 260 10 0 0 -9999)
// (186,1985 07 31 05 133 78 -9999 250 0 -9999 0 -9999)
// (248,1985 07 31 06 122 72 -9999 90 0 -9999 0 0)
// (310,1985 07 31 07 117 67 -9999 60 0 -9999 0 -9999)
// (371,1985 07 31 08 111 61 -9999 90 0 -9999 0 -9999)
// (434,1985 07 31 09 111 61 -9999 60 5 -9999 0 -9999)
// (497,1985 07 31 10 106 67 -9999 80 0 -9999 0 -9999)
// (560,1985 07 31 11 100 56 -9999 50 5 -9999 0 -9999) // (03103,[200,172,156,133,122,117,111,111,106,100]) // 根据自己业务需要 , map 函数的功能仅限于提取气象站和气温信息 // 1998 #year
// 03 #month
// 09 #day
// 17 #hour
// 11 #temperature 感兴趣
// -100 #dew
// 10237 #pressure
// 60 #wind_direction
// 72 #wind_speed
// 0 #sky_condition
// 0 #rain_1h
// -9999 #rain_6h if (temperature != -9999){//过滤无效数据
//第三步:提取气象站编号
//获取输入分片
FileSplit fileSplit = (FileSplit) context.getInputSplit();//提取问加你输入分片,并转换类型
// 即由InputSplit -> FileSplit // context.getInputSplit()
// (FileSplit) context.getInputSplit()这是强制转换
// fileSplit的值是file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/temperature/30yr_03870.dat:0+16357956
// 即,读的是30yr_03870.dat这个文件 //然后通过文件名称提取气象站编号
String weatherStationId = fileSplit.getPath().getName().substring(5, 10);//通过文件名称提取气象站id
//首先通过文件分片fileSplit来获取文件路径,然后再获取文件名字,然后截取第5位到第10位就可以得到气象站 编号
// fileSplit.getPath()
// fileSplit.getPath().getName() // 30yr_03870.dat 我们只需获取03870就是气象站编号 // fileSplit.getPath().getName().substring(5, 10) //从0开始,即第5个开始截取,到第10个为止,第10个没有拿到,所以为03870
// weatherStationId是03870 context.write(new Text(weatherStationId), new IntWritable(temperature));//写入weatherStationId是k2,temperature是v2
// context.write(weatherStationId,temperature);等价 ,但是若是直接这样写会出错,因为, weatherStationId是String类型,注意与Text类型还是有区别的!
//气象站编号,气温值
}
}
} public static class TemperatureReducer extends Reducer< Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();//存取结果
//因为气温是IntWritable类型
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
// Iterable<IntWritable> values是iterable(迭代器)变量 // Iterable<IntWritable> values和IntWritable values这样有什么区别?
// 前者是iterable(迭代器)变量,后者是intwriteable(int的封装)变量 // Iterable<IntWritable> values
// 迭代器,valuses是 iterable(迭代器)变量,类型是IntWritable //reduce输出的key,key的集合,context的实例
//第一步:统计相同气象站的所有气温
int sum = 0;
int count = 0;
for (IntWritable val : values) //星型for循环来循环同一个气象站的所有气温值,即将values的值一一传给IntWritable val
// IntWritable val是IntWritable(int的封装)变量 {//对所有气温值累加
sum += val.get();//去val里拿一个值,就sum下 // val.get()去拿值 count++;
}
result.set(sum / count);//设为v3
// result.set(sum / count)去设置,将sum / count的值,设给result
// sum是21299119 count是258616 = 82.3580869 context.write(key,result);//写入key是k3,result是v3
}
} public int run(String[] args) throws Exception{
// TODO Auto-generated method stub
//第一步:读取配置文件
Configuration conf = new Configuration();//程序里,只需写这么一句话,就会加载到hadoop的配置文件了
//Configuration类代表作业的配置,该类会加载mapred-site.xml、hdfs-site.xml、core-site.xml等配置文件。 // new Configuration() //第二步:输出路径存在就先删除
Path mypath = new Path(args[1]);//定义输出路径的Path对象,mypath // new Path(args[1])将args[1]的值,给mypath FileSystem hdfs = mypath.getFileSystem(conf);//程序里,只需写这么一句话,就可以获取到文件系统了。
//FileSystem里面包括很多系统,不局限于hdfs,是因为,程序读到conf,哦,原来是hadoop集群啊。这时,才认知到是hdfs if (hdfs.isDirectory(mypath))//如果输出路径存在
{
hdfs.delete(mypath, true);//则就删除
}
//第三步:构建job对象
Job job = new Job(conf, "temperature");//新建一个任务,job名字是tempreature // new Job(conf, "temperature")有这么个构造方法 job.setJarByClass(Temperature.class);// 设置主类
//通过job对象来设置主类Temperature.class //第四步:指定数据的输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径,args[0]
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径,args[1] //第五步:指定Mapper和Reducer
job.setMapperClass(TemperatureMapper.class);// Mapper
job.setReducerClass(TemperatureReducer.class);// Reducer //第六步:设置map函数和reducer函数的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //第七步:提交作业
return job.waitForCompletion(true)?0:1;//提交任务
} /**
* @function main 方法
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
//第一步
// String[] args0 =
// {
// "hdfs://djt002:9000/inputData/temperature/",
// "hdfs://djt002:9000/outData/temperature/"
// }; String[] args0 = {"./data/temperature/","./out/temperature/"}; // args0是输入路径和输出路径的属组 //第二步
int ec = ToolRunner.run(new Configuration(), new Temperature(), args0); // ToolRunner.run(new Configuration(), new Temperature(), args0)有这么一个构造方法 //第一个参数是读取配置文件,第二个参数是主类Temperature,第三个参数是输入路径和输出路径的属组
System.exit(ec);
} }
TemperatureMapperTest.java
package zhouls.bigdata.myMapReduce.TemperatureTest; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.Before;
import org.junit.Test; /**
* Mapper 端的单元测试,这里用MRUnit框架,需要使用mrunit-hadoop.jar
*/
@SuppressWarnings("all")//告诉编译器忽略指定的警告,不用在编译完成后出现警告信息
public class TemperatureMapperTest{
private Mapper mapper;//定义一个Mapper对象,是mapper
private MapDriver driver;//定义一个MapDriver对象,是driver,因为是要MapDriver去做! @Before//@Before是在所拦截单元测试方法执行之前执行一段逻辑,读艾特Before
public void init(){//初始化方法init
mapper = new Temperature.TemperatureMapper();//实例化一个Temperature中的TemperatureMapper对象
driver = new MapDriver(mapper);//实例化MapDriver对象
} @Test//@Test是测试方法提示符,一般与@Before组合使用
public void test() throws IOException{
//因为测试的是Map
//输入一行测试数据
String line = "1985 07 31 02 200 94 10137 220 26 1 0 -9999";
driver.withInput(new LongWritable(), new Text(line))//withInput方法是第一行输入 跟TemperatureMapper输入类型一致
.withOutput(new Text("03103"), new IntWritable(200))//withOutput方法是输出 跟TemperatureMapper输出类型一致
.runTest();//runTest方法是调用运行方法
}
}
TemperatureReduceTest.java代码
package zhouls.bigdata.myMapReduce.TemperatureTest; import java.io.IOException; import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test; /**
* Reducer 单元测试,这里用MRUnit框架,需要使用mrunit-hadoop.jar
*/
@SuppressWarnings("all")//告诉编译器忽略指定的警告,不用在编译完成后出现警告信息
public class TemperatureReduceTest{
private Reducer reducer;//定义一个Reducer对象,是 reducer
private ReduceDriver driver;//定义一个ReduceDriver对象,是driver,因为是要ReduceDriver去做! @Before//@Before是在所拦截单元测试方法执行之前执行一段逻辑,读艾特Before
public void init(){//初始化方法init
reducer = new Temperature.TemperatureReducer();//实例化一个Temperature中的TemperatureReducer对象
driver = new ReduceDriver(reducer);//实例化ReduceDriver对象
} @Test//@Test是测试方法提示符,一般与@Before搭配使用
public void test() throws IOException{//为了模拟在reduer端单元测试,所以需如下
String key = "03103";//声明一个key值
List values = new ArrayList();
values.add(new IntWritable(200));//添加第一个value值
values.add(new IntWritable(100));//添加第二个value值
driver.withInput(new Text(key), values)//withInput方法是第一行输入 跟TemperatureReducer输入类型一致
.withOutput(new Text(key), new IntWritable(150))//withOutput方法是输出 跟TemperatureReducer输出类型一致
.runTest();//runTest方法是调用运行方法
}
}
TemperatureTest.java代码
package zhouls.bigdata.myMapReduce.TemperatureTest; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.MapReduceDriver;
import org.junit.Before;
import org.junit.Test; /**
* Mapper 和 Reducer 集成起来测试,这里用MRUnit框架
*/
@SuppressWarnings("all")
public class TemperatureTest {
private Mapper mapper;//定义一个Mapper对象
private Reducer reducer;//定义一个Reducer对象
private MapReduceDriver driver;//定义一个MapReduceDriver对象是driver,因为是对map和reducer联合起来测试,所以需要MapReduceDriver去做! @Before//@Before是在所拦截单元测试方法执行之前执行一段逻辑,读艾特Before
public void init(){ //初始化方法init
mapper = new Temperature.TemperatureMapper();//实例化一个Temperature中的TemperatureMapper对象
reducer = new Temperature.TemperatureReducer();//实例化一个Temperature中的TemperatureReducer对象
driver = new MapReduceDriver(mapper, reducer);//实例化MapReduceDriver对象
} @Test//@Test是测试方法提示符
public void test() throws RuntimeException, IOException{
//输入两行行测试数据
String line = "1985 07 31 02 200 94 10137 220 26 1 0 -9999";
String line2 = "1985 07 31 11 100 56 -9999 50 5 -9999 0 -9999";
driver.withInput(new LongWritable(), new Text(line))//withInput方法是第一行输入 跟TemperatureMapper输入类型一致
.withInput(new LongWritable(), new Text(line2))//第二行输入
.withOutput(new Text("03103"), new IntWritable(150))//withOutput方法是输出 跟TemperatureReducer输出类型一致
.runTest();//runTest方法是调用运行方法
}
}

Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)的更多相关文章
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
不多说,直接上代码. 统计出每个年龄段的 男.女 学生的最高分 这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据. 代码 package zhouls.bigdata.myMapRedu ...
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
随机推荐
- OpenCV:使用 随机森林与GBDT
随机森林顾名思义,是用随机的方式建立一个森林.简单来说,随机森林就是由多棵CART(Classification And Regression Tree)构成的.对于每棵树,它们使用的训练集是从总的训 ...
- matlab中 注意事项--字符串
Matlab中的字符串操作 原文链接:http://hi.baidu.com/dreamflyman/item/bd6d8224430003c9a5275a9f (1).字符串是以ASCII码形式存储 ...
- [Intermediate Algorithm] - Everything Be True
题目 所有的东西都是真的! 完善编辑器中的every函数,如果集合(collection)中的所有对象都存在对应的属性(pre),并且属性(pre)对应的值为真.函数返回ture.反之,返回false ...
- 【sqli-labs】 less31 GET- Blind -Impidence mismatch -Having a WAF in front of web application (GET型基于盲注的带有WAF注入)
标题和less30一样 http://192.168.136.128/sqli-labs-master/Less-31/login.php?id=1&id=2" ")闭合的 ...
- (转)C#开发微信门户及应用(4)--关注用户列表及详细信息管理
http://www.cnblogs.com/wuhuacong/p/3695213.html 在上个月的对C#开发微信门户及应用做了介绍,写过了几篇的随笔进行分享,由于时间关系,间隔了一段时间没有继 ...
- PyCharm 恢复默认设置 | JetBrains IDE 配置文件安装目录
网上的答案为什么都乱七八糟并且全都全篇一律?某度知道是发源地? 先说 Mac 按需运行下面的 rm 删除命令 # Configuration rm -rf ~/Library/Preferences/ ...
- python write和writelines的区别
file.write(str)的参数是一个字符串,就是你要写入文件的内容.file.writelines(sequence)的参数是序列,比如列表,它会迭代帮你写入文件. 下面两种方式写入文件的效果是 ...
- SSL证书在线申请和取回证书指南
1.客服下单后用户会收到一封邮件,来验证接收证书的邮箱;如图1所示:只有完成此邮箱验证才能正常申请证书; 请注意:为了确保您或您的用户能正常收到WoSign证书管理系统自动发送的邮件,请一定要把系统发 ...
- python PIL图像处理-图片上添加文字
首先需要安装库pillow cmd安装命令:pip install pillow 安装完后,编写脚本如下: from PIL import Image, ImageDraw, ImageFont de ...
- appium的滑动
#coding = utf-8from appium import webdriverimport time'''1.手机类型2.版本3.手机的唯一标识 deviceName4.app 包名appPa ...