Local Response Normalization作用——对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN(Local Response Normalization)
ImageNet中的LRN层是按下述公式计算的:

但似乎,在后来的设计中,这一层已经被其它种的Regularization技术,如drop out, batch normalization取代了。知道了这些,似乎也可以不那么纠结这个LRN了。
转自:http://blog.csdn.net/searobbers_duck/article/details/51645941
为什么要有局部响应归一化(Local Response Normalization)?
详见http://blog.csdn.net/hduxiejun/article/details/70570086
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),然后根据论文有公式如下
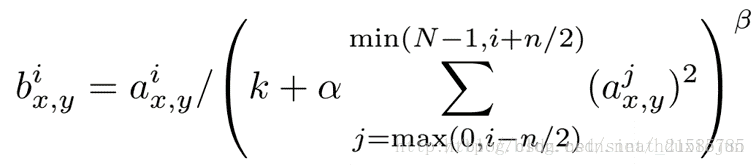
公式解释:
因为这个公式是出自CNN论文的,所以在解释这个公式之前读者应该了解什么是CNN,可以参见
http://blog.csdn.net/whiteinblue/article/details/25281459
http://blog.csdn.net/stdcoutzyx/article/details/41596663
http://www.jeyzhang.com/cnn-learning-notes-1.html
这个公式中的a表示卷积层(包括卷积操作和池化操作)后的输出结果,这个输出结果的结构是一个四维数组[batch,height,width,cha
nnel],这里可以简单解释一下,batch就是
批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经
过卷积操作后输出的神经元个数(或是理解
成处理后的图片深度)。ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某
个宽度位置的点,即第a张图的第d个通道下
的高度为b宽度为c的点。论文公式中的N表示通道数(channel)。a,n/2,k,α,β分别表示函数中的input,depth_radius,bias,alpha,beta,其
中n/2,k,α,β都是自定义的,特别注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的第3维channel方向
的,也就是一个点同方向的前面n/2个通
道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当
成是d个3维的矩阵,说白了就是把input的通道
数当作3维矩阵的个数,叠加的方向也是在
通道方向。
画个简单的示意图:
这里写图片描述
实验代码:
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1,33)]).reshape([2,2,2,4])
y = tf.nn.lrn(input=x,depth_radius=2,bias=0,alpha=1,beta=1)
with tf.Session() as sess:
print(x)
print('#############')
print(y.eval())
结果解释:
这里要注意一下,如果把这个矩阵变成图片的格式是这样的
这里写图片描述
然后按照上面的叙述我们可以举个例子比如26对应的输出结果0.00923952计算如下

26/(0+1*(25^2+26^2+27^2+28^2))^1
BN本质上解决的是反向传播过程中的梯度问题。
详细点说,反向传播时经过该层的梯度是要乘以该层的参数的,即前向有:
那么反向传播时便有:
那么考虑从l层传到k层的情况,有:
上面这个 便是问题所在。因为网络层很深,如果
大多小于1,那么传到这里的时候梯度会变得很小比如
;而如果
又大多大于1,那么传到这里的时候又会有梯度爆炸问题 比如
。
BN所做的就是解决这个梯度传播的问题,因为BN作用抹去了w的scale影响。
具体有:
(
) =
(
)
那么反向求导时便有了:
可以看到此时反向传播乘以的数不再和 的尺度相关,也就是说尽管我们在更新过程中改变了
的值,但是反向传播的梯度却不受影响。更进一步:
即尺度较大的 将获得一个较小的梯度,在同等的学习速率下其获得的更新更少,这样使得整体
的更新更加稳健起来。
总结起来就是BN解决了反向传播过程中的梯度问题(梯度消失和爆炸),同时使得不同scale的 整体更新步调更一致。
链接:https://www.zhihu.com/question/38102762/answer/164790133
说到底,BN的提出还是为了克服深度神经网络难以训练的弊病。其实BN背后的insight非常简单,只是在文章中被Google复杂化了。
首先来说说“Internal Covariate Shift”。文章的title除了BN这样一个关键词,还有一个便是“ICS”。大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同,即:对所有
那么好,为什么前面我说Google将其复杂化了。其实如果严格按照解决covariate shift的路子来做的话,大概就是上“importance weight”(ref)之类的机器学习方法。可是这里Google仅仅说“通过mini-batch来规范化某些层/所有层的输入,从而可以固定每层输入信号的均值与方差”就可以解决问题。如果covariate shift可以用这么简单的方法解决,那前人对其的研究也真真是白做了。此外,试想,均值方差一致的分布就是同样的分布吗?当然不是。显然,ICS只是这个问题的“包装纸”嘛,仅仅是一种high-level demonstration。
那BN到底是什么原理呢?说到底还是为了防止“梯度弥散”。关于梯度弥散,大家都知道一个简单的栗子:
Local Response Normalization作用——对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力的更多相关文章
- 局部响应归一化(Local Response Normalization,LRN)
版权声明:本文为博主原创文章,欢迎转载,注明地址. https://blog.csdn.net/program_developer/article/details/79430119 一.LRN技术介 ...
- caffe中的Local Response Normalization (LRN)有什么用,和激活函数区别
http://stats.stackexchange.com/questions/145768/importance-of-local-response-normalization-in-cnn ca ...
- Local Response Normalization 60 million parameters and 500,000 neurons
CNN是工具,在图像识别中是发现图像中待识别对象的特征的工具,是剔除对识别结果无用信息的工具. ImageNet Classification with Deep Convolutional Neur ...
- LRN(local response normalization--局部响应标准化)
LRN全称为Local Response Normalization,即局部响应归一化层,LRN函数类似DROPOUT和数据增强作为relu激励之后防止数据过拟合而提出的一种处理方法.这个函数很少使用 ...
- lecture9-提高模型泛化能力的方法
HInton第9课,这节课没有放论文进去.....如有不对之处还望指正.话说hinton的课果然信息量够大.推荐认真看PRML<Pattern Recognition and Machine L ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- Gradient Centralization: 简单的梯度中心化,一行代码加速训练并提升泛化能力 | ECCV 2020 Oral
梯度中心化GC对权值梯度进行零均值化,能够使得网络的训练更加稳定,并且能提高网络的泛化能力,算法思路简单,论文的理论分析十分充分,能够很好地解释GC的作用原理 来源:晓飞的算法工程笔记 公众号 论 ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- 北大博士生提出CAE,下游任务泛化能力优于何恺明MAE
大家好,我是对白. 何恺明时隔两年发一作论文,提出了一种视觉自监督学习新范式-- 用掩蔽自编码器MAE,为视觉大模型开路. 这一次,北大博士生提出一个新方法CAE,在其下游任务中展现的泛化能力超过了M ...
随机推荐
- PL/SQL实现JAVA中的split()方法的小例子
众所周知,java中为String类提供了split()字符串分割的方法,所以很容易将字符串以指定的符号分割为一个字符串数组.但是在pl/sql中并没有提供像java中的split()方法,所以要想在 ...
- ViewPager PagerAdapter 的使用
1: 目的,实现全屏滑动的效果 2:类似于BaseAdapter public class MyPagerAdapter extends PagerAdapter { private Context ...
- linux route命令的使用详解(转)
route命令用于显示和操作IP路由表.要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或者同时位于两个网络的网关来实现.在Linux系统中,设置路由通常是 为了解决以下问题:该Linu ...
- Kind (type theory)-higher-kinded types--type constructor
, pronounced "type", is the kind of all data types seen as nullary type constructors, and ...
- 平衡二叉树(Self-balancing Binary Search Tree)
Date: 2019-04-11 18:49:18 AVL树的基本操作 //存储结构 struct node { int data; int height; //记录当前子树的高度(叶子->根) ...
- [ZJOI2016]小星星(容斥+dp)
洛谷链接:https://www.luogu.org/problemnew/show/P3349 题意相当于给一棵树重新赋予彼此不同的编号,要求树上相邻的两个节点在给定的另外一个无向图中也存在边相连. ...
- 多态(day10)
二十二 多态(Polymorphic) 函数重写(虚函数覆盖).多态概念 如果将基类中的某个成员函数声明为虚函数,那么子类与其具有相同原型的成员函数就也将是虚函数,并且对基类中的版本形成覆盖. 这时, ...
- 目录-Linux
Linux文件系统: Linux: glibc 程序编译方式: 动态链接 静态编译 进程的类型: 终端:硬件设备,关联一个用户接口 与终端相关:通过终端启动 与终端无关:操作引导启动过程当中自动启动 ...
- vue_music:排行榜rank中top-list.vue中样式的实现:class
排行榜的歌曲列表,根据排名渲染不同的样式,同时需要考虑分辨率的2x 3x图 不同的样式--:class 考虑分辨率的2x 3x图--需要在stylu中的mixin中bgImage根据屏幕分辨率选择图片 ...
- CSS行高line-height的学习
一.定义和用法 line-height 属性设置行间的距离(行高). 可能的值 normal默认.设置合理的行间距. number设置数字,此数字会与当前的字体尺寸相乘来设置行间距. length设置 ...