python 全栈开发,Day95(RESTful API介绍,基于Django实现RESTful API,DRF 序列化)
昨日内容回顾
1. rest framework serializer(序列化)的简单使用
QuerySet([ obj, obj, obj]) --> JSON格式数据
0. 安装和导入:
pip3 install djangorestframework
from rest_framework import serializers
1. 简单使用
1. 创建一个类,类一定要继承serializers.Serializer
2. chocie字段和FK字段都可以通过使用source来获取对应的值
3. 多对多字段可以通过使用 serializers.SerializerMethodField
def get_tag(self, obj):
tag_list = []
for i in obj.tag.all():
tag_list.append(i.name)
return tag_list
2.使用 ModelSerializer
通过配置class Meta:
model = 表名
fields = ['字段', ...]
depth = 1
一、RESTful API介绍
什么是RESTful
REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移”或“表现层状态转化”。
RESTful API设计
API与用户的通信协议
总是使用HTTPs协议。
现在互联网企业,都开始关注安全了。所以,一般暴露的接口,都是使用https协议。前提是,需要购买SSL域名证书,一年花费,少则几千,多则上万。
域名
https://api.example.com 尽量将API部署在专用域名 https://example.org/api/ API很简单
使用第一种,可能会有跨域问题。为了避免这种问题,可以采用第二种。
版本
1. 将版本信息放在URL中,如:https://api.example.com/v1/ 2. 将版本信息放在请求头中。
国内的公司,一般使用第一种。前端代码不用大改动,后端开发好v2版本后。将url切换一下,就可以实现平滑迁移。
国外公司,使用会第二种,因为这样比较安全!
路径
视网络上任何东西都是资源,均使用名词表示(可复数) https://api.example.com/v1/zoos https://api.example.com/v1/animals https://api.example.com/v1/employees
上面的3个url分别表示:动物园、动物、员工
method
GET :从服务器取出资源(一项或多项) POST :在服务器新建一个资源 PUT :在服务器更新资源(客户端提供改变后的完整资源) PATCH :在服务器更新资源(客户端提供改变的属性) DELETE :从服务器删除资源
PATCH很少用到
过滤
通过在url上传参的形式传递搜索条件 https://api.example.com/v1/zoos?limit=10:指定返回记录的数量 https://api.example.com/v1/zoos?offset=10:指定返回记录的开始位置 https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数 https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序 https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件
上面的url参数,一眼望过去,就大概知道啥意思了。所以命令规范,很重要!
程序员写代码,不只是完成功能而已!写代码的时候,必须按照规范来。比如python,遵循PEP8。
已经写好的代码,有空的时候,将代码优化一下!这样,当你把项目交接给别人的时候,不至于,让人看着代码,晦涩难懂!一万匹马在内心崩腾,有木有?
状态码
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
几个常用的http状态码,需要知道。因为面试必问!
错误处理
状态码是4xx时,应返回错误信息,error当做key。
{
error: "Invalid API key"
}
尽量将代码写的健全一点,遇到错误时,抛出error
返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
比如url: http://127.0.0.1/api/comment/2 表示id为2的详细信息
Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
{"link": {
"rel": "collection https://www.example.com/zoos",
"href": "https://api.example.com/zoos",
"title": "List of zoos",
"type": "application/vnd.yourformat+json"
}}
这个,要看需求了,有需求,可以做一下!
更多内容,请参考:阮一峰的Blog
二、基于Django实现RESTful API
在昨天项目about_drf的基础上, 增加一个评论表
修改model.py,增加表comment
# 评论表
class Comment(models.Model):
content = models.CharField(max_length=128)
article = models.ForeignKey(to='Article', on_delete=models.CASCADE)
使用2个命令,生成表
python manage.py makemigrations
python manage.py migrate
现在需要对评论表,做增删改查,按照常规来讲,会这么写url
url(r'comment_list/',...),
url(r'add_comment/',...),
url(r'delete_comment/',...),
url(r'edit_comment/',...),
现在还只是一个表的增删改查,如果有80个表呢?写320个url ?
RESTful API之url设计
路由分发
在app01(应用名)目录下,创建文件app01_urls.py
from django.conf.urls import url
from app01 import views urlpatterns = [
url(r'^article_list/', views.article_list),
url(r'article_detail/(\d+)', views.article_detail), # 评论
url(r'comment/', views.Comment.as_view()),
]
修改urls.py,完整代码如下:
from django.conf.urls import url,include
from django.contrib import admin
from app01 import app01_urls urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'api/', include(app01_urls)),
]
include表示导入py文件
RESTful API之视图
CBV
针对4种请求方式,使用FBV
def comment(request):
if request.method == "GET":
return HttpResponse("获取评论")
elif request.method == "POST":
return HttpResponse("创建新评论")
elif request.method == "PUT":
return HttpResponse("修改评论")
elif request.method == "DELETE":
return HttpResponse("删除评论")
这样写的话,一个4层if判断,就会有很冗长的代码。不利与维护,推荐使用CBV方式
CBV方式
from django import views
class Comment(views.View):
def get(self, request):
return HttpResponse("获取评论") def post(self, request):
return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
代码看着,就很清晰了。知道哪一种请求方式,该做哪些操作
APIView
之前学习django用的都是View,APIView它是个啥呢?
APIView与View的区别
APIView是View的子类
传递给请求处理程序的request实例是REST框架的请求实例,而不是Django的HttpRequest实例 处理程序返回的基于REST框架的Response,而不是Django的HttpResponse,视图函数将会管理内容协商,然后设置正确的渲染方式 任何APIException将会被捕捉,然后转换成合适的response对象 接收到的请求首先被认证,然后赋予相应的权限,然后通过节流器分发给相应的请求处理函数,类似.get()和.post()
APIView是专门写API的视图函数,结合serializers,非常方便做序列化!
关于APIView的源码解析,请参考文章:
https://blog.csdn.net/u013210620/article/details/79857654
APIView的请求参数,一般都在self.request.data里面。
但是对于GET,参数在self.request.query_params里面
修改views.py,完整代码如下:
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView # Create your views here. class DBG(serializers.Serializer): # 声明序列化器
id = serializers.IntegerField()
title = serializers.CharField()
create_time = serializers.DateField()
type = serializers.IntegerField()
school = serializers.CharField(source="school.name") class CYM(serializers.ModelSerializer): # 声明ModelSerializer
#
type = serializers.CharField(source='get_type_display') class Meta:
model = models.Article
fields = "__all__" # ("id", "title", "type")
depth = 1 # 官方推荐不超过10层 def article_list(request): # 查询所有
# 去数据库查询所有的文章数据
query_set = models.Article.objects.all()
xbg = CYM(query_set, many=True)
print(xbg.data)
# 返回
return JsonResponse(xbg.data, safe=False) def article_detail(request, id): # 查询单条数据
article_obj = models.Article.objects.filter(id=id).first()
xcym = CYM(article_obj)
return JsonResponse(xcym.data) class Comment(APIView):
def get(self, request):
print(request)
print(self.request.query_params) # get请求参数
print(self.request.data) # 其他请求方式参数,比如POST,PUT...
return HttpResponse("获取评论") def post(self, request):
print(self.request.query_params) # get请求参数
print(self.request.data) # 其他请求方式参数,比如POST,PUT...
return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
get请求
举例:get方式
点击Parsms设置参数age为18,那么url会自动变成http://127.0.0.1:8000/api/comment/?age=18
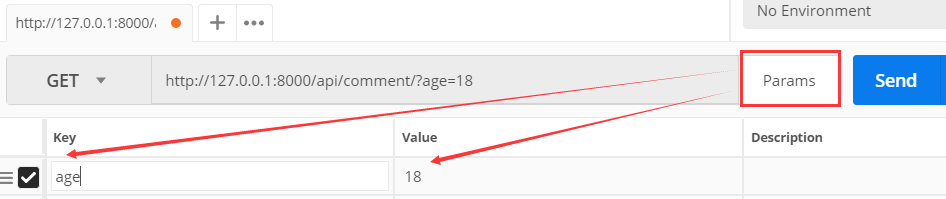
点击send,结果如下:

查看Pycharm控制台输出:
<rest_framework.request.Request object at 0x0000027A15ED9E80>
<QueryDict: {'age': ['18']}>
{}
post请求
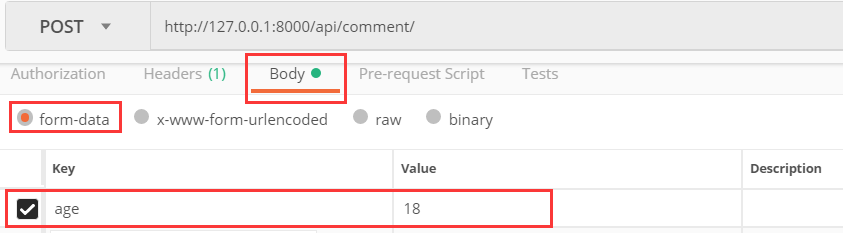
post请求参数,是在请求体中的,点击Body,默认数据格式为form-data,也就是表单提交
点击send,效果如下:
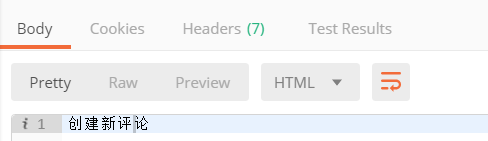
查看Pycharm控制台输出:
<QueryDict: {}>
<QueryDict: {'age': ['18']}>
可以发现get参数是空的,但是post是有参数的!
注意:针对提交类型不同,获取参数也是不同的!不一定就在self.request.data里面,
GET
get请求中参数都会以http://xxx.com/api/getjson?param1=asdf¶m2=123
这样的形式拼接在url后面.
在request对象中
request.query_params 中可以获取?param1=32¶m2=23形式的参数.
request.query_params 返回的数据类型为QueryDict
QueryDict转为普通python字典. query_params.dict()即可.
POST
post 请求参数都在请求体中, 但是其实你的url可以写成get的形式, 最终结果, 参数会有两部分组成, 一部分在url中, 一部分在http body 中, 但是非常不建议这样做.
接下来的代码编写也不会考虑这样的情况, post 仅考虑所有参数都在http body 中的情况.
| 提交类型 | 参数位置 | 参数类型 |
|---|---|---|
| form-data提交, | 参数在data中, | 类型为QueryDict |
| application/json提交 | 参数在data中 | 类型为dict |
| (swagger)使用接口文档提交, 由于使用curl提交, 虽然是post 但是参数依然被类似get的形式拼接到了url之后, | 此时 参数在query_params 中 | 类型为 QueryDict |
| x-www-form-urlencoded | 参数在data中 | 类型为 QueryDict |
PUT
| 提交类型 | 参数位置 | 参数类型 |
|---|---|---|
| form-data | request.data | QueryDict |
| application/json | request.data | dict |
| x-www-form-urlencoded | request.data | QueryDict |
| (swagger) | request.data | dict |
PATCH
| 提交类型 | 参数位置 | 参数类型 |
|---|---|---|
| form-data | request.data | QueryDict |
| application/json | request.data | dict |
| x-www-form-urlencoded | request.data | QueryDict |
| (swagger) | request.data | dict |
DELETE
| 提交类型 | 参数位置 | 参数类型 |
|---|---|---|
| form-data | request.data | QueryDict |
| application/json | request.data | dict |
| x-www-form-urlencoded | request.data | QueryDict |
| (swagger) | request.query_params | QueryDict |
| iOS端提交和get情况一样 | request.query_params | QueryDict |
更多详细信息,请参考:
https://www.jianshu.com/p/f2f73c426623
三、DRF 序列化
DRF是django rest framework的简称
表结构:
还是以about_drf项目为例,增加几个表,models.py完整代码如下:
from django.db import models # Create your models here. # 文章表
class Article(models.Model):
title = models.CharField(max_length=32, unique=True, error_messages={"unique": "文章标题不能重复"})
# 文章发布时间
# auto_now每次更新的时候会把当前时间保存
create_time = models.DateField(auto_now_add=True)
# auto_now_add 第一次创建的时候把当前时间保存
update_time = models.DateField(auto_now=True)
# 文章的类型
type = models.SmallIntegerField(
choices=((1, "原创"), (2, "转载")),
default=1
)
# 来源
school = models.ForeignKey(to='School', on_delete=models.CASCADE)
# 标签
tag = models.ManyToManyField(to='Tag') # 文章来源表
class School(models.Model):
name = models.CharField(max_length=16) # 文章标签表
class Tag(models.Model):
name = models.CharField(max_length=16) # 评论表
class Comment(models.Model):
content = models.CharField(max_length=128)
article = models.ForeignKey(to='Article', on_delete=models.CASCADE)
使用2个命令,生成表
python manage.py makemigrations
python manage.py migrate
使用navicat打开sqlite3数据库,增加几条数据
# 评论表
INSERT INTO app01_comment ("id", "content", "article_id") VALUES (1, '呵呵', 1);
INSERT INTO app01_comment ("id", "content", "article_id") VALUES (2, '哈哈', 2);
INSERT INTO app01_comment ("id", "content", "article_id") VALUES (3, '嘿嘿', 3);
INSERT INTO app01_comment ("id", "content", "article_id") VALUES (4, '嘻嘻', 2);
INSERT INTO app01_comment ("id", "content", "article_id") VALUES (5, '呜呜', 1); # 文章表
INSERT INTO app01_article ("id", "create_time", "update_time", "type", "school_id", "title") VALUES (4, '2018-08-01', '2018-08-01', 1, 1, 'Linux全都是记不住的命令'); # 文章和标签关系表
INSERT INTO app01_article_tag ("id", "article_id", "tag_id") VALUES (3, 2, 1);
INSERT INTO app01_article_tag ("id", "article_id", "tag_id") VALUES (4, 4, 1);
INSERT INTO app01_article_tag ("id", "article_id", "tag_id") VALUES (5, 4, 2);
INSERT INTO app01_article_tag ("id", "article_id", "tag_id") VALUES (6, 4, 3);
查看评论表记录

查看文章表记录

查看文章和标签关系表
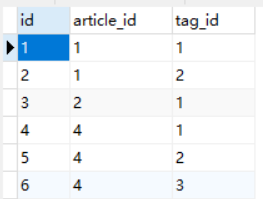
单表的GET和POST:
使用serializers序列化,针对每一个表,需要单独写函数。一般会写在views.py里面,但是这样做,会导致整个文件代码过长。需要分离出来!
在app01(应用名)目录下,创建文件app01_serializers.py,表示自定义序列化
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
depth = 2 # 深度为2
修改app01_urls.py,注释掉多余的路径
from django.conf.urls import url
from app01 import views urlpatterns = [
# url(r'^article_list/', views.article_list),
# url(r'article_detail/(\d+)', views.article_detail), # 评论
url(r'comment/', views.Comment.as_view()),
]
修改views.py,删除多余的代码,并使用app01_serializers
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化 # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return JsonResponse(res) def post(self, request):
return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
使用postman发送get请求,不带参数。效果如下:

Response
Rest framework 引入了Response对象,它是一个TemplateResponse类型,并根据客户端需求正确返回需要的类型。
使用前,需要导入模块Response
from rest_framework.response import Response
语法:
return Response(data) # 根据客户端的需求返回不同的类型。
举例:
修改视图Comment中的get方法,将JsonResponse改成Response
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
使用浏览器访问url: http://127.0.0.1:8000/api/comment/
出现错误,找不到模板文件
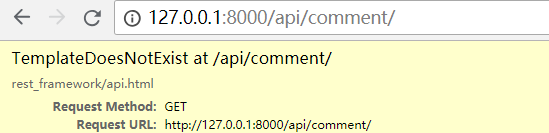
注意:使用postman,访问get请求,是不会报错的。但是使用浏览器访问,会报错。因为浏览器要渲染页面!
修改settings.py,在INSTALLED_APPS配置项中,最后一行添加rest_framework
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'rest_framework',
]
刷新页面,效果如下:
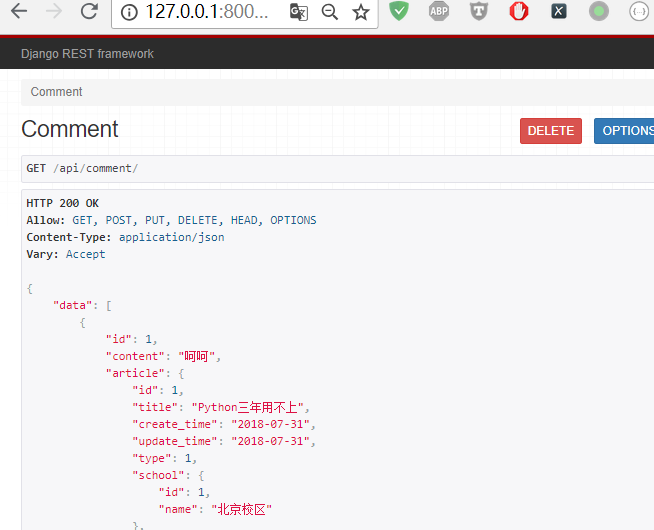
这个页面,可以发送post请求
serializers校验
之前学到了form组件校验,那么serializers也可以校验。
校验空数据
举例:判断空数据
修改views.py,添加post逻辑代码。注意:使用is_valid校验
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": 0}
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
pass
else:
# 表示数据有问题
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
使用postman发送一个空数据的post请求
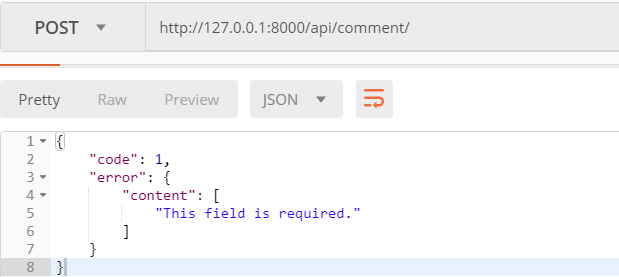
它返回This field is required,表示次字段不能为空!
错误信息中文显示
修改app01_serializers.py,使用extra_kwargs指定错误信息
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
}
重启django,重新发送空的post请求
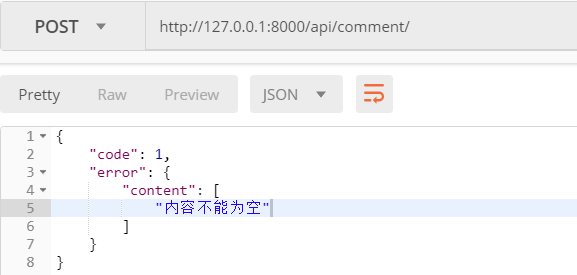
发送一个带参数的post请求,注意key为content

code为0表示成功了!看一下app01_comment表记录,发现并没有增加数据?为什么呢?因为成功时,执行了pass,并没有执行插入操作!
外键的GET和POST
序列化校验
上面虽然只发送了content参数,就让通过了,显然不合理!为什么呢?
因为app01_comment表有2个字段,content和article。这2个字段都应该校验才对!
因为serializers默认校验时,排除了外键字段。比如article
要对外键进行校验,必须在extra_kwargs中指定外键字段
修改app01_serializers.py,注意关闭depth参数
当序列化类MATE中定义了depth时,这个序列化类中引用字段(外键)则自动变为只读,所以进行更新或者创建操作的时候不能使用此序列化类
大概意思就是,使用了depth参数,会忽略外键字段
完整代码如下:
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
再次发送post请求,还是只有一个参数content
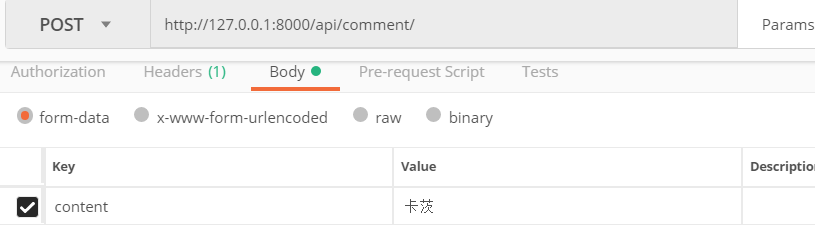
查看执行结果:
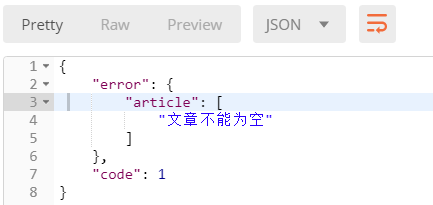
发送正确的2个参数
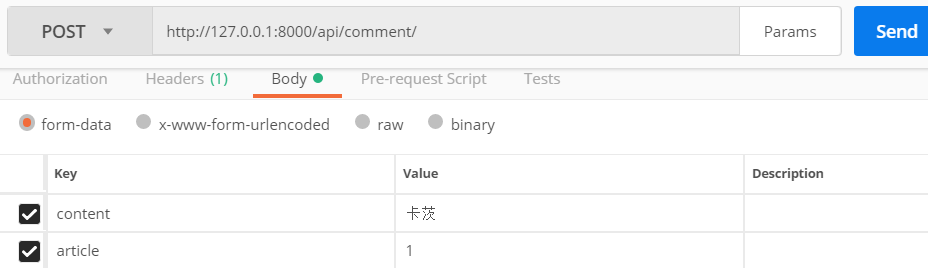
查看结果
read_only=True
read_only:True表示不允许用户自己上传,只能用于api的输出。如果某个字段设置了read_only=True,那么就不需要进行数据验证,只会在返回时,将这个字段序列化后返回
举例:允许article不校验
修改app01_serializers.py,加入一行代码
article = serializers.SerializerMethodField(read_only=True)
完整代码如下:
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
article = serializers.SerializerMethodField(read_only=True) class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
只发content参数

查看结果,发现通过了!

这个参数在什么场景下,使用呢?
举个简单的例子:在用户进行购物的时候,用户post订单时,肯定会产生一个订单号,而这个订单号应该由后台逻辑完成,而不应该由用户post过来,如果不设置read_only=True,那么验证的时候就会报错
保存post数据
修改views.py,在post方法中,将pass改成ser_obj.save(),完整代码如下:
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": 0}
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论")
修改app01_serializers.py,注释掉read_only=True
from app01 import models
from rest_framework import serializers # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
发送2个正确的参数
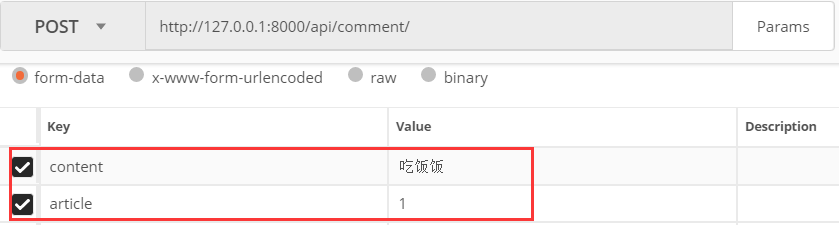
查看返回结果
查看app01_comment表记录,发现多了一条记录

为什么直接save,就可以保存了呢?
因为它将校验过的数据传过去了,就好像form组件中的self.cleaned_data一样
本质上还是调用ORM的create()方法
非serializer 的验证条件
比如重置密码、修改密码都需要手机验证码。但是用户 model 里面并没有验证码这个选项
需要使用validate,用于做校验的钩子函数,类似于form组件的clean_字段名
使用时,需要导入模块,用来输出错误信息
from rest_framework.validators import ValidationError
局部钩子
validate_字段名,表示局部钩子。
举例:评论的内容中,不能包含 "草"
修改app01_serializers.py,校验评论内容
from app01 import models
from rest_framework import serializers
from rest_framework.validators import ValidationError # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) # 用于做校验的钩子函数,类似于form组件的clean_字段名
def validate_content(self, value):
if '草' in value:
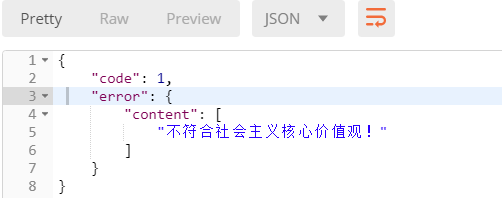
raise ValidationError('不符合社会主义核心价值观!')
else:
return value class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
}
使用postman发送包含关键字的评论
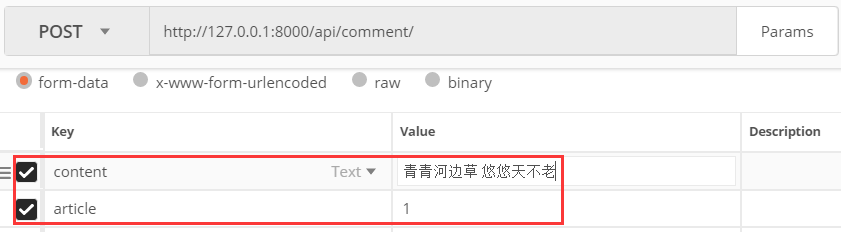
查看返回结果:
全局钩子
validate,表示全局钩子。
比如在用户注册时,我们需要填写验证码,这个验证码只需要验证,不需要保存到用户这个Model中:
def validate(self, attrs):
del attrs["code"]
return attrs
这里就不演示了,about_drf项目还没有验证码功能!
多对多的GET和POST
路由
修改app01_urls.py,增加路由
from django.conf.urls import url
from app01 import views urlpatterns = [
# 文章
url(r'article/', views.Article.as_view()),
# 评论
url(r'comment/', views.Comment.as_view()),
]
GET
修改views.py,增加视图函数
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": 0}
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论") # 文章CBV
class Article(APIView):
def get(self, request):
res = {"code": 0}
all_article = models.Article.objects.all()
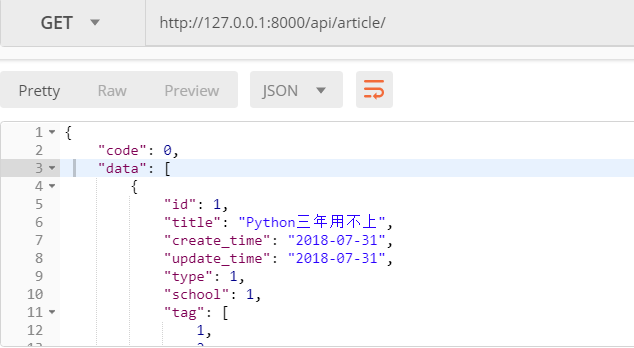
ser_obj = app01_serializers.ArticleModelSerializer(all_article, many=True)
res["data"] = ser_obj.data
return Response(res)
修改app01_serializers.py,增加文章的序列化类
from app01 import models
from rest_framework import serializers
from rest_framework.validators import ValidationError # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) # 用于做校验的钩子函数,类似于form组件的clean_字段名
def validate_content(self, value):
if '草' in value:
raise ValidationError('不符合社会主义核心价值观!')
else:
return value #全局的钩子
def validate(self, attrs):
# self.validated_data # 经过校验的数据 类似于form组件中的cleaned_data
# 全局钩子
pass class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
} # 文章的序列化类
class ArticleModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article # 绑定的ORM类是哪一个
fields = "__all__" # ["id", "title", "type"]
# depth = 1 # 官方推荐不超过10层
发送get请求
POST
修改views.py,增加post
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": 0}
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论") # 文章CBV
class Article(APIView):
def get(self, request):
res = {"code": 0}
all_article = models.Article.objects.all()
ser_obj = app01_serializers.ArticleModelSerializer(all_article, many=True)
res["data"] = ser_obj.data
return Response(res) def post(self, request):
res = {"code": 0}
ser_obj = app01_serializers.ArticleModelSerializer(data=self.request.data)
if ser_obj.is_valid():
ser_obj.save()
else:
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res)
发送post请求,增加参数type

查看结果
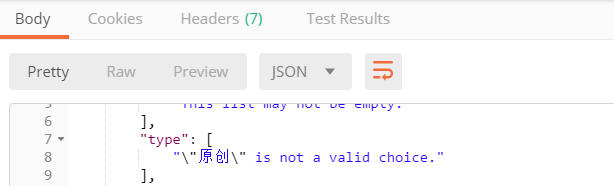
提示不是一个有效的选项,为什么呢?因为article表的type字段的值,只有1和2。不能是其他的值!
增加正确的值
先使用postman发送get请求,然后复制一段json数据
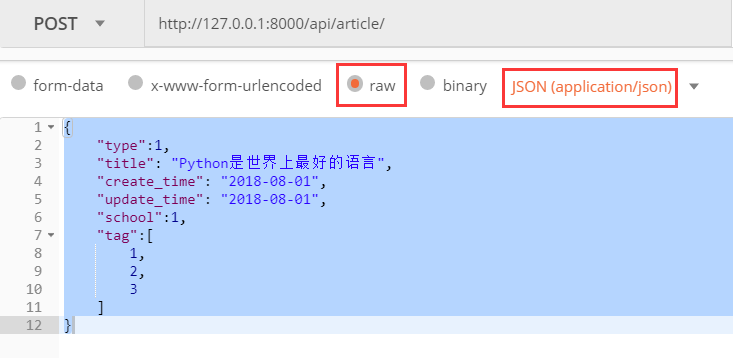
再使用postman发送post请求,参数如下
{
"type":1,
"title": "Python是世界上最好的语言",
"create_time": "2018-08-01",
"update_time": "2018-08-01",
"school":1,
"tag":[
1,
2,
3
]
}
注意参数类型为raw,表示未经过加工的。选择json格式
查看返回状态,提示成功了
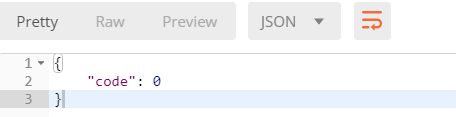
查看app01_article表,发现多了一条记录
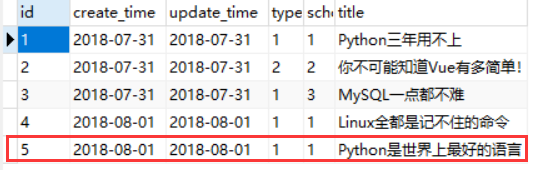
唯一校验
article表的titie加了唯一属性,在添加时,需要判断标题是否存在。
那么serializers是不能做唯一校验的,为什么呢?
针对这个问题,有人向官方提问了,官方回复,ORM可以做,这里就没有必要做了!
重新提交上面的post请求,结果输出:
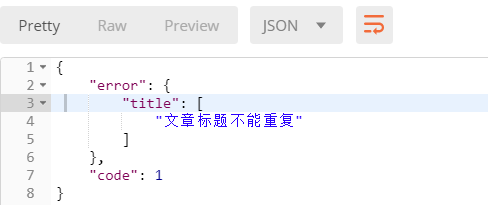
这个中文提示,是在ORM的error_messages参数定义的
title = models.CharField(max_length=32, unique=True, error_messages={"unique": "文章标题不能重复"})
它还可以定义其他错误,比如长度,为空,唯一...
超链接的序列化
HyperlinkedModelSerializer类类似于ModelSerializer类,不同之处在于它使用超链接来表示关联关系而不是主键。
默认情况下序列化器将包含一个url字段而不是主键字段。
url字段将使用HyperlinkedIdentityField字段来表示,模型的任何关联都将使用HyperlinkedRelatedField字段来表示。
你可以通过将主键添加到fields选项中来显式的包含,例如:
class AccountSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Account
fields = ('url', 'id', 'account_name', 'users', 'created')
绝对和相对URL
当实例化一个HyperlinkedModelSerializer时,你必须在序列化器的上下文中包含当前的request值,例如:
serializer = AccountSerializer(queryset, context={'request': request})
这样做将确保超链接可以包含恰当的主机名,一边生成完全限定的URL,例如:
http://api.example.com/accounts/1/
而不是相对的URL,例如:
/accounts/1/
如果你真的要使用相对URL,你应该明确的在序列化器上下文中传递一个{'request': None}。
需求:要求api返回结果中,school展示的是超链接
路由
修改app01_urls.py,增加路由
urlpatterns = [
# 文章
url(r'article/', views.Article.as_view()),
url(r'article/(?P<pk>\d+)', views.ArticleDetail.as_view(), name='article-detail'),
# 学校
url(r'school/(?P<id>\d+)', views.SchoolDetail.as_view(), name='school-detail'),
# 评论
url(r'comment/', views.Comment.as_view()),
]
指定name是为做反向链接,它能解析出绝对url
序列化
修改app01_serializers.py
from app01 import models
from rest_framework import serializers
from rest_framework.validators import ValidationError # 序列化评论的类
class CommentSerializer(serializers.ModelSerializer):
# article = serializers.SerializerMethodField(read_only=True) # 用于做校验的钩子函数,类似于form组件的clean_字段名
def validate_content(self, value):
if '草' in value:
raise ValidationError('不符合社会主义核心价值观!')
else:
return value #全局的钩子
def validate(self, attrs):
# self.validated_data # 经过校验的数据 类似于form组件中的cleaned_data
# 全局钩子
pass class Meta:
model = models.Comment # Comment表
fields = "__all__" # 序列化所有字段
# depth = 2 # 深度为2
# 定义额外的参数
extra_kwargs = {
"content": {
"error_messages": {
"required": '内容不能为空',
}
},
"article": {
"error_messages": {
"required": '文章不能为空'
}
}
} # 文章的序列化类
class ArticleModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Article # 绑定的ORM类是哪一个
fields = "__all__" # ["id", "title", "type"]
# depth = 1 # 官方推荐不超过10层 # 文章超链接序列化
class ArticleHyperLinkedSerializer(serializers.HyperlinkedModelSerializer):
school = serializers.HyperlinkedIdentityField(view_name='school-detail', lookup_url_kwarg='id') class Meta:
model = models.Article # 绑定的ORM类是哪一个
fields = ["id", "title", "type", "school"] # 学校的序列化
class SchoolSerializer(serializers.ModelSerializer):
class Meta:
model = models.School
fields = "__all__"
参数解释:
source 表示来源
lookup_field 表示查找字段,默认使用的pk, 指的是反向生成URL的时候, 路由中分组命名匹配的value
lookup_url_kwarg 表示路由查找的参数,pk表示主键, 默认使用pk,指的是反向生成URL的时候 路由中的分组命名匹配的key
view_name 它是指urls定义的name值,一定要一一对应。 默认使用 表名-detail
修改views.py,增加视图函数
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
from django import views
from rest_framework.views import APIView
from app01 import app01_serializers # 导入自定义的序列化
from rest_framework.response import Response # Create your views here. class Comment(APIView):
def get(self, request):
res = {"code":0} # 默认状态
all_comment = models.Comment.objects.all()
# print(all_comment)
# 序列化,many=True表示返回多条
ser_obj = app01_serializers.CommentSerializer(all_comment, many=True)
res["data"] = ser_obj.data return Response(res) def post(self, request):
res = {"code": 0}
# 去提交的数据
comment_data = self.request.data
# 对用户提交的数据做校验
ser_obj = app01_serializers.CommentSerializer(data=comment_data)
if ser_obj.is_valid():
# 表示数据没问题,可以创建
ser_obj.save()
else:
# 表示数据有问题
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # return HttpResponse("创建新评论") def put(self, request):
return HttpResponse("修改评论") def delete(self, request):
return HttpResponse("删除评论") # 文章CBV
class Article(APIView):
def get(self, request):
res = {"code": 0}
all_article = models.Article.objects.all()
ser_obj = app01_serializers.ArticleHyperLinkedSerializer(all_article, many=True, context={'request': request})
res["data"] = ser_obj.data
return Response(res) def post(self, request):
res = {"code": 0}
ser_obj = app01_serializers.ArticleModelSerializer(data=self.request.data)
if ser_obj.is_valid():
ser_obj.save()
else:
res["code"] = 1
res["error"] = ser_obj.errors
return Response(res) # 文章详情CBV
class ArticleDetail(APIView):
def get(self, request, pk):
res = {"code": 0}
article_obj = models.Article.objects.filter(pk=pk).first()
# 序列化
ser_obj = app01_serializers.ArticleHyperLinkedSerializer(article_obj, context={'request': request})
res["data"] = ser_obj.data
return Response(res) # 学校详情CBV
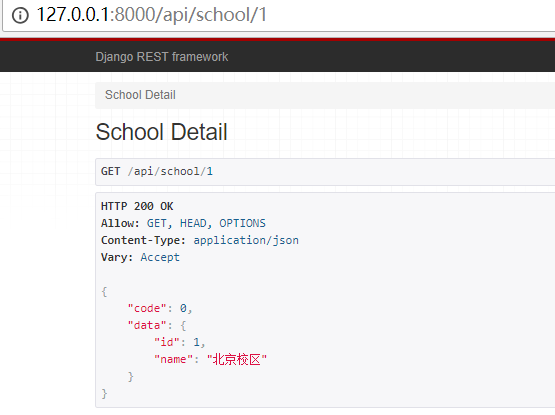
class SchoolDetail(APIView):
def get(self, request, id):
res = {"code": 0}
school_obj = models.School.objects.filter(pk=id).first()
ser_obj = app01_serializers.SchoolSerializer(school_obj, context={'request': request})
res["data"] = ser_obj.data
return Response(res)
参数解释:
id 表示参数,它和url的参数,是一一对应的
content 表示上下文
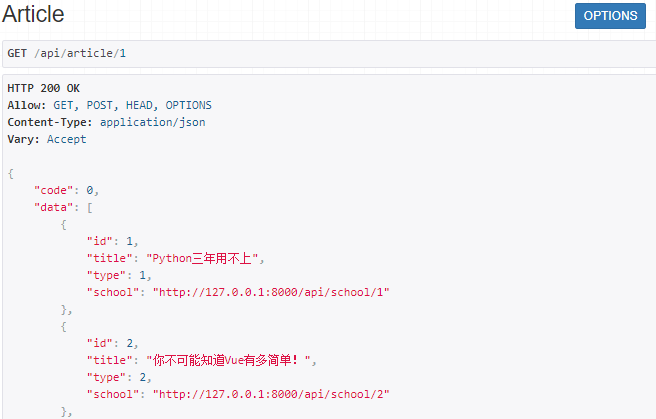
重启django项目,访问网页:
http://127.0.0.1:8000/api/article/1
效果如下:
点击第一个链接,效果如下:
今日内容总结:
1. RESTful风格API介绍
2. from rest_framework import APIView class Comment(views.View):
pass -------- 之前的写法 ↑ ---------- class APIView(views.View):
扩展的功能
self.request = Resquest(
self._request = request(Django的request)
)
self.request.data 封装好的数据属性,POST\PUT请求携带的数据都可以从这里取
pass class Comment(APIView):
pass 3. serializer
1. ModelSerializer
1. 基于APIView实现的GET和POST
2. POST过来的数据进行校验
3. 保存数据
2. 超链接的URL
python 全栈开发,Day95(RESTful API介绍,基于Django实现RESTful API,DRF 序列化)的更多相关文章
- python 全栈开发,Day94(Promise,箭头函数,Django REST framework,生成json数据三种方式,serializers,Postman使用,外部python脚本调用django)
昨日内容回顾 1. 内容回顾 1. VueX VueX分三部分 1. state 2. mutations 3. actions 存放数据 修改数据的唯一方式 异步操作 修改state中数据的步骤: ...
- python 全栈开发,Day45(html介绍和head标签,body标签中相关标签)
一.html介绍 1.web标准 web准备介绍: w3c:万维网联盟组织,用来制定web标准的机构(组织) web标准:制作网页遵循的规范 web准备规范的分类:结构标准.表现标准.行为标准. 结构 ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- Python 全栈开发【第0篇】:目录
Python 全栈开发[第0篇]:目录 第一阶段:Python 开发入门 Python 全栈开发[第一篇]:计算机原理&Linux系统入门 Python 全栈开发[第二篇]:Python基 ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
- Python全栈开发
Python全栈开发 一文让你彻底明白Python装饰器原理,从此面试工作再也不怕了. 一.装饰器 装饰器可以使函数执行前和执行后分别执行其他的附加功能,这种在代码运行期间动态增加功能的方式,称之为“ ...
- Win10构建Python全栈开发环境With WSL
目录 Win10构建Python全栈开发环境With WSL 启动WSL 总结 对<Dev on Windows with WSL>的补充 Win10构建Python全栈开发环境With ...
随机推荐
- android studio 统一管理版本号配置
1.在android 的根目录新建一个versions.gradle 2.在这里面声明 各个第三方库的版本,写法有两种,第一种,写ext 扩展, 引用的时候, 第二种: 然后在project级的bui ...
- mysql的事件
mysql的事件定时器的使用: SHOW VARIABLES LIKE 'event_scheduler' --查询event_scheduler开启状态 SET GLOBAL event_sched ...
- Objects源码解析
Objects类解析 JDK7新增Objects类介绍(以下程序以1.8来说明) 简介: JDK7里面新增的Objects类,本人学习HashMap源码偶遇此类,所以研究一下,本类将对象常用的 ...
- wFuzz使用帮助
******************************************************** * Wfuzz 2.0 - The Web Bruteforcer * ******* ...
- Debian Linux Error “Driver 'pcspkr' is already registered, aborting...”
问题: Error: Driver ‘pcspkr’ is already registered, aborting… 解决: [root@reistlin.com ~]# echo "bl ...
- 【逆向工具】使用x64dbg+spy去除WinRAR5.40(64位)广告弹框
1 学习目标 WinRAR5.40(64位)的弹框广告去除,由于我的系统为x64版本,所以安装了WinRAR(x64)版本. OD无法调试64位的程序,可以让我熟悉x64dbg进行调试的界面. 其次是 ...
- Getting started with machine learning in Python
Getting started with machine learning in Python Machine learning is a field that uses algorithms to ...
- CentOS挂载光盘
mkdir /mnt/cdrom mount /dev/cdrom /mnt/cdrom umount /dev/cdrom /mnt/cdrom 在Ambari集群中配置192.168.0.210: ...
- Linux系统调用的运行过程【转】
本文转自:http://blog.csdn.net/kernel_learner/article/details/7331505 在Linux中,系统调用是用户空间访问内核的唯一手段,它们是内核唯一的 ...
- aiohttp分流处理
# -*- coding: utf-8 -*- # @Time : 2018/12/26 9:55 PM # @Author : cxa # @Software: PyCharm import asy ...