ML平台_Angel参考
Angel 是腾讯开源基于参数服务器(Parameter Server)理念的机器学习框架(为支持超大维度机器学习模型运算而生)。核心设计理念围绕模型,它将高维度的大模型切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及灵活的同步协议,实现机器学习算法的高效运行。,开源代码地址:https://github.com/Tencent/angel。 Angel 由 Java 和 Scala 开发,基于 Yarn 调度运行,既能独立运行,高效运行特有的算法,亦能作为 PS Service,支持 Spark 或其它深度学习框架,为其加速。它基于腾讯内部的海量数据进行了反复的实践和调优,并具有广泛的适用性和稳定性,模型维度越高,优势越明显。
解释
- BSP:(Bulk Synchronous Parallel 整体同步并行计算模型),BSP的概念由Valiant(1990)提出的,“块”同步模型,是一种异步MIMD-DM模型,支持消息传递系统,块内异步并行,块间显式同步,该模型基于一个master协调,所有的worker同步(lock-step)执行, 数据从输入的队列中读取
- SSP:(Stale Synchronous Parallel)
- ASP:(Asynchronous Parallel)
研发背景
腾讯公司是一家消息平台 + 数字内容的公司,本质上也是一家大数据公司,每天产生数千亿的收发消息,超过 10 亿的分享图片,高峰期间百亿的收发红包。每天产生的看新闻、听音乐、看视频的流量峰值高达数十 T。这么大的数据量,处理和使用上需求如下:
- 首先业务上存在三大痛点:
- 第一,需要具备 T/P 级的数据处理能力,几十亿、百亿级的数据量,基本上 30 分钟就要能算出来。
- 第二,成本需低,可以使用很普通的 PC Server,就能达到以前小型机一样的效果;
- 第三,容灾方面,原来只要有机器宕机,业务的数据肯定就有影响,各种报表、数据查询,都会受到影响。
- 其次是需要融合所有产品平台的数据的能力。“以前的各产品的数据都是分散在各自的 DB 里面的,是一个个数据孤岛,现在,需要以用户为中心,建成了十亿用户量级、每个用户万维特征的用户画像体系。以前的用户画像,只有十几个维度主要就是用户的一些基础属性,比如年龄、性别、地域等,构建一次要耗费很多天,数据都是按月更新”。
- 另外就是需要解决速度和效率方面的问题,以前的数据平台“数据是离线的,任务计算是离线的,实时性差”。
“所以,我们必须要建设一个能支持超大规模数据集的一套系统,能满足 billion 级别的维度的数据训练,而且,这个系统必须能满足我们应用需求的一个工业级的系统。它能解决 big data,以及 big model 的需求,它既能做数据并行,也能做模型并行。”
经过 7 年的不断发展,历经了三代大数据平台:第一代 TDW(腾讯分布式数据仓库), 到基于 Spark 融合 Storm 的第二代实时计算架构,到现在形成了第三代的平台,核心为 Angel 的高性能计算平台。
- Angel 项目在 2014 年开始准备,15 年初正式启动,刚启动只有 4 个人,后来逐步壮大。项目跟北京大学和香港科技大学合作,一共有 6 个博士生加入到腾讯大数据开发团队。目前在系统、算法、配套生态等方面开发的人员,测试和运维,以及产品策划及运维,团队超过 30 人。
- Angel 平台是使用 Java 和 Scala 混合开发的机器学习框架,用户可以像用 Spark, MapReduce 一样,用它来完成机器学习的模型训练。
- Angel 采用参数服务器架构,支持十亿级别维度的模型训练。采用了多种业界最新技术和腾讯自主研发技术,如 SSP(Stale synchronous Parallel)、异步分布式 SGD、多线程参数共享模式 HogWild、网络带宽流量调度算法、计算和网络请求流水化、参数更新索引和训练数据预处理方案等。
- 这些技术使 Angel 性能大幅提高,达到常见开源系统 Spark 的数倍到数十倍,能在千万到十亿级的特征维度条件下运行。
- 自在腾讯内部上线以来,Angel 已应用于腾讯视频、腾讯社交广告及用户画像挖掘等精准推荐业务。未来还将不断拓展应用场景,目标是支持腾讯等企业级大规模机器学习任务。
腾讯为何要选择自研?
- 首先需要一个满足十亿级维度的工业级的机器学习平台,当时有两种思路: 一个是基于第二代平台的基础上做演进,解决大规模参数交换的问题。另外一个,就是新建设一个高性能的计算框架。
- 当时有研究业内比较流行的几个产品:GraphLab,主要做图模型,容错差;Google 的 Distbelief,还没开源;还有 CMU Eric Xing 的 Petuum,当时很火,不过它更多是一个实验室的产品,易用性和稳定性达不到要求。
- “其实在第二代,我们已经尝试自研,我们消息中间件,不论是高性能的,还是高可靠的版本,都是我们自研的。他们经历了腾讯亿万流量的考验,这也给了我们在自研方面很大的信心”。
- “同时,第三代高性能计算平台,还需要支持 GPU 深度学习,支持文本、语音、图像等非结构化的数据”。
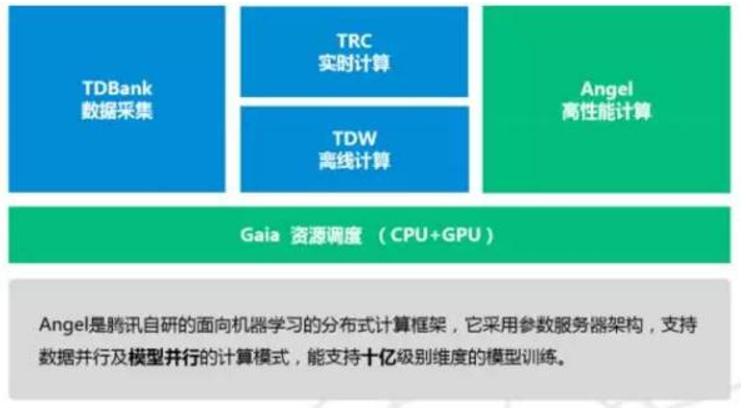
Angel 的整体架构
Angel在整体架构上参考了谷歌的DistBelief。DistBeilef最初是为深度学习而设计,它使用了参数服务器,以解决巨大模型在训练时的更新问题。参数服务器同样可用于机器学习中非深度学习的模型,如SGD、ADMM、LBFGS的优化算法在面临在每轮迭代上亿个参数更新的场景中,需要参数分布式缓存来拓展性能。Angel在运算中支持BSP、SSP、ASP三种计算模型,其中SSP是由卡耐基梅隆大学EricXing在Petuum项目中验证的计算模型,能在机器学习的这种特定运算场景下提升缩短收敛时间。系统有五个角色:
- Master:负责资源申请和分配,以及任务的管理。
- Task:负责任务的执行,以线程的形式存在。
- Worker:独立进程运行于Yarn的Container中,是Task的执行容器。
- ParameterServer:随着一个任务的启动而生成,任务结束而销毁,负责在该任务训练过程中的参数的更新和存储。
WorkerGroup为一个虚拟概念,由若干个Worker组成,元数据由Master维护。为模型并行拓展而考虑,在一个WorkerGroup内所有Worker运行的训练数据都是一样的。虽然我们提供了一些通用模型,但并不保证都满足需求,而用户自定义的模型实现可以实现我们的通用接口,形式上等同于MapReduce或Spark
详细结构如下图
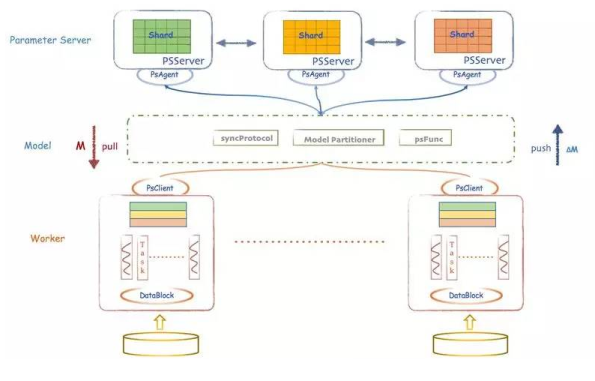
- Angel 在运算中支持 BSP(Bulk Synchronous Parallel 整体同步并行计算模型)、SSP(Stale Synchronous Parallel)、ASP(Asynchronous Parallel) 三种计算模型,其中 SSP 是由卡耐基梅隆大学 EricXing 在 Petuum 项目中验证的计算模型,能在机器学习的这种特定运算场景下提升缩短收敛时间。
- Angel 支持数据并行及模型并行。
- 使用了港科大杨强教授的团队做的诸葛弩来做网络调度,ParameterServer 优先服务较慢的 Worker,当模型较大时,能明显降低等待时间,任务总体耗时下降 5%~15%。另外,Angel 整体是跑在 Gaia(Yarn)平台上面的
Angel主要模块:
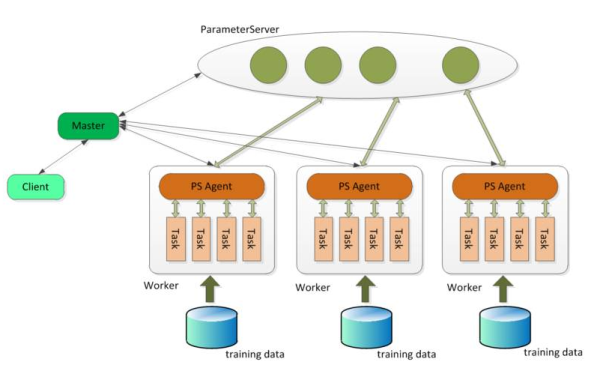
Client作为客户端可以发送启动或停止、加载或存储模型命令,可以获取运行状态;具体的任务分配、协调调度、资源申请由Master完成;Parameter Sever复杂存储和更新参数,一个Angel计算任务中可以包含多个ParameterSever实例,随着任务启动而生成,随着任务结束而销毁;Work实例负责具体的模型训练或者结果推理,每个Worker可以包含一个或者多个Task,这样的Task可以更方便地共享Worker的公共资源。
- Client: Angel 的客户端,它给应用程序提供了控制任务运行的功能。目前它支持的控制接口主要有:启动和停止 Angel 任务,加载和存储模型,启动具体计算过程和获取任务运行状态等。
- Master: Master 的职责主要包括:原始计算数据以及参数矩阵的分片和分发;向 Gaia(一个基于 Yarn 二次开发的资源调度系统)申请 Worker 和 ParameterServer 所需的计算资源; 协调,管理和监控 Worker 以及 ParameterServer。
- Parameter Server: ParameterServer 负责存储和更新参数,一个 Angel 计算任务可以包含多个 ParameterServer 实例,而整个模型分布式存储于这些 ParameterServer 实例中,这样可以支撑比单机更大的模型。
- Worker: Worker负责具体的模型训练或者结果预测,为了支持更大规模的训练数据,一个计算任务往往包含许多个 Worker 实例,每个 Worker 实例负责使用一部分训练数据进行训练。一个 Worker 包含一个或者多个 Task,Task 是 Angel 计算单元,这样设计的原因是可以让 Task 共享 Worker 的许多公共资源。
Angel 的系统框架如下图:
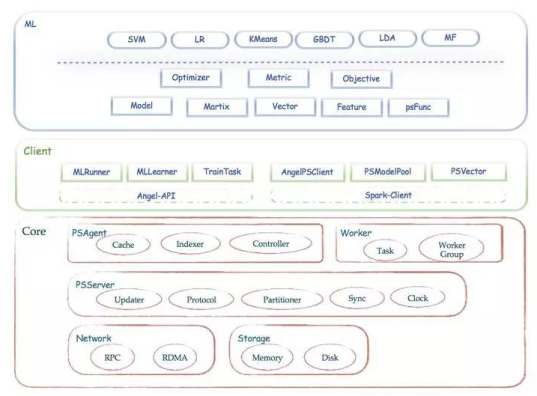
- PS Service: Angel 支持两种运行模式:ANGEL_PS & ANGEL_PS_WORKER
- ANGEL_PS: PS Service 模式,在这种模式下,Angel 只启动 Master 和 PS,具体的计算交给其他计算平台(如 Spark,Tensorflow)负责,Angel 只负责提供 Parameter Server 的功能。
- ANGEL_PS_WORKER:启动 Master,PS 和 Worker,Angel 独立完成模型的训练。
- 良好的可扩展性: psf(ps function)为了满足各类算法对参数服务器的特殊需求,Angel 将参数获取和更新过程进行了抽象,提供了 psf 函数功能。用户只需要继承 Angel 提供的 psf 函数接口,并实现自己的参数获取 / 更新逻辑,就可以在不修改 Angel 自身代码的情况下定制自己想要的参数服务器的接口。
- 同步协议: 支持多种同步协议:除了通用的 BSP(Bulk Synchronous Parallel)外,为了解决 task 之间互相等待的问题,Angel 还支持 SSP(Stale Synchronous Parallel)和 ASP(Asynchronous Parallel)
- 自定义数据格式:Angel 支持 Hadoop 的 InputFormat 接口,可以方便的实现自定义文件格式。
- 自定义模型切分方式:默认情况下,Angel 将模型(矩阵)切分成大小相等的矩形区域;用户也可以自定义分区类来实现自己的切分方式。
- 易用性: 训练数据和模型自动切割:Angel 根据配置的 worker 和 task 数量,自动对训练数据进行切分;同样,也会根据模型大小和 PS 实例数量,对模型实现自动分区。
- 易用的编程接口:MLModel/PSModel/AngelClient
容错设计和稳定性
- PS 容错: PS 容错采用了 checkpoint 的模式,也就是每隔一段时间将 PS 承载的参数分区写到 hdfs 上去。如果一个 PS 实例挂掉,Master 会新启动一个 PS 实例,新启动的 PS 实例会加载挂掉 PS 实例写的最近的一个 checkpoint,然后重新开始服务。这种方案的优点是简单,借助了 hdfs 多副本容灾, 而缺点就是不可避免的会丢失少量参数更新。
- Worker 容错: 一个 Worker 实例挂掉后,Master 会重新启动一个 Worker 实例,新启动的 Worker 实例从 Master 处获取当前迭代轮数等状态信息,从 PS 处获取最新模型参数,然后重新开始被断掉的迭代。
- Master 容错: Master 定期将任务状态写入 hdfs,借助与 Yarn 提供的 App Master 重试机制,当 Angel 的 Master 挂掉后,Yarn 会重新拉起一个 Angel 的 Master,新的 Master 加载状态信息,然后重新启动 Worker 和 PS,从断点出重新开始计算。
- 慢 Worker 检测: Master 会将收集一些 Worker 计算性能的一些指标,如果检测到有一些 Worker 计算明显慢于平均计算速度,Master 会将这些 Worker 重新调度到其他的机器上,避免这些 Worker 拖慢整个任务的计算进度。
Spark on Angel
Angel 在 1.0 版本开始,就加入了 PS-Service 的特性,不仅仅可以作为一个完整的 PS 框架运行,也可以作为一个 PS-Service,为不具备参数服务器能力的分布式框架,引入 PS 能力,从而让它们运行得更快,功能更强。而 Spark 是这个 Service 设计的第一个获益者。作为一个比较流行的内存计算框架,Spark 的核心概念是 RDD,而 RDD 的关键特性之一,是其不可变性,来规避分布式环境下复杂的各种并行问题。这个抽象,在数据分析的领域是没有问题的,能最大化的解决分布式问题,简化各种算子的复杂度,并提供高性能的分布式数据处理运算能力。
然而在机器学习领域,RDD 的弱点很快也暴露了。机器学习的核心是迭代和参数更新。RDD 凭借着逻辑上不落地的内存计算特性,可以很好的解决迭代的问题,然而 RDD 的不可变性,却不适合参数反复多次更新的需求。这个根本的不匹配性,导致了 Spark 的 MLLib 库,发展一直非常缓慢,从 15 年开始就没有实质性的创新,性能也不好,从而给了很多其它产品机会。而 Spark 社区,一直也不愿意正视和解决这个问题。
现在,由于 Angel 良好的设计和平台性,提供 PS-Service,Spark 可以充分利用 Angel 的参数更新能力,用最小化的修改代价,让 Spark 也具备高速训练大模型的能力,并写出更加优雅的机器学习代码,而不必绕来绕去。Angel 已经支持了 20 多种不同算法,包括 SGD、ADMM 优化算法等,我们也开放比较简易的编程接口,用户也可以比较方便的编写自定义的算法,实现高效的 ps 模型。并提供了高效的向量及矩阵运算库(稀疏 / 稠密),方便了用户自由选择数据、参数的表达形式。在优化算法方面,Angel 已实现了 SGD、ADMM,并支持 Latent DirichletAllocation (LDA)、MatrixFactorization (MF)、LogisticRegression (LR) 、Support Vector Machine(SVM) 等。
Spark on Angel Optimizer, Angel 的优势包括几点:
- 能高效支持超大规模(十亿)维度的数据训练;
- 同样数据量下,比 Spark、Petuum 等其他的计算平台性能更好;
- 有丰富的算法库及计算函数库,友好的编程接口,让用户像使用 MR、Spark 一样编程;
- 丰富的配套生态,既有一体化的运营及开发门户,又能支持深度学习、图计算等等其他类型的机器学习框架,让用户在一个平台能开发多种类型的应用。
Angel做过的优化
Angel 是基于参数服务器的一个架构,与其他平台相比,在性能上很多优化。
- 首先,我们能支持 BSP、SSP、ASP 三种不同计算和参数更新模式,
- 其次,我们支持模型并行,参数模型可以比较灵活进行切分。
- 第三,我们有个服务补偿的机制,参数服务器优先服务较慢的节点,根据我们的测试结果,当模型较大时,能明显降低等待时间,任务总体耗时下降 5%~15%。
- 最后,我们在参数更新的性能方面,做了很多优化,比如对稀疏矩阵的 0 参数以及已收敛参数进行过滤,我们根据参数的不同数值类型进行不同算法的压缩,最大限度减少网络负载,
- 我们还优化了参与获取与计算的顺序,边获取参数变计算,这样就能节省 20-40% 的计算时间。
除了在性能方面进行深入的优化,在系统易用性上我们也做了很多改进。
- 第一,我们提供很丰富的机器学习算法库,以及数学运算算法库;
- 第二,我们提供很友好的高度抽象的编程接口,能跟 Spark、MR 对接,开发人员能像用 MR、Spark 一样编程;
- 第三,我们提供了一体化的拖拽式的开发及运营门户,用户不需要编程或只需要很少的开发量就能完成算法训练;
- 第四,我们内置数据切分、数据计算和模型划分的自动方案及参数自适应配置等功能,并屏蔽底层系统细节,用户可以很方便进行数据预处理;
- 最后一点,Angel 还能支持多种高纬度机器学习的场景,比如支持 Spark 的 MLLib,支持 Graph 图计算、还支持深度学习如 Torch 和 TensorFlow 等业界主流的机器学习框架,提供计算加速。
为什么开源?
Angel 不仅仅是一个只做并行计算的平台,它更是一个生态,我们围绕 Angel,建立了一个小生态圈,
- 它支持 Spark 之上的 MLLib,支持上亿的维度的训练;
- 我们也支持更复杂的图计算模型;
- 同时支持 Caffe、TensorFlow、Torch 等深度学习框架,实现这些框架的多机多卡的应用场景。

Angel 的生态圈
- 腾讯大数据平台来自开源的社区,受益于开源的社区中,所以我们自然而然地希望回馈社区。
- 开源,让开放者和开发者都能受益,创造一个共建共赢的生态圈。在这里,开发者能节约学习和操作的时间,提升开发效率,去花时间想更好的创意,而开放者能受益于社区的力量,更快完善项目,构建一个更好的生态圈。
- 我们目前希望能丰富 Angel 配套生态圈,进一步降低用户使用门槛,促进更多开发人员,包括学校与企业,参与共建 Angel 开源社区。而通过推动 Angel 的发展,最终能让更多用户能快速、轻松地建立有大规模计算能力的平台。
- 我们一直都向社区做贡献,开放了很多源代码,培养了几个项目的 committer,这种开放的脚步不会停止。
小结:腾讯公司通过 18 年的发展今天已经成为了世界级的互联网公司。“在技术上,我们过去更加关注的是工程技术,也就是海量性能处理能力、海量数据存储能力、工程架构分布容灾能力。未来腾讯必将发展成为一家引领科技的互联网公司,我们将在大数据、核心算法等技术领域上进行积极的投入和布局,和合作伙伴共同推动互联网产业的发展。”
参考资料:
- http://www.sohu.com/a/149470913_470008
- http://news.ifeng.com/a/20170619/51276636_0.shtml
- http://djt.qq.com/article/view/1484
ML平台_Angel参考的更多相关文章
- ML平台_Paddle参考
PaddlePaddle源自于 2013 年百度深度学习实验室创建的 “Paddle”.当时的深度学习框架大多只支持单 GPU 运算,对于百度这样需要对大规模数据进行处理的机构,这显然远远不够,极大拖 ...
- ML平台_PAI参考
阿里云机器学习PAI(Platform of Artificial Intelligence)是一款一站式的机器学习平台,包含数据预处理.特征工程.常规机器学习算法.深度学习框架.模型的评估以及预测这 ...
- ML平台_设计要点
如果说机器是人类手的延伸.交通工具是人类腿的延伸,那么人工智能就是人类大脑的延伸,甚至可以帮助人类自我进化,超越自我.人工智能也是计算机领域最前沿和最具神秘色彩的学科,科学家希望制造出代替人类思考的智 ...
- ML平台_小米深度学习平台的架构与实践
(转载:http://www.36dsj.com/archives/85383)机器学习与人工智能,相信大家已经耳熟能详,随着大规模标记数据的积累.神经网络算法的成熟以及高性能通用GPU的推广,深度学 ...
- ML平台_微博深度学习平台架构和实践
( 转载至: http://www.36dsj.com/archives/98977) 随着人工神经网络算法的成熟.GPU计算能力的提升,深度学习在众多领域都取得了重大突破.本文介绍了微博引入深度学 ...
- ML平台_饿了么实践
(转载至:https://zhuanlan.zhihu.com/p/28592540) 说到机器学习.大数据,大家听到的是 Hadoop 和 Spark 居多,它们跟 TensorFlow 是一个什么 ...
- <转>ML 相关算法参考
转自 国内外网站如果你想搜索比较新颖的机器学习资料或是文章,可以到以下网站中搜索,里面不仅包括了机器学习的内容,还有许多其它相关领域内容,如数据科学和云计算等.InfoWord:http://www. ...
- How To Build Kubernetes Platform (构建Kubernetes平台方案参考)
Architecture Architecture Diagram Non-Prod Environment Prod Environment Cluster Networking Container ...
- API 开发平台 dreamfactory,参考SAWAGGER,国外厂家,开源,本地与云部署
API 开发平台,参考SAWAGGER,国外厂家,本地与云部署:参考 http://swagger.io/commercial-tools/ 1.dreamfactory 梦工厂公司 https: ...
随机推荐
- Web服务器使用基于纯文本表单的身份验证——.net(未完待续)
asp.net 表单验证方式 Asp.net的身份验证有有三种,分别是"Windows | Forms| Passport",其中又以Forms验证用的最多,也最灵活. 根据实际需 ...
- [转]Skynet之斗转星移 - 将控制权交给Lua
Skynet之斗转星移 - 将控制权交给Lua http://www.outsky.org/code/skynet-lua.html Sep 7, 2014 在我看来,Skynet的一个重要优势是 ...
- 基于CART的回归和分类任务
CART 是 classification and regression tree 的缩写,即分类与回归树. 博主之前学习的时候有用过决策树来做预测的小例子:机器学习之决策树预测--泰坦尼克号乘客数据 ...
- gdb debug
http://www.cnblogs.com/life2refuel/p/5396538.html
- 认识MySQL中的索引
一.什么是索引 索引是一种将数据库中单列或者多列的值进行排序的结构,引用索引可以大大提高索引的速度. 二.索引的优缺点 优点:整体上提高查询的速度,提高系统的整体性能. 缺点:创建索引和维护索引都需要 ...
- 百练-16年9月推免-B题-字符串判等
2743:字符串判等 查看 提交 统计 提示 提问 总时间限制: 1000ms 内存限制: 65536kB 描述 判断两个由大小写字母和空格组成的字符串在忽略大小写,且忽略空格后是否相等. 输入 ...
- 牛客OI赛制测试赛2
A题: https://www.nowcoder.com/acm/contest/185/A 链接:https://www.nowcoder.com/acm/contest/185/A来源:牛客网 题 ...
- Django自定义查询对象
在Django中,objects对象类继承于models.Manager 1.声明 EntryManager 类,继承自 models.Manager 允许在 EntryManager中增加自定义函数 ...
- python day 09 文件操作
一 初识文件操作 使⽤用python来读写⽂文件是非常简单的操作. 我们使⽤用open()函数来打开⼀一个⽂文件, 获取到⽂文件句句柄. 然后通过⽂文件句句柄就可以进⾏行行各种各样的操作了了. 根据打 ...
- Damped Track 阻尼跟随
Damped Track 阻尼跟随 https://www.youtube.com/watch?v=pd1od5WPCUw 2个网格及对应的2个空对象Z轴方向网格:{O.up}; 上方园孔把手中间放空 ...