如何理解机器学习/统计学中的各种范数norm | L1 | L2 | 使用哪种regularization方法?
参考:
L1 Norm Regularization and Sparsity Explained for Dummies 专为小白解释的文章,文笔十分之幽默
- why does a small L1 norm give a sparse solution?
- why does a sparse solution avoid over-fitting?
- what does regularization do really?
减少feature的数量可以防止over fitting,尤其是在特征比样本数多得多的情况下。
L1就二维而言是一个四边形(L1 norm is |x| + |y|),它是只有形状没有大小的,所以可以不断伸缩。我们得到的参数是一个直线(两个参数时),也就是我们有无数种取参数的方法,但是我们想满足L1的约束条件,所以 要选择相交点的参数组。
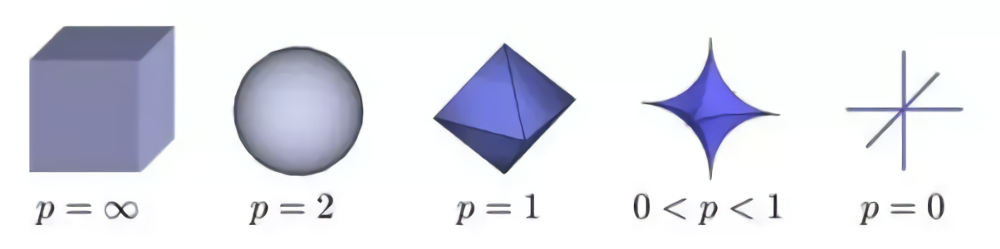
Then why not letting p < 1? That’s because when p < 1, there are calculation difficulties. 所以我们通常只在L1和L2之间选,这是因为计算问题,并不是不能。
l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm

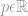
就是一个简单的公式而已,所有的范数瞬间都可以理解了。(注意范数的写法,写在下面,带双竖杠)
Before answering your question I need to edit that Manhattan norm is actually L1 norm and Euclidean norm is L2.
As for real-life meaning, Euclidean norm measures the beeline/bird-line distance, i.e. just the length of the line segment connecting two points. However, when we move around, especially in a crowded city area like Manhattan, we obviously cannot follow a straight line (unless you can fly like a bird). Instead, we need to follow a grid-like route, e.g. 3 blocks to teh west, then 4 blocks to the south. The length of this grid route is the Manhattan norm.
之前的印象是L1就是Lasso,是一个四边形,相当于绝对值。
L2就是Ridge,相当于是一个圆。
如何理解机器学习/统计学中的各种范数norm | L1 | L2 | 使用哪种regularization方法?的更多相关文章
- 机器学习中的规则化范数(L0, L1, L2, 核范数)
目录: 一.L0,L1范数 二.L2范数 三.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问 ...
- 深入理解javascript选择器API系列第三篇——h5新增的3种selector方法
× 目录 [1]方法 [2]非实时 [3]缺陷 前面的话 尽管DOM作为API已经非常完善了,但是为了实现更多的功能,DOM仍然进行了扩展,其中一个重要的扩展就是对选择器API的扩展.人们对jQuer ...
- 深入理解javascript选择器API系列第三篇——HTML5新增的3种selector方法
前面的话 尽管DOM作为API已经非常完善了,但是为了实现更多的功能,DOM仍然进行了扩展,其中一个重要的扩展就是对选择器API的扩展.人们对jQuery的称赞,很多是由于jQuery方便的元素选择器 ...
- 机器学习中正则惩罚项L0/L1/L2范数详解
https://blog.csdn.net/zouxy09/article/details/24971995 原文转自csdn博客,写的非常好. L0: 非零的个数 L1: 参数绝对值的和 L2:参数 ...
- css浮动中避免包含元素高度为0的4种解决方法
问题:当子元素中使用了float时,如果其父元素不指定高度,其高度将为0 解决:清除(闭合)浮动元素,使其父div高度自适应 方法一:额外标签+clear:both (W3C推荐方法,兼容性较 ...
- Spark机器学习 Day2 快速理解机器学习
Spark机器学习 Day2 快速理解机器学习 有两个问题: 机器学习到底是什么. 大数据机器学习到底是什么. 机器学习到底是什么 人正常思维的过程是根据历史经验得出一定的规律,然后在当前情况下根据这 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要: 数据挖掘.机器学习和推荐系统中的评测指标—准确率(Precision).召回率(Recall).F值(F-Measure)简介. 引言: 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型 ...
随机推荐
- shelve模块,sys模块,logging模块
1.shelve模块 用于序列化的模块,shelve模块比pickle模块简单,只有open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型. impor ...
- 检测 C++ 内存泄露
转载:http://www.cnblogs.com/zouzf/p/4152279.html #include "stdafx.h" #include <string> ...
- javaScript随机数取值方法
Math.random()方法返回0到1之间的一个随机数,不包括0和1 如若想取的一个范围的随机数可套用下面的公式: 一.X+开始数-1=结束数 二.Math.floor(Math.random()* ...
- repo总结【转】
本文转载自:https://blog.csdn.net/weixin_38599972/article/details/78982408 1. repo start ##创建并切换分支repo st ...
- 给ThinkPad E470C 换个高分屏(1080P)
- vim改善生活的几个插件
vim改善生活的几个插件 http://www.cnblogs.com/lovesaber/archive/2012/01/06/2315343.html
- sql server查看用户权限
System.ServiceModel.FaultException: Server error. Detail: The EXECUTE permission was denied on the o ...
- LuoguP2680 运输计划
题目地址 题目链接 题解 二分答案,那么大于答案的路径都需要有一条公共边,maxlen-val>=二分出来的x.val是边权. 考虑树剖,对每条大于答案的路径都+1(线段树里),枚举边,如果(线 ...
- MPU6050可以读取ID值,温度值和原始数据值为零问题解决
MPU6050可以读取ID值是0x68,但是读取到的原始数据为零(下面虚拟示波器图中温度值是36.529是单位转换公式中的值被打印出来了,实际值也是零).经论坛搜寻,发现MPU6050出现问题的原因有 ...
- 【译】第43节---EF6-自定义约定
原文:http://www.entityframeworktutorial.net/entityframework6/custom-conventions-codefirst.aspx Code-Fi ...