机器学习数据处理时label错位对未来数据做预测
这篇文章继上篇机器学习经典模型简单使用及归一化(标准化)影响,通过将测试集label(行)错位,将部分数据作为对未来的预测,观察其效果。
实验方式
- 以不同方式划分数据集和测试集
- 使用不同的归一化(标准化)方式
- 使用不同的模型
- 将测试集label错位,计算出MSE的大小
- 不断增大错位的数据的个数,并计算出MSE,并画图
- 通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据预处理部分与上次相同。两种划分方式:
一、
test_sort_data = sort_data[16160:]
test_sort_target = sort_target[16160:] _sort_data = sort_data[:16160]
_sort_target = sort_target[:16160]
sort_data1 = _sort_data[:(int)(len(_sort_data)*0.75)]
sort_data2 = _sort_data[(int)(len(_sort_data)*0.75):]
sort_target1 = _sort_target[:(int)(len(_sort_target)*0.75)]
sort_target2 = _sort_target[(int)(len(_sort_target)*0.75):]
二、
test_sort_data = sort_data[:5000]
test_sort_target = sort_target[:5000] sort_data1 = _sort_data[5000:16060]
sort_data2 = _sort_data[16060:]
sort_target1 = _sort_target[5000:16060]
sort_target2 = _sort_target[16060:]
一开始用的第一种划分方式,发现直接跑飞了

然后仔细想了想,观察了上篇博客跑出来的数据,果断换了第二种划分方式,发现跑出来的结果还不错
MaxMinScaler()
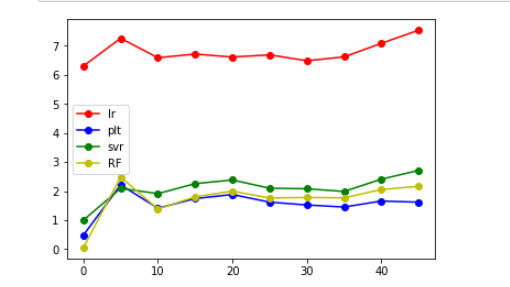
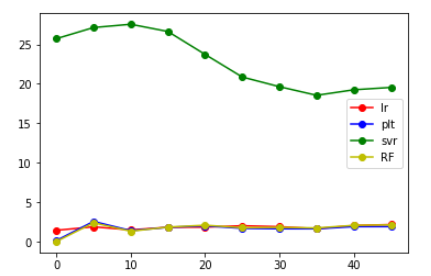
看到lr模型明显要大,就舍弃了
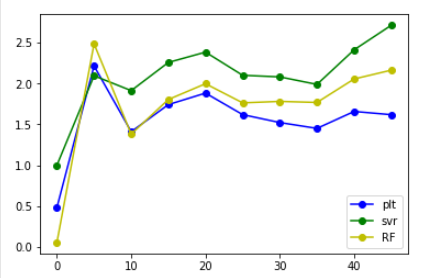
(emmmmm。。。这张图看起来就友好很多了)
MaxAbsScaler()

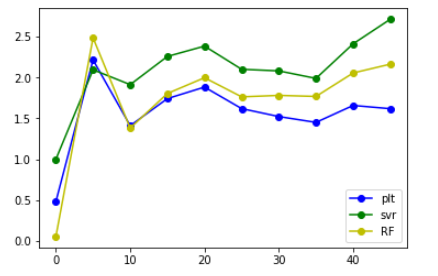
StandardScaler()
代码
其中大部分的代码都是一样的,就是改改归一化方式,就只放一部分了
数据预处理部分见上篇博客
加上这一段用于画图
import matplotlib.pyplot as plt
lr_plt=[]
ridge_plt=[]
svr_plt=[]
RF_plt=[]
接着,先计算不改变label时的值
from sklearn.linear_model import LinearRegression,Lasso,Ridge
from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler
from sklearn.metrics import mean_squared_error as mse
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
#最大最小归一化
mm = MinMaxScaler() lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(sort_data2[new_fea]))
lr_mse=mse(lr_ans,sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(sort_data2[new_fea]))
svr_mse=mse(svr_ans,sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea]))
RF_mse=mse(predict_RF,sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0,
subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1)
bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
bst_ans = bst.predict(mm.transform(sort_data2[new_fea]))
print('bst:',mse(bst_ans,sort_target2))
先将label错位,使得data2的第i位对应target2的第i+5位
change_sort_data2 = sort_data2.shift(periods=5,axis=0)
change_sort_target2 = sort_target2.shift(periods=-5,axis=0)
change_sort_data2.dropna(inplace=True)
change_sort_target2.dropna(inplace=True)
然后用一个循环不断迭代,改变错位的数量
mm = MinMaxScaler() for i in range(0,45,5):
print(i)
lr = Lasso(alpha=0.5)
lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1)
lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea]))
lr_mse=mse(lr_ans,change_sort_target2)
lr_plt.append(lr_mse)
print('lr:',lr_mse) ridge = Ridge(alpha=0.5)
ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea]))
ridge_mse=mse(ridge_ans,change_sort_target2)
ridge_plt.append(ridge_mse)
print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea]))
svr_mse=mse(svr_ans,change_sort_target2)
svr_plt.append(svr_mse)
print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea]))
RF_mse=mse(predict_RF,change_sort_target2)
RF_plt.append(RF_mse)
print('RF:',RF_mse) # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0,
# subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1)
# bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1)
# bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea]))
# print('bst:',mse(bst_ans,change_sort_target2)) change_sort_target2=change_sort_target2.shift(periods=-5,axis=0)
change_sort_target2.dropna(inplace=True)
change_sort_data2 = change_sort_data2.shift(periods=5,axis=0)
change_sort_data2.dropna(inplace=True)
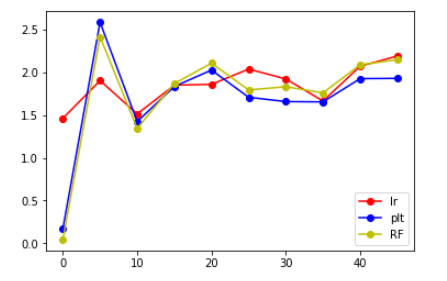
然后就可以画图了
x=[0,5,10,15,20,25,30,35,40,45]
plt.plot(x,lr_plt,label='lr',color='r',marker='o')
plt.plot(x,ridge_plt,label='plt',color='b',marker='o')
plt.plot(x,svr_plt,label='svr',color='g',marker='o')
plt.plot(x,RF_plt,label='RF',color='y',marker='o')
plt.legend()
plt.show()
结果分析
从上面给出的图来看,发现将label错位后,相比于原来的大小还是有所增大,但是增大后的值并不是特别大,并且大致在某个范围内浮动,大概在错位10个label时能得到的结果是最好的。
机器学习数据处理时label错位对未来数据做预测的更多相关文章
- 机器学习预测时label错位对未来数据做预测
前言 这篇文章时承继上一篇机器学习经典模型使用归一化的影响.这次又有了新的任务,通过将label错位来对未来数据做预测. 实验过程 使用不同的归一化方法,不同得模型将测试集label错位,计算出MSE ...
- 在进行机器学习建模时,为什么需要验证集(validation set)?
在进行机器学习建模时,为什么需要评估集(validation set)? 笔者最近有一篇文章被拒了,其中有一位审稿人提到论文中的一个问题:”应该在验证集上面调整参数,而不是在测试集“.笔者有些不明白为 ...
- 大数据处理时用到maven的repository
由于做数据处理时,经常遇到maven 下载依赖包错误,下面我将自己下载好的repository 分享下 里边包含:Hadoop ,storm ,sprk ,kafka ,等 压缩后500多M. htt ...
- ssh下:系统初始化实现ServletContextListener接口时,获取spring中数据层对象无效的问题
想要实现的功能:SSH环境下,数据层都交由Spring管理:在服务启动时,将数据库中的一些数据加载到ServletContext中缓存起来. 系统初始化类需要实现两个接口: ServletContex ...
- Windows Phone 8初学者开发—第14部分:在运行时绑定到真实的数据
原文 Windows Phone 8初学者开发—第14部分:在运行时绑定到真实的数据 第14部分:在运行时绑定到真实的数据 原文地址: http://channel9.msdn.com/Series/ ...
- 页面跳转时,url 传大数据的参数不全的问题+序列化对象
1.页面跳转时,url 传大数据的参数不全的问题 //传参: url: '/pages/testOfPhysical/shareEvaluation?detailInfo=' +encodeURICo ...
- PDO exec 执行时出错后如果修改数据会被还原?
PDO exec 执行时出错后如果修改数据会被还原? 现象 FastAdmin 更新了 1127 版本,但是使用在线安装方式出现无法修改管理员密码的问题. 一直是默认的 admin 123456 密码 ...
- SQL获取当前日期的年、月、日、时、分、秒数据
SQL Server中获取当前日期的年.月.日.时.分.秒数据: SELECT GETDATE() as '当前日期',DateName(year,GetDate()) as '年',DateName ...
- js中对arry数组的各种操作小结 瀑布流AJAX无刷新加载数据列表--当页面滚动到Id时再继续加载数据 web前端url传递值 js加密解密 HTML中让表单input等文本框为只读不可编辑的方法 js监听用户的键盘敲击事件,兼容各大主流浏览器 HTML特殊字符
js中对arry数组的各种操作小结 最近工作比较轻松,于是就花时间从头到尾的对js进行了详细的学习和复习,在看书的过程中,发现自己平时在做项目的过程中有很多地方想得不过全面,写的不够合理,所以说啊 ...
随机推荐
- Biorhythms HDU - 1370 (中国剩余定理)
孙子定理: 当前存在三个式子,t%3=2,t%5=3,t%7=2.然后让你求出t的值的一个通解. 具体过程:选取3和5的一个公倍数t1能够使得这个公倍数t1%7==1,然后选取3和7的一个公倍数t2使 ...
- Database学习 - mysql 连接数据库 库操作
连接数据库 语法格式: mysql -h 服务器IP -P 端口号 -u用户名 -p密码 --prompt 命令提示符 --delimiter 指定分隔符 示例: mysql -h 127.0.0.1 ...
- linux 中的 open() read() write() close() 函数
1. open()函数 功能描述:用于打开或创建文件,在打开或创建文件时可以指定文件的属性及用户的权限等各种参数. 所需头文件:#include <sys/types.h>,#includ ...
- T_RegionNDS表创建及值
-- Table structure for t_regionnds -- ---------------------------- DROP TABLE IF EXISTS t_regionnds; ...
- 用zmq的pub/sub+flask实现异步通信的研究
zmq_client监听端代码: #coding=utf8 ## client.py import zmq import sys import time import logging import o ...
- maven项目提示web.xml is missing或红色感叹号
1.web.xml is missing and <failOnMissingWebXml> is set to true 提示信息应该能看懂.也就是缺少了web.xml文件,<fa ...
- mysql字符串 转 int-double CAST与CONVERT 函数的用法
MySQL 的CAST()和CONVERT()函数可用来获取一个类型的值,并产生另一个类型的值.两者具体的语法如下: CAST(value as type); CONVERT(value, type) ...
- 使用命令行登陆数据库配置文件修改 解决ora12528
下面是问题解决: ORA-12528: TNS:listener: all appropriate instances are blocking new connections 1:修改listene ...
- 简单解决“ORA-27100: shared memory realm already exists”的问题
背景 看到这篇文章,算是当初记录过程的一篇了,不像别的,只是有个结果算火.只是感觉到现在可能是碰不见这个问题了,现在哪有32位的oracle啊.可见技术随着岁月的变化,真不知10年后再看今天的问题,可 ...
- Python-JS中的事件详解
目录 fdf!! fefd 一.JS中的事件二.JS中的事件分类: 1.事件初级: 2.事件参数 Event 3.鼠标事件 4.键盘事件 *** 5.表单事件 *** 6.文档事件 * 7.图片事件 ...