【Hive学习之五】Hive 参数&动态分区&分桶
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
apache-hive-3.1.1
一、Hive 参数
1、Hive 参数类型
hive当中的参数、变量,都是以命名空间开头;

通过${}方式进行引用,其中system、env下的变量必须以前缀开头;
在Hive CLI查看参数
#显示所有参数
hive>set;
#查看单个参数
hive> set hive.cli.print.header;
hive.cli.print.header=false
2、Hive参数设置方式
(1)、修改配置文件 ${HIVE_HOME}/conf/hive-site.xml 这会使所有客户端都生效
(2)、启动hive cli时,通过--hiveconf key=value的方式进行设置 这只会在当前客户端生效
例:
[root@PCS102 ~]# hive --hiveconf hive.cli.print.header=true
hive> set hive.cli.print.header;
hive.cli.print.header=true
hive>
(3)、进入cli之后,通过使用set命令设置 这只会在当前客户端生效
hive> set hive.cli.print.header;
hive.cli.print.header=false
hive> select * from wc;
OK
hadoop
hbase
hello
name
world
zookeeper
Time taken: 2.289 seconds, Fetched: row(s)
hive> set hive.cli.print.header=true;
hive> set hive.cli.print.header;
hive.cli.print.header=true
hive> select * from wc;
OK
wc.word wc.totalword
hadoop
hbase
hello
name
world
zookeeper
Time taken: 2.309 seconds, Fetched: row(s)
hive>
(4)使用.hiverc文件设置
当前用户家目录(例:root用户:家目录是/root)下的.hiverc文件
如果没有,可直接创建该文件,将需要设置的参数写到该文件中,hive启动运行时,会加载改文件中的配置。
[root@PCS102 ~]# vi ~/.hiverc
set hive.cli.print.header=true
:wq
[root@PCS102 ~]# ll -a|grep hive
-rw-r--r--. root root Feb : .hivehistory
-rw-r--r--. root root Feb : .hiverc
另外:
.hivehistory 文件记录hive历史操作命令集
#重新登录 可以发现配置生效了 影响当前linux用户登录的客户端
[root@PCS102 ~]# hive
hive> set hive.cli.print.header;
hive.cli.print.header=true
hive>
二、动态分区
参数设置:
开启支持动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrict;
默认:strict(至少有一个分区列是静态分区)
其他参数
set hive.exec.max.dynamic.partitions.pernode;
每一个执行mr节点上,允许创建的动态分区的最大数量(100)
set hive.exec.max.dynamic.partitions;
所有执行mr节点上,允许创建的所有动态分区的最大数量(1000)
set hive.exec.max.created.files;
所有的mr job允许创建的文件的最大数量(100000)
数据 /root/data:
,小明1,,boy,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明2,,man,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明3,,boy,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明4,,man,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明5,,boy,lol-book-movie,beijing:shangxuetang-shanghai:pudong
,小明6,,man,lol-book-movie,beijing:shangxuetang-shanghai:pudong
1、原始表
hive> CREATE TABLE psn21( > id INT,
> name STRING,
> age INT,
> sex string,
> likes ARRAY<STRING>,
> address MAP<STRING,STRING>
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY '-'
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.183 seconds
hive> LOAD DATA LOCAL INPATH '/root/data' INTO TABLE psn21;
Loading data to table default.psn21
OK
Time taken: 0.248 seconds
hive> select * from psn21;
OK
psn21.id psn21.name psn21.age psn21.sex psn21.likes psn21.address
小明1 boy ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明2 man ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明3 boy ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明4 man ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明5 boy ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
小明6 man ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"}
Time taken: 0.113 seconds, Fetched: row(s)
hive>
2、分区表
hive> CREATE TABLE psn22(
> id INT,
> name STRING,
> likes ARRAY<STRING>,
> address MAP<STRING,STRING>
> )
> partitioned by (age int,sex string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY '-'
> MAP KEYS TERMINATED BY ':'
> LINES TERMINATED BY '\n';
OK
Time taken: 0.045 seconds
3、原始表数据导入分区表(注意psn21下数据不变)
hive> from psn21
> insert overwrite table psn22 partition(age, sex)
> select id, name,likes, address,age, sex distribute by age, sex;
Query ID = root_20190215170643_7aeb9dae-62d5-49fe-ab37-022446f6a004
Total jobs =
Launching Job out of
Number of reduce tasks not specified. Estimated from input data size:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1548397153910_0009, Tracking URL = http://PCS102:8088/proxy/application_1548397153910_0009/
Kill Command = /usr/local/hadoop-3.1./bin/mapred job -kill job_1548397153910_0009
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 2.86 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 6.26 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1548397153910_0009
Loading data to table default.psn22 partition (age=null, sex=null) Time taken to load dynamic partitions: 0.482 seconds
Time taken for adding to write entity : 0.001 seconds
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 6.26 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
id name likes address age sex
Time taken: 18.572 seconds
hive>

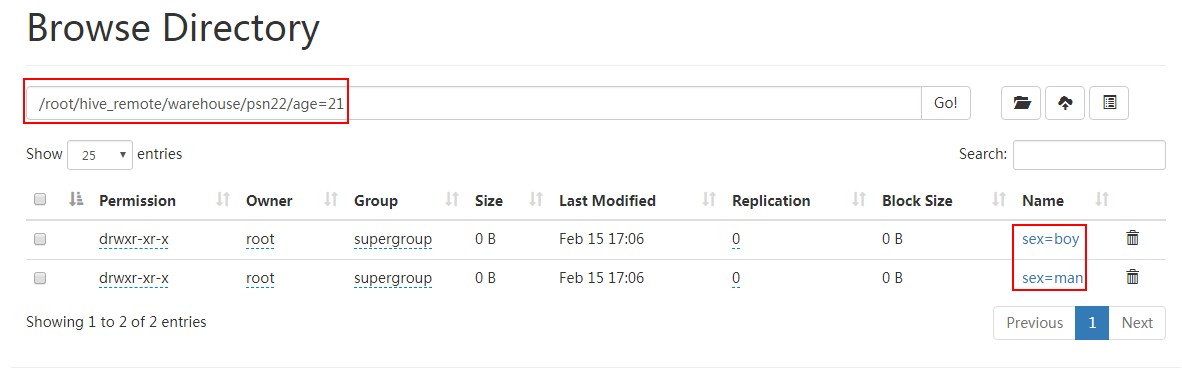

查看该分区下数据:
[root@PCS102 ~]# hdfs dfs -cat /root/hive_remote/warehouse/psn22/age=21/sex=boy/*
5,小明5,lol-book-movie,beijing:shangxuetang-shanghai:pudong
3,小明3,lol-book-movie,beijing:shangxuetang-shanghai:pudong
[root@PCS102 ~]#
全部分区数据:
hive> select * from psn22;
OK
psn22.id psn22.name psn22.likes psn22.address psn22.age psn22.sex
小明1 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} boy
小明2 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} man
小明5 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} boy
小明3 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} boy
小明6 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} man
小明4 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} man
Time taken: 0.141 seconds, Fetched: row(s)
hive>
三、分桶
1、分桶
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。
对于hive中每一个表、分区都可以进一步进行分桶。
由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
适用场景:数据抽样( sampling )、map-join
2、开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数。
(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和reduce task个数一致。
3、桶表 抽样查询
select * from bucket_table tablesample(bucket 1 out of 4 on columns);
TABLESAMPLE语法:
TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子 (Y表示相隔多少个桶再次抽取)
举例:
当表总bucket数为32时
(1)TABLESAMPLE(BUCKET 2 OUT OF 4),抽取哪些数据?
数据个数:32/4=8份
桶号:2,6(2+4),10(6+4),14(10+4),18(14+4),22(18+4),26(22+4),30(26+4)
(2)TABLESAMPLE(BUCKET 3 OUT OF 8),抽取哪些数据?
数据个数:32/8=4份
桶号:3,11(3+8),19(11+8),27(19+8)
(3)TABLESAMPLE(BUCKET 3 OUT OF 256),抽取哪些数据?
数据个数:32/256=1/8份
桶号:3, 一个桶取1/8即可
4、分桶案例
原始表:
CREATE TABLE psn31
( id INT,
name STRING,
age INT)
ROW FORMAT
DELIMITED FIELDS TERMINATED BY ',';
数据/root/data2:
,tom,11
,cat,
,dog,
,hive,
,hbase,
,mr,
,alice,
,scala,
数据导入:
hive>load data local inpath '/root/data2' into table psn31;
创建分桶表
CREATE TABLE psnbucket
( id INT,
name STRING,
age INT)
CLUSTERED BY (age) INTO BUCKETS
ROW FORMAT
DELIMITED FIELDS TERMINATED BY ',';
数据分桶预测:
age%4
1,tom, --3
,cat,22 --2
,dog,33 --1
,hive,44 --0
,hbase,55 --3
,mr,66 --2
,alice,77 --1
,scala,88 --0
加载数据 执行MR任务 表目录下有四个文件(桶表不能通过load的方式直接加载数据,只能从另一张表中插入数据):
hive>insert into table psnbucket select id, name, age from psn31;

看一下每个桶文件内的数据是否和预测一样:
[root@PCS102 ~]# hdfs dfs -cat /root/hive_remote/warehouse/psnbucket/000000_0
,scala,
,hive,
[root@PCS102 ~]# hdfs dfs -cat /root/hive_remote/warehouse/psnbucket/000001_0
,alice,
,dog,
[root@PCS102 ~]# hdfs dfs -cat /root/hive_remote/warehouse/psnbucket/000002_0
,mr,
,cat,
[root@PCS102 ~]# hdfs dfs -cat /root/hive_remote/warehouse/psnbucket/000003_0
,hbase,
,tom,
数据抽样:结果跟之前版本预期不一样 很奇怪 为什么不是取00001_0里的数据?
hive> select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
OK
id name age
mr
tom
Time taken: 0.184 seconds, Fetched: row(s)
hive>
【Hive学习之五】Hive 参数&动态分区&分桶的更多相关文章
- Hive学习之修改表、分区、列
Hive学习之修改表.分区.列 https://blog.csdn.net/skywalker_only/article/details/30224309 https://www.cnblogs.co ...
- 对现有Hive的大表进行动态分区
分区是在处理大型事实表时常用的方法.分区的好处在于缩小查询扫描范围,从而提高速度.分区分为两种:静态分区static partition和动态分区dynamic partition.静态分区和动态分区 ...
- Hive Experiment 2(表动态分区和IDE)
1.使用oracle sql developer 4.0.3作为hive query的IDE. 下载hive-jdbc driver http://www.cloudera.com/content/c ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- hive学习(二) hive操作
hive ddl 操作官方手册https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL hive dml 操作官方手 ...
- hive学习(三) hive的分区
1.Hive 分区partition 必须在表定义时指定对应的partition字段 a.单分区建表语句: create table day_table (id int, content string ...
- Hive学习之五 《Hive进阶—UDF操作案例》 详解
hive—UDF操作 udf的操作过程: 在HIVE会话中add 自定义函数的jar文件,然后创建function,继而使用函数. 下面就以下面课题为例: 课题:统计每个活动的PV和UV 一.Java ...
- hive学习(四) hive的函数
1.内置运算符 1.1关系运算符 运算符 类型 说明 A = B 所有原始类型 如果A与B相等,返回TRUE,否则返回FALSE A == B 无 失败,因为无效的语法. SQL使用”=”,不使用”= ...
- Hive学习:Hive连接JOIN用例详解
1 准备数据: 1.1 t_1 01 张三 02 李四 03 王五 04 马六 05 小七 06 二狗 1.2 t_2 01 11 03 33 04 44 06 66 07 77 08 88 1.3 ...
随机推荐
- Linux中常用命令
.cd命令 cd 回到跟目录 cd uqihong 进入到uqihong这个文件夹(且cd命令只能一级一级的进入) 2.复制命令 cp -r /usr/local/tomcat ...
- Linux I/O重定向
所谓I/O重定向简单来说就是一个过程,这个过程捕捉一个文件,或者命令,程序,脚本,甚至脚本中的代码块的输出,然后把捕捉到的输出,作为输入 发送给另外一个文件,命令,程序,或者脚本.谈到I/O重定向,就 ...
- 【数据库】SQL语句解析
学习网站: http://www.runoob.com/sql/sql-having.html 1. 1.现在我们想要查找总访问量大于 200 的网站. 回取出多条重复的网址的SQL语句: selec ...
- (4.6)mysql备份还原——深入解析二进制日志(2)binlog参数配置解析
关键词:binlog配置,binlog参数,二进制日志配置,二进制文件参数配置 关键词:binlog缓存,binlog 刷新 0.bin写入流程 写binlog流程如下:# 数据操作buffer po ...
- what's the 跨期套利
出自 MBA智库百科(https://wiki.mbalib.com/) 跨期套利的定义 跨期套利是套利交易中最普遍的一种,是股指期货的跨期套利(Calendar Spread Arbitrage)即 ...
- 1 认识开源性能测试工具jmeter
典型的性能测试工具主要有2个,Load Runner和jmeter.Load Runner是商业化的,Jmeter是开源的.下面我们认识一下开源性能测试工具jmeter. 1.jmeter是什么? A ...
- 从Trie树(字典树)谈到后缀树
转:http://blog.csdn.net/v_july_v/article/details/6897097 引言 常关注本blog的读者朋友想必看过此篇文章:从B树.B+树.B*树谈到R 树,这次 ...
- python的map函数
map:对指定序列做映射 python3中的: map(function, iterable, ...) map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, ...
- Eclipse中git上如何把自己的分支保存到远端
1 Team——>remote——>push 2 next 3 选择自己的分支,然后点击 Add Spec 4 查看是否是自己的分支——>自己的分支,然后Finish PS ...
- Hadoop生态集群之HDFS
一.HDFS是什么 HDFS是hadoop集群中的一个分布式的我文件存储系统.他将多台集群组建成一个集群,进行海量数据的存储.为超大数据集的应用处理带来了很多便利. 和其他的分布式文件存储系统相比他有 ...