使用pandas处理数据并绘图的例子
import sys
import os
import re
import datetime
import csv def get_datetime(record):
request_time = ""
p = re.compile(r"(?P<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d+)")
# p = re.compile(r"(?P<time>[\d.]+)ms")
m = p.search(record)
if m:
request_time = m.group("time")
dt = datetime.datetime.strptime(request_time, '%Y-%m-%d %H:%M:%S,%f')
return dt def parse(log_file_name, result_csv_name):
start = 0
end = 0
start_time = ''
end_time = ''
md5crc32 = ''
csv_writer = csv.writer(open(result_csv_name, 'wb'),
delimiter = ',')
with open(log_file_name, 'rb') as log_file:
for i, line in enumerate(log_file):
line = line.strip()
if 'folderProcessing() INFO download from' in line:
start = i
start_time = get_datetime(line)
elif 'DownLoadFile() INFO download to' in line:
end = i
end_time = get_datetime(line)
# got one download action
if end - start == 1:
# parse hash
md5crc32 = line.rsplit('/', 1)[1]
print md5crc32, (end_time - start_time).total_seconds()
csv_writer.writerow((md5crc32, (end_time - start_time).total_seconds()))
# assert False def do_statistics(file_name):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv(file_name, header = None, names= ['hash', 'time'], dtype = {'time': np.float64},
# nrows = 10000
)
time_series = df.time
print time_series.describe()
plt.figure()
# fig = time_series.hist().get_figure()
# define range
ranges = (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 2.0, 3.0, 4.0, 10.0, 10000)
bins = zip(ranges[:-1], ranges[1:])
labels = ['%s-%s'%(begin, end) for i ,(begin, end) in enumerate(bins) ]
print labels
#print bins
#fig = time_series.plot(kind='bar', xticks = ranges)
results = [0] * len(bins)
for i in time_series:
for j , (begin, end) in enumerate(bins):
if i > begin and i <= end:
results[j] += 1
print results mu = time_series.mean()
median = np.median(time_series)
sigma = time_series.std() ax = pd.Series(results).plot(kind='bar', logy = True, figsize=(25, 13.5))
# dpi = ax.figure.get_dpi()
# print 'dpi = ', dpi
# plt.gcf().set_size_inches(25, 13.5) ax.set_ylabel('Count')
ax.set_xlabel('Time in seconds')
# print dir(fig)
ax.set_xticklabels(labels, rotation = 45)
ax.set_title('MDSS download statistics') textstr = 'count=%s\nmin=%.2f\nmax=%.2f\n$\mu=%.2f$\n$\mathrm{median}=%.2f$\n$\sigma=%.2f$'%(time_series.count(),time_series.min(), time_series.max(),mu, median, sigma) # these are matplotlib.patch.Patch properties
props = dict(boxstyle='round', facecolor='wheat', alpha=0.5) # place a text box in upper right in axes coords
ax.text(0.90, 0.95, textstr, transform=ax.transAxes, fontsize=14,
verticalalignment='top', bbox=props) ax.figure.show()
#
ax.figure.set_size_inches(25, 13.5, forward = True)
print ax.figure.get_size_inches()
ax.figure.savefig('result.png', format='png',)
input('asdfasd') if __name__ == "__main__":
# print get_datetime("2014-10-23 09:19:34,251 pid=27850")
# parse('inpri_p_antiy.log', 'result.csv')
do_statistics('result.csv')
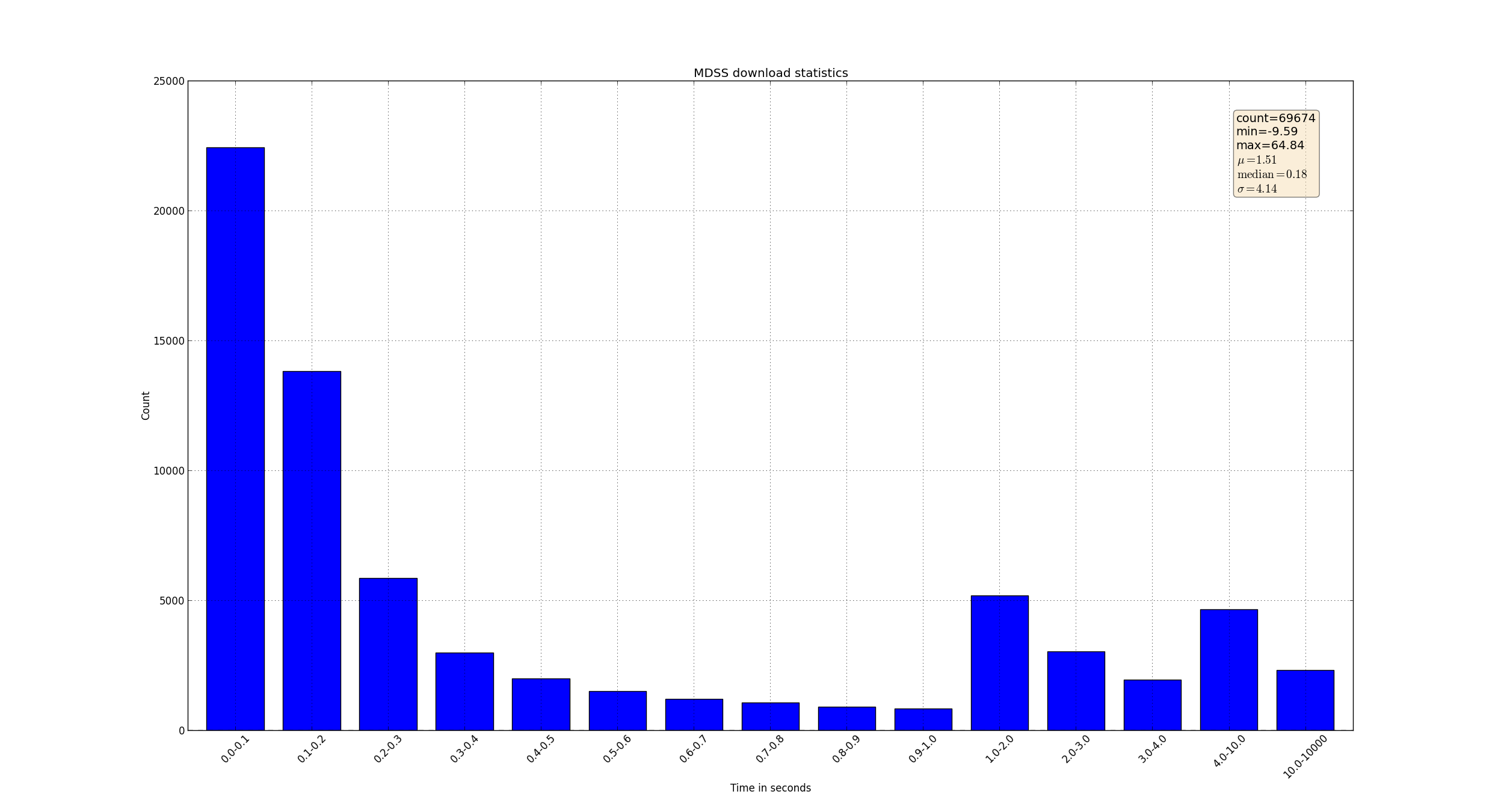
生成图像如下:
使用pandas处理数据并绘图的例子的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 【转载】使用Pandas对数据进行筛选和排序
使用Pandas对数据进行筛选和排序 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas对数据进行筛选和排序 目录: sort() 对单列数据进行排序 对多列数据进行排序 获取金额最小前10项 ...
- 【转载】使用Pandas进行数据提取
使用Pandas进行数据提取 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据提取 目录 set_index() ix 按行提取信息 按列提取信息 按行与列提取信息 提取特定日期的信 ...
- 【转载】使用Pandas进行数据匹配
使用Pandas进行数据匹配 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas进行数据匹配 目录 merge()介绍 inner模式匹配 lefg模式匹配 right模式匹配 outer模式 ...
- 【转载】使用Pandas创建数据透视表
使用Pandas创建数据透视表 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas创建数据透视表 目录 pandas.pivot_table() 创建简单的数据透视表 增加一个行维度(inde ...
- Pandas 把数据写入csv
Pandas 把数据写入csv from sklearn import datasets import pandas as pd iris = datasets.load_iris() iris_X ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
- Pandas DataFrame数据的增、删、改、查
Pandas DataFrame数据的增.删.改.查 https://blog.csdn.net/zhangchuang601/article/details/79583551 #删除列 df_2 = ...
- pandas 选取数据 修改数据 loc iloc []
pandas选取数据可以通过 loc iloc [] 来选取 使用loc选取某几列: user_fans_df = sample_data.loc[:,['uid','fans_count']] 使 ...
随机推荐
- Cognition math based on Factor Space (2016.05)
Cognition math based on Factor Space Wang P Z1, Ouyang H2, Zhong Y X3, He H C4 1Intelligence Enginee ...
- 转-Android仿微信气泡聊天界面设计
微信的气泡聊天是仿iPhone自带短信而设计出来的,不过感觉还不错可以尝试一下仿着微信的气泡聊天做一个Demo,给大家分享一下!效果图如下: 气泡聊天最终要的是素材,要用到9.png文件的素材,这样气 ...
- Android开发--FrameLayout的应用
1.简介 frameLayout为框架布局,该布局的特点为层层覆盖,即最先放置的部件位于最下层,最后放置的部件位于最上层. 2.构建 如图所示,该视图中有五个TextView.其中,tv1放置在最底层 ...
- SSM框架学习之高并发秒杀业务--笔记4-- web层
在前面几节中已经完成了service层和dao层,到目前为止只是后端的设计与编写,这节就要设计到前端的设计了.下面开始总结下这个秒杀业务前端有哪些要点: 1. 前端页面的流程 首先是列表页,点某个商品 ...
- 连接英文字符集的ORACLE和调用存储过程问题及64位服务器连接ORACLE问题
部署在IIS上的webservice连接英文字符集的ORACLE数据库出现问题“未在本地计算机上注册"MSDAORA.1"提供程序”,解决方案如下: 原因:如错误,64位系统未注册 ...
- Reflector反编译WinForm程序重建项目资源和本地资源
工具:vs2012..NET Reflector8.1.0.35 要解决的问题: 通过Reflector反编译生成的代码可以编译通过并显示窗体的本地资源和项目资源图片 一.测试项目 两个图片分别放在项 ...
- HDU 1561 树形DP入门
The more, The Better Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- sqlite以及python的应用
有点乱,自己平时,遇到了就记下来,所以没整理. 数据库sqlite,以及Qt对数据库的操作 sql学习网址: sqlite官网:http://www.sqlite.org http://www.w3s ...
- ajaxsearch要点1
ajaxsearch中必须将form的class定义为pagerForm,才能在foot中submit按钮得到值
- web前端基础篇⑧
1.伪类选择器 都以冒号开始.:focus 焦点的地方加样式:first-child 向元素的第一个子元素添加样式锚伪类:a:link {color:red} 未访问的链接 a:visited {co ...