python2.x 默认编码问题
python2.x中处理中文,是一件头疼的事情。网上写这方面的文章,测次不齐,而且都会有点错误,所以在这里打算自己总结一篇文章。
我也会在以后学习中,不断的修改此篇博客。
这里假设读者已有与编码相关的基础知识,本文不再再次介绍,包括什么是utf-8,什么是unicode,它们之间有什么关系。
str与字节码
首先,我们完全不谈unicode。
|
1
|
s = "人生苦短" |
s是个字符串,它本身存储的就是字节码。那么这个字节码是什么格式的?
如果这段代码是在解释器上输入的,那么这个s的格式就是解释器的编码格式,对于windows的cmd而言,就是gbk。
如果将段代码是保存后才执行的,比如存储为utf-8,那么在解释器载入这段程序的时候,就会将s初始化为utf-8编码。
unicode与str
我们知道unicode是一种编码标准,具体的实现标准可能是utf-8,utf-16,gbk ……
python 在内部使用两个字节来存储一个unicode,使用unicode对象而不是str的好处,就是unicode方便于跨平台。
你可以用如下两种方式定义一个unicode:
|
1
2
|
s1 = u"人生苦短"s2 = unicode("人生苦短", "utf-8") |
encode与decode
在python中的编码解码是这样的:
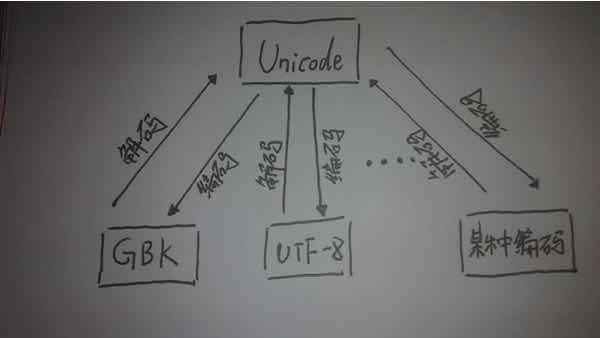
所以我们可以写这样的代码:
|
1
2
3
4
5
6
7
8
9
|
# -*- coding:utf-8 -*-su = "人生苦短"# : su是一个utf-8格式的字节串u = s.decode("utf-8")# : s被解码为unicode对象,赋给usg = u.encode("gbk")# : u被编码为gbk格式的字节串,赋给sgprint sg# 打印sg |
但是事实情况要比这个复杂,比如看如下代码:
|
1
2
|
s = "人生苦短"s.encode('gbk') |
这样为什么可以?看上图的编码流程的箭头,你就能想到原理,当对str进行编码时,会先用默认编码将自己解码为unicode,然后在将unicode编码为你指定编码。
这就引出了python2.x中在处理中文时,大多数出现错误的原因所在:python的默认编码,defaultencoding是ascii
看这个例子:
|
1
2
3
|
# -*- coding: utf-8 -*-s = "人生苦短"s.encode('gbk') |
上面的代码会报错,错误信息:UnicodeDecodeError: ‘ascii' codec can't decode byte ……
因为你没有指定defaultencoding,所以它其实在做这样的事情:
|
1
2
3
|
# -*- coding: utf-8 -*-s = "人生苦短"s.decode('ascii').encode('gbk') |
设置defaultencoding
设置defaultencoding的代码如下:
|
1
2
|
reload(sys)sys.setdefaultencoding('utf-8') |
如果你在python中进行编码和解码的时候,不指定编码方式,那么python就会使用defaultencoding。
比如上一节例子中将str编码为另一种格式,就会使用defaultencoding。
|
1
|
s.encode("utf-8") 等价于 s.decode(defaultencoding).encode("utf-8") |
再比如你使用str创建unicode对象时,如果不说明这个str的编码格式,那么程序也会使用defaultencoding。
|
1
|
u = unicode("人生苦短") 等价于 u = unicode("人生苦短",defaultencoding) |
默认的defaultcoding:ascii是许多错误的原因,所以早早的设置defaultencoding是一个好习惯。
文件头声明编码的作用。
这要感谢这篇博客关于python文件头部分知识的讲解。
顶部的:# -*- coding: utf-8 -*-目前看来有三个作用。
如果代码中有中文注释,就需要此声明
比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。
程序会通过头部声明,解码初始化 u”人生苦短”,这样的unicode对象,(所以头部声明和代码的存储格式要一致)
关于requests库
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。
其中的Request对象在访问服务器后会返回一个Response对象,这个对象将返回的Http响应字节码保存到content属性中。
但是如果你访问另一个属性text时,会返回一个unicode对象,乱码问题就会常常发成在这里。
因为Response对象会通过另一个属性encoding来将字节码编码成unicode,而这个encoding属性居然是responses自己猜出来的。
官方文档:
text
Content of the response, in unicode.
If Response.encoding is None, encoding will be guessed using chardet.
The encoding of the response content is determined based solely on HTTP headers, following RFC 2616 to the letter. If you can take advantage of non-HTTP knowledge to make a better guess at the encoding, you should set r.encoding appropriately before accessing this property.
所以要么你直接使用content(字节码),要么记得把encoding设置正确,比如我获取了一段gbk编码的网页,就需要以下方法才能得到正确的unicode。
|
1
2
3
4
5
6
|
import requestsresponse = requests.get(url)response.encoding = 'gbk' print response.text |
不仅仅要原理,更要使用方法!
如果是早期的我写博客,那么我一定会写这样的例子:
如果现在的文件编码为gbk,然后文件头为:# -*- coding: utf-8 -*-,再将默认编码设置为xxx,那么如下程序的结果会是……
这就类似于,当年学c的时候,用各种优先级,结合性,指针来展示自己水平的代码。
实际上这些根本就不实用,谁会在真正的工作中写这样的代码呢?我在这里想谈谈实用的处理中文的python方法。
基本设置
主动设置defaultencoding。(默认的是ascii)
代码文件的保存格式要与文件头部的# coding:xxx一致
如果是中文,程序内部尽量使用unicode,而不用str
关于打印
你在打印str的时候,实际就是直接将字节流发送给shell。如果你的字节流编码格式与shell的编码格式不相同,就会乱码。
而你在打印unicode的时候,系统自动将其编码为shell的编码格式,是不会出现乱码的。
程序内外要统一
如果说程序内部要保证只用unicode,那么在从外部读如字节流的时候,一定要将这些字节流转化为unicode,在后面的代码中去处理unicode,而不是str。
|
1
2
3
4
5
|
with open("test") as f: for i in f: # 将读入的utf-8字节流进行解码 u = i.decode('utf-8') .... |
如果把连接程序内外的这段数据流比喻成通道的的话,那么与其将通道开为字节流,读入后进行解码,不如直接将通道开为unicode的。
|
1
2
3
4
5
|
# 使用codecs直接开unicode通道file = codecs.open("test", "r", "utf-8")for i in file: print type(i) # i的类型是unicode的 |
所以python处理中文编码问题的关键是你要清晰的明白,自己在干什么,打算读入什么格式的编码,声明的的这些字节是什么格式的,str到unicode是如何转换的,str的一种编码到另一种编码又是如何进行的。 还有,你不能把问题变得混乱,要自己主动去维护一种统一。
python 3和2很大区别就是python本身改为默认用unicode编码。
字符串不再区分"abc"和u"abc", 字符串"abc"默认就是unicode,不再代表本地编码、
由于有这种内部编码,像c#和java类似,再没有必要在语言环境内做类似设置编码,比如“sys.setdefaultencoding”;
也因此也python 3的代码和包管理上打破了和2.x的兼容。2.x的扩展包要适应这种情况改写。
另一个问题是语言环境内只有unicode怎么输出gbk之类的本地编码。
1.如果你在Python中进行编码和解码的时候,不指定编码方式,那么python就会使用defaultencoding。 而python2.x的的defaultencoding是ascii,
这也就是大多数python编码报错:“UnicodeDecodeError: 'ascii' codec can't decode byte ......”的原因。
2.关于头部的# coding:utf-8,有以下几个作用 2.1如果代码中有中文注释,就需要此声明 2.2比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。 2.3程序会通过头部声明,解码初始化 u"人生苦短",这样的unicode对象,(所以头部声明和代码的存储格式要一致)
python2.7以后不用setdefaultencoding了,这两个是没有区别的
这两个作用不一样, 1. # coding:utf-8 作用是定义源代码的编码. 如果没有定义, 此源码中是不可以包含中文字符串的. PEP 0263 -- Defining Python Source Code Encodings https://www.python.org/dev/peps/pep-0263/ 2. sys.getdefaultencoding() 是设置默认的string的编码格式
答按惯例都在(序列化)输出时才转换成本地编码。
python2.x 默认编码问题的更多相关文章
- python unicode转中文及转换默认编码
一. 在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是unicode的中文编码.可 ...
- Python2.x的编码问题
1. 计算机编码历史 ASCII Python的默认编码,其是一种单字节的编码.刚开始计算机世界里只有英文,而单字节可以表示256个不同的字符.最开始ASCII只定义了128个字符编码,包括96个文字 ...
- Python2.7字符编码详解
目录 Python2.7字符编码详解 声明 一. 字符编码基础 1.1 抽象字符清单(ACR) 1.2 已编码字符集(CCS) 1.3 字符编码格式(CEF) 1.3.1 ASCII(初创) 1.3. ...
- 一篇文章助你理解Python2中字符串编码问题
前几天给大家介绍了unicode编码和utf-8编码的理论知识,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系.下面在Python2环境中进行代码演示,分别Wind ...
- python2和python3编码问题
欢迎加入python学习交流群 667279387 一.什么是编解码 1.什么是unicode 2.编码方式 二.python中的编解码 1.python2 (1).encode() 和 .decod ...
- 一篇文章搞懂python2、3编码
说在前边: 编码问题一直困扰着每一个程序员的编程之路,如果不将它彻底搞清楚,那么你的的这条路一定会走的格外艰辛,尤其是针对使用python的程序员来说,这一问题更加显著, 因为python有两个版本, ...
- 字符编码、python2和python3编码的区别
目录 字符编码 文本编辑器存储信息的过程 python解释器解释python代码的流程 python解释器与文本编辑器的异同 不同编码格式存入与读取数据的过程 乱码的分析 python2和python ...
- python2与python3编码
#coding:utf8#一#1.在python2中,默认以ASCII编码chcp 936import sysprint sys.getdefaultencoding()# ascii#str:byt ...
- 解决Python2中文ascii编码的方法
在YiiChina签到的时候,经常会看到有人在说说里面发群主是最帅的,yii 是 PHP 最好的框架,没有之一,就想到使用一言,在每天签到的时候也发一句话 同时使用方糖将内容推送到微信,防止有什么不对 ...
随机推荐
- golang开发缓存组件
代码地址github:cache 花了一天时间看了下实验楼的cache组件,使用golang编写的,收获还是蛮多的,缓存组件的设计其实挺简单的,主要思路或者设计点如下: 全局struct对象:用来做缓 ...
- 转【】浅谈sql中的in与not in,exists与not exists的区别_
浅谈sql中的in与not in,exists与not exists的区别 1.in和exists in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表 ...
- [ASP.net MVC] 将HTML转成PDF档案,使用iTextSharp套件的XMLWorkerHelper (附上解决显示中文问题)
原文:[ASP.net MVC] 将HTML转成PDF档案,使用iTextSharp套件的XMLWorkerHelper (附上解决显示中文问题) [ASP.net MVC] 将HTML转成PDF档案 ...
- css 用direction来改变元素水平方向,价值研究。
"direction"有两个值:ltr | rtl ltr:从左往右 rtl:从右往左 默认:ltr 一起看个效果就懂了. <style> div{ direction ...
- 【WP开发】使用磁倾仪
磁倾仪,也叫倾斜仪,主要用来检测手机设备在各个轴上旋转的角度.注意,磁倾仪与陀螺仪的差异,陀螺仪的关注点是旋转的角速度,它并不关注角度,只注重速度.而磁倾仪的读数就是设备倾斜的角度. 不管是使用重力感 ...
- .NET面试题解析(04)-类型、方法与继承
系列文章目录地址: .NET面试题解析(00)-开篇来谈谈面试 & 系列文章索引 做技术是清苦的.一个人,一台机器,相对无言,代码纷飞,bug无情.须梦里挑灯,冥思苦想,肝血暗耗,板凳坐穿 ...
- Android实现下滑和上滑事件
做过开发的对于下滑刷新与上滑加载都一定不陌生,因为我们在很多时候都会使用到,那对对于这个效果如何实现呢?相信难道过很多小伙伴,今天我就带领大家一道通过第三方组件快速完成上述效果的实现,保准每位小伙伴都 ...
- 利用Dapper ORM搭建三层架构
利用Dapper关系对象映射器写的简单的三层架构.Dapper:StackOverFlow在使用的一个微型的ORM,框架整体效率较高,轻量级的ORM框架.网上有较多的扩展.此处只是简单的调用Dappe ...
- DA - 信息分析思路概要
要素 局部 --->整体 显性 --->隐性 表面 --->本质 割裂 --->联系 特殊 --->普遍 串行 --->并发 纵向 --->横向 单点 --- ...
- 实用js代码大全
实用js代码大全 //过滤数字 <input type=text onkeypress="return event.keyCode>=48&&event.keyC ...