MySQL 调优基础(五) Linux网络
1. TCP/IP模型
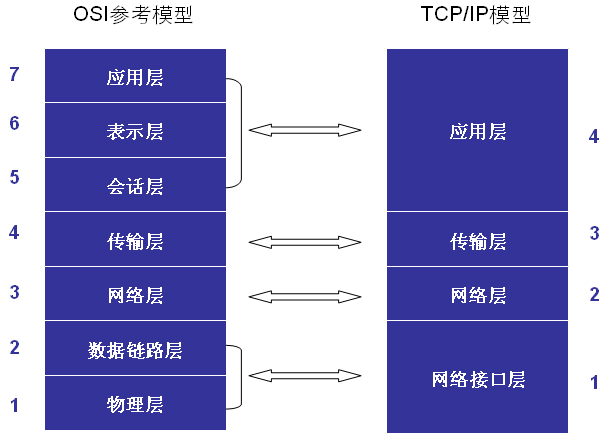
我们一般知道OSI的网络参考模型是分为7层:“应表会传网数物”——应用层,表示层,会话层,传输层,网络层,数据链路层,物理层。而实际的Linux网络层协议是参照了OSI标准,但是它实现为4层:应用层,传输层,网络层,网络接口层。OSI的多层对应到了实际实现中的一层。我们最为关注的是传输层和网络层。一般而言网络层也就是IP层,负责IP路由寻址等等细节,而传输层TCP/UDP负责数据的可靠/快速的传输功能。
网络的实际运行过程就是发送方,从高层向底层,根据协议对数据进行一层一层的封包,每一层加上该层协议的header;而接收方,从底层向高层,不断的解封数据包,每一层去掉该层的协议的header,然后最高层的应用层得到应用层数据:
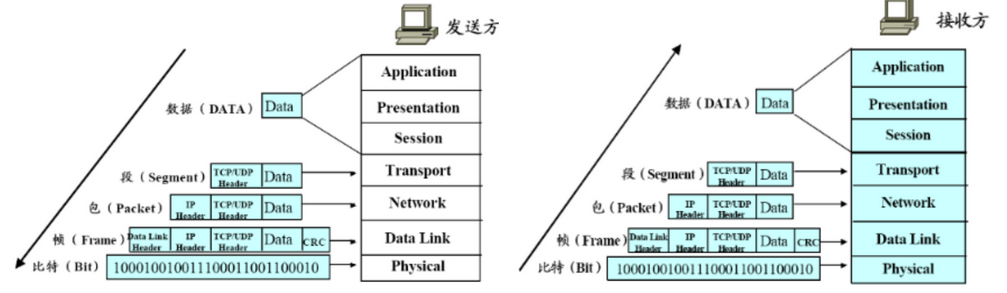
每一层添加的 Header(TCP/UDP Header, IP Header, Data Link Header) 都是为了实现该层协议服务而必须存在的协议相关数据。
2. Socket Buffer
发生方发送数据,接收方接受数据,那么双方必须存在一个保存数据的buffer,称为Socket Buffer,TCP/IP的实现都是放在kernel中的,所以Socket Buffer也是在kernel中的。Socket Buffer的大小配置对网络的性能有很大的影响,相关参数如下:
1)/proc/sys/net/ipv4/tcp_mem: 这是一个系统全局参数,表示所有TCP的buffer配置。有三个值,单位为内存页(通常为4K),第一个值buffer值的下限,第二个值表示内存压力模式开始对buffer应于压力的上限;第三个值内存使用的上限,超过时,可能会丢弃报文。
2)/proc/sys/net/ipv4/tcp_rmen: r 表示receive,也有三个值,第一个值为TCP接收buffer的最少字节数;第二个是默认值(该值会被rmem_default覆盖);第三个值TCP接收buffer的最大字节数(该值会被rmem_max覆盖);
3)/proc/sys/net/ipv4/tcp_wmem: w表示write,也就是send。也有三个值,第一个值为TCP发送buffer的最少字节数;第二个是默认值(该值会被wmem_default覆盖);第三个值TCP发送buffer的最大字节数(该值会被wmem_max覆盖);
4)/proc/sys/net/core/wmem_default: TCP数据发送窗口默认字节数;
5)/proc/sys/net/core/wmem_max: TCP数据发送窗口最大字节数;
6)/proc/sys/net/core/rmem_default: TCP数据接收窗口默认字节数;
7)/proc/sys/net/core/rmem_max: TCP数据接收窗口最大字节数;
注意:除了tcp_mem单位为内存页之外,其它几个单位都是字节;而且tcp_mem是全局配置,其它几个都是针对每一个TCP连接的配置参数。
3. 网络 NAPI, Newer newer NAPI
NAPI是为了解决网络对CPU的影响而引入的。
Every time an Ethernet frame with a matching MAC address arrives at the interface, there will be a hard interrupt. Whenever a CPU has to handle a hard interrupt, it has to stop processing whatever it was working on and handle the interrupt, causing a context switch and the associated flush of the processor cache. While you might think that this is not a problem if only a few packets arrive at the interface, Gigabit Ethernet and modern applications can create thousands of packets per second, causing a large number of interrupts and context switches to occur.
Because of this, NAPI was introduced to counter the overhead associated with processing network traffic. For the first packet, NAPI works just like the traditional implementation as it issues an interrupt for the first packet. But after the first packet, the interface goes into a polling mode. As long as there are packets in the DMA ring buffer of the network interface, no new interrupts will be caused, effectively reducing context switching and the associated overhead.
可见:NAPI 可以有效的减少网络对CPU中断而导致的上下文切换次数,减轻导致的CPU性能损耗。
4. Netfilter
Linux内核中的防火墙实现模块。也就是我们使用iptables调用的功能。提供了包过滤和地址转换功能。
5. TCP/IP 的三次握手建立连接和四次挥手结束连接
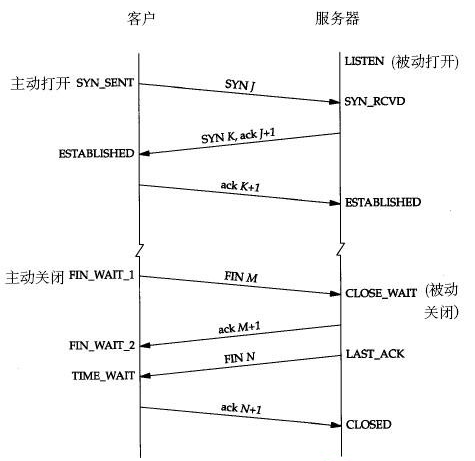
5.1 三次握手建立连接:
1)第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,并进入SYN_SEND状态,等待服务器B确认。
2)第二次握手:服务器B收到SYN包,必须发生一个ACK包,来确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
3)第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手(注意,主动打开方的最后一个ACK包中可能会携带了它要发送给服务端的数据)。
总结:三次握手,其实就是主动打开方,发送SYN,表示要建立连接,然后被动打开方对此进行确认,表示可以,然后主动方收到确认之后,对确认进行确认;
5.2 四次挥手断开连接:
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭,TCP的双方都要向对方发送一次 FIN 包,并且要对方对次进行确认。根据两次FIN包的发送和确认可以将四次挥手分为两个阶段:
第一阶段:主要是主动闭方方发生FIN,被动方对它进行确认;
1)第一次挥手:主动关闭方,客户端发送完数据之后,向服务器发送一个FIN(M)数据包,进入 FIN_WAIT1 状态;
被动关闭方服务器收到FIN(M)后,进入 CLOSE_WAIT 状态;
2)第二次挥手:服务端发生FIN(M)的确认包ACK(M+1),关闭服务器读通道,进入 LAST_ACK 状态;客户端收到ACK(M+1)后,关闭客户端写通道,
进入 FIN_WATI2 状态;此时客户端仍能通过读通道读取服务器的数据,服务器仍能通过写通道写数据。
第二阶段:主要是被动关闭方发生FIN,主动方对它进行确认;
3)第三次挥手:服务器发送完数据,向客户机发送一个FIN(N)数据包,状态没有变还是 LAST_ACK;客户端收到FIN(N)后,进入 TIME_WAIT 状态
4)第四次挥手:客户端返回对FIN(N)的确认段ACK(N+1),关闭客户机读通道(还是TIME_WAIT状态);
服务器收到ACK(N+1)后,关闭服务器写通道,进入CLOSED状态。
总结:
四次挥手,其本质就是:
主动关闭方数据发生完成之后 发生FIN,表示我方数据发生完,要断开连接,被动方对此进行确认;
然后被动关闭方在数据发生完成之后 发生FIN,表示我方数据发生完成,要断开连接,主动方对此进行确认;
5.3 CLOSE_WAIT状态的原因和处理方法:
由上面的TCP四次挥手断开连接的过程,可以知道 CLOSE_WAIT 是主动关闭方发生FIN之后,被动方收到 FIN 就进入了 CLOSE_WAIT状态,此时如果被动方没有调用 close() 函数来关闭TCP连接,那么被动方服务器就会一直处于 CLOSE_WAIT 状态(等待调用close函数的状态);
所以 CLOSE_WAIT 状态很多的原因有两点:
1)代码中没有写关闭连接的代码,也就是程序有bug;
2)该连接的业务代码处理时间太长,代码还在处理,对方已经发起断开连接请求; 也就是客户端因为某种原因先于服务端发出了FIN信号,导致服务端被动关闭,若服务端不主动关闭socket发FIN给Client,此时服务端Socket会处于CLOSE_WAIT状态(而不是LAST_ACK状态)。
CLOSE_WAIT 的特性:
由于某种原因导致的CLOSE_WAIT会维持至少2个小时的时间(系统默认超时时间的是7200秒,也就是2小时)。如果服务端程序因某个原因导致系统造成一堆 CLOSE_WAIT消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。CLOSE_WAIT 的危害还包括是TOMCAT失去响应等等。
要解决 CLOSE_WAIT 过多导致的问题,有两种方法:
1)找到程序的bug,进行修正;
2)修改TCP/IP的keepalive的相关参数来缩短CLOSE_WAIT状态维持的时间;
TCP连接的保持(keepalive)相关参数:
1> /proc/sys/net/ipv4/tcp_keepalive_time 对应内核参数 net.ipv4.tcp_keepalive_time
含义:如果在该参数指定的秒数内,TCP连接一直处于空闲,则内核开始向客户端发起对它的探测,看他是否还存活着;
2> /proc/sys/net/ipv4/tcp_keepalive_intvl 对应内核参数 net.ipv4.tcp_keepalive_intvl
含义:以该参数指定的秒数为时间间隔,向客户端发起对它的探测;
3> /proc/sys/net/ipv4/tcp_keepalive_probes 对应内核参数 net.ipv4.tcp_keepalive_probes
含义:内核发起对客户端探测的次数,如果都没有得到相应,那么就断定客户端不可达或者已关闭,内核就关闭该TCP连接,释放相关资源;
所以 CLOSE_WAIT 状态维持的秒数 = tcp_keepalive_time + tcp_keepalive_intvl * tcp_keepalive_probes
所以适当的 降低 tcp_keepalive_time, tcp_keepalive_intvl,tcp_keepalive_probes 三个值就可以减少 CLOSE_WAIT:
修改方法:
sysctl -w net.ipv4.tcp_keepalive_time=
sysctl -w net.ipv4.tcp_keepalive_probes=
sysctl -w net.ipv4.tcp_keepalive_intvl=5
sysctl -p
修改会暂时生效,重新启动服务器后,会还原成默认值。修改之后,进行观察一段时间,如果CLOSE_WAIT减少,那么就可以进行永久性修改:
在文件 /etc/sysctl.conf 中的添加或者修改成下面的内容:
net.ipv4.tcp_keepalive_time =
net.ipv4.tcp_keepalive_probes =
net.ipv4.tcp_keepalive_intvl =
这里的数值比上面的要大,因为上面的测试数据有点激进。当然数据该大之后效果不好,还是可以使用上面激进的数据。
修改之后执行: sysctl -p 使修改马上生效。
5.4 TIME_WAIT状态的原因和处理方法:
TIME_WAIT和CLOSE_WAIT不一样,默认的TIME_WAIT本来就比较大,但是默认的CLOSE_WAIT应该很短才对。
TIME_WAIT发生在TCP四次挥手的第二阶段:被动关闭方发生FIN(N),主动方收到该FIN(N),就进入 TIME_WAIT 状态,然后发生ACK(N+1)。
进入 TIME_WAIT 之后,主动关闭方会等待 2MSL(Maximum Segment Lifetime 报文最大存活时间)的时间,才释放自己占有的端口等资源。为什么呢?
这是因为,如果最后的ACK(N+1)没有被被动方收到的话,被动方会重新发生一个FIN(N2),那么主动方再次发生一个确认ACK(N2+1),所以这样一来就要用使主动关闭方在 TIME_WAIT 状态等待 2MSL 的时长。
如果你的 TIME_WAIT 状态的TCP过多,占用了端口等资源,那么可以通过修改TCP内核参数进行调优:
TCP 连接的 TIME_WATI相关参数:
1)/proc/sys/net/ipv4/tcp_tw_reuse 对应的内核参数:net.ipv4.tcp_tw_reuse
含义:是否能够重新启用处于TIME_WAIT状态的TCP连接用于新的连接;启用该resuse的同时,必须同时启用下面的快速回收recycle!
2)/proc/sys/net/ipv4/tcp_tw_recycle 对应的内核参数:net.ipv4.tcp_tw_recycle
含义:设置是否对TIME_WAIT状态的TCP进行快速回收;
3)/proc/sys/net/ipv4/tcp_fin_timeout 对应的内核参数:net.ipv4.tcp_fin_timeout
含义:主动关闭方TCP保持在FIN_WAIT_2状态的时间。对方可能会一直不结束连接或不可预料的进程死亡。默认值为 60 秒。
修改方法和 keepalive 的相关参数一样:
sysctl -w net.ipv4.tcp_tw_reuse=
sysctl -w net.ipv4.tcp_tw_recycle=
sysctl -w net.ipv4.tcp_fin_timeout=
sysctl -p
永久修改方法,也是修改 /etc/sydctl.conf:
net.ipv4.tcp_tw_reuse=
net.ipv4.tcp_tw_recycle=
net.ipv4.tcp_fin_timeout=
sysctl -p 是修改生效。
如果是Windows Server,则可以修改:TcpTimedWaitDelay 和 MaxUserPort;具体参见:http://www.cnblogs.com/digdeep/p/4779544.html
5.5 查看 TCP 连接处于各种状态的连接数量:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 297
ESTABLISHED 53
CLOSE_WAIT 5
windows 平台实现类似功能:
netstat -n | find /i "time_wait" /c
netstat -n | find /i "close_wait" /c
一个一个的状态来统计。
6. TCP/IP transfer window(传输窗口,滑动窗口)
Basically, the TCP transfer window is the maximum amount of data a given host can send or receive before requiring an acknowledgement from the other side of the connection. The window size is offered from the receiving host to the sending host by the window size field in the TCP header. Using the transfer window, the host can send packets more effectively because the sending host doesn't have to wait for acknowledgement for each sending packet. It enables the network to be utilized more. Delayed acknowledgement also improves efficiency. TCP windows start small and increase slowly with every successful acknowledgement from the other side of the connection.
传输窗口或者说滑动窗口,是指发送方在收到一个接收方的确认包之前,可以发送的数据的总量。接收方通过TCP头中的window size字段告诉发送方自己的可以接受的 传输窗口是多大,然后发送方就会据此对传输窗口的大小进行优化。
7. TCP/IP Offload
如果网卡硬件支持checksum、tso等等功能,那么就可以将这些功能让网卡来实现,从而降低CPU的负载。
1)checksum offload:为了保证数据传输时没有被破坏,IP/TCP/UDP都会对数据进行checksum,然后进行比较;该功能可以让网卡硬件实现;
2)TCP segmentation offload(TSO):如果传输的数据超过了网卡的MTU,那么就必须拆分成,也可以让网卡硬件来实现该功能;
8. 多网卡绑定
Linux 内核支持将多个物理网卡绑定成一个逻辑网络,从而进行网卡的负载均衡和网卡容错的实现。
9. 侦测网络瓶颈和故障
查看Linux网络情况的命令一般有:netstat, iptraf, tcpdump 等等,其中netstat是使用的最多,也最好使用的工具。
9.1 使用 netstat 命令查看活动的网络连接
netstat 查看信息根据协议不同和连接状态不同分为两类:
1)根据协议 tcp -t, udp -u 进行显示: netstat -ntap, netstat -nuap
-t 表示tcp 连接, -u 表示 udp 连接,如下所示
[root@localhost ~]# netstat -ntap
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0.0.0.0: 0.0.0.0:* LISTEN /vsftpd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /sshd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /redis-server *
tcp 0.0.0.0: 0.0.0.0:* LISTEN /rpcbind
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp ::: :::* LISTEN /sshd
tcp ::: :::* LISTEN /mysqld
tcp ::: :::* LISTEN /redis-server *
tcp ::: :::* LISTEN /rpcbind
[root@localhost ~]# netstat -nuap
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0.0.0.0: 0.0.0.0:* /rpcbind
udp 0.0.0.0: 0.0.0.0:* /rpcbind
udp 0.0.0.0: 0.0.0.0:* /portreserve
udp ::: :::* /rpcbind
udp ::: :::* /rpcbind
2)其中对于TCP协议又可以根据连接的状态不同进行显示: LISTEN -l ; 非 LISTEN 的,所有状态的 -a
加 -l 选项表示仅仅显示 listen 状态的TCP连接,-a 选项表示所有状态的TCP连接,默认只显示ESTABLISHED 的TCP的连接,如下所示:
[root@localhost ~]# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0.0.0.0: 0.0.0.0:* LISTEN /vsftpd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /sshd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /redis-server *
tcp 0.0.0.0: 0.0.0.0:* LISTEN /rpcbind
tcp ::: :::* LISTEN /sshd
tcp ::: :::* LISTEN /mysqld
tcp ::: :::* LISTEN /redis-server *
tcp ::: :::* LISTEN /rpcbind
[root@localhost ~]# netstat -ntp
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
[root@localhost ~]# netstat -ntap
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0.0.0.0: 0.0.0.0:* LISTEN /vsftpd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /sshd
tcp 0.0.0.0: 0.0.0.0:* LISTEN /redis-server *
tcp 0.0.0.0: 0.0.0.0:* LISTEN /rpcbind
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp 192.168.1.200: 192.168.1.3: ESTABLISHED /sshd
tcp ::: :::* LISTEN /sshd
tcp ::: :::* LISTEN /mysqld
tcp ::: :::* LISTEN /redis-server *
tcp ::: :::* LISTEN /rpcbind
-n 表示 numeric 用数字显示 ip 和 端口,而不是文字; -p 表示程序名称;
还有 -c 可以连续每秒显示一次。
字段含义:
recv-Q 表示网络接收队列(receive queue)
表示收到的数据已经在本地接收缓冲,但是还有多少没有被用户进程取走,如果接收队列Recv-Q一直处于阻塞状态,可能是遭受了拒绝服务 denial-of-service 攻击。
send-Q 表示网路发送队列(send queue)
发送了,但是没有收到对方的Ack的, 还保留本地缓冲区.
如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快。
这两个值通常应该为0,如果不为0可能是有问题的。packets在两个队列里都不应该有堆积状态。可接受短暂的非0情况。
netstat -s 显示所有协议的连接的统计数据:
[root@localhost ~]# netstat -s
Ip:
total packets received
forwarded
incoming packets discarded
incoming packets delivered
requests sent out
Icmp:
ICMP messages received
input ICMP message failed.
ICMP input histogram:
destination unreachable:
ICMP messages sent
ICMP messages failed
ICMP output histogram:
destination unreachable:
IcmpMsg:
InType3:
OutType3:
Tcp:
active connections openings
passive connection openings
failed connection attempts
connection resets received
connections established
segments received
segments send out
segments retransmited
bad segments received.
resets sent
Udp:
packets received
packets to unknown port received.
packet receive errors
packets sent
UdpLite:
TcpExt:
delayed acks sent
delayed acks further delayed because of locked socket
packets header predicted
acknowledgments not containing data received
predicted acknowledgments
TCP data loss events
IpExt:
InBcastPkts:
InOctets:
OutOctets:
InBcastOctets:
9.2 使用 iptraf 命令实时查看网络
该命令显示的是实时变化的网络信息,直接执行 iptraf 可以进入交互界面。
一般使用方法:iptraf -i eth0, iptraf -g eth0, iptraf -d eth0, iptraf -l eth0 其中 eth0 可以换成其它网卡,或者所有网卡 all
-i 表示 ip traffic, -g 表示 genral info, -d 表示 detail info
比较常用的是: iptraf -d eth0, iptraf -d eth0 
其中显示了:接收到的数据包的数量,发送的数据包的数量;还有网络发包速率:incoming rates, outgoing rates。
9.3 使用 tcpdump 命令查看网络
使用 tcpdump 可以对 网卡,host, 协议,端口等等进行过滤,指定只 查看指定的网络信息。
下面的结果来自 192.168.1.3 的浏览器访问虚拟机中的 192.168.1.200中的nginx的网络包的发送情况:
[root@localhost ~]# tcpdump -n -i eth0 host 192.168.1.200 and 192.168.1.3 and tcp port ! 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size bytes
::10.381925 IP 192.168.1.3. > 192.168.1.200.http: Flags [S], seq , win , options [mss ,nop,wscale ,nop,nop,s ackOK], length
::10.382024 IP 192.168.1.200.http > 192.168.1.3.: Flags [S.], seq , ack , win , options [mss ,nop, nop,sackOK,nop,wscale ], length
::10.382301 IP 192.168.1.3. > 192.168.1.200.http: Flags [.], ack , win , length
::10.383170 IP 192.168.1.3. > 192.168.1.200.http: Flags [P.], seq :, ack , win , length
::10.383222 IP 192.168.1.200.http > 192.168.1.3.: Flags [.], ack , win , length
::10.385314 IP 192.168.1.200.http > 192.168.1.3.: Flags [P.], seq :, ack , win , length
::10.386902 IP 192.168.1.200.http > 192.168.1.3.: Flags [P.], seq :, ack , win , length
::10.387324 IP 192.168.1.3. > 192.168.1.200.http: Flags [.], ack , win , length
::20.392717 IP 192.168.1.3. > 192.168.1.200.http: Flags [.], seq :, ack , win , length
::20.392784 IP 192.168.1.200.http > 192.168.1.3.: Flags [.], ack , win , options [nop,nop,sack {:}], length
^C
packets captured
packets received by filter
packets dropped by kernel
下面截图简单分析上面的结果:
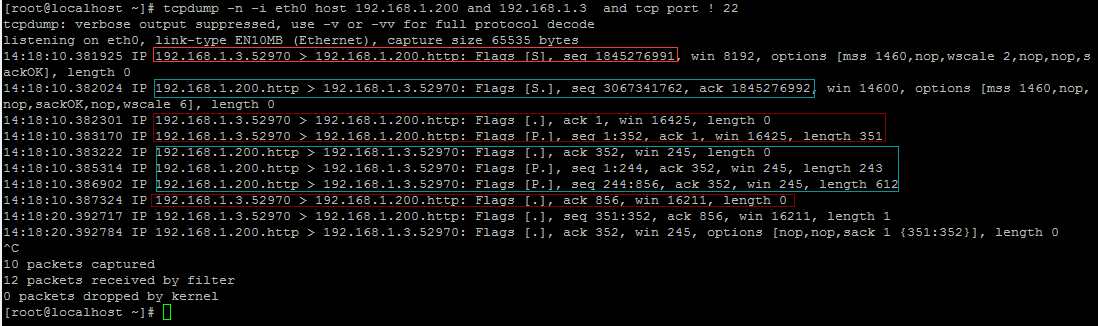
首先是 192.168.1.3.52970 的浏览器 向 192.168.1.200.http 的服务器 发送一个 主动打开的 SYN(1845276991) 包;
接下来 192.168.1.200.http 的服务器 向 192.168.1.3.52970 的浏览器 发送一个 SYN + ACK 包,注意 ack=1845276992 = 1845276991 +1;
然后是 192.168.1.3.52970 的浏览器 向 192.168.1.200.http 的服务器 发送一个 ACK(1),然后向 服务器发送请求,seq 1:352从1到352刚好351个字节,和请求的长度: length 351 吻合;
接下来 服务器接受http请求之后,返回一个 ACK(352) ,确认收到浏览器的请求,然后开始处理,接着返回内容:
seq: 1:244, seq: 244:856, 响应请求,发送内容是用了两个TCP连接,一起发送了 855个字节给浏览器;
然后是 192.168.1.3.52970 的浏览器 接收到 856 个字节之后,返回一个 ACK(856)该服务器。
最后的两个可能是用于 浏览器和服务器之间保持keepalive而发送的。因为浏览器向服务器进发送一个字节(seq 351:352),然后服务器进行确认ACK(352)
可以看到每一个连接的头部都带有了 win 字段值(window size),在确定传输窗口(滑动窗口)是需要使用到该字段;同时还可以看到MSS值。
9.4 使用 sar -n 命令查看网络
sar 命令太强大了,CPU、内存、磁盘IO、网络 都可以使用sar命令来查看。sar -n 专门用于网络,使用方法如下:
sar -n { keyword [,...] | ALL }
Report network statistics.
Possible keywords are DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6,
ICMP6, EICMP6 and UDP6.
sar -n DEV: 查看所有网卡每秒收包,发包数量,每秒接收多少KB,发送多少KB:
[root@localhost ~]# sar -n DEV
Linux 2.6.-.el6.i686 (localhost.localdomain) // _i686_ ( CPU) :: AM LINUX RESTART
... ...
:: AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
:: AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth0 14.40 17.84 2.16 8.13 0.00 0.00 0.06
:: AM eth1 0.25 0.03 0.02 0.01 0.00 0.00 0.00
:: AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth0 0.49 0.21 0.06 0.05 0.00 0.00 0.00
:: AM eth1 0.23 0.04 0.01 0.01 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth0 3.40 4.65 0.35 1.37 0.00 0.00 0.00
Average: eth1 0.24 0.04 0.01 0.01 0.00 0.00 0.00
字段含义:rxpck/s txpck/s rxkB/s txkB/s 每秒收包,每秒发包,每秒接收KB数量,每秒发送KB数量;
sar -n EDEV: 查看网络 错误,网络超负载,网络故障
[root@localhost ~]# sar -n EDEV
Linux 2.6.-.el6.i686 (localhost.localdomain) // _i686_ ( CPU) :: AM LINUX RESTART
... ...
:: AM IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
:: AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
:: AM eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
字段含义:
rxerr/s:Total number of bad packets received per second. 每秒接收的损坏的包
txerr/s:Total number of errors that happened per second while transmitting packets. 每秒发送的损坏的包
coll/s: Number of collisions that happened per second while transmitting packets. 每秒发送的网络冲突包数
rxdrop/s: Number of received packets dropped per second because of a lack of space in linux buffers. 每秒丢弃的接收包
txdrop/s: Number of transmitted packets dropped per second because of a lack of space in linux buffers. 每秒发送的被丢弃的包
txcarr/s: Number of carrier-errors that happened per second while transmitting packets. carrier-errors 是啥意思?
rxfram/s: Number of frame alignment errors that happened per second on received packets.
rxfifo/s:Number of FIFO overrun errors that happened per second on received packets. 接收fifo队列发生过载错误次数(每秒)
txfifo/s:Number of FIFO overrun errors that happened per second on transmitted packets. 发送方的fifo队列发生过载错误次数(每秒)
1)如果 coll/s 网络冲突 持续存在,那么可能网络设备存在问题或者存在瓶颈,或者配置错误;
2)发生了 FIFO 队列 overrun,表示 SOCKET BUFFER 太小;
3)持续的 数据包损坏,frame 损坏,可能预示着网络设备出现部分故障,或者配置错误;
sar -n SOCK:查看系统占用的所有的SOCKET端口 和 TIME_WAIT状态连接数
[root@localhost ~]# sar -n SOCK
Linux 2.6.-.el6.i686 (localhost.localdomain) // _i686_ ( CPU) :: PM LINUX RESTART :: PM totsck tcpsck udpsck rawsck ip-frag tcp-tw
:: PM
:: PM
:: PM
:: PM
:: PM
:: PM
:: PM
Average:
With the SOCK keyword, statistics on sockets in use are reported (IPv4). The following values are displayed:
totsck: Total number of sockets used by the system.
tcpsck: Number of TCP sockets currently in use.
udpsck: Number of UDP sockets currently in use.
rawsck: Number of RAW sockets currently in use.
ip-frag: Number of IP fragments currently in use.
tcp-tw: Number of TCP sockets in TIME_WAIT state.
9.5 使用 ifconfig 命令查看网络 活动,错误,负载:
[root@localhost ~]# ifconfig eth0
eth0 Link encap:Ethernet HWaddr :::::AA
inet addr:192.168.1.200 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe07:21aa/ Scope:Link
UP BROADCAST RUNNING MULTICAST MTU: Metric:
RX packets: errors: dropped: overruns: frame:
TX packets: errors: dropped: overruns: carrier:
collisions: txqueuelen:
RX bytes: (782.4 KiB) TX bytes: (2.3 MiB)
errors: 发生的该网卡上的错误;dropped: 被丢弃的数量;overruns: socket buffer被用完的次数;frame:帧错误数量
10. 网络调优 和 故障排除
10.1 首先了解网络的基本情况:
1)查看各种状态数量: netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
2)查看网络error, overruns等待错误:ifconfig eth0, ifconfig all, sar -n EDEV, sar -n EDEV | grep eth0
3)查看网络流量:sar -n DEV, sar -n DEV | grep eth0
10.2 确认网络 duplex 和 speed 是否正确:
[root@localhost ~]# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD:
Transceiver: internal
Auto-negotiation: on
MDI-X: off (auto)
Supports Wake-on: umbg
Wake-on: d
Current message level: 0x00000007 ()
drv probe link
Link detected: yes
结果中, Speed: 1000Mb/s Duplex: Full 表明了是对的。如果是 Half, 100Mb/s 等等 会对性能影响极大。必须调整。
10.3 MTU 大小 调优
如果TCP连接的两端的网卡和网络接口层都支持大的 MTU,那么我们就可以配置网络,使用更大的mtu大小,也不会导致被 切割重新组装发送。
配置命令:ifconfig eth0 mtu 9000 up
其实 除了 MTU ,还有一个 MSS(max segement size). MTU是网络接口层的限制,而MSS是传输层的概念。其实这就是 TCP分段 和 IP分片 。MSS值是TCP协议实现的时候根据MTU换算而得(减掉Header)。当一个连接建立时, 连接的双方都要通告各自的MSS值。
TCP分段发生在传输层,分段的依据是MSS, TCP分段是在传输层完成,并在传输层进行重组
IP分片发生在网络层,分片的依据是MTU, IP分片由网络层完成,也在网络层进行重组。
其实还有一个 window size, 但是它是完全不同的东西:
winsize is used for flow control. Each time the source can send out a number of segments without ACKs. You should check "sliding-
window" to understand this. The value of win is dynamic since it's related to the remaining buffer size.
(参见:http://www.newsmth.net/nForum/#!article/CompNetResearch/4555)
区分:MTU, MSS, window size
10.4 调高网络缓存
过小的网络缓存,或导致频繁的ACK确认包,以及导致 window size 很小,传输窗口也很小;过小的socket buffer对网络性能影响严重。
Small socket buffers could cause performance degradation when a server deals with a lot of concurrent large file transfers. A clear performance decline will hanppen when using small socket buffers. A low value of rmem_max and wmem_max limit available socket buffer sizes even if the peer has affordable socket buffers available. This causes small window sizes and creates a performance ceiling for large data transfers. Though not included in this chart, no clear performance difference is observed for small data (less than 4 KB) transfer.
1)/proc/sys/net/ipv4/tcp_mem TCP全局缓存,单位为内存页(4k);
对应的内核参数:net.ipv4.tcp_mem ,可以在 /etc/sysctl.conf 中进行修改;
2)/proc/sys/net/ipv4/tcp_rmem 接收buffer,单位为字节
对应的内核参数:net.ipv4.tcp_rmem, 可以在 /etc/sysctl.conf 中进行修改;
3)/proc/sys/net/ipv4/tcp_wmem 接收buffer,单位为字节
对应的内核参数:net.ipv4.tcp_wmem, 可以在 /etc/sysctl.conf 中进行修改;
-----------------------
4)/proc/sys/net/core/rmem_default 接收buffer默认大小,单位字节
对应内核参数:net.core.rmem_default, 可以在 /etc/sysctl.conf 中进行修改;
5)/proc/sys/net/core/rmem_max 接收buffer最大大小,单位字节
对应内核参数:net.core.rmem_max, 可以在 /etc/sysctl.conf 中进行修改;
6)/proc/sys/net/core/wmem_default 发送buffer默认大小,单位字节
对应内核参数:net.core.rmem_default, 可以在 /etc/sysctl.conf 中进行修改;
7)/proc/sys/net/core/wmem_max 发送buffer最大大小,单位字节
对应内核参数:net.core.rmem_max, 可以在 /etc/sysctl.conf 中进行修改;
注意:修改 /etc/sysctl.conf 之后,必须执行 sysctl -p 命令才能生效。
10.5 offload配置
可以将一些网络操作 offload 到网络硬件来负责。
ethtool -k eth0 可以查看当前的 offload 配置:
[root@localhost ~]# ethtool --show-offload eth0
Features for eth0:
rx-checksumming: on
tx-checksumming: on
tx-checksum-ipv4: off
tx-checksum-unneeded: off
tx-checksum-ip-generic: on
tx-checksum-ipv6: off
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off
tx-tcp6-segmentation: off
udp-fragmentation-offload: off [fixed]
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: on [fixed]
tx-vlan-offload: on [fixed]
ntuple-filters: off [fixed]
receive-hashing: off [fixed]
highdma: off [fixed]
rx-vlan-filter: on [fixed]
vlan-challenged: off [fixed]
tx-lockless: off [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
fcoe-mtu: off [fixed]
loopback: off [fixed]
ethtool -K eth0 rx on|off, ethtool -K eth0 tx on|off, ethtool -K eth0 tso on|off 进行修改
10.6 调大 接收队列和发送队列的大小:
1)接收队列:/proc/sys/net/core/netdev_max_backlog 对应内核参数:net.core.netdev_max_backlog
2)发送队列:
[root@localhost ~]# ifconfig eth0 | grep txqueue
collisions: txqueuelen:
进行修改:ifconfig eth0 txqueuelen 20000
10.7 调大 SYN 半连接 tcp_max_syn_backlog 数量
TCP三次握手建立连接时,被动打开方,有一个状态是SYN,
When the server is heavily loaded or has many clients with bad connections with high latency, it can result in an increase in half-open connections. This is common for Web servers, especially when there are a lot of dial-up users. These half-open connections are stored in the backlog connections queue. You should set this value to at least 4096. (The default is 1024.)
Setting this value is useful even if your server does not receive this kind of connection, because it can still be protected from a DoS (syn-flood) attack.
cat /proc/sys/net/ipv4/tcp_max_syn_backlog 对应内核参数: net.ipv4.tcp_max_syn_backlog,可以在/etc/sysctl.conf文件中配置。
sysctl -w net.ipv4.tcp_max_syn_backlog=4096
当服务器负载很重时,会导致很多的客户端的连接,服务器没有进行确认,所以就处在 SYN 状态,这就是所谓的半连接(half-open connection).半连接的数目由 tcp_max_syn_backlog 参数控制,增大它可以避免客户端的连接被拒绝,同时也能防御SYN洪水攻击。也就是可以容纳更多的等待连接的数量。
10.8 /proc/sys/net/core/somaxconn 和 net.core.somaxconn
该参数为完成3次握手,已经建立了连接,等待被accept然后进行处理的数量。默认为128,我们可以调整到 65535,甚至更大。也就是尅有容纳更多的等待处理的连接。
MySQL 调优基础(五) Linux网络的更多相关文章
- MySQL 调优基础(四) Linux 磁盘IO
1. IO处理过程 磁盘IO经常会成为系统的一个瓶颈,特别是对于运行数据库的系统而言.数据从磁盘读取到内存,在到CPU缓存和寄存器,然后进行处理,最后写回磁盘,中间要经过很多的过程,下图是一个以wri ...
- MySQL 调优基础(二) Linux内存管理
进程的运行,必须使用内存.下图是Linux中进程中的内存的分布图: 其中最重要的 heap segment 和 stack segment.其它内存段基本是大小固定的.注意stack是向低地址增长的, ...
- MySQL 调优基础:Linux内存管理 Linux文件系统 Linux 磁盘IO Linux网络
http://www.cnblogs.com/digdeep/category/739915.html
- MySQL 调优基础(三) Linux文件系统
Linux的文件系统有点像MySQL的存储引擎,它支持各种各样的文件系统.它最上层是通过 virtual files system虚拟文件系统作为一个抽象接口层来对外提供调用的.然后下层的各种文件系统 ...
- MySQL 调优基础(一) CPU与进程
一般而言,MySQL 的调优可以分为两个层面,一个是在MySQL层面上进行的调优,比如SQL改写,索引的添加,MySQL各种参数的配置:另一个层面是从操作系统的层面和硬件的层面来进行调优.操作系统的层 ...
- mysql调优 基础
MySQL调优可以从几个方面来做: 1. 架构层:做从库,实现读写分离: 2.系统层次:增加内存:给磁盘做raid0或者raid5以增加磁盘的读写速度:可以重新挂载磁盘,并加上noatime参数,这样 ...
- MySQL调优基础, 与hikari数据库连接池配合
1.根据硬件配置系统参数 wait_timeout 非交互连接的最大存活时间, 10-30min max_connections 全局最大连接数 默认100 根据情况调整 back_log ...
- MySQL调优系列基础篇
前言 有一段时间没有写博客了,整天都在忙,上班,录制课程,恰巧最近一段时间比较清闲,打算弄弄MYSQL数据库. 关于MySQL数据库,这里就不做过多的介绍,开源.免费等特性深受各个互联网行业喜爱,尤其 ...
- MySQL 调优/优化的 100 个建议
MySQL 调优/优化的 100 个建议 MySQL是一个强大的开源数据库.随着MySQL上的应用越来越多,MySQL逐渐遇到了瓶颈.这里提供 101 条优化 MySQL 的建议.有些技巧适合特定 ...
随机推荐
- hibernate----N-1(一)
*************************hibernate.cfg.xml <?xml version='1.0' encoding='utf-8'?> <!DOCTYPE ...
- 利用Yii框架中的collections体验PHP类型化编程
注:20150514 看过 惠新宸 关于PHP7的PPT后,看到了这一特性将被支持. Scalar Type Declarations function foo(int num) function ...
- linux_shell_5_shell特性_正则_1
前面我们了解了部分linux shell的相关特性,下面的链接是第4篇文章:linux_shell_4_shell特性 这里我们来继续讨论linux shell中至关重要的一个特性: 正则表达式 (r ...
- Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 1
场景:eclipse中编写java中用到数组 问题: 程序不报错但是运行过程中 终止,显示字样 “ Exception in thread "main" java.lang.Arr ...
- Scalaz(26)- Lens: 函数式不可变对象数据操作方式
scala中的case class是一种特殊的对象:由编译器(compiler)自动生成字段的getter和setter.如下面的例子: case class City(name:String, pr ...
- POJ 3276 Face The Right Way 反转
大致题意:有n头牛,有些牛朝正面,有些牛朝背面.现在你能一次性反转k头牛(区间[i,i+k-1]),求使所有的牛都朝前的最小的反转次数,以及此时最小的k值. 首先,区间反转的顺序对结果没有影响,并且, ...
- psql 命令行使用
如果觉得直接打开数据库修改繁琐,那么使用终端命令行是方便而又高大上的.下面来看看有哪些命令行: 说明:如果是正式的服务器则需要进行一个操作在执行下面的命令 ssh name @主机地址 -- name ...
- slid.es – 创建在线幻灯片和演示文稿的最佳途径
slid.es 提供了一种创建在线幻灯片和演示文稿的简单方法,让你通过几个简单的步骤制作效果精美的在线演示文稿.基于 HTML5 和 CSS3 实现,在现代浏览器中效果最佳. 您可能感兴趣的相关文章 ...
- 初识mfc
今天主要了解了Visual C++的开发环境Visual Studio(话说以前都是用来调试控制台程序的)和用mfc写了一个最简单的程序. 目前微软大力推广的开发环境就是vs,它的集成度相当高,方便程 ...
- React Native——我的学习套路
学习东西都有一定的套路,特别是新的框架,对于React Native,我是这么学的. 第一步 : 这是啥 在各种原因下,需要使用某个框架时,那第一件事就是知道这个框架是用来干什么.React Nati ...