leveldb 学习记录(六)SSTable:Block操作
block结构示意图
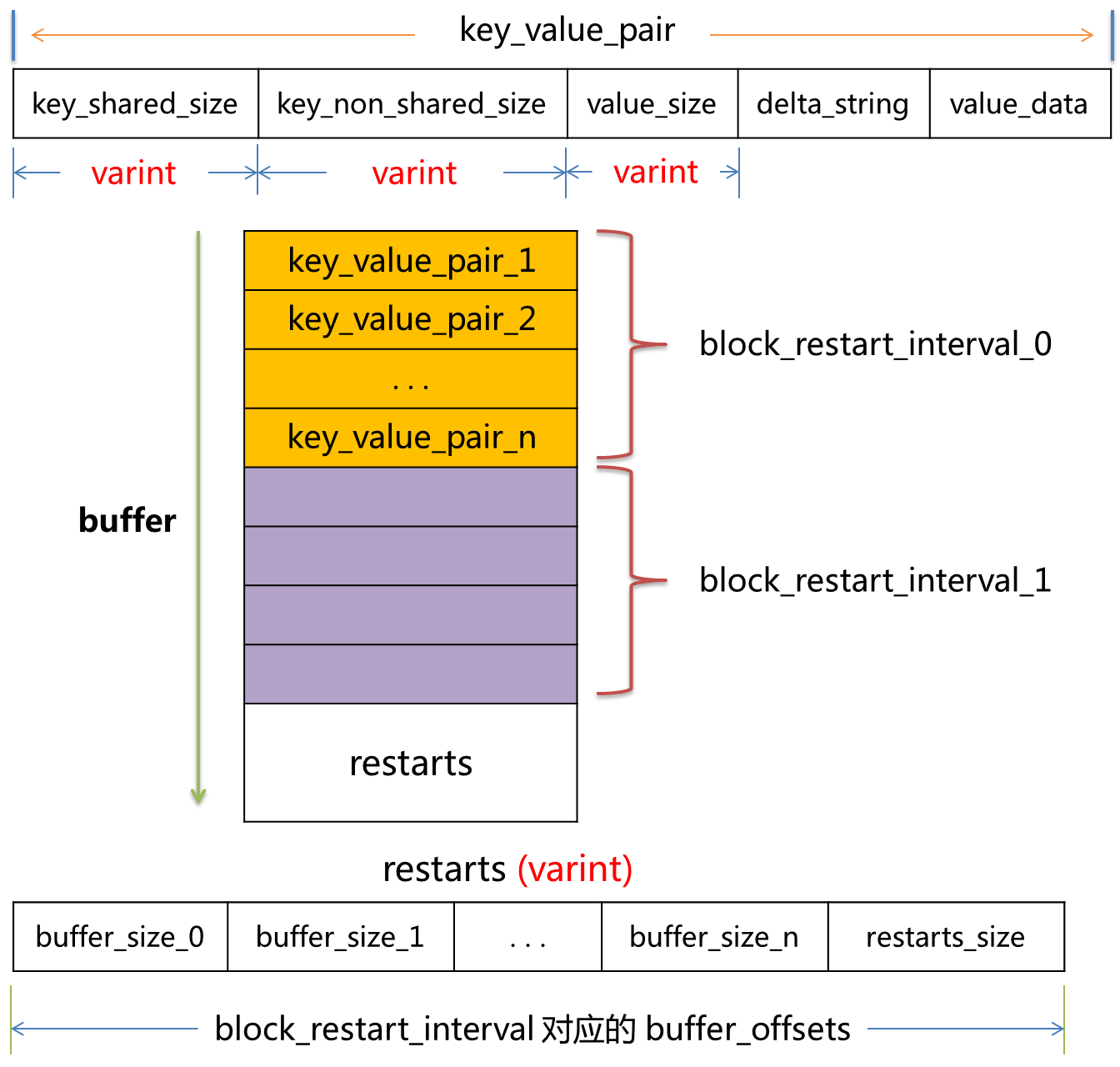
sstable中Block 头文件如下:
class Block {
public:
// Initialize the block with the specified contents.
// Takes ownership of data[] and will delete[] it when done.
Block(const char* data, size_t size);
~Block();
size_t size() const { return size_; }
Iterator* NewIterator(const Comparator* comparator);
private:
uint32_t NumRestarts() const;
const char* data_;
size_t size_;
uint32_t restart_offset_; // Offset in data_ of restart array
// No copying allowed
Block(const Block&);
void operator=(const Block&);
class Iter;
};
重启点在上个章节已经介绍过了
"“重启点”是干什么的呢?简单来说就是进行数据压缩,减少存储空间。我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。但是如果记录条数比较多,随机访问一条记录,需要从头开始一直解析才行,这样也产生很大的开销,所以设置了多个重启点,Block尾部就是指出哪些记录是这些重启点的。 "
//获取BLOCK中的重启点数目
inline uint32_t Block::NumRestarts() const {
assert(size_ >= *sizeof(uint32_t));
return DecodeFixed32(data_ + size_ - sizeof(uint32_t)); //重启点在block最后8字节(uint32_t)中
}
Block的创建和销毁
Block::Block(const char* data, size_t size)
: data_(data),
size_(size) {
if (size_ < sizeof(uint32_t)) {
size_ = ; // Error marker
} else {
restart_offset_ = size_ - ( + NumRestarts()) * sizeof(uint32_t); //重启点数目1个uint32 每个重启点的偏移记录 uint32 合记共(1+NumRestarts())* sizeof(uint32_t)
if (restart_offset_ > size_ - sizeof(uint32_t)) {
// The size is too small for NumRestarts() and therefore
// restart_offset_ wrapped around.
size_ = ;
}
}
} Block::~Block() {
delete[] data_;
}
Block中每个entry的解码
entry结构如上图的 KeyValuePair
static inline const char* DecodeEntry(const char* p, const char* limit,
uint32_t* shared,
uint32_t* non_shared,
uint32_t* value_length) {
if (limit - p < ) return NULL; //至少包含3个 共享字节
*shared = reinterpret_cast<const unsigned char*>(p)[];
*non_shared = reinterpret_cast<const unsigned char*>(p)[];
*value_length = reinterpret_cast<const unsigned char*>(p)[];
if ((*shared | *non_shared | *value_length) < ) {
// Fast path: all three values are encoded in one byte each
//三个记录的值或操作后 均没有超过128 即最高位为0
p += ;
} else {
if ((p = GetVarint32Ptr(p, limit, shared)) == NULL) return NULL;
if ((p = GetVarint32Ptr(p, limit, non_shared)) == NULL) return NULL;
if ((p = GetVarint32Ptr(p, limit, value_length)) == NULL) return NULL;
} if (static_cast<uint32_t>(limit - p) < (*non_shared + *value_length)) {
return NULL;
}
return p;
}
Block使用的迭代器
class Block::Iter : public Iterator
基本数据结构
class Block::Iter : public Iterator {
private:
const Comparator* const comparator_;
const char* const data_; // underlying block contents
uint32_t const restarts_; // Offset of restart array (list of fixed32)
uint32_t const num_restarts_; // Number of uint32_t entries in restart array
// current_ is offset in data_ of current entry. >= restarts_ if !Valid
uint32_t current_;
uint32_t restart_index_; // Index of restart block in which current_ falls
std::string key_;
Slice value_;
Status status_;
inline int Compare(const Slice& a, const Slice& b) const {
return comparator_->Compare(a, b);
}
}
// Return the offset in data_ just past the end of the current entry.
//下一个记录的起点就是当前记录的末尾偏移
//当前记录加上记录的长度 和 BLOCK的起点的差 就是偏移
inline uint32_t NextEntryOffset() const {
return (value_.data() + value_.size()) - data_;
} uint32_t GetRestartPoint(uint32_t index) {
//data_ + restarts_就是记录各个重启点偏移的数组
//根据重启点index 计算偏移data_ + restarts_ ,里面就是第index个重启点的偏移
assert(index < num_restarts_);
return DecodeFixed32(data_ + restarts_ + index * sizeof(uint32_t));
} void SeekToRestartPoint(uint32_t index) {
key_.clear();
restart_index_ = index;
// current_ will be fixed by ParseNextKey(); //value结束就是KEY的开始 所以使用value_记录
uint32_t offset = GetRestartPoint(index);
value_ = Slice(data_ + offset, );
}
bool ParseNextKey() {
current_ = NextEntryOffset(); //获取下一个entry的偏移
const char* p = data_ + current_;
const char* limit = data_ + restarts_; // 所有BLOCK内数据不可能超过restart
if (p >= limit) {
// No more entries to return. Mark as invalid.
current_ = restarts_;
restart_index_ = num_restarts_;
return false;
}
// Decode next entry
uint32_t shared, non_shared, value_length;
//解析获取 key的共享字段长度 非共享字段长度和value的长度
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
if (p == NULL || key_.size() < shared) {
CorruptionError();
return false;
} else {
key_.resize(shared); //key保存了其他entry的key 但是可以保留共享长度的字符串
key_.append(p, non_shared); //再添加非共享长度的字符串 就是当前KEY内容
value_ = Slice(p + non_shared, value_length); //value 就是略过key的偏移
//编译restart点 确认restart点的偏移是离自己最近的 restart_index_< current_ < (restart_index_ + 1)
while (restart_index_ + < num_restarts_ &&
GetRestartPoint(restart_index_ + ) < current_) {
++restart_index_;
}
return true;
}
}
};
参考:
https://www.cnblogs.com/itdef/p/9789620.html
leveldb 学习记录(六)SSTable:Block操作的更多相关文章
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplistleveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtablelevel ...
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- MyBatis学习 之 六、insert操作返回主键
数据库操作怎能少了INSERT操作呢?下面记录MyBatis关于INSERT操作的笔记,以便日后查阅. 二. insert元素 属性详解 其属性如下: parameterType ,入参的全 ...
- 实验楼Python学习记录_挑战字符串操作
自我学习记录 Python3 挑战实验 -- 字符串操作 目标 在/home/shiyanlou/Code创建一个 名为 FindDigits.py 的Python 脚本,请读取一串字符串并且把其中所 ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
- ElasticSearch 学习记录之ES如何操作Lucene段
近实时搜索 提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据.但是每次提交的一个新的段都fsync 这样操作代价过大.可以使用 ...
随机推荐
- unittest 出报告 并配合 jenkins,发现有用例错误,但是构建没出现红点 的解决方法
加了个 判断 测试用例总数 和 测试运行成功数 是否一致的判断,不一致 就断言失败,jenkins哪里是红点
- jQuery解决IE6/7/8不能使用 JSON.stringify 函数的问题
原文地址:http://www.ynpxrz.com/n1445665c2023.aspx JSON 对象是在 ECMAScript 第 5 版中实现的,此版于 2009 年 12 月发布:IE6 I ...
- inception 自动化sql审核
##概念: Inception是一款自动化运维的利器,有别与现在各个公司使用的方式,使用Inception,将会给DBA带来最大的便利性,将DBA从繁冗的工作中解放出来,做一些更多的自动化工作,或者从 ...
- 涂抹mysql笔记-InnoDB/MyISAM及其它各种存储引擎
存储引擎:一种设计的存取和处理方式.为不同访问特点的表对象指定不同的存储引擎,可以获取更高的性能和处理数据的灵活性.通常是.so文件,可以用mysql命令加载它. 查看当前mysql数据库支持的存储引 ...
- EasyUi 复杂多表头设置
columns: [ [ { field: 'Test', title: '测试', rowspan: 3, width: 100, sortable: true }, { title: '测试1', ...
- maven的单元测试中没有
原因:BaseTest没有找到单元测试造成的 增加一个空的单元测试 @Testpublic void testNothing(){} 异常现象:在maven项目执行mvn install 或mvn t ...
- leetcode85
class Solution { public int maximalRectangle(char[][] matrix) { if(matrix == null || matrix.length = ...
- leetcode287
public class Solution { public int FindDuplicate(int[] nums) { ) { ]; ]]; while (slow != fast) { slo ...
- SQL With (递归CTE查询)
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE).该表达式源自简单查询,并且在单条 SELECT.INSERT.UPDATE 或 DELETE 语句的执行范围内定义.该子句也可用在 CRE ...
- SpringBoot +Jpa+ Hibernate+Mysql工程
1 使用工具workspace-sts 3.9.5.RELEASE (1)新建一个SpringBoot 项目,选择加载项目需要的的组件.DevTools,JPA,Web,Mysql. Finish. ...