JDK1.7 的 HashMap
HashMap是一个用于存储key-value的键值对集合,每个键值对都是一个Entry。这些键值对分散存储在一个数组中,这个数组就是HashMap的主干。
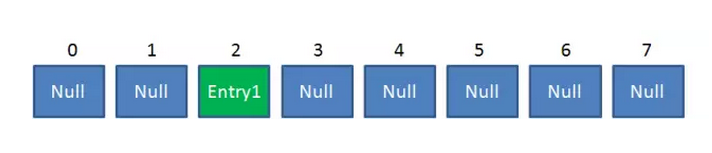
HashMap每个初始值都为null。

1.Put方法的原理
调用Put方法的时候发生了什么呢?
比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
index = Hash(“apple”)
假定最后计算出的index是2,那么结果如下:
但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况。比如下面这样:
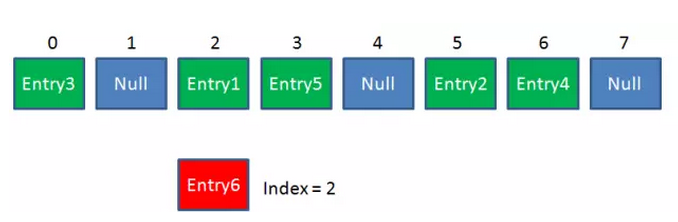
这时候该怎么办呢?我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:

需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。至于为什么不插入链表尾部,后面会有解释。
HashMap的初始化长度16,每次自动扩容或者手动扩容长度必须是2的幂。
之前说过,从Key映射到HashMap数组的对应位置,会用到一个Hash函数:
index = Hash(“apple”)
如何实现一个尽量均匀分布的Hash函数呢?我们通过利用Key的HashCode值来做某种运算。
2.Get方法的原理
使用Get方法根据Key来查找Value的时候,发生了什么呢?
首先会把输入的Key做一次Hash映射,得到对应的index:
index = Hash(“apple”)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是“apple”:
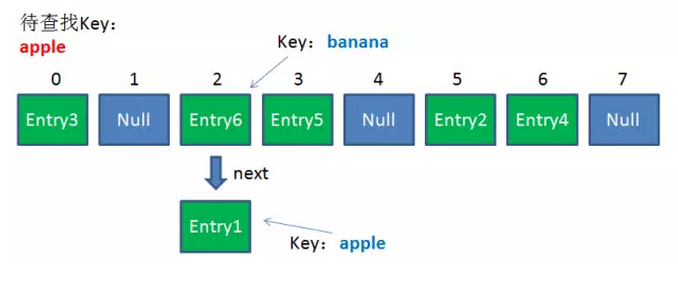
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
之所以把Entry6放在头节点,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大(头插法的原因)。
如何进行位运算呢?有如下的公式(Length是HashMap的长度):
index = HashCode(Key) & (Length - 1)
下面我们以值为“book”的Key来演示整个过程:
1.计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
JDK1.7 的 HashMap的更多相关文章
- JDK1.7中HashMap底层实现原理
一.数据结构 HashMap中的数据结构是数组+单链表的组合,以键值对(key-value)的形式存储元素的,通过put()和get()方法储存和获取对象. (方块表示Entry对象,横排表示数组ta ...
- JDK1.8中HashMap实现
JDK1.8中的HashMap实现跟JDK1.7中的实现有很大差别.下面分析JDK1.8中的实现,主要看put和get方法. 构造方法的时候并没有初始化,而是在第一次put的时候初始化 putVal方 ...
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- 基于JDK1.8的HashMap分析
HashMap的强大功能,相信大家都了解一二.之前看过HashMap的源代码,都是基于JDK1.6的,并且知其然不知其所以然,现在趁着寒假有时间,温故而知新.文章大概有以下几个方面: HashMap的 ...
- 关于JDK1.7+中HashMap对红黑树场景的思考
背景 在1.7之前的版本,当数组元素较多(几百.几千,或者更多)的时候,在这种前提扩容,涉及全量元素的遍历和坐标的重新定位,这个耗时会比较长.这是之前存在的一个弊端吧.那么引入红黑树之后就解决了问题, ...
- java集合: jdk1.8的hashMap原理简单理解
HashMap的数据结构 HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,他的底层结构是一个数组,而数组的元素是一个单向链表.HashMap默认初始化的是一个长度为16位的数 ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- JDK1.7之 HashMap 源码分析
转载请注明出处:http://blog.csdn.net/crazy1235/article/details/75451812 类继承关系 构造函数 Entry put put putForNullK ...
- JDK1.8的HashMap数据结构及红黑树
在JDK1.6,1.7中,HashMap的实现都是用基础的“拉链法”去实现,即数组+链表的形式.如下图:通过不同的hash值,来对数据进行分配存储. 关于HashMap的Entry长度,可以参考htt ...
- Java集合(七)--基于jdk1.8的HashMap源码
HashMap在开发中经常用,面试源码方面也会经常问到,在之前也多次了解过源码,今天算是复习一下,顺便好好总结一下,包括在后面有 相关面试题.本文不会对红黑树代码由太多深入研究,特别是删除方面太复杂, ...
随机推荐
- [Spring Boot]什么是Spring Boot
<Spring Boot是什么> Spring Boot不是一个框架 是一种用来轻松创建具有最小或零配置的独立应用程序的方式 用来开发基于Spring的应用,但只需非常少的配置. 它提供了 ...
- JS的异步操作
异步操作: 1.定时器都是异步操作 2.事件绑定都是异步操作 3.AJAX中一般我们都采用异步操作 4.回调函数可以理解为异步 同步:一次只能完成一个任务,如果多个任务就必须排队,先前面一个任务再执行 ...
- vue2.0 父子组件通信 兄弟组件通信
父组件是通过props属性给子组件通信的来看下代码: 父组件: <parent> <child :child-com="content"></chil ...
- vue 15分钟倒计时
HTML: <span>{{minute}}:{{second}}</span> script: 一 二 // 倒计时 num(n) { return n & ...
- linux下设置mysql5.7数据库远程访问
1.在网上看了很多关于设置远程访问的方式,根本就不起作用,后来在网上看到有一篇文章终于解决了我的问题,在配置文件中 /etc/mysql/my.cnf : 2.编辑 vi /etc/mysql/mys ...
- SQL-记录修改篇-008
修改记录: update table_name as a set a.type = ‘青年' where a.age>18 and a.age<40 解释:将表中age字段大于1 ...
- (33)关于django中路由自带的admin + 建表关系的讲解
admin是django自带的后台管理,在初始的时候就默认配置好了 当输入ip地址的时候后面跟admin,就会登陆管理员的后台,这个是django自带的,可以快速管理数据表(增删改查) PS:ip地址 ...
- windows 2008R2系统程序运行提示无法定位程序输入点ucrtbase.terminate
1.用python写了个脚本,打成exe程序,在一些机器上正常运行,再另外一些机器上运行提示 无法定位程序输入点ucrtbase.terminate 应该是缺少库文件支持 2.网上搜了下.https: ...
- 20165308实验三 敏捷开发与XP实践实验报告
实验三 敏捷开发与XP实践实验报告 实验目的 安装 alibaba 插件,解决代码中的规范问题.再研究一下Code菜单,找出一项让自己感觉最好用的功能. 在码云上把自己的学习搭档加入自己的项目中,确认 ...
- uniq的坑坑
很久没有做过文本统计之类的操作了,今天有点任务弄一下,幸亏机智的我列出了全部看了一遍,发现uniq的时候还是有重复的,然后总结了一下 假如我有1.txt这个文本: 10.0.0.1 10.0.0.1 ...