Linux内核分析 读书笔记 (第十八章)
第十八章 调试
18.1 准备开始
1. 需要的只是:
- 一个bug
- 一个藏匿bug的内核版本
- 相关内核代码的知识和运气
2. 在跟踪bug的时候,掌握的信息越多越好。
18.2 内核中的bug
1. 内核bug多种多样,产生的原因有很多:从错误代码(没有把正确的值存放在恰当的位置);到同步时发生的错误(共享变量锁定不当);再到错误的管理硬件(给错误的控制寄存器发送错误的指令)。
2. 从降低所有程序的运行性能到毁坏数据再到使得系统处于死锁状态都可能是bug发作时的症状。
3. 从隐藏在源代码中的错误到展现在目击者面前的bug,往往是经历一系列连锁反应的事件才可能触发的。
18.3 通过打印来调试
printk()是内核提供的格式化打印函数,除了和C库提供的printf()函数功能相同外还有一些自身特殊的功能。
18.3.1 健壮性
1.健壮性是printk()函数最容易让人们接受的一个特质,在任何时候内核的任何地方都能调用它。
除非在启动过程的初期就要在终端输出,否则可以认为printk()在什么情况下都能工作。
- 可以在中断上下文和进程上下文中被调用
- 可以在任何持有锁时被调用
- 可以在多处理器上同时被调用,调用者不必使用锁。
2.printk()函数也会有漏洞,解决办法是提供一个变体函数early _ printk(),但这种办法在某些硬件体系结构上无法实现,缺少可移植性。
18.3.2 日志等级
1.printk()可以指定一个日志级别,内核根据这个级别来判断是否在终端上打印消息。内核把级别比某个特定值低的所有消息显示在终端上。
2. KERN_ WARNING和KERN_ DEBUG都是简单的宏定义,加进printk()函数要打印的消息的开头。内核用这个指定的记录等级和当前终端的记录等级console_loglevel来决定是不是向终端上打印。
3.如果没有指定一个等级记录,函数会选用默认的DEFAULT _ MESSAGE _ LOGLEVEL,现在的默认等级为KERN _ WARNING。但默认值将来存在变化性,所以还是应该指定一个记录等级。

4.内核将最重要的记录等级KERN _ EMERG定为<0>,无关紧要的记录等级KERN _ DEBUG定为<7>
5.有两种赋予记录等级的方法:
- 保持终端的默认记录等级不变,给所有调试信息KERN _ CRIT或更低的等级。
- 给所有调试信息KERN _ DEBUG等级,调整终端的默认记录等级。
18.3.3 记录缓冲区
内核消息都被保存在一个环形队列中,该缓冲区的大小可以在编译时通过设置CONFIG _ LOG _ BUF _ SHIFT进行调整,在单处理器的系统上默认值是16kb,也就是说内核在同一时间只能保存16kb的内核消息,再多的话新消息就会覆盖老消息。读写都是按照环形队列方式操作的。
- 优点:健壮性,在中断上下 文中也可以方便的使用;简单性,使记录维护起来更容易。
- 缺点:可能会丢失消息。
18.3.4 syslogd和klogd
1.在标准的Linux系统上,用户空间的守护进程klogd从记录缓冲区中获取内核消息,再通过syslogd守护进程将他们保存在系统日志文件中。
2.klogd:既可以从/proc/kmsg文件中,也可以通过syslog()系统调用读取获得的内核信息,默认情况下选择读取/proc方式实现。两种情况klogd都会阻塞,直到有新的内核消息可供读出,被唤醒之后,默认处理是将消息传给syslogd。在启动时,可以通过-c标志来改变终端的记录等级。
3.syslogd:把它接收到的所有消息添加到一个文件中,默认是/var/log/messages,也可通过/etc/syslog.conf配置文件重新指定。
18.4 oops
1.oops是内核告知用户有不幸发生的最常用的方式。
2.因为内核是整个系统的管理者,不能采取像在用户空间出现运行错误时使用的那些简单手段,因为他很难自我修复,也不能将自己杀死,只能发布oops,过程为:向终端上输出错误消息、输出寄存器中保存的信息、输出可供跟踪的回溯线索。通常发布oops之后,内核会处于一种不稳定状态。
2.oops发生的时机:
- 发生在中断上下文:内核无法继续,会陷入混乱,导致系统死机
- 发生在idle进程或init进程(0号进程和1号进程),同上
- 发生在其他进程运行时,内核会杀死该进程并尝试着继续执行
3.oops中包含的重要信息:
寄存器上下文和回溯线索
- 回溯线索:显示了导致错误发生的函数调用链,以便我们观察发生了什么。
- 寄存器上下文信息:帮助冲进引发问题的现场。
18.4.1 ksymoops
回溯线索中的地址需要转化成有意义的符号名称才可以方便使用,需要调用ksymoops命令,还必须提供编译内核时产生的System.map。如果用的是模块,还需要一些模块信息。调用方法:
kysmoop saved_oops.txt18.4.2 kallsyms
现在的版本中不需要使用sysmoops这个工具,因为可能会发生很多问题,新版本中引入了kallsyms疼,可以通过定义CONFIG _ KALLSYMS配置选项启用。
18.5 内核调试配置选项
在编译时,为了方便调试和测试内核代码,内核提供了许多配置选项。这些选项都在内核配置编译器的内核开发菜单中,都依赖于CONFIG_ DEBUG_ KERNEL。
- slab layer debugging slab层调试选项
- high-memory debugging 高端内存调试选项
- I/O mapping debugging I/O映射调试选项
- spin-lock debugging 自旋锁调试选项
- stack-overflow debugging 栈溢出检查选项
- sleep-inside-spinlock checking 自旋锁内睡眠选项
18.6 引发bug并打印信息
1.一些内调用可以用来方便标记bug,提供断言并输出信息。最常用的两个是BUG()和BUG_ON()。当被调用时会引发oops,导致栈的回溯和错误信息的打印。
2.大部分体系把BUG()和BUG_ON()定义成某种非法操作,这样自然会产生需要的oops。可以把这些调用当做断言使用,想要断言某种情况不该发生:
if (bad_thing)
BUG();
或使用更好的形式:
BUG_ON(bad_thing);2.BUILD _ BUG_ ON()与BUG_ON()作用相同,仅在编译时调用。
3.引用panic()可以引发更严重的错误,不但会打印错误信息,还会挂起整个系统。
4.dump_stack()只在终端上打印寄存器上下文和函数的跟踪线索。
18.7 神奇的系统请求键
1.该功能可以通过定义CONFIG _ MAGIC _ SYSRQ配置选项来启用。SysRq(系统请求)键在大多数键盘上都是标准键。
2.当该功能被启用时,无论内核出于什么状态,都可以通过特殊的组合键和内核进行通信。
3.除了配置选项以外,还要通过一个sysctl用来标记该特性的开或关,需要启动它时使用如下命令:
echo 1 > /proc/sys/kernel/sysrq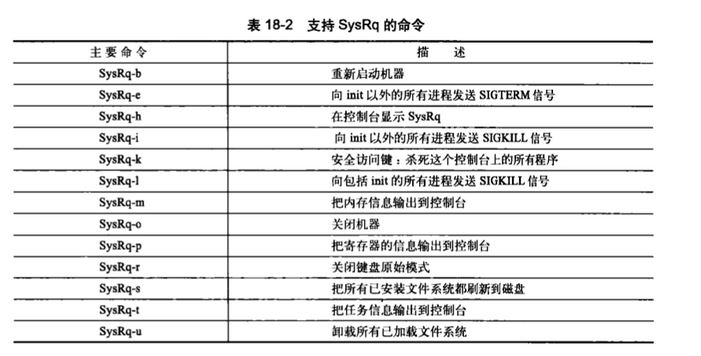
18.8 内核调试器的传奇
18.8.1 gdb
1.可以使用标准的GNU调试器对正在运行的内核进行查看。针对内核启动调试器的方法与针对进程的方法大致相同:
gdb vmlinux /proc/kcore- vmlinx:未经压缩的内核映像,区别于zImage或bImage,它存放于源代码树的根目录上。
- /proc/kcore作为一个参数选项,是作为core文件来用的,通过它能够访问到内核驻留的高端内存。只有超级用户才能读取此文件的数据。
2.可以使用gdb的所有命令来获取信息。
打印一个变量的值:p global_variable
反汇编一个函数:disassemble function3. 如果编译内核的时候使用了-g参数(在内核的Makefile文件的CFLAGS变量中加入-g)gdb还可以提供更多的信息。
4.局限性:
- 没有办法修改内核数据
不能单步执行内核代码
- 不能加断点
18.8.2 kgdb
1.kgdb是一个补丁 ,可以让我们在远端主机上通过串口利用gdb的所有功能对内核进行调试。
这需要两台计算机:第一台运行带有kgdb补丁的内核,第二台通过串行线使用gdb对第一台进行调试。
2.通过kgdb,gdb的所有功能都能使用:
- 读取和修改变量值
- 设置断点
- 设置关注变量
- 单步执行
18.9 探测系统
18.9.1 使用uid作为选择条件
1.一般情况下,只要保留原有的算法而把你的新算法加入到其他位置上,基本就能保证安全。
可以把用户id(UID)作为选择条件来实现这种功能,通过某种选择条件,安排到底执行哪种算法:
if (current-> uid !=7777) {
/* 老算法…… */
} else {
/* 新算法…… */
}2.除了uid为7777的用户以外,其他所有的用户都是用的老算法,可以创建一个UID为7777用户,专门用来测试新算法。
18.9.2 使用条件变量
如果代码与进程无关,或者希望有一个针对所有情况都能使用的机制来控制某个特性,可以使用条件变量。这比使用UID更简单,只需要创建一个全局变量作为一个条件选择开关。如果该变量为0,就使用某一个分支上的代码;否则,选择另外一个分支。可以通过某种接口提供对这个变量的操控,也可以直接通过调试器进行操控。
18.9.3 使用统计量
1.这种方法常用于使用者需要掌握某个特定事件的发生规律的时候。
2.方法是创建统计量,并提供某种机制访问其统计结果。
3.这种实现并非是SMP安全的,更好的方式是用原子操作。
18.9.4 重复频率限制
当系统的调试信息过多的时候,有两种方式可以防止这类问题发生:
- 重复频率限制:
限制调试信息,最多几秒打印一次,可以根据自己的需要调节频率。
发生次数限制
这种方法是要调试信息至多输出几次,超过次数限制后就不能再输出。
这种方法可以用来确认在特定情况下某段代码的确被执行了。
注:不管哪种方法用到的变量需要是静态的、局部的。并且限制在函数的局部范围以内,这样才能保证变量的值在经历多次函数调用后仍然能够保留下来。不是SMP安全或抢占安全的,更好的方式是用原子操作。
18.10 使用二分查找法找出罪恶的变更
18.11 使用Git进行二分搜索
1.Git源码管理工具提供了一个有用的二分搜索机制,如果使用Git来控制Linux源码树的副本,则Git将自动运行二分搜索进程。此外,Git会在修订版本中进行二分搜索,可以具体找到哪次提交的代码引发了bug。
告知git要进行二分搜索:git bisect start
提供一个出现问题的最早内核版本: git bisect bad <revision>
当前版本就是引发bug的最初版本的情况下使用这条命令:
git bisect bad
提供一个最新的可正常运行的内核版本: git bisect good <revision>2.这之后,git就会利用二分搜索法在Linux源码树中,自动检测正常的版本内核和有bug的内核版本之间那个版本有隐患,然后再编译、运行以及测试正被检测的版本。
如果这个版本正常:
git bisect good如果这个版本运行有异常:
git bisect bad3.对于每一个命令,Git将在每一个版本的基础上反复二分搜索源码树,并且返回所查的下一个内核版本,直到不能再进行二分搜索位置,最终Git会打印出有问题的版本号。
4,指定Git仅仅在与错误相关的目录列表中去二分搜索提交的补丁:
git bisect start - arch/x86
Linux内核分析 读书笔记 (第十八章)的更多相关文章
- 《Linux内核》读书笔记 第十八章
- Linux内核分析 读书笔记 (第一章、第二章)
第一章 Linux内核简介 1.1 Unix的历史 Unix很简洁,仅仅提供几百个系统调用并且有一个非常明确的设计目的. 在Unix中,所有东西都被当做文件,这种抽象使对数据和对设备的操作是通过一套相 ...
- 20135239 益西拉姆 linux内核分析 读书笔记之第四章
chapter 4 进程调度 4.1 多任务 多任务操作系统就是能同时并发的交互执行多个进程的操作系统. 多任务系统可以划分为两类: - 非抢占式多任务: - 进程会一直执行直到自己主动停止运行(这一 ...
- Linux内核分析 读书笔记 (第四章)
第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间.进程调度程序可看做在可运行态进程之间分配有限的处理器时间资源的内核子系统.只有通过调度程序的合理调度,系统资源才能最大限 ...
- Linux内核分析 读书笔记 (第七章)
第七章 链接 1.链接是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或被拷贝)到存储器并执行. 2.链接可以执行于编译时,也就是在源代码被翻译成机器代码时:也可以执行于 ...
- Linux内核分析 读书笔记 (第三章)
第三章 进程管理 3.1 进程 1.进程: 进程就是处于执行期的程序. 进程就是正在执行的程序代码的实时结果. 进程是处于执行期的程序以及相关的资源的总称. 进程包括代码段和其他资源. 2.线程:执行 ...
- Linux内核分析 读书笔记 (第五章)
第五章 系统调用 5.1 与内核通信 1.调用在用户空间进程和硬件设备之间添加了一个中间层.该层主要作用有三个: 为用户空间提供了硬件的抽象接口. 系统调用保证了系统的稳定和安全. 实现多任务和虚拟内 ...
- Linux内核分析课程笔记(一)
linux内核分析课程笔记(一) 冯诺依曼体系结构 冯诺依曼体系结构实际上就是存储程序计算机. 从两个层面来讲: 从硬件的角度来看,冯诺依曼体系结构逻辑上可以抽象成CPU和内存,通过总线相连.CPU上 ...
- 《Linux内核设计与实现》读书笔记 第十八章 调试
第十八章调试 18.1 准备开始 需要准备的东西: l 一个bug:大部分bug通常都不是行为可靠而且定义明确的 l 一个藏匿bug的内核版本:找出bug首先出现的版本 l 相 ...
随机推荐
- linux 下正则匹配时间命名格式的文件夹
用正则表达式匹配时间格式命名的文件夹 ls mypath | grep -E "[0-9]{4}-[0-9]{1,2}" mypath为需要查询的目录 查询出来的文件夹格式为:例 ...
- Jenkins 自动发布 Spring Boot 项目(Gitee)
1.下载 wget http://mirrors.jenkins.io/war-stable/latest/jenkins.war,并部署到tomcat下 2.机器安装好 java ,maven ,g ...
- SAP SD模块功能构成
- golang中数组与切片的区别
初始化:数组需要指定大小,不指定也会根据初始化的自动推算出大小,不可改变 数组: a := [...],,} a := [],,} 切片: a:= [],,} a := make([]) a := m ...
- python scrapy爬虫框架概念介绍(个人理解总结为一张图)
python的scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架 python和scrapy的安装就不介绍了,资料很多 这里我个人总结一下,能更加快理解scrapy和快速上手一个简 ...
- P3265 [JLOI2015]装备购买(高斯消元+贪心,线性代数)
题意; 有n个装备,每个装备有m个属性,每件装备的价值为cost. 小哥,为了省钱,如果第j个装备的属性可以由其他准备组合而来.比如 每个装备属性表示为, b1, b2.......bm . 它可以由 ...
- Android集成讯飞语音、百度语音、阿里语音识别
项目实践:https://blog.csdn.net/Jsagacity/article/details/80094164 demo下载地址:https://fir.im/jy28 demo源码:ht ...
- jQuery:自定义函数
<!doctype html><html><head><meta charset="utf-8"><title>< ...
- linux计划任务(转)
文章转自https://blog.csdn.net/jixieyang3701/article/details/79410725 linux 系统则是由 cron (crond) 这个系统服务来控制的 ...
- springmvc+ajax文件上传
环境:JDK6以上,这里我是用JDK8,mysql57,maven项目 框架环境:spring+springmvc+mybaits或spring+springmvc+mybatis plus 前端代码 ...