[SequenceFile_1] Hadoop 序列文件
1. 关于 SequenceFile
对于日志文件来说,纯文本不适合记录二进制类型数据,通过 SequenceFile 为二进制键值对提供了持久的数据结构,将其作为日志文件的存储格式时,可自定义键(LongWritable)和值(Writeable的实现类)的类型。
多个小文件在进行计算时需要开启很多进程,所以采用容器文件 SequenceFile 按固定大小将多个小文件包装起来,使存储和处理更高效。
2. SequenceFile 说明
【SequenceFile 序列文件】
是由序列化 K-V 对组成,而 K 和 V 即 Hadoop 的 Writable 格式
【为什么使用序列文件】
1、纯文本文件(日志文件)占用了磁盘空间较大
2、将日志文件通过序列文件进行包装,可以获得更好的性能(处理速度和磁盘空间的压缩)
3. SequenceFile 特性
1、扁平化文件,包括二进制的 K-V(将多行纵向的日志文件变成纵向的文件)
2、可读、可写、可排序
3、有三种压缩方式来压缩 K-V 对
1)不压缩
2)记录压缩:只压缩 value
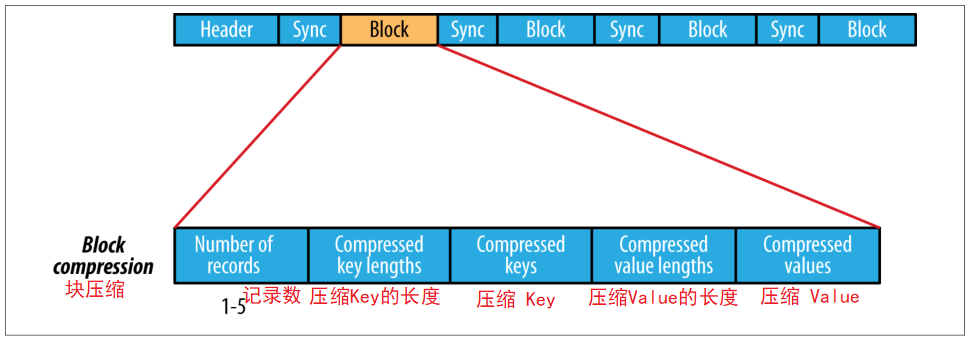
3)块压缩:将多组 K-V 聚集成一个 "block" 然后进行压缩
4、seqFile 格式
1)SEQ 三字节的头 + 数字(如6)作为版本号
2)Key 的完整类名
3)Value的完整类名
4)Boolean 值,指定了 seqFile 是否采用压缩
5)Boolean 值,指定了 seqFile 是否采用块压缩
6)压缩编解码器类
7)metadata: 源数据
8)sync: 同步点
4. SequenceFile 的基本操作
内容如下:
测试序列文件的读写操作 && 测试序列文件的排序操作 && 测试序列文件的合并操作 && 测试序列文件的压缩方式 && 测试将日志文件转换成序列文件
详情链接:
5. SequenceFile 的特性
【Write】
写
【Read】
读
//seek => 将读取指针手动移动,如果指针不在文件头,则会报错
//getPosition => 得到当前指针位置
//sync => 获取下一个同步点位置
【Sort】
//sort => 对sequenceFile进行排序
//merge => 合并+排序
【SequenceFile 压缩说明】
SequenceFile 压缩分为不压缩、记录压缩(默认)、块压缩
记录压缩只压缩值,详情如下:
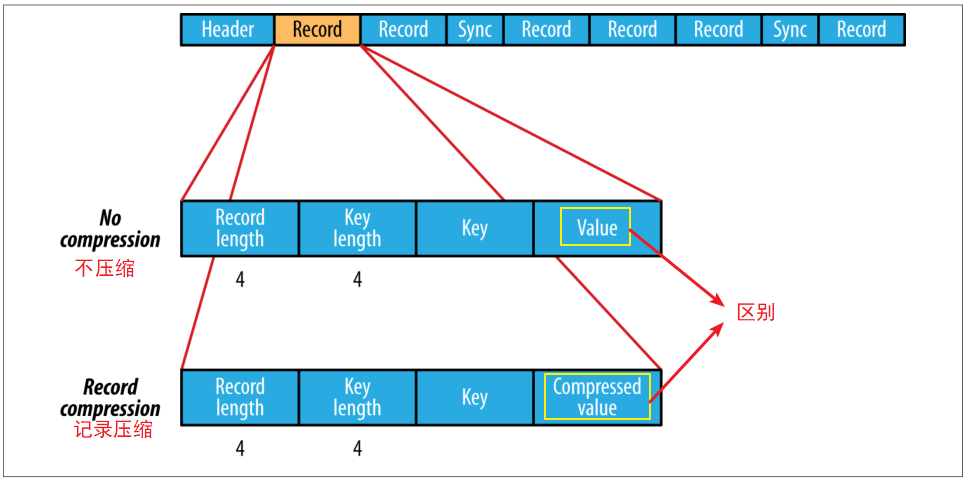
块压缩:将多组 K-V 聚集成一个 "block" 然后进行压缩
块压缩是指一次性压缩多条记录,利用记录间的相似性进行压缩,压缩效率高,压缩的块大小默认 1MB
在块压缩中,同步点与同步点之间是以块为单位进行存储的,块是多个 K-V 聚集的产物
Windows 下查看压缩后的 seqfile :
hdfs dfs -text file:///D:/seq/random.seq
[SequenceFile_1] Hadoop 序列文件的更多相关文章
- hadoop文本转换为序列文件
在以前使用hadoop的时候因为mahout里面很多都要求输入文件时序列文件,所以涉及到把文本文件转换为序列文件或者序列文件转为文本文件(因为当时要分析mahout的源码,所以就要看到它的输入文件是什 ...
- <Hadoop><SequenceFile><Hadoop小文件>
Origin 我们首先理解一下SequenceFile试图解决什么问题,然后看SeqFile怎么解决这些问题. In HDFS 序列文件是解决Hadoop小文件问题的一个方法: 小文件是显著小于HDF ...
- Hadoop HDFS文件常用操作及注意事项
Hadoop HDFS文件常用操作及注意事项 1.Copy a file from the local file system to HDFS The srcFile variable needs t ...
- Hadoop的文件读写操作流程
以下主要讲解了Hadoop的文件读写操作流程: 读文件 读文件时内部工作机制参看下图: 客户端通过调用FileSystem对象(对应于HDFS文件系统,调用DistributedFileSystem对 ...
- hadoop 提高hdfs删文件效率----hadoop删除文件流程解析
前言 这段时间在用hdfs,由于要处理的文件比较多,要及时产出旧文件,但是发现hdfs的blocks数一直在上涨,经分析是hdfs写入的速度较快,而block回收较慢,所以分心了一下hadoop删文件 ...
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Linux内核实践之序列文件【转】
转自:http://blog.csdn.net/bullbat/article/details/7407194 版权声明:本文为博主原创文章,未经博主允许不得转载. 作者:bullbat seq_fi ...
- 序列文件(seq_file)接口
转载:http://blog.csdn.net/gangyanliang/article/details/7244664 内容简介: 本文主要讲述序列文件(seq_file)接口的内核实现,如何使用它 ...
- hadoop基本文件配置
[学习笔记] 5)hadoop基本文件配置:hadoop配置文件位于:/etc/hadoop下(etc即:“etcetera”(附加物))core-site.xml:<configuration ...
随机推荐
- 关于vue项目中,手动定义的scrollTop的值
在项目中,有时需要控制scrollTop的值,比如有一个列表页,点击任意一个列表可以进入其详情页,这时如果你要返回的话, 肯定是希望还回到刚刚点击的地方,我当时的解决办法是,本地存下点击那一刻的scr ...
- python字符串操作简单方法
1.join #将字符中的每一个元素按照指定分隔符进行拼接 test='你说话带空格' print(test) t=' ' x='_' print(t.join(test)) print(x.join ...
- git同步github代码
yum install -y git 在linux下搭建git环境1.注册Github账号,网站:https://github.com2.Linux创建SSH密钥:git config --hel ...
- 堆排序——HeapSort
基本思想: 图示: (88,85,83,73,72,60,57,48,42,6) 平均时间复杂度: O(NlogN)由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作 ...
- Android使用AIDL跨进程通信
一.基本类型 1.AIDL是什么 AIDL是Android中IPC(Inter-Process Communication)方式中的一种,AIDL是Android Interface definiti ...
- 2018.4.23-ml笔记(线性回归、梯度下降)
线性回归:找到最合适的一条线来最好的拟合我们的数据点. hθ(x) = θixi=θTx θ被称之为权重参数 θ0为拟合参数 对每个样本yi=θTxi + εi 误差ε是独立并且具有 ...
- dva reduxRouter 跳转路由的参数
应该由 新页面的 this.props.location获取
- 通过spring抽象路由数据源+MyBatis拦截器实现数据库自动读写分离
前言 之前使用的读写分离的方案是在mybatis中配置两个数据源,然后生成两个不同的SqlSessionTemplate然后手动去识别执行sql语句是操作主库还是从库.如下图所示: 好处是,你可以人为 ...
- Hystrix参数配置
1.Hystrix参数配置文档 2.Hystrix参数配置示例 import org.springframework.beans.factory.annotation.Autowired; impo ...
- C++虚表详解
所有结果均为32位系统,指针为4个字节 简单继承 class A { public: int a; }; class B : public A { public: int b; }; 对象B的内存布局 ...