【Java入门提高篇】Day23 Java容器类详解(六)HashMap源码分析(中)
上一篇中对HashMap中的基本内容做了详细的介绍,解析了其中的get和put方法,想必大家对于HashMap也有了更好的认识,本篇将从了算法的角度,来分析HashMap中的那些函数。
HashCode
先来说说HashMap中HashCode的算法,在上一篇里,我们看到了HashMap中的put方法是这样的:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
那这个hash函数又是什么呢?让我们来看看它的真面目:
/**
* 将高位与低位进行与运算来计算哈希值。因为在hashmap中使用2的整数幂来作为掩码,所以只在当前掩码之上的位上发生
* 变化的散列总是会发生冲突。(在已知的例子中,Float键的集合在小表中保持连续的整数)因此,我们应用一个位运算
* 来向下转移高位的影响。 这是在综合考虑了运算速度,效用和质量之后的权衡。因为许多常见的散列集合已经合理分布
* (所以不能从扩散中受益),并且因为我们使用树来处理bin中发生的大量碰撞的情况,所以我们尽可能以代价最低的方式
* 对一些位移进行异或运算以减少系统损失, 以及合并由于hashmap容量边界而不会被用于散列运算的最高位的影响。
*
* todo 扰动函数
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
可以看出,这里并不是简单的使用了key的hashCode,而是将它的高16位与低16位做了一个异或操作。(“>>>”是无符号右移的意思,即右移的时候左边空出的部分用0填充)这是一个扰动函数,具体效果后面会说明。接下来再看看之前的putval方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果当前table未初始化,则先重新调整大小至初始容量
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(n-1)& hash 这个地方即根据hash求序号,想了解更多散列相关内容可以查看下一篇
if ((p = tab[i = (n - 1) & hash]) == null)
//不存在,则新建节点
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//先找到对应的node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果是树节点,则调用相应的putVal方法,这部分放在第三篇内容里
//todo putTreeVal
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果是链表则之间遍历查找
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//如果没有找到则在该链表新建一个节点挂在最后
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//如果链表长度达到树化的最大长度,则进行树化,该函数内容也放在第三篇
//todo treeifyBin
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果已存在该key的映射,则将值进行替换
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//修改次数加一
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
注意看第八行的代码:
tab[i = (n - 1) & hash]
(n - 1) & hash 即通过key的hash值来取对应的数组下标,并非是对table的size进行取余操作。
那么,为什么要这样做呢?首先,扰动函数的目的就是为了扩大高位的影响,使得计算出来的数值包含了高 16 位和第 16 位的特性,让 hash 值更加深不可测 来降低碰撞的概率。从hash方法的注释中,我们也可以找到答案,一般的散列,其实都是做取余处理,但是HashMap中的table大小是2的整数次幂,也就是说,肯定不是质数,那么在取余的时候,偶数的映射范围势必就要小了一半,这样效果显然就差很多,而且,除法和取余其实是很慢的操作,所以在JDK8中,使用了一种很巧妙的方式来进行散列。首先,table的大小size设置成了2的整数次幂,这样使用size-1就变成了掩码,下面是我找的一张图,能很好的解释这个过程:
来降低碰撞的概率。从hash方法的注释中,我们也可以找到答案,一般的散列,其实都是做取余处理,但是HashMap中的table大小是2的整数次幂,也就是说,肯定不是质数,那么在取余的时候,偶数的映射范围势必就要小了一半,这样效果显然就差很多,而且,除法和取余其实是很慢的操作,所以在JDK8中,使用了一种很巧妙的方式来进行散列。首先,table的大小size设置成了2的整数次幂,这样使用size-1就变成了掩码,下面是我找的一张图,能很好的解释这个过程:
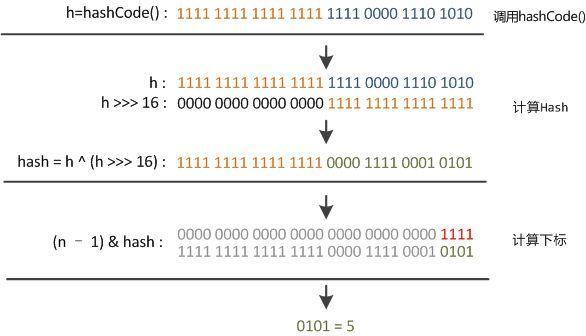
n是table的大小,默认是16,二进制即为10000,n - 1 对应的二进制则为1111,这样再与hash值做“与”操作时,就变成了掩码,除了最后四位全部被置为0,而最后四位的范围肯定会落在(0~n-1)之间,正好是数组的大小范围,散列函数的妙处就在于此了。 简直不能更稳,一波操作猛如虎。
简直不能更稳,一波操作猛如虎。
那么我们继续上一篇的栗子,我们来一步一步分析一下,小明和小李的hash值的映射过程:
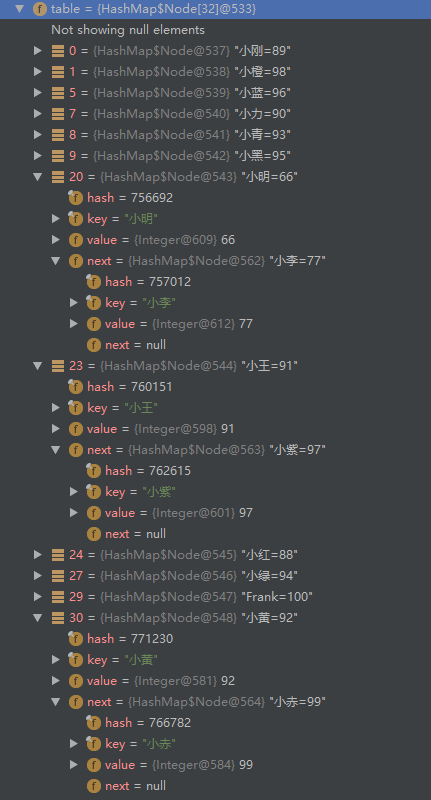
小明的hash值是756692,转换为二进制为10111000101111010100,table的大小是32,n-1=31,对应的二进制为:11111,做“与”运算之后,得到的结果是10100,即为20。
小李的hash值是757012,转换为二进制为10111000110100010100,与11111做与运算后,得到的结果也是10100,即20,于是就与小明发生了冲突,但还是要先来后到,于是小李就挂在了小明后面。
散列函数看完了,我们接下来再看看扩容函数。
扩容函数
扩容函数其实之前也已经见过了,就在上面的putVal方法里,往上面翻一翻,第六行可以看到resize函数,这就是扩容函数,让我们来看看它的庐山真面目:
/**
* 初始化或将table的大小进行扩容。 如果table为null,则按照字段threshold中的初始容量目标进行分配。
* 否则,因为我们使用2次幂进行扩容,所以在新表中,来自每个bin中的元素必须保持在相同的索引处,或者以原偏移量的2次幂进行移动。
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//新的容量扩展成原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//阈值也调整为原来的两倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//将旧数组中的node重新散列到新数组中
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
这里可以看到,如果原来的table还未被初始化的话,调用该函数后就会被扩容到默认大小(16),上一篇中也已经说过,HashMap也是使用了懒加载的方式,在构造函数中并没有初始化table,而是在延迟到了第一次插入元素之后。
当使用put插入元素的时候,如果发现目前的bins占用程度已经超过了Load Factor所设置的比例,那么就会发生resize,简单来说就是把原来的容量和阈值都调整为原来的2倍,之后重新计算index,把节点再放到新的bin中。因为index值的计算与table数组的大小有关,所以扩容后,元素的位置有可能会调整:
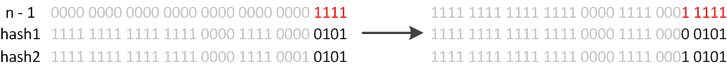
以上图为例,如果对应的hash值第五位是0,那么做与操作后,得到的序号不会变,那么它的位置就不会改变,相反,如果是1,那么它的新序号就会变成原来的序号+16,。

好像也不是很多嘛,嗯,算法部分就先介绍到这里了,之后的一篇再来说说HashMap中的EntrySet,KeySet和values(如果时间够的话顺便把迭代器也说一说)。
好了,本篇就此愉快的结束了,最后祝大家端午节快乐!如果觉得内容还不错的话记得动动小手点关注哦,你的支持就是我最大的动力!
【Java入门提高篇】Day23 Java容器类详解(六)HashMap源码分析(中)的更多相关文章
- Android事件传递机制详解及最新源码分析——ViewGroup篇
版权声明:本文出自汪磊的博客,转载请务必注明出处. 在上一篇<Android事件传递机制详解及最新源码分析--View篇>中,详细讲解了View事件的传递机制,没掌握或者掌握不扎实的小伙伴 ...
- Java BAT大型公司面试必考技能视频-1.HashMap源码分析与实现
视频通过以下四个方面介绍了HASHMAP的内容 一. 什么是HashMap Hash散列将一个任意的长度通过某种算法(Hash函数算法)转换成一个固定的值. MAP:地图 x,y 存储 总结:通过HA ...
- Android事件传递机制详解及最新源码分析——View篇
摘要: 版权声明:本文出自汪磊的博客,转载请务必注明出处. 对于安卓事件传递机制相信绝大部分开发者都听说过或者了解过,也是面试中最常问的问题之一.但是真正能从源码角度理解具体事件传递流程的相信并不多, ...
- Android事件传递机制详解及最新源码分析——Activity篇
版权声明:本文出自汪磊的博客,转载请务必注明出处. 在前两篇我们共同探讨了事件传递机制<View篇>与<ViewGroup篇>,我们知道View触摸事件是ViewGroup传递 ...
- Tomcat详解系列(3) - 源码分析准备和分析入口
Tomcat - 源码分析准备和分析入口 上文我们介绍了Tomcat的架构设计,接下来我们便可以下载源码以及寻找源码入口了.@pdai 源代码下载和编译 首先是去官网下载Tomcat的源代码和二进制安 ...
- ThreadLocal详解,ThreadLocal源码分析,ThreadLocal图解
本文脉路: 概念阐释 ----> 原理图解 ------> 源码分析 ------> 思路整理 ----> 其他补充. 一.概念阐述. ThreadLocal 是一个为 ...
- 【Java入门提高篇】Java集合类详解(一)
今天来看看Java里的一个大家伙,那就是集合. 集合嘛,就跟它的名字那样,是一群人多势众的家伙,如果你学过高数,没错,就跟里面说的集合是一个概念,就是一堆对象的集合体.集合就是用来存放和管理其他类对象 ...
- Java集合详解及List源码分析
对于数组我们应该很熟悉,一个数组在内存中总是一块连续的存储空间,数组的创建使用new关键字,数组是引用类型的数据,一旦第一个元素的位置确定,那么后面的元素位置也就确定了,数组有一个最大的局限就是数组一 ...
- Netty学习:ChannelHandler执行顺序详解,附源码分析
近日学习Netty,在看书和实践的时候对于书上只言片语的那些话不是十分懂,导致尝试写例子的时候遭遇各种不顺,比如decoder和encoder还有HttpObjectAggregator的添加顺序,研 ...
- 【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:put()get()**resize()** 首先介绍resize()这个方法,在我看来这是HashMap中一个非常 ...
随机推荐
- Setting Up Swagger 2 with a Spring REST API
Last modified: August 30, 2016 REST, SPRING by baeldung If you're new here, join the next webinar: & ...
- CentOS7 linux 中提示 bash: ls: 未找到命令...
记录一次CentOS7里执行ls命令失败的问题 执行ls命令时报找不到命令,原因是环境变量PATH被修改, 解决办法: 执行 export PATH=/bin:/usr/bin:$PATH 然后 ...
- 爬虫--反爬--css反爬---大众点评爬虫
大众点评爬虫分析,,大众点评 的爬虫价格利用css的矢量图偏移,进行加密 只要拦截了css 解析以后再写即可 # -*- coding: utf- -*- """ Cre ...
- Thread-方法以及wait、notify简介
Thread.sleep()1.静态方法是定义在Thread类中.2.Thread.sleep()方法用来暂停当前执行的线程,将CPU使用权释放给线程调度器,但不释放锁(也就是说如果有synchron ...
- HDU 4570---Multi-bit Trie(区间DP)
题目链接 Problem Description IP lookup is one of the key functions of routers for packets forwarding and ...
- Python获取网页指定内容(BeautifulSoup工具的使用方法)
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能,此文中所有的功能都是基于BeautifulSoup这个包. ...
- CentOS+Nginx+Supervisor部署ASP.NET Core项目
对.Net Core的学习和实践,已经进行了一年多的世间,截止目前,微软已经发布.Net Core2.1,关于.NetCore的应用部署的文章比比皆是.今天借此,回顾下.net core环境的部署过程 ...
- 使用Spring Boot开发 “Hello World” Web应用
环境准备 由于现在很多IDE都支持Maven, 所以我们将使用Maven构建该工程: 开始之前,需要先安装Java和Maven: 本工程将基于Spring Boot 1.4.3.RELEASE开发,推 ...
- CentOS 6.5 网络服务器功能的实现②:运用光盘(镜像)制作一个本地yum源
在用Linux安装软件时(rpm安装方式),有时会出现“包依赖”的现象.因此,我们可以用yum工具来实现一次性安装所有rpm工具包的功能. 实例:在此服务器上用yum的方式安装DHCP服务和TFTP服 ...
- cgroup其他部分 IO + hugepage
cgroup还有其他一些限制特性,如io,pid,hugetlb等,这些用处不多,参见Cgroupv1.下面介绍下与系统性能相关的io和hugepage,cgroup的io介绍参考Cgroup - L ...